

Ijraset Journal For Research in Applied Science and Engineering Technology
A Survey on Food Image Classification and Calorie Prediction Using Machine Learning
Authors: Aman Singh, Aman Shukla, Adishri Kadam, Khushi Magotra, Dhanashree Phalke, Vishakha Metre
DOI Link: https://doi.org/10.22214/ijraset.2024.60380
Certificate: View Certificate
Abstract
This work aims to find new techniques for food type recognition, diabetes disease prediction and food recommendation have been proposed for managing the diabetic disease and for recommending food with required calorie for the persons detected with diabetes. Therefore, this Project work focuses on effective methods for identifying the food type and estimating its calorie values with reference to the calorie table. Moreover, it focuses on prediction of diabetic disease. Based on the predicted level of diabetes, food recommendations have been made for the required calorie values. By combining image classification with calorie prediction, the approach aims to empower users in making informed dietary choices and managing their caloric intake more effectively. The proposed method demonstrates promising outcomes in both food item classification accuracy and calorie estimation precision. Its potential application extends to supporting healthier eating habits and aiding dietary monitoring for individuals, dietitians, and the food industry. This technological approach could serve as a valuable tool in promoting nutritional awareness and combating diet-related health issues.
Introduction
I. INTRODUCTION
Since health care on food attracts people recently, a food image system which easily records everyday meals is most awaited. Various studies have shown that eating a healthy diet with required calories will significantly reduce risks of various diseases. Dietary intake monitoring is a procedure of observing the food intake of a person throughout the day and providing the amount of calories consumed. This motivates a need to monitor and assess dietary intake of individual person’s food in a systematic way. But it is very difficult to report the actual dietary intake of an individual. Even dietitians should carry out complex lab experiments for accurately assessing the food intake. Therefore, measuring the calories of daily food intake is considered as an important Project area in health care domain. And to improve the habits of the people we have developed such a project which will provide predictions about calorie content and health recommendations as well.
Diabetes is a disease where the human body is not capable of producing the required insulin which is a necessary hormone used to convert intake foods into energy required for day-to-day life. It is classified into three types namely, Type1 Diabetes Mellitus (T1DM), Type2 Diabetes Mellitus (T2DM) and Gestational Diabetes. The T1DM is also known as insulin dependent diabetes mellitus. People with Type1 diabetes need to take insulin daily through injections. This type of diabetes is more common in children or young adults. The main factors for development of the disease are autoimmune, genetic and environment. T2DM is also called non – insulin dependent diabetes mellitus. This disease occurs when the body is unable to effectively make use of enough insulin produced by it.
It is usually seen in adults in the age of 30 and above. This type affects about 90-95% of people with diabetes. This is more common among older people and also for those obese people who have a family history of diabetes. Moreover, out of 90% of T2DM, around 30 to 80 percent is undiagnosed. Gestational diabetes occurs during pregnancy and usually disappears after pregnancy. But women with gestational diabetes have greater risk to get T2DM later. It is found that around 8.3% of the adult population in the world is affected by Diabetes Mellitus and it is predicted that the estimated 366 million in 2011 may be raised to 552 million in the year 2030.Therefore, some measure is needed to prevent or to delay the development of diabetes.
The three major objectives addressed by this Project work are the proposal of intelligent techniques for identification of the food type and effective estimation of its calorie value, application of intelligent algorithms for prediction of diabetic disease and then to recommend the food items with required calorie in order to control the severity caused by the disease. Since data mining algorithms provide suitable rules for decision making, data mining techniques are used in this Project work for performing effective food recommendation.
II. OVERVIEW OF PROPOSED MODEL
There have been several number of models proposed for detection of food images, measuring the amount of calories present in food items and analyzing the calorie intake of a person by determining their daily dietary information as well. Several methods and algorithms have been implemented in the related works for calculating the same. CNN has been proved as the finest method to be used for classification and achieved promising results. CNN, when used, gave an accuracy of about 70% (when images are noisy) to 99% (when the images used are plain and without noise). RGB provides better results as Red, Green, Blue being the primary colors provide array of colors for the purpose of feature extraction and delivers a higher accuracy. In the RGB model, the images are placed over 3 different channels according to their distinguished colors i.e., Red, Green and Blue. Whereas in the Gray Scale method, only one channel is available in which the intensity of the image is taken into consideration. Hence, because of vast range of colors in the RGB models it gives higher accuracy compared to the Gray scale. The model, when trained convolutionally, generates the natural image samples which gives the better broad statistical structure of the natural images as compared with previously existing parametric generative methods.
A. Dataset
The dataset we used is a combination of two existing datasets, namely FooDD and Food101. FooDD dataset comprises of 3,491 images in total. This dataset consists of images with very little noise. On the other hand, Food101 is a public dataset which consists of 101,000 images. This is indeed a very complex dataset with each class containing high variations in images. Using these two predefined datasets, we made a dataset by hand-picking few food items collected from each of the datasets which are considered to be frequently consumed by users as given in the table.
TABLE I. FOOD DATASET
|
Sr.No. |
Food Item |
Quantity |
|
1 |
Chiken Biryani |
14 |
|
2 |
Chiken Curry |
13 |
|
3 |
Dosa |
13 |
|
4 |
Fried Rice |
20 |
|
5 |
Idli |
12 |
|
6 |
Poori |
12 |
|
7 |
Vada |
11 |
|
8 |
Rice |
10 |
With the combination of these two datasets, a total of 8931 images were obtained with a collection of 8 categories in total consisting of 400-500 images each. Our proposed system showed training accuracy of 93.29% and testing accuracy of 78.7%.
B. Convolutional Neural Network
Convolutional Neural Networks (CNN), a class of Deep Neural Network, is majorly used for the process of image recognition. CNN consists of some basic layers comprising of hidden layers and fully connected layers where hidden layers are used to extract and learn the features of training images and fully connected layers are used for classification of the image. The structure of CNN is inspired by the structure of the human body’s nervous system which consists of neurons. The way each neuron passes messages to the next neuron, in the same way the layer in CNN communicates with each other for the process of feature extraction. As the name suggests, CNN performs convolution on the input data using filters (or kernel) in convolutional layer. This is done to extract the features from the input. For the proposed system, we have used 4 convolutional layers with kernel size of 3x3. Each convolutional layer is followed by pooling layer which is used to reduce the dimension of the images while preserving the spatial invariance. This in turn reduces the amount of computation cost in the whole CNN network. In our architecture, we have used max pooling of filter size 2x2 and strides of one to get the most prominent features which is selected by taking the maximum value of the feature from the prior layers. After gathering all the features and converting it into a vector, a fully connected (FC) layer is used to map the features and classify the test images into correct categories. We have used 2 FC layers, out of which last layer is predicting the probability distribution with the use of SoftMax classifier. The CNN architecture used by our proposed system is shown in Fig. 1 given below refer it for clear understanding.
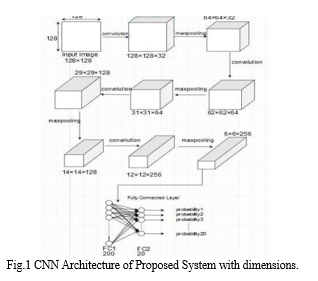
III. COMPARATIVE ANALYSIS OF EXISTING LITERATURE PAPERS
|
Sr. No |
Title and Authors |
Conference/ Journal Name |
Algorithms/ Methodology used. |
Advantages & Drawback |
|
1 |
Indian Food Image Classification with Transfer Learning- B. Anderson and H. Lee, |
2021 4th International Conference on Computational Systems and Information Technology for Sustainable Solution (CSITSS) |
The models used are IncceptionV3, VGG16, VGG19 and ResNet Build CNN- Classifier using pre- trained model. |
IncceptionV3 gives highest accuracy to classify food Items.
Complexity while working in large datasets. |
|
2 |
Food Image Recognition and calorie prediction- T. Chen and Y. Wang et al |
2021 IEEE International Symposium on Multimedia |
Color- segmentation, k-means clustering, texture segmentation tools.
Cloud-SVM and deep Neural Network to increase performance of image identify model. |
Capable of estimating calorie from mixed portion of food by clicking picture from mobile and giving input to system.
Require user to manually input the size and dimension of portion they ate. |
|
3 |
Image Based |
2020 IEEE |
Conventional |
Automatic food |
|
4. |
Deep residual learning for image recognition- K.He et al |
Proceedings of the2021 IEEE conference paper on Computer Vision and pattern recognition |
Residual Networks |
Improved Trainingand accuracy
Network depth maylead to overfitting. |
|
5. |
Rethinking theinception architecture for computer vision- C.Szegedy et al |
Proceedings of the2021 IEEE conference paper on Computer Vision and pattern recognition |
Inception Architecture |
Improved Feature extraction
Complex architecture design. |
|
6. |
Obesity and cancer risk- R. Patel et al |
National Cancer Institute Website2022 |
Information Source |
link between the obesity and cancer risk |
|
7. |
A deep convolutional neural network for food detectionand recognition- M.A.Subhi and S.M.Ali |
2022 IEEE- EMBS Conference on biomedical Engineering andSciences |
CNN for food detection and recognition. |
Accurate Food Image recognition
Data availability andmodel generalization |
|
7. |
A deep convolutional neural network for food detectionand recognition- M.A.Subhi and S.M.Ali |
2022 IEEE- EMBS Conference on biomedical Engineering andSciences |
CNN for food detection and recognition. |
Accurate Food Image recognition
Data availability andmodel generalization |
IV. CUDA DEEP NEURAL NETWORK
As working with CNN is computationally costly, it is not advised to work on a system with low configuration. This drawback can be eliminated by training and creating a model in a system with GPU. CUDA Deep Neural Network (CuDNN) is a library of primitives for DNN i.e. Deep Neural Networks that works by accelerating the GPU. It provides the user with the highly adjustable standard routines like normalization, pooling, forward & backward propagation (including cross-correlation) and activation layers. By leveraging the features and performance, it delivers better and faster training performance. CuDNN aims on improving the performance with significantly less memory consumption. After training the system, the model created can be used in any machine.
The basic block diagram of our proposed food system is shown in Fig 1.
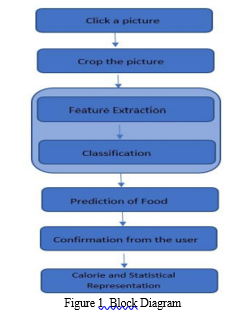
Our proposed system takes the food image as an input, calculates its calories and displays the weekly statistical analysis of the user’s calorie consumption. This helps the user keep a record of his/her calorie intake in check. In the first step, the user clicks the picture of the food item (using a smartphone) whose calorie is to be calculated.
Then the user is made to bound the food image using a bounding rectangle which crops the image. This bounding rectangle is used to remove the unnecessary part (background) of the image and emphasise on the target area. Out of 8,931 images in total, they are separated such that 7,144 images are given for the training purpose (80% of total image) and the remaining 1,787 are sent for testing. We used nVidia graphic card to enhance the training speed as we are working on a huge dataset. The food image clicked by the user is sent for feature extraction purpose. The features extracted in this step are shape, size and colour respectively. The feature extraction process is performed to make the whole model easier to interpret and to reduce overfitting. On these feature vectors, filtering is done. Then classification is performed on these feature vectors to classify these images into its respective categories. Name of the food item is then predicted, after which a question is popped to the user for the purpose of confirmation of the predicted food item. If the prediction is wrong, user will specify the food category. If the prediction is correct, system then prompts the user to give the quantity of the predicted item to be consumed by the user. Using that value, system calculates and generates the calorie count. Calculation of the calories is done by using the quantity input taken from the user and mathematically calculating the corresponding values for it. Calorie count for some fixed quantity is stored in a csv file from which the values are fetched and are used for final calorie estimation of the users’ food. This application keeps record of food items consumed and displays a weekly statistical analysis to the user which helps user to control his/her consumption to avoid obesity-related diseases. I
TABLE II. COMPARISON FOR DIFFERENT DATASETS WITH PROPOSED SYSTEM
|
Combined Dataset FooDD Dataset |
|
Training Accuracy 93.29 % 95.45% |
|
Testing Accuracy 78.7% 96.16% |
As shown in the table above, our combined dataset (FooDD and Food101) showed a training accuracy of 93.29% whereas FooDD dataset showed an accuracy of 95.45%. And in the testing stage, our proposed system gave an accuracy of 78.7% whereas the FooDD dataset gave an accuracy of 96.16%. Hence it was observed that the dataset we used by combining the two datasets gave less accuracy as compared to the FooDD dataset and relatively higher accuracy than the Food101. This was because the images in the FooDD dataset are noise-less data and are less complex whereas the images in the Food101 dataset are the images taken from internet which contains huge amount of noisy data including background and unnecessary objects in it.
Conclusion
Despite the big importance of food classification systems, the current number of studies and improvements are still too limited. The main drawback is the lack of big and international databases, which are necessary to train the algorithms. Also, new methods can help to improve the performance on available databases. This work overviews the main algorithms used for food classification, it details the databases of food items currently available and it presents the results of several deep learning algorithms, considering both the best-shot performance as well as the average over five trials. In the best shot performance experiment, this paper reaches the state-of-the-art accuracy of 90.02% on the UEC Food-100 database, improving the previous record by 0.44 percentage points. However, since all methods are very sensitive to the choice of the training and test sets, we believe that comparison based on the average performance over 5-trials is more appropriate. With the best of our knowledge, this is the first work, which reports the accuracy averaged over 5-trials on the UEC Food100 and it can be used as benchmark.
References
[1] Almaghrabi, R, Villalobos, G, Pouladzadeh, P & Shirmohammadi, S 2012, ‘A Novel Method for Measuring Nutrition Intake Based on Food Image’, Proceedings of the International Conference on Instrumentation and Measurement Technology, pp.366-370. [2] Angulo N´u˜nez 2002, ‘Rule Extraction from Support Vector Machines’, Proceedings of Europian Symposium Artificial Neural Network, pp 291–296. [3] Bandini, L, Must, A, Cyr, H, Anderson, S, Spadano, J & Dietz, W 2003, ‘Longitudinal Changes in the Accuracy of Reported Energy Intake in Girls 10-15 Years of Age’, American Journal of Clinical Nutrition, vol. 78, pp. 480–484. [4] Baumberg, A 2000, ‘Reliable Feature Matching Across Widely Separated Views’, Proceedings of Conference on Computer Vision and Pattern Recognition, pp. 774–781. [5] Bellazzi, R 2008, ‘Telemedicine and Diabetes Management: Current Challenges and Future Research Directions’, Journal of Diabetes Science Technology, vol. 2, no. 1, pp. 98–104. [6] Bellazzi, R, Larizza, C, Magni, P, Montani, S & Stefanelli, M 2000, ‘Intelligent Analysis of Clinical Time Series: An Application in the Diabetes Mellitus Domain’, Artificial Intelligence in Medicine, vol. 20, pp. 37–57. [7] Bifet, A & Ricard, G 2008, ‘Mining Adaptively Frequent Closed Unlabeled Rooted Trees in Data Streams’, In Proceedings of the 14th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, pp. 34-42. [8] Bottou, L, Cortes, C, Denker, J, Drucker, H, Guyon, I, Jackel, L, LeCun, Y, Muller, U, Sackinger, E, Simard, P & Vapnik, V 1994, ‘Comparison of Classifier Methods: A Case Study in Handwriting Digit Recognition’, Proceedings of the International Conference on Pattern Recognition, pp. 77–87. [9] Brown, M & Lowe, DG 2002, ‘Invariant Features from Interest Point Groups’, Proceedings of British Machine Vision Conference, pp.656– 665. [10] Brown, N, Julia, C, Paul, B, Mary, M & Nigel, U, 2012, ‘Risk Scores Based on Self-Reported or Available Clinical Data to Detect Undiagnosed Type 2 Diabetes: A Systematic Review’, Diabetes Research and Clinical Practice, vol. 98, no. 3, pp. 369-385. [11] Buijsse, B, Simmons, RK, Griffin, SJ & Schulze, MB 2011, ‘Risk Assessment Tools for Identifying Individuals at Risk of Developing Type 2 Diabetes’, Epidemiologic reviews, vol.33, no.1, pp. 46-62. [12] Bulut, A & Singh, AK 2005, ‘A Unified Framework for Monitoring Data Streams in Real Time’, in Proceedings of the 21st Internatioal Conference on Data Engineering (ICDE), pp.44-55. [13] Catley, C, Stratti, H & McGregor, C 2008, ‘Multi-Dimensional Temporal Abstraction and Data Mining of Medical Time Series Data: Trends and Challenges’, 30th Annual International IEEE EMBS Conference, pp. 4322-4325. [14] Chang-Shing Lee, Mei-Hui Wan & Hani Hagras 2010, ‘A Type-2 Fuzzy Ontology and Its Application to Personal Diabetic-Diet Recommendation’, IEEE Transactions on Fuzzy Systems, vol. 18, no. 2, pp-374-395. [15] Chen Chun-Hao, Tzung-Pei Hong & Shih-Bin Lin 2011, ‘Mining Fuzzy Temporal Knowledge from Quantitative Transactions’, In Proceedings of the International Conference on System Science and Engineering (ICSSE), pp. 405-409. [16] Chen, DG, Wang, XZ, Yeung, DS & Tsang, ECC 2006, ‘Rough Approximations on a Complete Completely Distributive Lattice with Applications to Generalized Rough Sets’, Information Sciences, vol. 176, pp. 1829-1848. [17] Chen, M, Dhingra, K, Wu, W, Sukthankar, R & Yang, J 2009, ‘PFID: Pittsburgh Fast-Food Image Dataset’, Proceedings in the 16th IEEE International Conference in Image Processing, pp.289-292. [18] Chil, PY, Chen, JH, Chu, HH & Lo, JL 2008, ‘Enabling Calorie- Aware Cooking in a Smart Kitchen’, Computing 2008 Springer- Verlag, vol. 5033, pp. 116-127. [19] Chu Chun-Jung, Vincent S Tsengb & Tyne Lianga 2009, ‘Efficient Mining of Temporal Emerging Itemsets from Data Streams’, Journal of Expert Systems with Applications, vol. 36, no. 1, pp. 885-893. [20] Cios, KJ & Moore, GW 2002, ‘Uniqueness of Medical Data Mining’, Journal of Artificial Intelligence in Medicine’, vol. 26, no. 1-2, pp.1-24. [21] Dee Miller, L & Leen-Kiat Soh 2015, ‘Cluster Based Boosting’, IEEE Transactions on Knowledge and Data engineering, vol.27, no.6, pp.1491-1504. [22] Ding, C & Peng, H 2005, ‘Minimum Redundancy Feature Selection from Microarray Gene Expression Data’, Journal of Bioinformatics Computation Biology, vol. 3, no. 02, pp. 185–205. [23] Dubois, D & Prade, H 1992, ‘Putting Rough Sets and Fuzzy Sets Together’, Intelligent Decision Support, Handbook of Applications and Advances of the Rough Sets Theory, Kluwer Academic Publishers, pp. 203-232. [24] Duda, RO & Hart, P 1973, ‘Pattern Classification and Scene Analysis’, John Wiley and Sons. [25] Durairaj, M & Kalaiselvi, G 2015, ‘Prediction of Diabetes Using Soft Computing Techniques’, International Journal of Scientific & Technology Research, vol. 4, no.3, pp.190-192. [26] Elizabeth, DS, Kannan, A & Nehemiah, HK 2009, ‘Computer?aided Diagnosis System for the Detection of Bronchiectasis in Chest Computed Tomography Images’, Proceedings in International Journal of Imaging Systems and Technology, vol. 19, no.4, pp.290-298. [27] Elizabeth, DS, Nehemiah, HK, Retmin Raj, CS & Kannan, A 2012, ‘Computer-aided Diagnosis of Lung Cancer Based on Analysis of the Significant Slice of Chest Computed Tomography Image’, IET Image Processing, vol. 6, no.6, pp. 697-705. [28] Euisun Choi & Chulhee Lee 2001, ‘Optimizing Feature Extraction for Multiclass Problems’, Proceedings of IEEE Transactions on Geoscience and Remote Sensing, vol. 39, no. 3, pp.521-528. [29] Fei, H, Hua-min, Y & Li-guo, F 2012, ‘A Novel Algorithm for Disease Diagnosis’, Proceedings of International Conference on Computer Science and Network Technology, pp. 29-31.
Copyright
Copyright © 2024 Dhanashree Phalke , Vishakha Metre , Adishri Kadam, Aman Singh , Khushi Magotra, Adishri Kadam. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET60380
Publish Date : 2024-04-15
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online