

Ijraset Journal For Research in Applied Science and Engineering Technology
Advancements in Natural language Processing: An In-depth Review of Language Transformer Models
Authors: Ritesh Kumar Singh, Deepanshu Rana
DOI Link: https://doi.org/10.22214/ijraset.2024.63408
Certificate: View Certificate
Abstract
This review paper provides a succinct exploration of the history and impact of language transformer models in natural language processing (NLP). Beginning with a literature review, we trace the evolution of key models and elucidate fundamental concepts like self-attention mechanism and positional encoding. A comparative analysis of major transformer models, including BERT, GPT, T5, XLNet, offers insights into their architectures, strengths, and weaknesses. The discussion extends to pre-training objectives, fine-tuning strategies, and evaluation metrics, complemented by real-world examples of successful applications in NLP. We address current challenges, discuss potential future directions, and explore ethical considerations, providing valuable suggestions for researchers and practitioners in the NLP community in our conclusive summary.
Introduction
I. INTRODUCTION
In the realm of natural language processing (NLP), the advent of transformer-based language models represents a
paradigm shift. This review delves into the historical evolution and impact of these models, spotlighting their significance in NLP. The pivotal moment in 2017, with the unveiling of the Transformer architecture by Vaswani et al., triggered a surge in research, yielding diverse language models that redefine natural language interpretation.
Transformer models, exemplified by GPT and BERT, transcend conventional benchmarks, showcasing adaptability across a spectrum of NLP applications. Moving through the review, a critical evaluation traces the conceptual currents shaping fundamental language models, exploring notions from self-attention mechanisms to the original Transformer architecture. The subsequent deep dive into models like BERT and GPT provides a comparative analysis, considering their topologies, merits, and limitations.
Beyond technical intricacies, the review sheds light on pre- training objectives, emphasizing the impact of masked and causal language modelling. Fine-tuning strategies, illuminated by real-world case studies, underscore the practical adaptability of pre-trained models to diverse downstream tasks. Addressing the limitations of existing assessment metrics, the paper explores various applications of language models in NLP, from text generation to sentiment analysis, through real-world examples.
II. LITERATURE REVIEW
In the field of natural language processing (NLP), language models (LMs) play a central role, aiding tasks like sentiment analysis and machine translation. The combination of advanced neural networks and expansive datasets has propelled language modelling research, notably impacting recent advancements. Early statistical techniques, such as N- gram models, set the stage for language modelling, yet struggled with contextual nuances. The introduction of recurrent neural networks (RNNs) marked a transformative era, significantly enhancing language understanding.
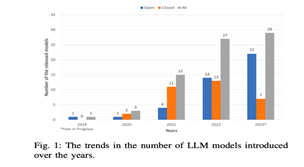
Recent research highlights language models' capabilities in diverse NLP applications, leading to a surge in multifaceted contributions. Covering topics ranging from robotics to efficient training techniques, these studies underscore the intricate landscape of language models and Large Language Models (LLMs). Navigating advanced subjects at the forefront of language models, our comprehensive review consolidates insights from in-depth analyses, serving as a valuable resource for scholars and professionals and propelling the Language Model studies forward.
Acknowledging the seminal contribution of Vaswani et al. in crafting the Transformer architecture (2017), our review illuminates its revolutionary impact on natural language processing. Models like GPT and BERT, offspring of the Transformer architecture, stand as cornerstones in contemporary NLP networks, outperforming predecessors. Delving into auto-encoder architectures (BERT, RoBERTa, ALBERT) and auto-regressive models (GPT, GPT-2, XLNET), our study underscores their exemplary performance across diverse NLP tasks, showcasing the efficiency and adaptability of Transformer-based techniques in capturing intricate language patterns and semantics.
A focused exploration into Transformer variations, known as X-formers, fills a crucial gap in the literature, spanning audio processing, computer vision, and NLP. The article establishes a taxonomy considering applications, pre- training techniques, and architectural alterations, providing clarity for researchers in these interdisciplinary domains. Additionally, our review introduces a pioneering application of BERT for document categorization, showcasing state-of- the-art results. BERT's success in various tasks, coupled with proposed knowledge distillation methods for computational efficiency, reinforces its position as a pioneering deep language representation model. In summary, our literature review seamlessly navigates the intricate landscape of language models, from historical perspectives to contemporary breakthroughs, providing a comprehensive resource for researchers and practitioners alike.
III. FUNDAMENTAL CONCEPTS
A. N-gram Models
N-gram models are a type of probabilistic language model that predicts the likelihood of the next word in a sequence based on the context of the preceding N-1 words. The probability is computed using co-occurrence statistics.
Contextual Prediction: N-gram models assume that the probability of a word depends only on the previous N-1 words. For example, in a bigram model (N=2), the probability of a word is predicted based on the preceding word.
Probability Computation: The probability of a word sequence is calculated using the formula:


IV. MAJOR TRANSFORMER MODELS: IN-DEPTH REVIEW AND COMPARATIVE ANALYSIS
A. BERT (Bidirectional Encoder Representations from Transformers)
BERT, introduced by Google in 2018, marked a significant advancement in NLP by pre-training bidirectional representations of text. Its architecture comprises an encoder-only Transformer with multiple layers. One of BERT's strengths lies in its ability to capture contextual information bidirectionally, leading to superior performance in tasks requiring understanding of context, such as question answering and sentiment analysis. However, BERT's main weakness is its computational intensity and memory requirements, especially for larger models like BERT-large, which limits its practical applicability in resource-constrained environments.
B. GPT (Generative Pre-trained Transformer)
GPT, developed by OpenAI, focuses on generating coherent and contextually relevant text. Its architecture includes a decoder-only Transformer with a stack of self-attention layers. GPT excels in tasks like text generation and completion due to its autoregressive nature, where it predicts the next token based on previously generated tokens.
However, GPT's unidirectional nature restricts its ability to effectively utilize context from both past and future tokens, which can lead to issues with long-range dependencies and coherence in generated text.
C. T5 (Text-to-Text Transfer Transformer)
T5, introduced by Google in 2019, presents a unified framework where all NLP tasks are formulated as text-to-text tasks. Its architecture combines encoder-decoder Transformer layers, enabling it to handle a wide range of tasks through fine-tuning. T5's strength lies in its versatility and simplicity, as it offers a single architecture for diverse NLP tasks, promoting easier experimentation and transfer learning. However, T5's performance can vary based on task complexity, and it may require substantial fine-tuning for optimal results in specific domains.
D. XLNet (eXtreme Learning with Large-scale Language Models)
XLNet, proposed by Google in 2019, innovatively integrates ideas from both autoregressive models like GPT and autoencoding models like BERT. Its architecture leverages permutations of input sequences during pre-training, enabling it to capture bidirectional context without the drawbacks of masked language modeling. XLNet excels in capturing long-range dependencies and understanding nuanced relationships in text. However, its complexity and computational demands can pose challenges in training and deployment, particularly for large-scale models.
E. Comparative Analysis
When comparing these major transformer models, several key factors come into play. BERT's bidirectional approach enhances contextual understanding but comes with high computational costs. GPT's autoregressive nature enables
coherent text generation but struggles with long-range dependencies. T5's unified framework offers versatility but may require extensive fine-tuning. XLNet's innovative permutation strategy balances bidirectionality and coherence but demands significant computational resources. In summary, each major transformer model brings unique strengths and weaknesses to the table, catering to different NLP requirements and computational constraints. Understanding these nuances is crucial for selecting the most suitable model for specific tasks and optimizing performance in practical applications.
V. PRE-TRAINING OBJECTIVES: IMPACT ON MODEL PERFORMANCE
A. Introduction to Pre-training Objectives
Pre-training objectives play a crucial role in shaping the capabilities and performance of language transformer models. These objectives define the tasks that the model must solve during the pre-training phase, which involves learning general linguistic patterns and representations from large unlabeled text corpora. Two prominent pre-training objectives widely used in language transformer models are Masked Language Modeling (MLM) and Causal Language Modeling (CLM).
B. Masked Language Modeling (MLM)
In MLM, a certain percentage of tokens in the input sequence are masked (replaced with a special token) during pre-training, and the model is trained to predict the original tokens based on the context provided by the surrounding tokens. BERT is a notable example of a transformer model that uses MLM as its pre-training objective.
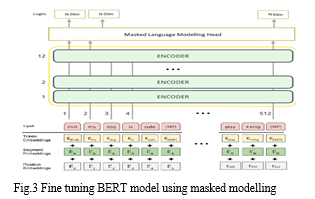
C. Impact on Model Performance:
MLM encourages the model to understand bidirectional context and dependencies within a sentence or text snippet, leading to improved performance in tasks requiring contextual understanding, such as sentiment analysis and named entity recognition.
- Strengths
- Encourages bidirectional context understanding.
- Captures syntactic and semantic relationships within text.
- Enables the model to handle masked tokens during inference, promoting robustness.
2. Weaknesses
- Computational overhead due to masking tokens and predicting them individually.
- May struggle with long-range dependencies and coherence in generated text.
D. Causal Language Modeling (CLM)
CLM, also known as autoregressive language modeling, requires the model to predict the next token in a sequence given the previous tokens. Models like GPT utilize CLM during pre-training, where the decoder-only transformer predicts tokens sequentially based on the context provided by the preceding tokens. CLM focuses on generating coherent and contextually relevant text, making it suitable for tasks like text generation, dialogue systems, and machine translation.
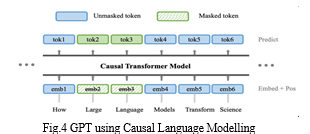
E. Impact on Model Performance
- Strengths
- Promotes coherent text generation with long-range dependencies.
- Captures context from both past and future tokens, enhancing understanding.
- Supports diverse NLP tasks through fine-tuning on downstream datasets.
2. Weaknesses
- Unidirectional nature may limit understanding of bidirectional context.
- Challenges with handling masked tokens or filling in gaps in incomplete sequences.
F. Comparative Analysis and Hybrid Approaches
The strengths and shortcomings of MLM and CLM complement each other. CLM is more concerned with producing coherent text and capturing long-range dependencies, whereas MLM is better at bidirectional context understanding and resilience. In an effort to take use of the advantages of both autoregressive and bidirectional modelling at the same time, researchers have looked into hybrid techniques that include aspects of both goals. XLNet, for instance, incorporates bidirectional context into permutation-based training while preserving coherence through autoregressive generation.
G. Impact of Pre-training Objectives on Model Diversity
The choice of pre-training objectives significantly influences the diversity of model capabilities and performance characteristics. For instance, models trained with MLM may excel in understanding contextual relationships within sentences due to their bidirectional nature. In contrast, CLM-focused models may be better suited for generating fluent and coherent text, emphasizing the autoregressive nature of the training objective. Therefore, selecting the appropriate pre-training objective depends on the intended downstream tasks and the desired balance between contextual understanding and generative capabilities.
H. Future Directions in Pre-training Objectives
Future research in pre-training objectives explores novel approaches that address current limitations and enhance model performance across various NLP tasks. Potential directions include:
- Incorporating self-supervised learning tasks beyond language modeling, such as knowledge graph completion or commonsense reasoning.
- Designing adaptive pre-training objectives that dynamically adjust based on the input data characteristics or task requirements.
- Exploring multi-task learning frameworks that combine multiple pre-training objectives to encourage broader model capabilities and transfer learning across diverse tasks.
In conclusion, pre-training objectives significantly influence the capabilities and performance of language transformer models.
VI. FINE-TUNING STRATEGIES FOR LANGUAGE TRANSFORMER MODELS
A. Introduction to Fine-Tuning
The method of fine-tuning involves learning task-specific information from labelled data and changing model parameters to tailor pre-trained language transformer models to particular downstream tasks. By utilising the broad knowledge and linguistic representations acquired during pre-training, this method improves the performance of the model on specific tasks like named entity recognition, text classification, and sentiment analysis.
B. Fine-Tuning Approaches
- Task-Specific Heads Replacement: One common fine-tuning strategy involves replacing the task-agnostic heads (e.g., classification or regression heads) of the pre-trained model with task-specific heads tailored to the downstream task. This approach allows the model to focus on learning task-specific features during fine-tuning while retaining the pre-trained knowledge.
- Layer Freezing and Gradual Unfreezing: Fine-tuning may also involve freezing certain layers of the pre-trained model initially and gradually unfreezing them during training. This technique helps in preserving important linguistic representations learned during pre-training while allowing task-specific information to be learned in the unfrozen layers.
- Multi-Task Fine-Tuning: Another approach is multi-task fine-tuning, where the model is fine-tuned on multiple related tasks simultaneously. This encourages the model to learn shared representations across tasks, leading to improved generalization and performance on diverse tasks.
C. Real-World Case Studies
- Sentiment Analysis with BERT: A common application of fine-tuning is sentiment analysis, where the goal is to classify the sentiment (positive, negative, neutral) of text. Researchers have successfully fine-tuned BERT for sentiment analysis tasks across various domains, achieving state-of-the-art performance. By fine-tuning BERT on sentiment-labeled datasets and adopting task-specific heads, models can accurately classify sentiment in customer reviews, social media posts, and product feedback.
- Named Entity Recognition (NER) with GPT-3: GPT-3, known for its generative capabilities, has also been fine-tuned for named entity recognition tasks. By fine-tuning GPT-3 with task-specific heads and annotated NER datasets, researchers have demonstrated its effectiveness in accurately identifying and categorizing named entities such as persons, organizations, and locations in text data. This fine-tuned model has applications in information extraction, entity linking, and document analysis tasks.
- Text Generation for Chatbots using T5: T5's text-to-text framework lends itself well to fine-tuning for text generation tasks, particularly in building conversational chatbots. By fine-tuning T5 on dialogue datasets and employing task-specific prompts, developers have created chatbot models capable of engaging in meaningful conversations, answering user queries, and providing personalized responses based on context.
VII. MODEL EVALUATION METRICS FOR LANGUAGE TRANSFORMER MODELS
A. Introduction to Evaluation Metrics
Evaluating the performance of language transformer models requires the use of appropriate metrics that assess various aspects such as accuracy, fluency, coherence, and robustness. Commonly used evaluation metrics provide insights into model capabilities and guide improvements in NLP systems. However, it's essential to critically analyze these metrics to understand their strengths and limitations.
B. Commonly Used Evaluation Metrics
- Accuracy and Precision: Accuracy measures the percentage of correct predictions made by the model on a given task or dataset. Precision evaluates the proportion of true positive predictions among all positive predictions, providing insight into the model's ability to make accurate classifications or identifications.
- Recall and F1 Score: Recall calculates the percentage of true positives identified by the model out of all actual positives in the dataset. The F1 score, a harmonic mean of precision and recall, balances between precision and recall, offering a comprehensive evaluation of model performance, especially in imbalanced datasets.
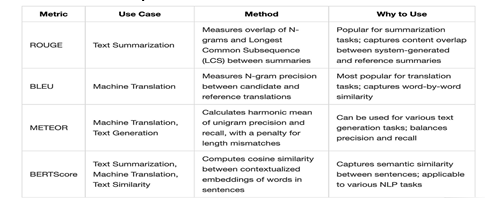
- BLEU (Bilingual Evaluation Understudy): BLEU assesses the quality of generated text in machine translation tasks by comparing n-grams (sequences of n words) between the generated output and reference translations. Higher BLEU scores indicate better correspondence with reference translations, although it has limitations in capturing semantic meaning and fluency.
- ROUGE (Recall-Oriented Understudy for Gisting Evaluation): ROUGE measures the overlap of n-grams between the model-generated summaries and human-written summaries in tasks like text summarization. It provides insights into the informativeness and coherence of generated summaries but may not capture semantic understanding comprehensively.
- Perplexity: Perplexity evaluates the uncertainty or unpredictability of a language model based on how well it predicts a given sequence of tokens. Lower perplexity scores indicate better model performance in terms of language modeling and text generation tasks.
- Word Error Rate (WER): WER is commonly used in speech recognition tasks to measure the rate of incorrect words generated by the model compared to the reference transcripts. It quantifies the accuracy of the model's transcription but may not reflect semantic or contextual errors accurately.
C. Limitations of Existing Evaluation Metrics
- Limited Semantic Understanding: Many evaluation metrics, such as BLEU and ROUGE, focus on surface-level characteristics like n-gram overlap, which may not capture the model's semantic understanding or contextual coherence accurately. This limitation is particularly evident in tasks requiring nuanced language comprehension.
- Domain Specificity: Evaluation metrics often vary in effectiveness across different domains and languages. Metrics that perform well in one domain may not generalize effectively to other domains, highlighting the need for domain-specific evaluation strategies.
- Human Subjectivity: Metrics like accuracy and precision rely on labeled data or human annotations, introducing subjectivity and potential biases in evaluation. Human evaluation remains essential for assessing complex linguistic tasks but can be resource-intensive and subjective.
- Lack of Diversity Metrics: Existing metrics may overlook aspects of diversity, creativity, and novelty in generated text, especially in tasks like text generation and dialogue systems. Evaluating models based solely on standard metrics may not capture their full expressive capabilities.
- Task-Specific Metrics: Some tasks require specialized evaluation metrics tailored to specific objectives, such as sentiment analysis accuracy, named entity recognition F1 score, or conversational coherence metrics. Adapting metrics to task requirements enhances evaluation accuracy and relevance.
D. Future Directions in Evaluation Metrics
Addressing the limitations of existing evaluation metrics requires ongoing research and development in several areas:
- Semantic Evaluation: Developing metrics that assess semantic understanding, coherence, and contextual relevance in generated text.
- Domain Adaptation: Designing evaluation strategies that generalize effectively across diverse domains and languages.
- Subjectivity Analysis: Incorporating measures to quantify and mitigate human subjectivity and biases in evaluation.
- Diversity Metrics: Introducing metrics that capture diversity, novelty, and creativity in language generation tasks.
- Task-Specific Evaluation: Creating task-specific evaluation frameworks and metrics for accurate and comprehensive assessment.
VIII. APPLICATIONS AND USE CASES OF LANGUAGE TRANSFORMER MODELS IN NLP
A. Overview of Diverse Applications
Since language transformer models can capture complex verbal patterns, contextual information, and semantic comprehension, they have revolutionised NLP applications in a variety of disciplines.
Among the important applications are:
- Text Generation: Language transformers excel in generating coherent and contextually relevant text, making them invaluable for tasks such as story generation, poetry creation, and content summarization.
- Sentiment Analysis: Analyzing sentiment in text, including sentiment classification (positive, negative, neutral) and sentiment intensity analysis, is a common application of language transformers in tasks like social media monitoring, customer feedback analysis, and brand sentiment tracking.
- Question Answering (QA): QA systems leverage language transformers to understand and respond to user queries, ranging from fact-based questions (e.g., "Who is the president of France?") to complex reasoning tasks (e.g., "What are the implications of climate change on biodiversity?").
- Named Entity Recognition (NER): Identifying and categorizing named entities such as persons, organizations, locations, and dates in text data is a vital application of language transformers, crucial for information extraction, entity linking, and data structuring tasks.
- Text Summarization: Language transformers are used for abstractive and extractive summarization, condensing large volumes of text into concise summaries while preserving key information and context, beneficial for news summarization, document summarization, and content curation.
- Machine Translation: Language transformers play a significant role in machine translation systems, facilitating accurate and context-aware translation between multiple languages, supporting cross-language communication and global content localization efforts.
- Conversational AI: Building conversational agents, chatbots, and virtual assistants that engage in natural language conversations with users is a prominent application of language transformers, enhancing customer support, information retrieval, and interactive user experiences.
B. Real-World Examples and Successful Implementations
- GPT-3 in Content Creation: OpenAI's GPT-3 has been used to generate creative content, including poetry, fiction, and code snippets. For example, AI-powered writing assistants like Sudowrite leverage GPT-3's language generation capabilities to assist writers in generating engaging and grammatically correct text.
- BERT for Sentiment Analysis: Businesses use BERT-based sentiment analysis models to analyze customer feedback on social media platforms. For instance, companies like Hootsuite utilize BERT-powered sentiment analysis tools to monitor brand sentiment, identify customer sentiments, and analyze trends in social media conversations.
- T5 for Text Summarization: Google's T5 model is employed in news aggregation platforms like SummarizeBot, where it generates concise summaries of news articles, providing users with key information and insights without reading the entire content.
4. XLNet for Question Answering: XLNet-based QA systems, such as AllenNLP's Machine Comprehension model, excel in answering complex questions by understanding context and reasoning. These models are utilized in educational platforms and search engines to provide accurate and informative answers to user queries.
5. BART for Text Generation: Facebook's BART model is utilized in dialogue systems and chatbots, such as Facebook Messenger's M suggestions, to generate contextually relevant responses, handle user queries, and assist in natural language interactions.
6. RoBERTa for Named Entity Recognition: RoBERTa-based NER models, like the ones used in medical record analysis systems, accurately identify and categorize medical entities (e.g., diseases, medications) in unstructured text, aiding healthcare professionals in information retrieval and patient care.
7. T5 in Machine Translation: Translation platforms like DeepL utilize T5-based models to provide high-quality and context-aware translations between multiple languages, facilitating cross-border communication and global content localization for businesses and individuals.
IX. CHALLENGES AND FUTURE DIRECTIONS IN LANGUAGE TRANSFORMER RESEARCH
A. Current Challenges in Language Transformer Research:
- Scalability and Efficiency
Large-scale language transformer models, while powerful, face scalability and efficiency issues, including high computational costs, memory requirements, and training times.
For Instance, Training and deploying state-of-the-art models like GPT-3 and T5 require significant computational resources, limiting accessibility and practical deployment in resource-constrained environments.
2. Robustness and Generalization
Language transformers often struggle with robustness and generalization, exhibiting biases, sensitivity to adversarial attacks, and limited performance on out-of-domain data.
For Instance, Models like BERT and RoBERTa have shown biases in gender, race, and culture, highlighting the importance of addressing fairness and bias mitigation in NLP systems.
3. Interpretability and Explainability
Language transformers lack interpretability and explainability, making it challenging to understand model decisions, identify errors, and ensure transparency in AI systems.
For Instance, Healthcare applications of NLP models require interpretability for clinical decision support systems, where understanding model predictions is crucial for medical professionals.
B. Future Directions for Research and Development:
- Efficient Model Architectures:
Developing more efficient and scalable transformer architectures that reduce computational costs, memory footprint, and training time while maintaining performance. Exploring techniques like sparse attention mechanisms, model distillation, and parameter sharing to improve efficiency in large-scale language models.
2. Robustness and Fairness
Addressing biases, improving model robustness against adversarial attacks, and ensuring fairness and inclusivity in language transformer models. Investigating debiasing techniques, adversarial training, and fairness-aware learning to mitigate biases and enhance model reliability across diverse demographics and domains.
3. hancing interpretability and explainability in language transformers to facilitate model understanding, error analysis, and trustworthiness in AI systems.
Developing post-hoc explanation methods, attention visualization techniques, and model introspection tools for transparent decision-making and accountability.
4. Multimodal Transformers
Integrating language transformers with multimodal capabilities to handle text, image, audio, and other modalities for comprehensive understanding and generation.
Advancing multimodal architectures, cross-modal pre-training objectives, and fusion strategies for seamless integration of diverse data types in NLP systems.
5. Continual Learning and Adaptation
Enabling language transformers to learn incrementally from new data, adapt to changing environments, and retain knowledge without catastrophic forgetting.
Exploring lifelong learning techniques, continual adaptation strategies, and domain adaptation approaches for continuous model improvement and adaptation.
6. Ethical and Societal Implications
Addressing ethical concerns, promoting responsible AI practices, and ensuring transparency, accountability, and fairness in language transformer research and deployment.
Collaborative efforts between researchers, policymakers, and industry stakeholders to establish ethical guidelines, governance frameworks, and regulatory standards for AI systems.
X. ETHICAL CONSIDERATIONS IN LANGUAGE TRANSFORMER MODELS
A. Exploration of Ethical Concerns
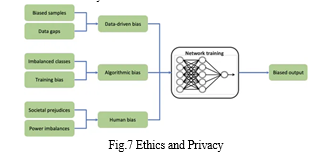
- Bias in Language Transformer Models
Language transformer models, like other AI systems, can exhibit biases inherited from training data, leading to unfair or discriminatory outcomes. Biases can manifest in various forms, including gender bias, racial bias, cultural bias, and socio-economic bias. Biased language models can perpetuate stereotypes, reinforce inequalities, and contribute to societal harm by producing biased predictions, recommendations, or classifications. Studies have highlighted gender bias in word embeddings, racial bias in language models, and cultural biases in machine translation systems.
2. Fairness and Discrimination
Ensuring fairness and mitigating discrimination are crucial ethical considerations in language transformer research. Fairness encompasses equitable treatment, unbiased decision-making, and avoiding unjust discrimination based on protected attributes.
Unfair or discriminatory language models can lead to unequal opportunities, marginalization of certain groups, and erosion of trust in AI systems, particularly in sensitive domains like hiring, lending, and criminal justice.
Cases of biased language models affecting hiring decisions, biased sentiment analysis tools impacting user perceptions, and discriminatory language generation in chatbots.
B. Overview of Efforts to Address Ethical Challenges
- Bias Detection and Mitigation
Researchers and developers employ bias detection tools and techniques to identify biases in language models. Mitigation strategies include data preprocessing to remove biased patterns, debiasing algorithms, and fairness-aware training objectives.
Efforts are directed towards developing robust bias detection methods, quantifying bias severity, and integrating bias mitigation techniques into model training pipelines.
2. Fairness-Aware Learning
Fairness-aware learning frameworks incorporate fairness constraints and objectives into model training, ensuring equitable outcomes across diverse demographic groups.
Researchers explore fairness metrics, fairness regularization techniques, and fairness-aware loss functions to promote fairness and mitigate discrimination in language transformer models.
3. Diverse Representation and Inclusive Data Collection
Promoting diverse representation in training data and ensuring inclusive data collection practices are essential for addressing bias and fairness issues.
Collaborative efforts involve collecting diverse datasets, incorporating diverse perspectives, and engaging with underrepresented communities to improve data quality and reduce biases.
4. Interpretability and Transparency
Enhancing model interpretability and transparency fosters accountability, allows users to understand model decisions, and facilitates error analysis and bias identification.
Techniques such as attention visualization, explanation methods, and model introspection tools enable stakeholders to assess model behavior and detect biases.
5. Ethics Guidelines and Governance
Organizations, research institutions, and industry bodies develop ethics guidelines, best practices, and governance frameworks to guide responsible AI development, deployment, and usage.
Multidisciplinary collaboration involving AI researchers, ethicists, policymakers, and community stakeholders promotes ethical awareness, accountability, and ethical decision-making in AI projects.
C. Examples of Efforts to Address Ethical Challenges
- Google's Responsible AI Practices
Google has implemented guidelines and practices for responsible AI development, including fairness considerations, bias detection tools, and transparency measures in language model research and deployment.
2. Fairness in AI Initiative (FAI)
The Fairness in AI Initiative at Stanford University focuses on advancing fairness-aware learning techniques, promoting transparency, and addressing bias and discrimination in AI systems, including language transformers.
3. BiasMitigation.ai
BiasMitigation.ai is a platform that offers bias detection and mitigation tools for AI developers, including techniques tailored for language models to identify and mitigate biases in text data.
4. AI Ethics Guidelines by IEEE and ACM
Professional organizations like IEEE and ACM provide AI ethics guidelines, codes of conduct, and ethical frameworks for AI practitioners and researchers, emphasizing fairness, transparency, and accountability.
Conclusion
The study of language transformer models demonstrates how they can revolutionize a variety of natural language processing (NLP) applications, such as sentiment analysis, question answering, text production, and machine translation. The capacity of these models to comprehend and produce language that resembles that of a person has created a wealth of opportunities, making them indispensable resources in a variety of fields. Accuracy, precision, recall, F1 score, BLEU, ROUGE, perplexity, and word error rate are just a few of the metrics that must be thoroughly understood to evaluate language transformer models. These metrics have significant limitations, especially in capturing contextual coherence and semantic understanding, even if they offer crucial insights into model performance. To overcome these drawbacks and offer a more comprehensive assessment of model capabilities, future paths in evaluation research will prioritize the creation of more reliable, task-specific, domain-specific measures. Numerous real-world applications have effectively employed language transformer models. Prominent instances comprise the function of GPT-3 in generating imaginative material, the efficacy of BERT in sentiment analysis, and the usefulness of T5 in text summarization and machine translation. These applications highlight the adaptability of the models and their potential to improve information processing, content production, and human-computer interaction. The scalability, robustness, and interpretability of language transformer models remain major issues even with their achievements. For the field to advance, these issues must be resolved. Subsequent investigations will focus on creating more effective structures, strengthening the stability and equity of the models, refining interpretability, and incorporating multimodal functionalities. Furthermore, an increasing focus on ethical issues and ongoing learning is making sure that these models are not only strong but also accountable and reliable. Language transformer model deployment must consider ethical considerations as prejudice, fairness, and openness. To address these problems, organizations such as IEEE and ACM have developed ethical principles, and bias detection and mitigation methodologies and fairness-aware learning frameworks are among the measures taken. Language transformer models must benefit society equally, which is why these projects are essential to promoting ethical AI methods. In summary, language transformer models offer major advantages in a wide range of applications, marking a significant leap in natural language processing. Their sustained success, though, hinges on resolving current ethical, technical, and evaluation issues. The potential of language transformer models may be fully realized, opening the door for more intelligent, equitable, and interpretable AI systems, by expanding research in these areas and encouraging responsible AI practices.
References
[1] H. Naveed, A. U. Khan, S. Qiu, M. Saqib, S. Anwar, M. Usman, N. Akhtar, N. Barnes, and A. Mian, \"A Comprehensive Overview of Large Language Models,\" 2024. [2] A. Chernyavskiy, D. Ilvovsky, and P. Nakov, “Transformers:“the end of history” for natural language processing?” in Machine Learning and Knowledge Discovery in Databases. Research Track: European Conference, ECML PKDD 2021, Bilbao, Spain, September 13–17, 2021, Proceedings, Part III 21. Springer, 2021, pp. 677–693. [3] T. Lin, Y. Wang, X. Liu, and X. Qiu, \"A Survey of Transformers,\" 2024. [4] J. Ainslie, S. Ontanon, C. Alberti, V. Cvicek, Z. Fisher, P. Pham, A. Ravula, S. Sanghai, Q. Wang, and L. Yang, \"ETC: Encoding long and structured inputs in transformers,\" in Proceedings of EMNLP, 2020, pp. 268-284. Available: http://dx.doi.org/10.18653/v1/2020.emnlp-main.19. [5] R. Al-Rfou, D. Choe, N. Constant, M. Guo, and L. Jones, \"Character-level language modeling with deeper self-attention,\" in Proceedings of AAAI, 2019, pp. 3159-3166. Available: http://dx.doi.org/10.1609/aaai.v33i01.33013159. [6] A. Arnab, M. Dehghani, G. Heigold, C. Sun, M. Lu?i?, and C. Schmid, \"Vivit: A video vision transformer,\" arXiv:2103.15691, 2021. [7] L. J. Ba, J. R. Kiros, and G. E. Hinton, \"Layer normalization,\" CoRR, arXiv:1607.06450, 2016. [8] J. Devlin, M.-W. Chang, K. Lee, and K. Toutanova, \"BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding,\" arXiv:1810.04805, 2018. [9] R. Al-Rfou, D. Choe, N. Constant, M. Guo, and L. Jones, \"Character-level language modeling with deeper self-attention,\" arXiv preprint arXiv:1808.04444, 2018. [10] R. K. Ando and T. Zhang, \"A framework for learning predictive structures from multiple tasks and unlabeled data,\" Journal of Machine Learning Research, vol. 6, no. Nov, pp. 1817–1853, 2005. [11] L. Bentivogli, B. Magnini, I. Dagan, H. T. Dang, and D. Giampiccolo, \"The fifth PASCAL recognizing textual entailment challenge,\" in TAC, NIST, 2009. [12] R. Tang, J. Lin, B. Liu, and Y. Zhang, \"DocBERT: BERT for Document Classification,\" Preprint, April 2019. [Online]. Available: https://www.researchgate.net/publication/332493790. [13] A. Gillioz, J. Casas, E. Mugellini, and O. Abou Khaled, \"Overview of the Transformer-based Models for NLP Tasks,\" arXiv:2109.01139, 2021. [Online]. Available: https://arxiv.org/abs/2109.01139. [14] S. Hochreiter and J. Schmidhuber, \"Long Short-Term Memory,\" Neural Computation, vol. 9, pp. 1735–1780, Nov. 1997. [15] K. Cho, B. van Merrienboer, C. Gulcehre, D. Bahdanau, F. Bougares, H. Schwenk, and Y. Bengio, \"Learning Phrase Representations using RNN Encoder-Decoder for Statistical Machine Translation,\" arXiv:1406.1078 [cs, stat], Sept. 2014. [16] K. Greff, R. K. Srivastava, J. Koutník, B. R. Steunebrink, and J. Schmidhuber, \"LSTM: A Search Space Odyssey,\" IEEE Transactions on Neural Networks and Learning Systems, vol. 28, pp. 2222–2232, Oct. 2017, arXiv:1503.04069. [17] A. Vaswani, N. Shazeer, N. Parmar, J. Uszkoreit, L. Jones, A. N. Gomez, L. Kaiser, and I. Polosukhin, \"Attention Is All You Need,\" arXiv:1706.03762 [cs], Dec. 2017. [18] J. Cheng, L. Dong, and M. Lapata, \"Long short-term memory-networks for machine reading,\" in EMNLP, 2016. [19] M. Cheng, E. Durmus, and D. Jurafsky, \"Marked personas: Using natural language prompts to measure stereotypes in language models,\" in ACL, 2023. [20] A. Wang, \"NLP Evaluation in the Time of Large Language Models,\" Ph.D. dissertation, Department of Computer Science, New York University, Sep. 2022.
Copyright
Copyright © 2024 Ritesh Kumar Singh, Deepanshu Rana. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET63408
Publish Date : 2024-06-21
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online