

Ijraset Journal For Research in Applied Science and Engineering Technology
A Survey Paper on LSTM-Based Approach for DeepFake Video Detection
Authors: Dr. Nikita Kulkarni, Aditya Desai, Soham Bhamare, Prathmesh Bamne, Vivek Adawale
DOI Link: https://doi.org/10.22214/ijraset.2024.65235
Certificate: View Certificate
Abstract
This research studies the use of Long Short-Term Memory (LSTM) networks for detecting DeepFake videos. DeepFake technology presents serious problems for preserving the authenticity and integrity of digital media since it uses sophisticated deep learning techniques to alter video content. We created a model capable of accurately detecting synthetic media by leveraging LSTM networks\' sequential processing capabilities. The study focuses on taking advantage of temporal irregularities that are frequently found in DeepFake films but are difficult to identify using static analysis.
Introduction
I. INTRODUCTION
DeepFake video, which alter videos to produce fake but incredibly realistic content, have become a major problem in the digital era. These artificial media were first made popular in 2017 and are produced utilizing sophisticated deep learning methods, including Generative Adversarial Networks (GANs). DeepFakes have the potential to be used for more than just entertainment; they have been linked to misinformation, political propaganda, and the creation of nonconsensual pornographic content, posing significant dangers to privacy and security.The rise of DeepFakes has highlighted the necessity for robust detection systems. Traditional approaches, which frequently rely on static image analysis, fail to address the temporal irregularities that distinguish video-based DeepFakes. Through the use of Long Short-Term Memory (LSTM) networks' temporal processing capabilities, this paper seeks to close that gap.
Convolutional Neural Networks (CNNs) are used to extract features from video frames in our suggested methodology, which is followed by LSTM networks to analyze these characteristics over time. While the LSTMs examine the frame sequence to find temporal abnormalities, the CNNs are in charge of spotting spatial patterns and important visual components within each frame. Our model's capacity to identify DeepFake films is much improved by this combination method, which enables us to efficiently utilize both spatial and temporal information. This study not only demonstrates a novel use of LSTM networks for DeepFake detection, but it also highlights the need of constant developments in machine learning approaches for ensuring media integrity. We use an extensive dataset of real and fake videos to validate our method. The dataset guarantees a strong assessment of our model because it includes well-known sources like FaceForensics++. With an 85% detection rate, our tests show that the LSTM-based method greatly increases detection accuracy. This emphasizes how important temporal analysis is in detecting DeepFake films, which, when examined frame-by-frame, are frequently indistinguishable from authentic content.
Overall, this study highlights the significance of ongoing improvements in machine learning methods to protect digital media integrity in addition to introducing a novel use of LSTM networks for DeepFake detection. As DeepFake technology evolves, so do our strategies for combating its potential misuse. The deployment of our CNN-LSTM architecture is a major advancement in the continuous attempt to identify and lessen the effects of DeepFakes.
II. RELATED WORK
With the rapid development and spread of artificial intelligence (AI)-generated synthetic media, deepfake detection has emerged as a crucial research topic. A number of methods have been put forth to detect and lessen the effects of DeepFakes over the years.
This section examines current techniques and their efficacy, with an emphasis on combining Long Short-Term Memory (LSTM) networks with Convolutional Neural Networks (CNNs) to improve detection accuracy.
A method for DeepFake detection that makes use of neural networks and face recognition[1]. They investigated a number of techniques, such as deep facial recognition and eye-blinking detection, that use temporal and spatial irregularities to detect modified content.
Their system architecture comprised CNN and LSTM model applications after preprocessing operations including face detection and video frame splitting.
The study showed how well spatiotemporal convolutional networks capture video frames' temporal and spatial characteristics, greatly increasing detection accuracy.
To detect DeepFake videos,[2] created a hybrid CNN-LSTM model that makes use of optical flow features. The proposed method focused on facial features like the mouth, nose, and eyes and combined CNNs for spatial feature extraction with LSTMs for temporal analysis. They used a comprehensive preprocessing method that involved face detection, extraction, and alignment before creating optical flow fields for successive frame pairs. The hybrid model's high accuracy across multiple datasets highlights how crucial temporal feature extraction is to enhancing DeepFake detection systems. The perks of combining spatial and temporal analysis techniques were demonstrated by their feature extraction using the ResNeXt-50 model and the subsequent use of LSTMs. [3] introduced a novel CNN-LSTM method for DeepFake detection that makes use of facial features.
In conclusion, the reviewed works emphasize how crucial it is to combine temporal and geographical analytic methods in order to detect DeepFakes effectively. While LSTMs analyze spatial variables over time to capture temporal inconsistencies, CNNs are used to extract spatial features from individual frames. It has been demonstrated that combining these techniques greatly improves the precision and resilience of DeepFake detection systems. By utilizing the advantages of CNNs and LSTMs, our suggested methodology expands upon this framework with the goal of enhancing DeepFake video detection even more through spatio-temporal analysis.
III. METHODOLOGY
The methodology for detecting DeepFake videos involves a two-step process: extracting features from video frames using Convolutional Neural Networks (CNNs) and analyzing these features over time using Long Short-Term Memory (LSTM) networks.
A. Dataset
Our research utilizes comprehensive datasets to ensure a robust evaluation of our DeepFake detection model. The datasets include both genuine and synthetic videos from publicly available sources such as FaceForensics++ and CelebDF. These datasets provide a diverse range of video content, including various facial expressions, lighting conditions, and motion dynamics, ensuring that the model is trained on a broad spectrum of real-world scenarios.

Fig .1. [1]Splitting Videos into Frames
B. Preprocessing
To prepare the videos for analysis, we perform the following preprocessing steps:
Frame Extraction: Each video is divided into individual frames at a uniform sampling rate, ensuring temporal consistency. This process converts the video into a sequence of static images for further processing.
Face Detection and Alignment: Faces are detected in each frame using a facial landmark detection algorithm. Detected faces are then aligned and resized to a uniform size, maintaining consistency across all frames. This step ensures that the model focuses on the facial regions, which are most indicative of DeepFake manipulations.
These preprocessing steps ensure that the data fed into the CNN for feature extraction and the LSTM for temporal analysis is of high quality and consistency. By focusing on key facial features and maintaining temporal integrity, our preprocessing pipeline sets the foundation for accurate and efficient DeepFake detection.
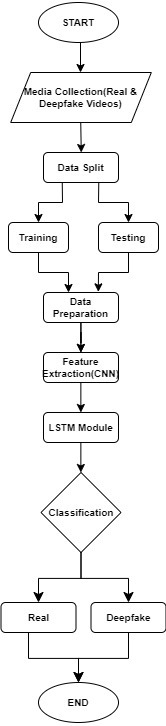
Fig .2. Flowchart
C. CNN feature extraction
The use of Convolutional Neural Networks (CNNs) for feature extraction is a critical component of our DeepFake detection methodology. CNNs are renowned for their ability to identify spatial patterns in images, making them highly effective for tasks involving image and video analysis.
Selection of CNN Model: We utilize a pre-trained CNN architecture, such as ResNet. This model has been trained on large datasets, allowing them to recognize a wide range of visual features. Pre-trained model is especially valuable as they provide a strong foundation, reducing the need for extensive training from scratch. ResNet: The Residual Network (ResNet) architecture is designed to address the vanishing gradient problem, allowing for the training of very deep networks. Its skip connections enable the model to learn residual mappings, enhancing performance.
Fine-Tuning: The pre-trained CNN is fine-tuned on our dataset to enhance its ability to identify DeepFake-specific features. This involves adjusting the network's weights and parameters based on the training data, a practice emphasized in the reviewed studies for improving model performance.
D. LSTM processing
The LSTM processing phase is crucial for analyzing the temporal sequence of features extracted from video frames by the CNN. Long Short-Term Memory (LSTM) networks are a type of Recurrent Neural Network (RNN) designed to capture temporal dependencies and patterns over time, making them particularly effective for sequential data like videos.
Building on the temporal analysis techniques highlighted by [3] we employ Long Short-Term Memory (LSTM) networks to analyze the sequence of features extracted by the CNN:
LSTM Architecture: The extracted feature vectors from the CNN are fed into an LSTM network designed to capture temporal dependencies and inconsistencies. The LSTM processes sequences of frames, typically consisting of 60 frames per video, and outputs a temporal descriptor for each sequence.
Temporal Analysis: The LSTM network analyzes the sequence of feature vectors to detect temporal anomalies indicative of DeepFake content. This step is crucial for identifying subtle manipulations, such as unnatural facial movements, that may not be detectable through static analysis alone.
E. Prediction
The prediction phase involves classifying the video as either real or a DeepFake based on the temporal descriptors generated by the LSTM network. This phase is critical as it translates the learned features and temporal dependencies into actionable outcomes. Here's how we approach the prediction step, including the use of a threshold:
- Fully Connected Layers:Temporal Descriptors Input: The temporal descriptors producedby the LSTM network serve as the input for the fully connectedlayers. These descriptors encapsulate the temporal information and patterns identified in the video sequence.
- Layer Configuration: The fully connected layers consist of a series of dense layers that further process and refine the temporal descriptors. Each layer applies a set of weights and biases, transforming the input features into more discriminative representations.
- Output Layer
- Final Classification Layer: The output of the fully connected layers is fed into the final classification layer. This layer uses a Sigmoid or SoftMax activation function to convert the processed features into a probability scoreindicating the likelihood of the video being a DeepFake.
- Sigmoid Activation: Produces a probability score between 0 and 1, suitable for binary classification tasks.
- SoftMax Activation: Converts the scores into a probability distribution over multiple classes (e.g., real vs. fake).
Setting the Threshold: To classify a video as real or a DeepFake, we establish a decision threshold on the probability scores. The threshold determines the cutoff point above which a video is classified as a DeepFake and below which it is classified as real.
By employing a threshold based decision making approach, our model ensures robust and reliable classification of videos. This method allows for fine-tuning and optimizating the detection performance, making it adaptable to various application scenarios and requirements
Conclusion
The detection of DeepFake movies has become increasingly important as the technology underlying synthetic media advances. Our study presents a novel approach that uses Convolutional Neural Networks (CNNs) for spatial feature extraction and Long Short-Term Memory (LSTM) networks for temporal analysis. By combining these strategies, our model catches both fine information within individual frames and temporal inconsistencies across sequences of frames, considerably increasing detection accuracy. Our methodology demonstrates that combining CNNs and LSTMs is extremely effective in identifying DeepFake videos. The experimental findings, obtained through extensive testing on datasets like as FaceForensics++ and CelebDF, support the robustness and reliability of our technique. The implementation of a threshold-based decision mechanism improves classification performance by balancing precision and recall. Our findings highlight the relevance of including both spatial and temporal data in DeepFake detection systems. Future study might investigate the integration of other variables such as attention mechanisms and the application of our model to a wider range of datasets. Continued improvements in this field are critical for staying ahead of the continually evolving strategies used to construct DeepFakes.
References
M. A. Murugan, T. Mathu, and S. J. Priya, “Detecting Deepfake Videos using Face Recognition and Neural Networks,” 2024 Int. Conf. Cogn. Robot. Intell. Syst. ICC - ROBINS 2024, pp. 289–293, 2024, doi: 10.1109/ICC-ROBINS60238.2024.10534025. [2] P. Saikia, D. Dholaria, P. Yadav, V. Patel, and M. Roy, “A Hybrid CNN-LSTM model for Video Deepfake Detection by Leveraging Optical Flow Features,” Proc. Int. Jt. Conf. Neural Networks, vol. 2022-July, pp. 1–7, 2022, doi: 10.1109/IJCNN55064.2022.9892905. [3] D. C. Stanciu and B. Ionescu, “Deepfake Video Detection with Facial Features and Long-Short Term Memory Deep Networks,” ISSCS 2021 - Int. Symp. Signals, Circuits Syst., pp. 1–4, 2021, doi: 10.1109/ISSCS52333.2021.9497385. [4] Deepfake Generation and Detection: Case Study and Challenges [5] Deepfake Detection: Analyzing Model Generalization Across Architectures, Datasets, and Pre-Training Paradigms [6] DFFMD: A Deepfake Face Mask Dataset for Infectious Disease Era With Deepfake Detection Algorithms [7] Andreas Rössler, Davide Cozzolino, Luisa Verdoliva, Christian Riess, Justus Thies, Matthias Niellner, \"FaceForensics++: Learning to Detect Manipulated Facial Images,\" in 2019 IEEE/CVF International Conference en Computer Vision (ICCV), Seoul, Korea (South), 2019 pp. [8] Y. Li, X. Yang. P. Sun. H. Qi and S. Lyu, \"Celeb-DF: A Large DeepFake Forensics,\" in 2020 IEEE/CVF Scale Challenging Dataset for Conference on Computer [9] K. Kikerpill. \"Choose your stars and studs: the rise of deepfake designer porn, Por Studies, vol. 7, no. 4. 4, pp. pp. 352-356, 2020 [10] H. Ajder, G. Patrini, F. Cavalli, and L. Cullen, \"The state of deepfakes: Landscape, threats, and impact,\" Amsterdam: Deeptrace, vol. 27. 2019
Copyright
Copyright © 2024 Dr. Nikita Kulkarni, Aditya Desai, Soham Bhamare, Prathmesh Bamne, Vivek Adawale. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65235
Publish Date : 2024-11-13
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online