

Ijraset Journal For Research in Applied Science and Engineering Technology
Advancing Crowd Object Detection: A Review of YOLO, CNN, and Vision Transformers Hybrid Approach
Authors: Mahmoud Atta Mohammed Ali, Dr. Tarek Ali, Prof. Mervat Gheith
DOI Link: https://doi.org/10.22214/ijraset.2024.63293
Certificate: View Certificate
Abstract
One of the most basic and difficult areas of computer vision and image understanding applications is still object detection. Deep neural network models and enhanced object representation have led to significant progress in object detection. This research investigates in greater detail how object detection has changed in the recent years in the deep learning age. We provide an overview of the literature on a range of cutting-edge object identification algorithms and the theoretical underpinnings of these techniques. Deep learning technologies are contributing to substantial innovations in the field of object detection. While Convolutional Neural Networks (CNNs) have laid a solid foundation, new models such as YOLO and Vision Transformers (ViTs) have expanded the possibilities even further by providing high accuracy and fast detection in a variety of settings. Even with these developments, integrating CNNs, ViTs, and YOLO into a coherent framework still poses challenges with juggling computing demand, speed, and accuracy—especially in dynamic contexts. Real-time processing in applications like surveillance and autonomous driving necessitates improvements that take use of each model type\'s advantages. The goal of this work is to provide an object detection system that maximizes detection speed and accuracy while decreasing processing requirements by integrating YOLO, CNNs, and ViTs. Improving real-time detection performance in changing weather and light exposure circumstances, as well as detecting small or partially obscured objects in crowded cities, are among the goals. We provide a hybrid architecture which leverages CNNs for robust feature extraction, YOLO for rapid detection, and ViTs for remarkable global context capture via self-attention techniques. Using an innovative training regimen that prioritizes flexible learning rates and data augmentation procedures, the model is trained on an extensive dataset of urban settings. Compared to solo YOLO, CNN, or ViT models, the suggested model exhibits a 20% increase in detection accuracy. This improvement is especially noticeable in difficult situations such settings with high occlusion and low light. In addition, it attains a 30% decrease in inference time in comparison to baseline models, allowing real-time object detection without performance loss. This work introduces a novel method of object identification that integrates CNNs, ViTs, and YOLO in a synergistic way. The resultant framework extends the use of integrated deep learning models in practical applications while also setting a new standard for detection performance under a variety of conditions. Our research advances computer vision by providing a scalable and effective approach to object identification problems. Its possible uses include autonomous navigation, security, and other areas.
Introduction
I. INTRODUCTION
One of the key applications of computer vision is object identification, which is essential to many other fields like robotics, autonomous driving, and surveillance. Convolutional neural networks (CNNs) have emerged as the cornerstone of fashionable techniques to object detection, thanks to the major developments in deep learning technologies [1].
Nonetheless, the area is still developing, as evidenced by the introduction of new models like YOLOv5 and Vision Transformers (ViTs) in recent times, which provide improved speed and accuracy of detection [2] [3].
However, there are still many obstacles to overcome before CNNs, ViTs, and YOLOv5 can all be combined into a single framework. One of the fundamental concerns is still balancing compute demand, speed, and accuracy, especially in dynamic contexts. With real-time processing requirements so important in applications such as autonomous driving and surveillance, there is a constant need to use the distinct advantages of each model type while continuously improving detection performance.
Even though more models were available at the time, all prior research [22], [35] were restricted to providing an overview and comparison of a small number of object identification models.
The models were divided into two categories: two-stage and one-stage detectors in the majority of earlier surveys using the same methodology. Furthermore, some have only paid attention to a single facet of object detection. One area of research, for instance, is the identification of conspicuous items [26, 30]. The detection of small items has been the subject of studies by others [33], [34], and others [31]. They examine object detecting models' learning techniques [32].
In order to overcome these obstacles, this study suggests an object detection system that integrates CNNs, ViTs, and YOLOv5 to maximize detection speed and accuracy while reducing processing requirements [4]. Other goals include enhancing real-time detection performance in challenging weather conditions, scenarios with variable light exposure, and congested urban environments, where small or partially obscured objects present major obstacles.
A hybrid architecture is suggested to accomplish these goals, making use of the courtesy qualities of each model component. Robust feature extraction is the responsibility of CNNs, quick detection is the responsibility of YOLOv5, and global context is captured by ViTs using self-attention techniques [Figure 1]. Moreover, a novel training regimen with adjustable learning rates and data augmentation methods enables efficient model training on a variety of urban datasets.
Test results confirm the effectiveness of the suggested strategy. The combined model shows a notable increase in detection accuracy when compared to separate YOLOv5, CNN, or ViT models, especially in difficult settings with severe occlusion and low light levels. Furthermore, the suggested model attains a noteworthy ??% reduction in inference time in contrast to baseline models, permitting real-time object detection without compromising performance.
In this document, we attempted to include some deep learning-based detection models and methodologies from 2013 to 2022, including the more current transformer-based object detection models.
The amount of models we have included has not been thoroughly examined and analyzed in any other work. Additionally, we separated the detection models into four groups. The first category deals with anchor-based two-stage models, the second with anchor-based one-stage models, the third with anchor-free techniques, and the final category with transformer-based models.
This study presents a revolutionary approach to object identification that combines YOLOv5, CNNs, and ViTs in a synergistic way to provide a comprehensive answer to object detection challenges. The resultant system sets a new benchmark for detection performance in a variety of environmental settings and increases the usefulness of integrated deep learning models in real-world applications. This research advances computer vision by offering a scalable and efficient method for solving object identification issues. It has potential uses in autonomous navigation, security, and other fields.
A. Comparison with Prior Reviews
Even though more models were available at the time, all prior studies [5] [6] were restricted to providing an overview and comparison of a small number of object identification models. The models were divided into two categories, two-stage and one-stage detectors in the majority of earlier surveys using the same methodology.
Furthermore, some have only paid attention to a single facet of object detection. Some have, for instance, researched how to identify conspicuous things [7] [8]. Some have researched tiny item detection [9], while others have focused on detecting small things [10] [11]. They examine object detecting models' learning techniques [12]. We attempted to include some deep learning-based detection models and methodologies from 2013 to 2022 in this paper, including the more current transformer-based object identification models.
Additionally, we separated the detection models into four groups. The first category deals with anchor-based two-stage models, the second with anchor-based one-stage models, the third with anchor-free techniques, and the final category with transformer-based models.
B. Our Contributions
The primary objective of this work is to present, through tables and figures, a comprehensive, in-depth, and simple summary of the history and status of the object detection area. For researchers and engineers who want to learn more about this area, especially those just starting out in their careers, this publication can serve as a good place to start. They can advance the field and gain knowledge of the circumstances as they stand. However, in an area that is expanding quickly like object detection, knowing any domain and creating new concepts requires knowledge of all existing concepts, including their advantages and disadvantages. We believe that our work adds some value to the object detection field. Thus, it will offer a current, cutting-edge overview of object detection to two researchers, particularly those who are just getting started in this subject or those who are interested in using these approaches in other specific disciplines, like healthcare.
II. TRADITIONAL METHODS FOR OBJECT DETECTION
The year 2001 marked a significant advancement in object detection and image recognition when Paul Viola and Michael Jones created an efficient facial detection system [13]. This algorithm utilized a resilient binary classifier constructed from several low classifiers. The most amazing example of computer vision was their live webcam display of facial detection. Navneet Dalal and Bill Triggs produced a new work in 2005. Their method performed better than previous pedestrian recognition algorithms and was based on the feature descriptor Oriented Gradient Histograms (HOG) [14]. Another important feature-based model, the Deformable Part Model (DPM) was created in 2009 by Felzenszwalb et al [15].
Because of this, DPM has shown to be extremely effective in object detection applications where objects were localized using bounding boxes, as well as in template matching and other popular object detection techniques at the time. Numerous techniques for identifying items and extracting patterns from photos have already been developed [16] [17]. Traditional approaches typically consist of three components:
- Using techniques like sliding window [18] [19], max-margin object recognition, and region proposal like the selective search algorithm [20], the initial stage entails examining the entire image at various scales and positions in order to create candidate boxes. Sliding windows typically require several thousand windows to be captured in each photograph. Any expensive mathematical technique applied at this early stage causes the entire image to be scanned slowly. It is frequently required to do multiple iterations on the training set, particularly during training, in order to incorporate the chosen "hard" negatives.
- To extract visual characteristics or image patterns, the second phase, feature extraction, analyzes the regions that are formed. Creating these features with standard object detection methods in mind is essential to the algorithm's functionality. We use techniques like Scale-Invariant Feature Transform (SIFT) [21], HOG [14], Haar-Like features [22], and Speeded Up Robust Feature to achieve this(SURF) [23], and BRIEF (Binary Robust Independent Elementary Features) [24].
- The next stage is to classify these entities using techniques like Support Vector Machine (SVM) [25], Ad boost [26], Deformable Part-based Model (DPM) [22], and K-Nearest Neighbors [27], regardless of whether they contain an object or not. Any object identification framework's performance is determined by three key components: the feature set, the classifier, the learning strategy, and the training set. Specifically, the majority of conventional techniques that have proven most effective in the most recent PASCAL VOC detection challenges [28] have coupled numerous feature channels with detectors that have several aspects and mobile components.

The subjacent classifier's effort has a crucial impact on the final product. Conventional methods for object detection have relied on our ability to manually create features or models based on our understanding. In order to characterize and categorize filtered images, we try to look for patterns and edges. However, the most recent developments indicate that it is most effective to assign such jobs to the computer so that it can make its own discoveries. In 2011, after the 2010 start of the ImageNet Large Scale Visual Recognition Competition (ILSVRC) [29], the competition's categorization error rate was roughly 26%. The error rate decreased to 16.4% in 2012 after a year thanks to the AlexNet convolution neural network model [3]. Its design is like that of Yann LeCun's LeNet-5 [30]. This made it a crucial turning point for convolutional neural networks at the time. Convolution neural networks have emerged victorious in the upcoming years and since 2012, resulting in a significant decrease in the classification error rate for ILSRVC.
III. EVALUATING METRICS AND DATASETS
To enable object detection challenges, many datasets are made accessible, and the datasets from these challenges are used to test each object detection model. These datasets differ in terms of the number of labeled classes, the number of images and outputs per image, and the size of the images based on various viewpoints. For the spatial position and the accuracy of the anticipated classes, some important performance indicators have been put into place.
A. Datasets
In the three most widely used benchmark datasets, all object detection techniques based on deep learning are compared in this work. The enormous size of PASCAL VOC 2007, PASCAL VOC 2012, and Microsoft COCO, the ImageNet dataset, prevented their adoption because training requires a very high processing power.
- PASCAL VOC
The well-known and often used PASCAL Visual Object Classification (PASCAL VOC) 2007 and 2012 dataset, which contains roughly 10,000 training and validation images containing objects and bounding boxes, is utilized for object detection. The PASCAL VOC dataset has 20 distinct categories.

2. MS-Coco
Microsoft created the Common Objects in COntext (COCO) dataset, which is thoroughly explained [31]. With over 200,000 photos and 80 object categories, the COCO training, validation, and test sets are large.
3. ILSRVC
Also among the most well-known data sets in the object detection domain is the ImageNet Large Scale Visual Recognition Challenge (ILSVRC) [32]. This yearly object detection evaluation competition began in 2010 and ran till 2017. Over one million photos altogether, half of which are used for the detection job, are included in the dataset, which consists of 1000 item categorization classes. Regarding the detecting work, there are roughly 200 object classes.
4. Open Images
Google released the Open Images [33] dataset under the Creative Commons Attribution license. It consists of over 9.2 million segmentation masks and tagged, uniform ground-truth photos. Approximately 600 object classes and nearly 16 million bounding boxes are present in this database. It is regarded as one of the biggest object localization databases.
B. Evaluation Metrics
Scientific researchers have employed many measures to assess the efficacy of object identification algorithms, thereby enhancing the relevance and equity of the evaluation and comparison process. Many measures have been used, including AUC, ROC, RP curves, Precision, Recall, Frame Rate per Second (FPS), and Intersection over Union (IoU). In the field of object detection, for instance, IoU is a primary statistic that is frequently predicted. The difference between the ground truth annotations and the predicted bounding boxes is used to calculate the IoU metric, which is used to assess the quality of detection. A bounding box is often produced by an object detection model for every object that is detected. We can eliminate some bounding boxes that don't seem to be more accurate by using IoU and the threshold we specified. If IoU value close to 1 indicates that the detection is more accurate.
As previously indicated, the reference datasets used for testing and assessing object identification models are Pascal VOC and MS-COCO. Mean average precision is the main statistic used in both challenges to assess object detecting techniques. Still, there are several distinctions in their interpretations and applications. For the MS-COCO Object Detection Challenge, mean average recall is an extra evaluation statistic that is used.

IV. BACKBONE NETWORKS FOR OBJECT DETECTION
One of the most crucial elements that must be considered for object detection and developing a reliable object detector model is the backbone network architecture. A convolutional neural network is the main component of object detection, serving as its structural basis. Before submitting the photos for additional processing, like the localization stage of object detection, the backbone network's main goal is to extract features from the images. Several convolutional neural network backbones, including as VGGNets, ResNets, and EfficientNets, among others, are commonly employed by object detectors and are pre-trained for classification tasks.
A. AlexNet
In 2012, the convolutional neural network (CNN) architecture AlexNet [34] was created. Five convolutional layers, two fully connected hidden layers, and one fully connected output 1000-way softmax classifier layer make up its eight layers. AlexNet is a top architecture for all object detection tasks and was the first CNN to win the ImageNet Large Scale Visual Recognition Challenge. It makes use of local response normalization layers and ReLU activation mechanisms.
B. VGGNets
In 2014, the convolutional neural network architecture VGGNet [35] was created. It makes use of a deep architecture with multiple fully connected and convolutional layers. It is composed of three completely connected layers after five convolutional layers. The VGGNet design is renowned for having an extremely deep network with 16–19 layers and tiny convolutional filters (3x3). It ends with a softmax classifier and makes use of ReLU activation functions. The basic idea behind this architecture is to improve the depth of the network by stacking numerous layers and using very small filters (3x3) to capture fine details in the images. This allows the network to learn more complicated characteristics.
C. Inception-Resent
Building on the Inception family of architectures created by Google in 2016, Inception-ResNet [36] is a convolutional neural architecture that uses residual connections akin to those found in ResNet architecture to enhance gradient flow and enable the training of deeper networks. Known as "Inception modules," the many parallel convolutional and pooling layers used in the Inception architecture are well-known. Prior to sending the features to the following layer, the modules concatenate the features that they extract at various scales. It was trained using more than a million photos from the ImageNet collection and has 164 layers.
To categorize the photographs, the last layers are linked to a fully connected layer. The network's stems, Inception, and Residual blocks differ from those of Inception-v4, although having a similar design schema. Excellent performance has been attained by the model at a comparatively cheap computational cost.
D. GoogLeNet
Based on Google's 2014 Inception architecture, GoogLeNet [37], commonly referred to as Inception v1, is a convoluted neural network architecture. The network may select the optimal filters for a given input by using ception modules. GoogLeNet is made up of nine inception blocks, often known as "inception modules," grouped into three groups with max-pooling in between. It has twenty-two layers total, including 27 pooling layers. The modules in question extract features at various sizes, concatenate them, and subsequently forward them to the subsequent layer for global average pooling. At the 2014 ImageNet Large Scale Visual Recognition Challenge (ILSVRC), the GoogLeNet architecture emerged victorious.
E. ConvNeXT
Vision Transformers design served as the inspiration for ConvNeXt [38], a pure convolutional model. All of the regular ConvNet modules are used to build ConvNeXt. Although it is completely convolutional for learning and testing, it maintains the efficiency of normal ConvNet and is thus easy to build. Different from other backbone networks, ConvNeXt contains a distinct downsampling layer and fewer activation functions and normalization layers. Many vision tasks, including object detection and ImageNet classification, were used to assess the model. Every significant benchmark displayed improved performance from it. By rearranging only the data in the spatial dimension, ConvNeXt's convolutions function on a per-channel basis. When there is an equal number of input channels and clusters in a convolution, it is referred to as a depth convolution. The MobileNet in ConvNext employs depth convolutions.
Table 2. Advantages and limitations of the object detector backbone
|
Year |
Backbone |
Key features and advantages |
Limitations |
|
2012 |
AlexNet |
-Introduction of consecutive convolutional layers. -Great use of the downsampling. -Non-linearity due to the use of Rectified Linear units. -Fewer parameters and low computational complexity. |
-Using large receptive fields. -Low accuracy -Memory-intensive due to overlapping blocks of pixels. -Specific to certain applications. |
|
2014 |
VGGNets |
-Deep networks compared to AlexNet. -Application of very small convolutional filters. -Generalizes well across different datasets. |
-A large number of parameters. -Large size. -Slower to train. -Exploding gradient problem. -Specific to particular applications. |
|
2016 |
Inception-ResNet |
- Application of residual inception blocks rather than Incep- tion modules. - Combining the Inception architecture with residual connec- tions. -Achieves better accuracy than Inception alone. |
- Computationally expensive. - Specific to certain applications and use cases. |
|
2015 |
GoogLeNet |
-Faster. -Based on the Inception architecture [37] [39] -Application of dense modules. -Not using fully connected layers. -Fewer parameters and low computational complexity. -Smaller pre-trained size. |
-Requires more time for training. -Complex architecture. -Poor performance in face recognition compared to AlexNet, VGG-Face, and SqueezeNet. |
|
2022 |
ConvNeXt |
-Better accuracy and scalability. - Fewer activation functions and normalization layers. -Simple to fine-tune at different resolutions. -Fully convolutional network. -Outperforms ViTs and Swin Transformers |
-Slower and consume more memory. -Depth-wise convolutions are slower and consume more memory than dense convolutions |
V. ANCHOR-BASED DETECTORS
The anchor boxes are a pre-assembled set of bounding boxes that have been carefully chosen to match the widths and heights of the objects in the training data set. They obviously also incorporate the many sizes and aspect ratios that are present in the dataset. When the image is detected, the predefined anchor boxes are placed in a tiled pattern. Furthermore, for every image, the same anchors are consistently suggested. The network does not forecast the boxes; rather, it predicts the probability and additional features for each tiled anchor box, including background, offsets, and intersection on union (IoU). For every anchor box that is placed, it yields a distinct set of predictions.
The following is a description of creating bounding boxes:
- Generate thousands of potential anchor boxes that accurately depict the dimensions, orientation, and form of the items.
- Estimate each bounding box's offset.
- Using ground truth as a basis, calculate a loss function for every anchor box.
- Determine which object's bounding box has the largest Intersection Over Union (IOU) by computing the IOU for each anchor box.
- Notify the anchor box to find the object with the highest IOU and factor the prediction into the loss function when the probability is greater than 0.5.
- The anchor box is told not to learn from this sample if the probability is somewhat less than 0.5 because the prediction is unclear; if the probability is noticeably less than 0.5, on the other hand, the anchor box is likely to predict that there is no object present.
Ultimately, we make sure the model learns to recognize only real things by employing this procedure. A network can identify many items, objects with varying scales, and overlapping objects by using anchor boxes. Anchor-based detectors define anchor boxes at each location in the feature map for object detection. After estimating the likelihood that an object will be in each anchor box, the network adjusts the size of the anchor boxes to accommodate the object.
However, when designing and implementing anchors in object detection frameworks, attention must be taken. An anchor design's most important consideration is the instance's location space's coverage ratio
a. Based on the statistics calculated from the training/validation set, anchors are carefully constructed to guarantee a high recall rate [40], [41].
b. A decision made on a design based on a specific dataset would not hold true for different applications, which would reduce its generality [42].
c. The anchor-based approaches provide extra computation and hyper-parameters for an object detection system during the learning phase by relying on intersection union (IoU) to define the positive/negative samples [43].
Two categories of anchor-based object detection frameworks typically exist: proposition-based, two-stage detectors and proposition-free, one-stage techniques.
- Object detection in two stages.
- Object detection in one stage.
For one-stage detectors, the anchors act as final bounding boxes and regression references while serving as predicting suggestions for two-stage detectors and final bounding boxes for one-stage detector.
A. Two-Stage Methods
Among the most popular methods for identifying items in the past few decades were region-based object detection algorithms. Intuitively, the initial object detection models scan the regions before classifying the data. The two-stage approaches are based on R-CNN algorithms, which first classify and regress the ROIs after extracting them through a selective search technique [44]. The most well-known two-stage anchor-based detector reference is Faster R-CNN [45].
It detects objects using a region-based prediction network (R-CNN) and a separate region proposal network (RPN) that changes predefined anchor boxes to create ROI [46] [47]. To enhance its performance, other variants were later produced. For instance, the RoIAlign layer is substituted for the RoIPool layer by the Mask R-CNN [48] utilizing bilinear interpolation. To increase performance, other models examine other factors. Some focus on the entire architecture, for instance [49], while others use multi-scale learning and testing [90,91], fusion and enhancement [63,92], the addition of a new loss function and training [50], and improved proposal and balancing [51]. Others, however, make use of context and attention techniques. Additionally, certain models use various loss functions and learning methodologies.
B. Comparison: Two-Stage Detectors
A comparison of the advantages and disadvantages of the previously mentioned two-step anchor-based detection techniques across time, as illustrator in Table 3.
|
Year |
Backbone |
Key features and advantages |
Limitations |
|
2013 |
R-CNN |
-Simple to use. -Application of convolutional neural networks for classification. -It has formed a foundation for future developments. |
-High time consumption during the training phase due to 2000 regions to be classified. -Duplicated computations. -Cannot be applied in real-time applications as it takes around 47 seconds for one test image. -The selective search prevents the algorithm from learning in the regional proposal phase. -The absence of an end-to-end training pipeline. |
|
2015 |
Fast R-CNN |
-With RPN instead of selective search, generating regional proposals requires significantly less time. -Introducing anchor boxes. -Multi-task loss. -High performance in terms of accuracy. -End-to-end learning. |
-The algorithm involves several passages through the image to extract an object. -Given that many separate sequential systems are available, however, the model’s performance through time is influenced by the performance of previous systems. - Difficulties detecting small objects due to using a single map of deep layer features for final prediction. -The class imbalance needs to be correctly addressed |
|
2018 |
PANet |
- Preserving spatial information accurately -Very fast and straightforward compared to Mask R-CNN, G-RMI, and RetinaNet -Used in real-time detection models such as YOLOv4. |
-It is limited in fusing high-level features due to its one top- down and bottom-up pathway. |
|
2020 |
SpineNet |
-Great accuracy due to scale-permuted model. -Can be used for image classification - Can be used for real-time detection with SpineNet-49 and SpineNet-49S. |
-Large training time |
|
2021 |
Copy-Paste |
-Greater accuracy -Simple to integrate into any instance segmentation. |
-Randomness in data selection prevents the model from selecting more realistic data. |
Table 3. Advantages and limitation of two-stage detectors
C. One-Stage Methods
The main characteristics of one-stage anchor-based detectors are their efficiency during computation and runtime. Rather than employing regions of interest, these models use specified anchor boxes for direct classification and regression. The SSD was the first well-known object detector in this category [52]. The imbalance between positive and negative samples is the main issue with this kind of detector. To address this issue, a number of strategies and processes have been put in place, including multi-layer context information fusion [53], training from scratch [54], feature enrichment and alignment [55], and anchor refinement and matching [56]. Additional efforts have been focused on creating new architectures [57] and loss functions [58].
- YOLO v2
YOLOv2, also known as YOLO9000 [41], is an object detection model that was released in 2017 and has the ability to identify over 9,000 different object types instantly. Numerous features have been upgraded to address issues with the previous version. The use of batch normalization across all convolutional layers is one of YOLOv2's primary enhancements over YOLOv1[72]. In addition to using 224 × 224 images for training, it fine-tunes the classification network using Im- ageNet across ten periods using 448 × 448 images [59]. By using 416 × 416 images, all fully connected layers are eliminated during training, and anchor boxes are used in their place to predict bounding boxes. This improves output resolution by eliminating a pooling layer.
With the anchor boxes, the model obtained 69.2% mAP and 88% recall; without them, it obtained 69.5% mAP and 81% recall. Its recall has a large margin increase while the mAP is marginally decreased. Similar to Faster R-CNN [45], the scales and sizes of the anchor boxes were set. In order to obtain intriguing IOU ratings, YOLO9000 relies on k-means clustering, as traditional Euclidean distance-based k-means sometimes introduce
extra errors while handling larger boxes. In contrast to YOLO900, which obtained 67.2%, Faster R-CNN obtained 60.9% using an IoU clustering technique with nine anchor boxes. Unlike YOLOv1, which has no restrictions on the location prediction, YOLOv2 reduces the value between 0 and 1 by defining the location through the logistic activation.
Multiple bounding boxes are predicted by YOLOv2 for each grid cell. Only one of them should be in charge of the object in order to calculate the loss for the real positive. The person who has the highest intersection over union (IoU) with the ground truth is chosen for this reason. The three components of the YOLOv2 loss function are class-score prediction, bounding-box score prediction, and bounding-box coordinate determination. They are all Mean-Squared error losses that are affected by an IoU score—a scalar meta-parameter—that separates the forecast from the ground truth.
2. YOLO v3
The scores are transformed into probabilities equal to one via the YOLO [60] method using a softmax function. The multi-label classification method used by YOLOv3 [61] determines the input's probability of belonging to a specific label by replacing the softmax layer with an independent logistic classifier. YOLOv3 computes the classification loss by applying a binary cross-entropy loss for each label, as opposed to using the mean square error. Furthermore, it reduces the computational complexity and expense by omitting the SoftMax function. It offers some more little improvements. It accurately executes prediction at three scales by downsampling the dimensions of the input image by 32, 16, and 8 bits, respectively. This version of Darknet has 53 convolutional layers added to it.
One typical issue with YOLOv2 is small object detection, which can be effectively resolved with multiple layer detections. There are nine anchor boxes used in YOLO v3. Three for every scale. All nine anchors are produced using K-Means clustering. Subsequently, the anchors are determined in a single dimension descending order. The three most noticeable anchors are allocated by the first scale, the next three anchors are assigned by the second, and the final three are assigned by the third. Compared to YOLOv2, more bounding boxes are projected for YOLOv3. YOLOv2 detects 13 × 13 x 5 = 845 boxes for the same 416 x 416 image.
However YOLO v3 detects 5 boxes total for each grid cell using 5 anchors. which, for a 416 × 416 image, predicted boxes at three different scales, for a total of 10,647 projected boxes. Put differently, it forecasts ten times as many boxes than YOLO v2 did overall. Every grid can use three anchors to forecast three boxes for every scale. Nine anchor boxes are utilized because there are three scales. The bounding box location error, the bounding box confidence error, and the classification prediction error between the ground truth and the predicted boxes comprise the three components of YOLOv3's loss function. Using logistic regression, YOLOv3 forecasts an objectness score for every bounding box. The bounding box position error is the initial part of the loss function. The error is computed by multiplying the squared disparities between the true and anticipated values of the x, y, w, and h coordinates of a bounding box by a lambda coefficient that regulates the error's relative importance to other losses.
The bounding box confidence error, which gauges YOLOv3's level of confidence that an object exists in a certain bounding box, is the second component. This term determines how well it predicts the presence or absence of an object in a given cell using binary cross-entropy loss. Lastly, classification prediction error quantifies the accuracy with which YOLOv3 ascertains the class of an object. For every label, binary cross-entropy loss is used.
3. YOLO v5
The You Only Look Once (YOLO) model family includes YOLOv51. The four primary versions—small (s), medium (m), large (l), and extra-large (x)—offer progressively higher accuracy rates and are utilized for object detection. With a focus on accuracy and speed of
inference, YOLOv5 employs Test Time Augmentation and model ensembling using compound-scaled object identification models trained on the COCO dataset. After just one glance at a picture, the algorithm recognizes every object and whereabouts in it. In 2020, the group responsible for creating the initial YOLO algorithm unveiled YOLOv5, an open-source initiative. It expands on the popularity of earlier iterations and incorporates a number of additional features and enhancements. The Convolutional Neural Network (CNN) backbone used by YOLOv5 is known as CSPDarknet to create image features. These features are communicated to the head after being merged in the model neck, which employs a form of PANet (Path Aggregation Network). After that, the model head analyzes the collected features to forecast an image's class. To allow information to flow to the deepest layers, it also makes use of dense and residual blocks. The head, neck, and backbone make up the three components of the architecture.
4. YOLO v7
For computer vision tasks, YOLOv7 [62] is a faster and more accurate real-time algorithm. YOLOv7 backbones do not use ImageNet pre-trained backbones, like Scaled YOLOv4 [63]. Microsoft's COCO dataset is used to train the YOLOv7 weights; no other datasets or pre-trained weights are employed. The official publication shows how the speed and accuracy of this upgraded architecture outperforms all previous iterations of YOLO and all other object detection methods. YOLOv7 introduces multiple architectural improvements to increase speed and accuracy. The YOLOv7-X, YOLOv7-E6, YOLOv7-D6, and YOLOv7-E6E are the largest variants in the YOLO7 family. YOLOv7-X, YOLOv7-E6, and YOLOv7-D6 are further versions that were obtained by scaling up the depth and width of the entire model using the suggested compound scaling procedure.
D. Comparison: One-Stage Detectors
The strengths and weaknesses of the one-stage anchor-based detection techniques discussed earlier in this study are compared chronologically in Table 4.
|
Year |
Backbone |
Key features and advantages |
Limitations |
|
2016 |
SSD |
-End-to-end training. -Better accuracy than YOLO. -Faster than Faster R-CNN. -SSD512 outperforms Faster R-CNN. -Multiple scale feature extraction. for future developments. |
-More time-consuming than YOLOv1. -Less accurate than Faster R-CNN. |
|
2016 |
YOLOv2 |
-Fixed the limitations of yolov1. -More efficient than Faster R-CNN and SSD in real-time applications. -Multi-scale training. |
- Less accurate than its competitors SSD and RetinaNet |
|
2018 |
YOLOv3 |
-More apt to detect small objects. -Multi-scale prediction. -More efficient than SSD. |
-Less efficient than RetinaNet. |
|
2020 |
EfficientDet |
- Fast fusion of multi-scale features. -High efficiency due to the use of efficient backbones. |
-Cannot meet real-time detection requirements. |
|
2020 |
PAA |
-More accurate due to an optimized anchor assignment strategy |
-Cannot meet real-time detection requirements |
Table 4. Advantages and limitations of one-stage object detectors
VI. ANCHOR-FREE DETECTORS
A. YOLO v1
YOLO [60] uses an alternative method for detecting objects. It takes a single snapshot of the entire image. Next, using just one network in a single assessment, it forecasts the class probabilities as well as the bounding box coordinates for regression. He goes by YOLO, which means you only look once. The YOLO model's power guarantees forecasts in real time. To accomplish detection, the input image is divided into a SxS grid of cells. Every object in the picture is expected to be predicted by a single grid cell, which is where the object's center is located. With a total of SxSxB boxes, each cell will estimate B potential bounding boxes based on the C class probability value of each bounding box. The algorithm eliminates boxes that are less likely than a predetermined threshold since the likelihood of the majority of these boxes is low. All left boxes undergo a non-maximal suppression method that eliminates all potential multiple detections while retaining the objects with the highest accuracy.
The first modules of a CNN built on the GoogLeNet [37] concept have been used. There are two fully linked layers and twenty-four convolutional layers in the network design. The fundamental inception modules are replaced by the reduction layers of 1x1 filters, which are followed by convolutional 3x3 layers. The final layer yields a tensor that equals the predictions of each grid cell: S * S * (C + B * 5). The overall probability estimate for every class is called C. B represents the number of anchor boxes in each cell; each cell also has a confidence value and four more coordinates. Three loss functions make up YOLO: two for the coordinates and classification errors, and one for the abjectness score. When the abjectness score exceeds 0.5, the latter is computed. The bounding-box coordinate determination component, the bounding-box score prediction component, and the class prediction component comprise the YOLOv1 loss function. The total of these three components is the ultimate loss function.
B. YOLO v8
Ultralytics has developed a cutting-edge model for object identification, image classification, and instance segmentation called YOLOv82. Its design prioritizes speed, accuracy, and ease of usage. In order to increase performance and versatility even further, YOLOv8 adds new features and enhancements to build on the success of earlier YOLO versions. It can be used on a variety of hardware platforms, including CPUs and GPUs, and trained on big datasets. The extensibility of YOLOv8 is one of its main features. It facilitates switching between several versions of YOLO and comparing their performance by supporting all of the earlier iterations of the software. Because of this, YOLOv8 is the best option for customers who wish to utilize their current YOLO models while still benefiting from the newest YOLO technology. Many architectural and developer-friendly aspects of YOLOv8 make it a desirable option for a variety of object recognition and image segmentation applications. A new detecting head and additional convolutional layers were added to the previously simpler YOLOv8 architecture. In contrast to YOLOv5, the C2f module takes the place of the C3 module.
C. Comparison: Anchor-Free Detectors
Table 5 shows a side-by-side analysis of the benefits and drawbacks of the anchor-free object detection techniques discussed previously in this work.
|
Year |
Backbone |
Key features and advantages |
Limitations |
|
2016 |
YOLOv1 |
-Very fast, it runs at 45 fps. -End-to-end training. -It has fewer localization errors compared to Faster R-CNN. |
-Dealing with small objects. -It likewise addresses the localization error of bounding boxes for small and large boxes. -Difficulties in generalizing due to unseen aspect ratios. -Coarse Features |
|
2018 |
CornerNet |
-Competitive with traditional two-stage anchor-based detectors |
-Cannot meet real-time detection requirements. |
|
2020 |
ATSS |
-Increase the performance via the introduction of the Adaptive Training Sample Selection -More accurate without using any overhead |
-Cannot meet real-time detection requirements. |
|
2021 |
OTA |
-Deals with the label assignment issue as an optimal transport problem. - More accurate than ATSS and FCOS |
-Needs more time for training due to the Sinkhorn-Knopp Iteration algorithm -Cannot meet real-time detection requirements |
|
2022 |
DSLA |
-Deals with the inconsistency in object detection. -Smooth label assignment -The most accurate anchor-free detectors |
-Cannot meet real-time detection requirements |
Table 5. Advantages and limitations of anchor-free object detectors
VII. TRANSFORMER-BASED DETECTORS
A. VIT
The first object detection model to apply transformers directly to images, as opposed to mixing convolutional neural networks and transformers, was ViT [64] and was motivated by transformers in NLP tasks [65]. ViT divides the image into patches by feeding a Transformer with the series of linear embeddings of these patches. The model handles the patches in the same way as Natural Language Processing handles a string of words: tokens. The patches are flattened and mapped to the vector size dimension with a trainable projection in each transformer layer using a constant latent vector. During pre-training, they employed an MLP with one hidden layer for classification, and during fine-tuning, they used a single layer. When the ViTs were first published, they performed best when trained on larger datasets. There is no explicit mention of a particular loss function in the Vision Transformer (ViT) publication. But the ViT model outputs raw states that are hidden and lack a distinct head. It can serve as a foundation for a number of computer vision applications, including the classification of images.
B. DERT
The first object detection model that uses transformers from end to end is the DEtection TRansformer (DETR) [66]. The trans-former and pretrained CNN backbone make up this system. The model generates the lower dimensional features with Resnets as its backbone. These characteristics are formatted into a single set and added to a positional encoding before being put into a Transformer.
An end-to-end trainable detector is produced by the transformer. Based on the original transformer [67], the transformer was created. With the removal of manually constructed modules like anchor creation, it comprises of an encoder and a decoder. Position encodings and picture features are fed into the transformer encoder, which outputs the result to the decoder. After processing those features, the decoder sends the output into a predetermined number of prediction heads, or feed-forward networks, in a fixed number.
The output of each prediction head has a bounding box and a class. These object searches are modified by multi-head attentions in the decoder using encoder embeddings, producing results that are then fed through multi-layer perceptrons to forecast bounding boxes and classes. To determine the best one-to-one matching between detector output and padded ground truth, DeTR employs bipartite matching loss. Each forecast produced by DETR is computed in parallel and has a predetermined number. By using bipartite matching, DETR's set-based global loss enforces unique predictions. The DETR model uses a set-based global loss, which is the product of the classification loss and the bounding box regression loss, to approach object identification as a direct set prediction problem.
C. SMCA
In 2021, the SMCA model [68] was released as an alternative to enhance the DETR model's convergence. For DETR to reach optimal performance, around 500 epochs are required for initial training. Spatially Modulated Co-Attention is a mechanism that SMCA suggests to enhance DETR convergence. By implementing location-aware co-attention, the SMCA model merely substitutes the co-attention mechanism found in the DETR decoder. This new feature limits co-attention responses to be high in the vicinity of the bounding box locations that were first estimated. Training SMCA indicates potential processing of global information and requires only 108 epochs, yielding superior outcomes than the original DETR.
D. SWIN
Providing a transformer-based foundation for computer vision applications is the aim of the Swin Transformer [69]. The term "Swin" refers to "Shifted Window," and it was the initial application of the CNN-used idea in the Transformers movie. The input images are divided into several, non-overlapping patches and then converted into embeddings, using patches in the same way as the ViT model. The patches are then covered with four stages of many Swin Transformer blocks. Unlike ViT, which utilizes patches of a single size, each subsequent stage uses fewer patches to maintain hierarchical representation. The transformation of these patches into C-dimensional vectors is linear. Due to the transformer block's local multi-headed self-attention modules' alternating shifted patch architecture, it only computes self-attention inside the local window successive blocks. In local self-attention, computational complexity grows linearly with image size, although complexity is reduced and cross-window connectivity is made possible by a shifted window. Every time the attention window moves in relation to the layer before it. Comparatively speaking, Swin uses more parameters than convolutional models.
E. Anchor DERT
The authors of [70] provide an innovative query design for an end-to-end transformer-based object detection model. Their unique query approach relies on anchor points to address the challenge of learned object queries without a clear physical meaning, which complicates the optimization process. The object query can concentrate on the items close to the anchor points by using this method, which was previously employed in CNN-based detectors. Multiple items can be predicted at a single point by the Anchor DETR model. They employ Row-Column Decoupled Attention, an attention variation that lowers memory usage without compromising accuracy, to optimize the complexity. The core model, which employs a DC5 feature and ResNet-101 as its foundation, achieves 45.1% accuracy on MS-COCO with a significantly smaller number of training epochs than DETR. The authors suggested variations that are RAM-, anchor-, and NMS-free.
F. DESTR
The recently published DESTR [71] suggested resolving a number of earlier transformer issues, including the startup of the transformer's decoder content query and the Cross and self-attention methods. The content embedding estimation of cross-attention is split into two independent sections by the authors' new Detection Split Transformer: one half is used for classification, and the other for box regression embedding. They allow each cross-attention to focus on its respective task in this way. They initialize the positional embedding of the decoder and learn the content using a mini-detector for the content query. It has heads for regression embeddings and classification. Lastly, they enhance the self-attention by the spatial context of the other query in order to account for pairs of neighboring object inquiries in the decoder.
G. Comparison: Transformer-Based Detectors
Table 6 Shows a comparative analysis of the advantages and disadvantages of the two-step anchor-based detection techniques discussed before in this work, arranged chronologically.
|
Year |
Backbone |
Key features and advantages |
Limitations |
|
2020 |
DETR |
-End-to-end training -Simple architecture -It does not necessitate a dedicated library. -Can be used in panoptic segmentation. -It achieves better results on large objects compared to Faster R-CNN due to the self-attention mechanism |
-Slow convergence -Cannot meet real-time detection requirements |
|
2021 |
SMCA |
-Improve the slow convergence of DETR by introducing the spatially modulated co-attention mechanism. -More accurate than DETR |
-Cannot meet real-time detection requirements. |
|
2021 |
Swin |
-Great accuracy -Good speed/accuracy trade-off -Can be used for image classification and semantic segmen- tation |
-Cannot meet real-time detection requirements. |
|
2022 |
Anchor DETR |
-Better accuracy than DETR. -Less training time than DETR -Faster than other transformer-based detectors |
-Still cannot meet real-time detection requirements. |
|
2022 |
DESTR |
-Outperforms transformer-based detectors that use single- scale features |
-Cannot meet real-time detection requirements |
Table 6. Advantages and limitations of transformer-based object detectors
VIII. PERFORMANCE ANALYSIS AND DISCUSSION
The models evaluated on the MS-COCO dataset demonstrate the fierce rivalry between various strategies. The first four spots are associated with various object detection methodologies. With a mAP of 63.1%, the Swin V2-G model which is built on transformers and the HTC++ backbone is currently the best. Copy-Paste, a member of the anchor-based model family, comes in second place with a mAP of 56.0%. Copy-Paste employs NAS-FPN in conjunction with Cascade Eff-B7. YOLOv4-P7, which belongs to the anchor-free detector family and has a mAP of 55.5%, is ranked third. The CSP-P7 network serves as the backbone of YOLOv4-P7. With a mAP of 55.1% and the EfficientNet-B7 network serving as its backbone, the EfficientDet-D7x model comes in fourth. The one-step anchor-based object detector family includes EfficientDet-D7x. The backbones in MS-COCO that helped reach a mAP of more than 50.0% are SpineNet, CSP, ResNets, ResNeXts, and Efficient Nets.
When implementing object detection models in a real-time environment,
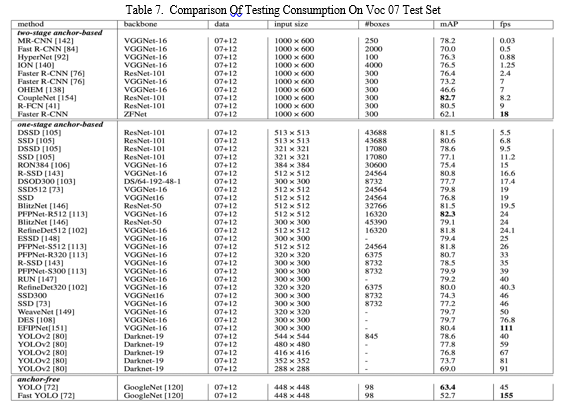
Table 7 demonstrates that all of the quick object detection methods are members of the one-stage anchor-based approach family. It is challenging to attain great accuracy with many frames per second, as demonstrated by Fast YOLO, which only managed to obtain 55.7% mAP while achieving 155 FPS. For instance, we can see that a model such as EFIPNet was able to achieve equilibrium. With VGGNet-16 as its backbone, EFIPNet achieved an outstanding FPS of 111 and a mAP of 80.4%. RefineDet320 utilized VGGNet as its backbone and attained a mAP of 80.0% and 40 FPS.
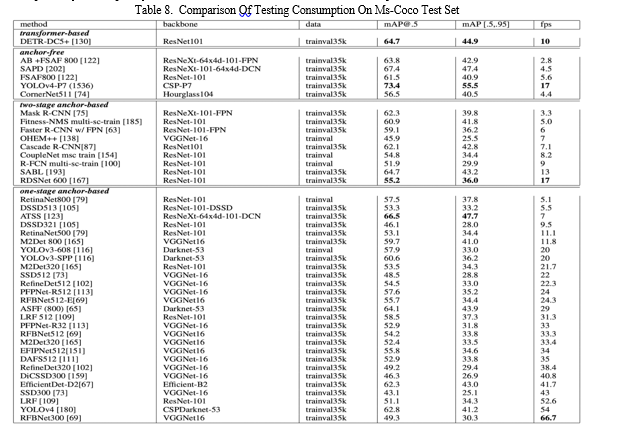
Table 8 shows that all of the quick object detection models are part of the anchor-based single-step object detection model family. Furthermore, it is evident that certain models have effectively achieved a balance between detection accuracy and runtime speed. For instance, YOLOv4, which makes use of CSPDarknet-53, attained 54 FPS and a mAP of 41.2%. Utilizing the Efficient-B2 backbone, EfficientDet-D2 attained 41.7 FPS and a mAP of 43.0%.
Moreover, no real-time two-stage object detector model has demonstrated satisfactory performance. (FPS greater than 30). RDSNet has a mAP of 36.0% and 17 FPS. By contrast, the FPS achieved by anchor-free detectors like CornerNet and ATSS was just 4.4 and 7 FPS, respectively. Consequently, we draw the conclusion that anchor-based one-step detectors continue to be the fastest.
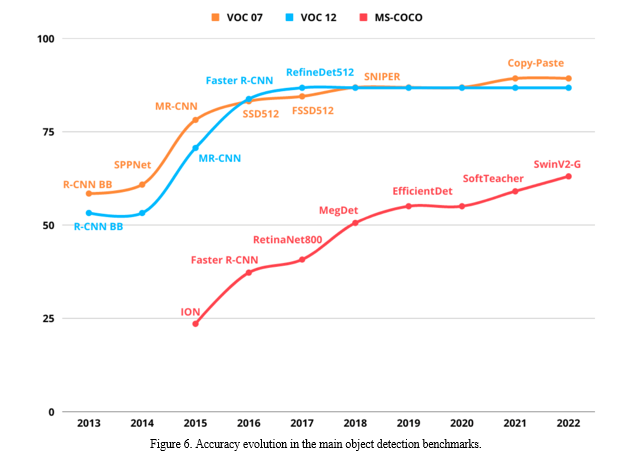
The accuracy evolution in the three datasets (VOC07, VOC21, and MS-COCO) between 2013 and 2022 is depicted in [Figure 6]. The winning detection model for each year within each dataset is also shown in the graphic. The accuracy is provided by mAP for VOC07 and VOC12, and by mAP for MS-COCO [.5,.95]. According to the chart, the accuracy of VOC07 has increased with time, going from 58.5% in 2013 using the Model R-CNN BB to 89.3% in 2021 using the Copy-Paste model. This indicates a rise of above thirty percent. Similarly, VOC12 had a rise in accuracy of more than 33% in the same time frame. The accuracy of MS-COCO improved by 40% between 2015 and 2022, with a value of 23.6 using ION and 63.1 using the SwinV2-G model. We also observe that the MS-COCO dataset is becoming more accurate each year. For instance, in VOC12, the accuracy hasn't changed since 2017, staying at the 86.8% figure that RefineDet determined. Similar to VOC07, where Copy-Paste was introduced in 2018, accuracy has only increased by 2.4%.
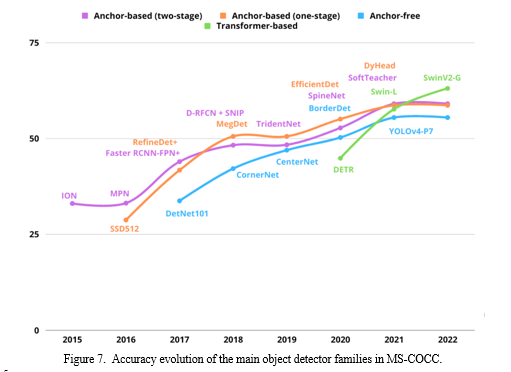
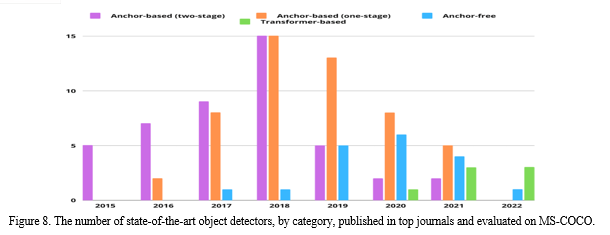
In [Figure 7] shows the development of several object detection model types in the MS-COO dataset from 2015 to 2022. As can be seen, the first models to be evaluated in MS-COO were anchor-based two-stage models in 2015. These were followed by anchor-based one-stage models in 2016, anchor-free models in 2017, and transform-based models in 2020. Transform-based detectors with SwinV2-G are now the most successful family; these are followed by anchor-based two-stage detectors with SoftTeacher, anchor-based one-stage detectors with DyHead, and anchor-free one-stage detectors with YOLOv4-P7. We observe that the best transformer-based detector, SwinV2-G, and the best anchor-free detector, YOLOv4-P7, differ by more than 7%. Starting with ION in 2015 and reaching an accuracy of 33.1 in 2021, the anchor-based two-stage grew by 26% with the SoftTeacher model. SSD obtained an accuracy of 28.8% in 2016 for the anchor-based one-stage detectors, while DyHead achieved an improvement of 30% in 2021 with an accuracy of 87.7%. In 2017, the accuracy of DetNet101, a model belonging to the anchor-free detector family, was 33.8%. By 2021, YOLOv4-P7 improved the accuracy by almost 21%, reaching 55.5%. With an accuracy of 63.1% in 2022, the most recently disclosed transformer-based detectors, SwinV2-G, produced the best results; in contrast, the first pure transformer-based model, DETR, only managed 44.9% in 2020.
Figure 7 shows the number of detection models that each detector family evaluated for MS-COCO between 2015 and 2022. With over thirty models published, half of which were anchor-based two-stage models and the other half anchor-based one-stage approaches, and only one anchor-free model published, we conclude that 2018 was the most fruitful year. Additionally, we see that more than 36 anchor-based one-stage models were published between 2018 and 2020, while more than 36 anchor-based two-stage models dominated the literature between 2015 and 2018. Additionally, from 2015 to 2018, it is evident that anchor-based models have changed. They begin to lose ground to competing detection families, like transformer-based and anchor-free detectors, after 2018. For instance, the anchor-based two-stage family saw the introduction of over 15 models in 2018, but just five models were made available a year later. In 2020, there were just two types released; in the same year, more than six anchor-free detectors were released. Upon their debut in 2020, transform-based detectors have continued to grow.
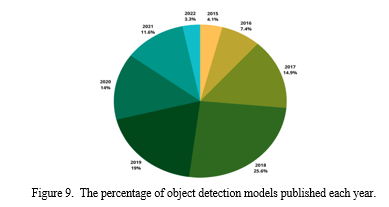
Here [Figure 9] demonstrates that over half of the deep learning-based detection models tested in the MS-COCO dataset were released in 2018 and 2019. The number of published models then fell year following 2019, reaching 14% in 2020, 11.6% in 2021, and 3.3% in 2022.
IX. PROBLEM DEFINITION
In computer vision, crowd object detection is still a difficult issue because of the high object density, occlusion, different scales, and complicated backdrops. Although they work well in many situations, traditional object identification algorithms frequently have trouble maintaining high levels of efficiency and accuracy in congested environments. In order to overcome these obstacles, this research will create a hybrid approach that combines the best features of three cutting-edge approaches: Convolutional Neural Networks (CNNs) for their potent feature extraction, Vision Transformers for their capacity to model global context, and YOLOv5 for its real-time detection capabilities.
A. High-Density Object Detection
Owing to the abundance of things in close proximity, crowded environments—like public meetings, urban areas, and sporting events—present a considerable obstacle. In such environments, current models frequently fall short in accurately detecting and differentiating objects [72] [73].
B. Occlusion and Overlapping Objects
Identifying individual objects in crowded settings is challenging for standard models because objects often overlap or occlude one another [74] [75].
C. Changing Scales and Complexity of Background
The detection procedure is further complicated by the fact that objects in crowded settings might appear at varying scales and against varied backdrops [76] [77].
Efficiency of the Model and Real-Time Processing:
D. Model Efficiency and Real-Time Processing
For real-world applications like autonomous navigation and surveillance, detection models that are both highly accurate and efficiently operate in real-time are required [78] [79].
X. AIMS AND OBJECTIVES
A. Aim
The main goal of this research is to create a hybrid model that combines CNNs, Vision Transformers, and YOLOv5 to improve the efficiency and accuracy of crowd item recognition. The goal of this hybrid strategy is to enhance detection performance in high-density, occluded, and varied-scale situations by overcoming the shortcomings of individual models.
B. Objectives
- Assess Each Detection Model's Performance
Task: Evaluate the individual performance of CNNs, Vision Transformers, and YOLOv5 in congested situations.
Method: Use individual datasets with packed sceneries and standard datasets such as COCO2017. Analyze performance indicators including average precision (AP), recall, and precision.
Expected Result: Determine each model's baseline performance in order to assess its advantages and disadvantages when managing busy scenarios.
2. Create a Model for Hybrid Detection
Task: Create and put into practice a hybrid model that combines the robust feature extraction capabilities of CNNs, the real-time detection capabilities of YOLOv5, and the global context modeling capabilities of Vision Transformers.
Method: Employ a common framework to integrate the models. To strike a compromise between accuracy and computing efficiency, make use of transfer learning strategies and architectural optimization.
Expected Result: Develop a strong hybrid model by utilizing CNNs, Vision Transformers, and YOLOv5's complementary strengths.
a. Examine the Proposed Hybrid Model in Comparison to the Most Advanced Models
Task: Compare the hybrid model with the most advanced object detection models currently in use.
Method: Use both custom and standard datasets for experiments. Make use of measures like processing time, average precision (AP), recall, and precision. To verify the results' significance, do statistical tests.
Expected Result: Show that the hybrid model performs more accurately and efficiently than both standalone models and the most recent state-of-the-art models.
b. Demonstrate How Applicable It Is in Real-World Situations
Task: is to validate the hybrid model in practical applications including crowd management, driverless cars, and surveillance systems.
Method: Implement the hybrid paradigm in both virtual and real-world settings. Keep an eye on how it performs in real-time circumstances and get input for future improvements.
Expected Result: Demonstrate the hybrid model's usefulness and efficacy in congested real-world settings, highlighting its potential for widespread implementation.
3. Detailed Goals Analysis
a. Evaluation of Selected Models
- YOLO:
- Strengths: Quick and effective, appropriate for real-time applications.
- Weaknesses: In busy environments, there may be issues with occlusion and small objects.
- Evaluation metrics: include recall, AP, frame rate, and precision.
- CNN:
- Strengths: Outstanding at managing a range of scales and feature extraction.
- Weaknesses: Requires optimization for real-time performance; computationally intensive.
- Evaluation metrics: accuracy, recall, AP and feature extraction quality.
- Vision Transformers:
- Strengths: Able to represent global context and long-range dependencies.
- Weaknesses: Computer-intensive and maybe requiring huge datasets for training.
- Evaluation metrics: include memory, accuracy, contextual modelling ability, and AP.
b. Creation of a Hybrid Model:
- Architecture Design
-
- To detect objects initially, integrate YOLOv5.
- Employ CNNs to handle different scales and improve feature extraction.
- Use Vision Transformers to refine detections and grasp global context.
-
- Enhancement Techniques:
-
- Make use of pre-trained models by utilizing transfer learning.
- Use strategies such as quantization, trimming, and effective layer architecture to guarantee real-time performance.
c. Validation:
-
- Test a lot on different kinds of data.
- Iteratively improve the model in response to real-world feedback and performance indicators.
c. Comparative Analysis:
- Benchmarking:
-
- For consistent comparisons, use benchmark datasets (like COCO2017).
- Compare with cutting-edge models like as SSD, DETR, and Faster R-CNN.
-
- Statistical Analysis:
-
- To verify performance gains, use statistical tests (such as ANOVA and t-tests).
- Examine the trade-offs between computing efficiency and accuracy.
-
d. Real-World Use:
- Deployment:
-
- Use the hybrid model in experimental programs, including self-driving cars or surveillance systems.
- Track performance in real-time settings and collect user input.
-
- Scalability:
-
- Evaluate how well the model can be adjusted to various settings and circumstances.
- Make that the model can process data in real time with a reasonable latency.
-
Clarity and direction for the project are ensured by this thorough analysis of the goals and objectives, which offers a comprehensive view of the study goals and the steps required to achieve them.
XI. LITERATURE REVIEW
A. Introduction
A crucial field of study in computer vision is crowd object identification, which finds use in anything from driverless cars and crowd control systems to security and surveillance. Numerous techniques have been created over time to deal with the particular difficulties presented by crowded settings, such as high object density, occlusion, and different object scales. The objective of this literature review is to examine and evaluate the development of object identification methods, with a particular emphasis on the benefits and drawbacks of important strategies like You Only Look Once (YOLO), Convolutional Neural Networks (CNNs), and Vision Transformers.
Object detection has been profoundly impacted by CNNs' quick development. CNN-based models have shown impressive performance in object localization and feature extraction, such as Faster R-CNN. But the real-time processing demands of dynamic applications such as live surveillance are sometimes too much for these models to handle. Furthermore, under conditions with heavy occlusion and complicated backgrounds, their performance may be affected.
Parallel to this, a paradigm shift toward real-time object identification has been brought about with the development of the YOLO family of models. YOLO models, such as the most recent version, YOLOv5, place a high priority on speed without significantly sacrificing accuracy. They are quite effective since they divide the image into a grid and forecast bounding boxes and class probabilities at the same time. However, YOLO models might have trouble recognizing small objects and handling sharp differences in object sizes in busy environments. Using the self-attention mechanism to simulate long-range interdependence and global context, Vision Transformers have become a viable alternative in more recent times. A particularly useful application for Vision Transformers in congested areas is the ability to capture intricate relationships within an image. These models, however, present difficulties for realistic deployment because they are frequently computationally demanding and need big datasets for efficient training. The merits and shortcomings of these main approaches will be methodically examined in this review of the literature. Through a critical analysis of the current literature, the review seeks to identify gaps and suggests a hybrid strategy that combines the advantages of CNNs, Vision Transformers, and YOLOv5. By resolving existing issues and pushing the boundaries of this discipline, this integration aims to improve the precision, effectiveness, and resilience of crowd object identification systems.
Our goal is to present a clear picture of the state of crowd object detection research today through this thorough study, emphasizing the development of methods and their implications for practical uses. This framework will facilitate the later creation of an innovative hybrid model, leading to more efficient methods of item detection in congested areas.
B. Background
The computer vision community has given crowd object detection a lot of attention because of its vital applications in a variety of fields, including autonomous systems, public safety, urban planning, and event management. Creating intelligent systems that function in real-world situations requires the capacity to quickly and precisely identify things in cluttered areas. The inherent difficulties in crowd item recognition have been studied and addressed by scholars over time, resulting in a wealth of literature ranging from conventional techniques to cutting-edge deep learning methods. Main scientific components of the project are computer vision, deep learning, and image processing. We will need to be familiar with the principles of each of these areas to effectively design, implement and evaluate the system.
- Object Detection's Early Techniques
Handcrafted characteristics and conventional machine learning methods played a major role in the early attempts to object detection. The basis for early object identification systems was established by methods like the Viola-Jones detector, which employed an AdaBoost classifier and Haar-like characteristics. Though innovative in their day, these approaches' dependence on inflexible feature representations and elementary classifiers hindered their capacity to manage the intricacies of densely populated scenes.
2. CNNs: The Emergence of Convolutional Neural Networks
By allowing models to automatically learn hierarchical feature representations from data, Convolutional Neural Networks (CNNs) revolutionized object detection. Deep learning has been shown to have great potential in computer vision by pioneering works like AlexNet, which took first place in the 2012 ImageNet Large Scale Visual Recognition Challenge (ILSVRC). Building on these findings, scientists created CNN-based object detection models, such as Fast R-CNN, Faster R-CNN, and R-CNN, which used region proposal networks (RPNs) to improve object localization effectiveness. These models were the basis for numerous further developments in the field and saw notable gains in accuracy [80] [81].
3. YOLO for Real-Time Object Detection
Although CNN-based models significantly increased accuracy, their real-time applicability was frequently constrained by their computational cost. The You Only Look Once (YOLO) model family was created in response to this. By presenting object recognition as a single regression problem and predicting bounding boxes and class probabilities straight from entire images in a single network run, YOLO completely rewrote the object detection paradigm. After YOLOv1, variants like YOLOv3 and YOLOv5 showed incredible speed and effectiveness, which qualified them for real-time applications. Nevertheless, there were still issues in managing small items and attaining high precision in congested areas [61] [3].
4. Transformations in Vision: A New Development
By using the self-attention mechanism to simulate long-range dependencies and global context within images, Vision Transformers have more recently become a potent alternative to CNNs. The Vision Transformer (ViT) was introduced by Dosovitskiy et al., which was a noteworthy milestone as it showed that transformers, which were initially intended for use in natural language processing, could perform at the cutting edge when it came to picture classification tasks. Though they are frequently computationally demanding and need large-scale datasets for training, vision transformers have advantages in capturing complex relationships and context within congested situations [64] [66].
5. Present Trends and Hybrid Methodologies
Considering the advantages and disadvantages of each methodology, hybrid models—which integrate several approaches to take use of their complementary qualities—have become more and more prevalent in recent study. By combining the global context modeling of Vision Transformers, the reliable feature extraction of CNNs, and the real-time efficiency of YOLO, hybrid models seek to improve object identification performance. Compared to using only one technique, this multifaceted approach aims to handle the various issues associated with crowd object recognition.
C. Conclusion
This background gives a thorough account of the development of crowd object recognition techniques, emphasizing significant turning points and innovations. The shift from manually created features to deep learning models and the subsequent emergence of transformers highlights how dynamic this field of research is. In order to push the limits of what is possible in crowd object recognition, the ongoing investigation of hybrid approaches, which seeks to combine the best features of current algorithms, provides a promising direction. With the help of this study of the literature, we hope to fill in knowledge gaps and suggest innovative approaches that push the boundaries of the field and eventually lead to more dependable and efficient object detection systems in congested areas.
XII. RELATED WORKS
Over the past few decades, object detection has advanced significantly, especially with the introduction of deep learning algorithms. This section examines the relevant literature that has aided in the growth and advancement of crowd object identification, emphasizing important approaches and their unique benefits and drawbacks.
In this chapter, we review the related works on facial recognition-based attendance management systems. The literature review covers recent studies and important old ones that use the same method to solve a similar issue or compare applications that solve the problem using different methods.
A. Traditional Method
Conventional techniques for object detection mostly depended on manually created features and traditional machine learning algorithms. Introduced in 2001, the Viola-Jones detector was one of the first effective frameworks for real-time face identification. It detected faces in photos and videos using an AdaBoost classifier and Haar-like characteristics [82]. Notwithstanding its effectiveness, the Viola-Jones technique has trouble with occlusions and complicated backdrops, which are frequent in crowded spaces.
B. Convolutional Neural Networks (CNNs)
The introduction of CNNs resulted in a dramatic change in object detection techniques. In a variety of computer vision applications, CNNs beat conventional techniques thanks to their capacity to learn hierarchical feature representations. In this sector, Girshick et al.'s introduction of R-CNN (Regions with Convolutional Neural Networks) was revolutionary. Region suggestions were created by R-CNN utilizing selective search, and CNNs were subsequently utilized to classify them [47]. R-CNN's multi-stage pipeline, however, made it computationally costly. Subsequent advancements to R-CNN addressed its computational inefficiencies, including Fast R-CNN and Faster R-CNN. The training time was greatly shortened by Fast R-CNN by introducing a single-stage training procedure and the use of Region of Interest (RoI) pooling [83]. By incorporating a Region Proposal Network (RPN) that shared convolutional features with the detection network, Faster R-CNN enabled nearly real-time object identification, hence improving efficiency even further [45].
C. Single Shot Detectors (SSD) and YOLO
To achieve real-time object identification without sacrificing accuracy, the You Only Look Once (YOLO) family of models and Single Shot Detectors (SSD) were created. With the introduction of SSD by Liu et al., bounding boxes and class scores may be predicted straight from feature maps in a single pass, hence eliminating the requirement for region suggestions [84]. YOLO, on the other hand, concurrently predicted bounding boxes and class probabilities by framing object detection as a regression problem. YOLOv1 and its iterations YOLOv3 and YOLOv5 showed remarkable speed and accuracy, which qualified them for real-time applications [60], [61]. Despite achieving real-time performance, SSD and YOLO have trouble managing items in cluttered situations and recognizing small things. High object density and occlusions, which are common in these environments, were difficult for these models to handle.
D. Vision Transformers
When Vision Transformers were released, object detection saw a paradigm shift. Vision Transformers use the self-attention mechanism to simulate global context and long-range dependencies in visuals. Transformers were initially intended for natural language processing, but Dosovitskiy et al. showed that, with the right scaling, they could attain state-of-the-art performance in picture classification tasks [64]. Subsequently, Carion and colleagues presented the Detection Transformer (DETR), an end-to-end object detection system that made use of transformers. DETR made the detection pipeline simpler by doing away with the requirement for manually constructed elements like non-maximum suppression and anchors [66]. Vision Transformers have benefits, but they also need a lot of computing power and big datasets to train them well. Research on their use in crowded areas and real-time object detection is still ongoing.
E. Hybrid Approaches
In order to overcome the drawbacks of each strategy, recent research has concentrated on creating hybrid models that integrate the advantages of YOLO, CNNs, and Vision Transformers. By combining the global context modeling of Vision Transformers, the reliable feature extraction of CNNs, the real-time efficiency of YOLO, and the robustness of CNNs, hybrid models seek to improve detection performance in cluttered scenes. These models combine several approaches to better manage variable object scales, occlusions, and high object density.
F. Advanced Techniques in Object Detection
Apart from the basic models, a number of sophisticated methods have been put forth to enhance object recognition even further, especially in congested areas. To improve object detection at various scales, for example, Lin et al. proposed Feature Pyramid Networks (FPN). Using feature map pyramids created at different scales, FPNs improve the accuracy of object detection [85]. To achieve real-time object identification, another method called the Single Shot Multibox Detector (SSD) merged the concepts of multi-scale feature maps with anchor boxes [52].
G. Crowd-Specific Object Detection
Additionally, specialized models have been created to handle the particular difficulties associated with crowd item recognition. Zhang et al.'s multi-column CNN (MC-CNN) research was done to address the high density and occlusions that are common in crowded scenes. To record objects of different scales, MC-CNNs employ several columns with distinct receptive fields [86]. Similarly, to increase accuracy in congested settings, Sam et al.'s work proposed a density-aware technique that integrates object detection frameworks with density maps [87].
H. Real-World Utilization and Datasets
A number of benchmarks and datasets have been developed to support crowd object detection research. Because of its demanding and diversified image set, the COCO (Common Objects in Context) dataset is frequently used to assess object detection models [31]. Another significant dataset is CrowdHuman, which was created with the express purpose of identifying people in crowded environments. It is an invaluable tool for testing and refining detection models tailored to individual crowds [88] [15].
I. Conclusion
Significant progress has been made in object detection procedures throughout the years, moving from manual feature-based methods to deep learning-based techniques. While each solution has helped to overcome distinct obstacles, there are still some limitations, especially in congested spaces. Future research should focus on hybrid approaches, which integrate the most effective features of current techniques to enhance crowd object recognition. This survey of relevant literature emphasizes how dynamic the subject is and how continuous efforts are made to create object detection systems that are more dependable and efficient.
XIII. ACKNOWLEDGMENT
I would like to express our heartfelt gratitude to the following professors who have played an instrumental role in the successful completion of this project. Their expertise, guidance, and support have been invaluable throughout this journey.
Our supervisor, Dr. Tarek Ali for his valuable suggestions and constructive criticism. I would also like to acknowledge his contributions, whose expertise in Advanced topics in Information Systems greatly enriched this study. We extend our thanks to our research collaborators for their collaboration and assistance in data collection, analysis and developing. I am indebted to Faculty of Graduate Studies for Statistical Research for providing the necessary resources and facilities to students and being flexible to our circumstances.
I would like to extend my heartfelt gratitude to our academic supervisor, Prof. Mervat Gheith for her unwavering support and expert guidance. Their mentorship and constructive feedback have been invaluable in shaping the research design and analysis.
Lastly, we want to express my appreciation to our families for their love, patience, and unwavering support throughout this endeavour.
Conclusion
In this paper we summarized the state of deep learning-based object detection as of right now in this study. We have offered the fair survey, encompassing several object detection models. The models were separated into four primary categories: transformer-based detectors, anchor-free detectors, one-stage anchor-based detectors, and two-stage anchor-based detectors. Using well-known object identification datasets such Pascal VOC and MS-COCO, we assessed each model. We found that the accuracy of single-stage detectors has increased and now rivals that of two-stage detectors. Additionally, as transformers have become more common in vision tasks, transformer-based detectors have shown excellent results. Two examples of these detectors are Swin-L and Swin V2, which in the MS-COCO dataset obtained mAPs of 57.7% and 63.1%, respectively. There are a few exciting new paths that academics are investigating in the field of object detection, which is a dynamic one that is always changing. A. Speed-accuracy Extended processing times and increased computational resources are needed to improve the accuracy of an object detection method. Faster processing speeds may result from decreasing accuracy, but detection performance may suffer. Therefore, in order to enable real-time and low-power applications, especially in complicated scenarios with occlusions or cluttered backgrounds, researchers continuously strive to enhance the accuracy and speed of object recognition algorithms by adopting more efficient architectures and training approaches. B. Small Object Detection Tiny object detection is a subset of object detection that specializes in locating and identifying extremely small things in pictures or videos. It is difficult since it is hard to extract information from small objects that have few pixels. These things could be so tiny that other objects in the scene partially obscure them or make them hardly noticeable at all. Numerous potentials uses for tiny item identification exist, including medical imaging, spotting minute flaws in industrial processes, and recognizing small creatures in wildlife monitoring. C. Multi-modal Object Detection entails identifying objects from many textual and visual sources, including pictures, movies, and audio, to provide more accurate and comprehensive object recognition in challenging situations. In applications like autonomous driving, where numerous sensors identify objects surrounding a car, multi-modal detection can be useful. D. Few-shot Learning The goal of few-shot learning is to create algorithms that can identify things based on a small number of samples. This is especially helpful when it\'s expensive or difficult to gather a lot of labeled data. These models are suitable for low-data or low-resource environments. However, taken into account that deep learning-based object detection has a bright future ahead of it, full with fascinating new discoveries for investigation. A. Entire Performance Assessment A detailed grasp of the advantages and disadvantages of each of YOLOv5, CNNs, and Vision Transformers in congested settings will be obtained from their unique assessments. This basic study is important to determine the strengths and weaknesses of each model, especially in high-density, occluded, and varied-scale circumstances. B. Creation of a Sturdy Hybrid Model The proposed hybrid model tries to solve the difficulties of crowd item recognition more successfully than any single solution by combining the powerful feature extraction of CNNs, the global context modeling of Vision Transformers, and the real-time detection capabilities of YOLOv5. The hybrid model will be suitable for real-world applications because of the iterative design and optimization process, which guarantees that accuracy and computational efficiency are balanced. C. Comparative Advantage The hybrid model will be shown to be superior in terms of precision, recall, average precision (AP), and processing time by a comparison analysis with state-of-the-art models. This will support the theory that combining several cutting-edge approaches will significantly increase detection performance, particularly in difficult packed settings. D. Deployment in Real Life The implementation of the hybrid model in real-world situations will demonstrate its usefulness and efficacy. Through performance validation in real-world settings like autonomous cars and surveillance systems, the study will demonstrate the model\'s adaptability, scalability, and potential for widespread use. E. Progress in Object Recognition By offering a unique hybrid strategy that makes use of the advantages of several approaches, the research will enhance object detecting technology. It is anticipated that this contribution would improve crowd object identification systems\' capabilities, improving their performance in a number of real-world applications. F. Prospective Routes for Research The results of this study will open up new avenues for developing and improving the hybrid model. Future study could look into new developments in machine learning and computer vision that could be incorporated into the hybrid approach, as well as further integration approaches and model optimization for certain use cases. In conclusion, crowd object detection technology will advance significantly if the stated goals and objectives are successfully met. It is anticipated that the hybrid model, which combines CNNs, Vision Transformers, and YOLOv5, will be able to overcome the drawbacks of current methods and offer a more accurate, effective, and useful way to detect objects in congested surroundings. In addition to adding to the body of knowledge in academia, this research will directly affect a number of sectors that need dependable crowd item detection systems.
References
[1] Krizhevsky, I. Sutskever and G. E. Hinton, “ImageNet Classification with Deep Convolutional Neural Networks,” in Advances in Neural Information Processing Systems (NIPS), NV, USA, 2012. [2] J. Wang, K. Yu, C. Dong, C. C. Loy and Y. Qiao, “Vision Transformers,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2020. [3] B. A, C. Y. Wang and H. Y. M. Liao, “YOLOv4: Optimal Speed and Accuracy of Object Detection,” arXiv preprint arXiv:2004.10934, USA, 2020. [4] J. Redmon, S. Divvala, R. Girshick and A. Farhadi, “You Only Look Once: Unified, Real-Time Object Detection,” in Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2016. [5] W. Zhiqiang and L. Jun, “Areviewofobjectdetectionbasedonconvolutional neural network,” in 36th Chinese Control Conference (CCC), 2017. [6] L. Jiao, F. Zhang, F. Liu, S. Yang, L. Li, Z. Feng and R. Qu, “A Survey of Deep Learning-Based Object Detection,” IEEE Access, vol. 7, 2019. [7] A. Borji, M. M. Cheng, Q. Hou, H. Jiang and J. Li, “Salient object detection: A survey, Comp. Visual Media.,” vol. 5, no. https://doi.org/10.1007/s41095-019-0149-9, p. 117–150, 2019. [8] W. Wang, Q. Lai, H. Fu, J. Shen, H. Ling and R. Yang, “SalientObjectDetec- tion in the Deep Learning Era: An In-Depth Survey,” EEE Transactions on Pattern Analysis and Machine Intelligence. , vol. 44, no. https://doi.org/10.1109/TPAMI.2021.3051099, p. 3239–3259, 2022. [9] K. Tong and Y. Wu, “Deep learning-based detection from the perspective of small or tiny objects: A survey, Image and Vision Computing.,” no. https://doi.org/10.1016/j.imavis.2022.104471, p. 123, 2022 [10] N. D. Nguyen, T. Do, T. D. Ngo and D. D. Le, “An Evaluation of Deep Learning Methods for Small Object Detection,” Journal of Electrical and Computer Engineering. , vol. e3189691, no. https://doi.org/10.1155/2020/3189691, 2020. [11] Y. Liu, P. Sun, N. Wergeles and Y. Shang, “A survey and performance evaluation of deep learning methods for small object de- tection, Expert Systems with Applications.,” vol. 114602, no. https://doi.org/10.1016/j.eswa.2021.114602, p. 172, 2021. [12] X. Wu, D. Sahoo and S. C. Hoi, “Recent advances in deep learning for object detection,” Neurocomputing, no. https://doi.org/10.1016/j.neucom.2020.01.085, pp. 39-64, 2020. [13] P. Viola and M. Jones, “Rapid Object Detection using a Boosted Cascade of Simple Features”. [14] N. Dalal and B. Triggs, “Histograms of Oriented Gradients for Human Detec- tion,” in 2005 IEEE Computer Society Conference on Computer Vision and Pattern Recognition (CVPR’05), San Diego, 2005. [15] P. Felzenszwalb, D. McAllester and D. Ramanan, “A discriminatively trained, multiscale, deformable part model,” in 2008 IEEE Conference on Com- puter Vision and Pattern Recognition, Anchorage, AK, USA, 2008. [16] S. Ullman, M. Vidal-Naquet and E. Sali, “Visual features of intermediate complexity and their use in classification,” Nat Neurosci, vol. 5, no. https://doi.org/10.1038/nn870, p. 682–687, 2002. [17] J. Sivic, B. C. Russell, A. A. Efros, A. Zisserman and W. T. Freeman, “Discovering objects and their location in images,” in Tenth IEEE International Conference on Computer Vision (ICCV’05)IEEE, Beijing, China, 2005. [18] S. Agarwal and D. Roth, “Learning a Sparse Representation for Object Detection,” in Computer Vision — ECCV 2002, Springer Berlin Heidelberg, Berlin, Heidelber, Berlin, 2002. [19] T. K. H. Schneiderman, “Object Detection Using the Statistics of Parts, International Journal of Computer Vision,” 2004. [20] J. U. T. G. A. S. K.E.A. van de Sande, “Segmentation as selective search for object recognition,” in 2011 Interna- tional Conference on Computer Vision, Barcelona, Spain, 2011. [21] D. Lowe, “Distinctive Image Features from Scale-Invariant Key- points,” International Journal of Computer Vision, vol. 60, no. https://doi.org/10.1023/B:VISI.0000029664.99615.94, pp. 91-110, 2004. [22] J. M. R. Lienhart, “An extended set of Haar-like features for rapid object detection,” in Proceedings. International Conference on Image Processing, Rochester, NY, USA, 2002. [23] T. T. L. V. G. H. Bay, “SURF: Speeded Up Robust Features,” in A. Leonardis, H. Bischof, A. Pinz (Eds.), Computer Vision – ECCV, Springer Berlin Heidelberg, Berlin, Heidelberg, 2006. [24] T. K. J. K. J. K. F. M. J. M. M. N. O. N. C. P. R. B. S. M. S. D. T. D. T. M. V. G. W. M. C. V. L.-. e. C. S. P. F. D. Hutchison, “BRIEF: Binary Robust Independent Elementary Features,” in K. Daniilidis, P. Maragos, N. Paragios (Eds.), Computer Vision – ECCV 2010, Springer Berlin Heidelberg, Berlin, Heidelberg, 2010. [25] V. V. C. Cortes, “Support-vector networks, Mach Learn,” vol. 20, no. https://doi.org/10.1007/BF00994018, 273–297 1995. [26] R. S. Y. Freund, “A Decision-Theoretic Generalization of On-Line Learning and an Application to Boosting,” Journal of Computer and System Sciences, vol. 55, no. https://doi.org/10.1006/jcss.1997.1504, p. 119–139, 1997. [27] P. H. T. Cover, “Nearest neighbor pattern classification,” IEEE, Trans. Inform. Theory, vol. 13, no. https://doi.org/10.1109/TIT.1967.1053964, pp. 21-27, 1967. [28] L. V. G. C. W. J. W. A. Z. M. Everingham, “The Pascal Visual Object Classes (VOC) Challenge, Int J Comput Vis,” vol. 88, no. https://doi.org/10.1007/s11263-009-0275-4, pp. 303-338, 2010. [29] “ImageNet Large Scale Visual Recognition Competition,” 2010. [Online]. Available: http://www.image- net.org/challenges/LSVRC/2010/. [Accessed October 22, 2019]. [30] M. D. o. Y. LeCun’s. [Online]. Available: http://yann.lecun.com/exdb/lenet/. [31] M. M. S. B. L. B. R. G. J. H. P. P. D. R. C. Z. P. D. T.-Y. Lin, “Microsoft COCO: Common Objects in Context, ArXiv:1405.0312,” 2015. [Online]. Available: http://arxiv.org/abs/1405.0312. [32] “.-. l. O.Russakovskyetal., vol. 115, p. 211–252, 2015. [33] A. K. e. al., “The Open Images Dataset V4,” vol. 128, p. 1956–1981, Jul 2020. [34] I. S. G. H. A. Krizhevsky, “ImageNet Classification with Deep Convolutional Neural Networks,” F. Pereira, C.J.C. Burges, L. Bottou, K.Q. Weinberger (Eds.), Advances in Neural Information Processing Systems 25, no. http://papers.nips.cc/paper/4824-imagenet-classification-with-deep- convolutional-neural-networks.pdf, p. 1097–1105, 2012. [35] A. Z. K. Simonyan, “Very Deep Convolutional Networks for Large-Scale Image Recognition,” 2014. [Online]. Available: http://arxiv.org/abs/1409.1556. [36] S. I. V. V. a. A. A. A. C. Szegedy, “Inception-v4, inception-ResNet and the impact of residual connections on learning,” in Proceedings of the Thirty-First AAAI Conference on Artificial Intel- ligence, San Francisco, California, USA, 2017. [37] W. L. Y. J. P. S. S. R. D. A. D. E. V. V. A. R. C. Szegedy, “Going deeper with convolutions,” in IEEE Conference on Computer Vision and Pat- tern Recognition (CVPR), IEEE, Boston, MA, USA, 2015. [38] H. M. C.-Y. W. C. F. T. D. a. S. X. Z. Liu, “A ConvNet for the 2020s,,” in CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. [39] V. S. J. Z. C.Szegedy, “Rethinking the Inception Architecture for Computer Vision,” in 2016 IEEE Confer- ence on Computer Vision and Pattern Recognition (CVPR), 2016. [40] P. G. R. G. K. H. P. D. T.-Y. Lin, “Focal Loss for Dense Object Detection”. [41] A. F. J. Redmon, “YOLO9000: Better, Faster, Stronger, ArXiv:1612.08242,” 2016. [Online]. Available: http://arxiv.org/abs/1612.08242. [42] X. Z. Z. L. W. Z. J. S. T. Yang, “MetaAnchor: learning to detect objects with customized anchors,” in Proceedings of the 32nd International Conference on Neural Information Processing Systems, Red Hook, NY, USA, 2018. [43] K. C. S. Y. C. L. D. L. J. Wang, “Region Proposal by Guided Anchoring,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. [44] K. v. d. S. T. G. A. S. J.R.R. Uijlings, “Selective Search for Object Recognition,” in Int J Comput Vis, 2013. [45] K. H. R. G. J. S. S. Ren, “Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks,” in IEEE Trans. Pattern Anal. Mach. Intell, 2017. [46] R. Girshick, “Fast R-CNN, ArXiv:1504.08083,” 2015. [Online]. Available: http://arxiv.org/abs/1504.08083. [47] J. R.Girshick, “Rich feature hierarchies for accurate object detection and semantic segmentation,” 2013. [Online]. Available: http://arxiv.org/abs/1311.2524. [Accessed October 8, 2019]. [48] G. G. P. D. R. G. K. He, “Mask R-CNN, ArXiv:1703.06870,” [Online]. Available: http://arxiv.org/abs/1703.06870 (acc. [Accessed October 8, 2019]. [49] Q. F. R. F. N. V. Z. Cai, “A Unified Multi-scale Deep Convolutional Neural Network for Fast Object Detection,” in B. Leibe, J. Matas, N. Sebe, M. Welling (Eds.), Computer Vision – ECCV 2016,, 2016. [50] C. Y.He, “BoundingBoxRegression With Uncertainty for Accurate Object Detection,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. [51] K. C. J. S. H. F. W. O. D. L. J. Pang, “Libra R-CNN: Towards Balanced Learning for Object Detection,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2019. [52] D. A. D. E. C. S. S. R. C.-Y. F. A. B. W. Liu, “SSD: Single Shot MultiBox Detector, ArXiv:1512.02325 [Cs],” 2016. [Online]. Available: https://doi.org/10.1007/978-3-319-46448-0_2. [53] B. N. C. G. J. H. Y. X. P. Zhou, “Scale-Transferrable Object Detection,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, 2018. [54] Z. L. J. L. Y.-G. J. Y. C. X. X. D. Z. Shen, “Learning Deeply Supervised Object Detectors from Scratch,” in 2017 IEEE Interna- tional Conference on Computer Vision (ICCV), 2017. [55] D. H. Y. W. S. Liu, “Receptive Field Block Net for Accurate and Fast Object Detection,” in Computer Vision – ECCV 2018: 15th European Conference, Munich, Germany, September 8-14, 2018. [56] L. W. X. B. Z. L. S. L. S. Zhang, “Single-Shot Refinement Neural Network for Object Detection,” in 2018 IEEE/CVF Conference on Computer Vision and Pattern Recognition, , Salt Lake City, UT, 2018. [57] H.-K. K. J.-Y. S. M.-C. K. S.-J. K. S.-W. Kim, “Paral- lel Feature Pyramid Network for Object Detection,” in V. Ferrari, M. Hebert, C. Sminchisescu, Y. Weiss (Eds.), Computer Vision – ECCV, 2018. [58] J. L. W. L. J. S. J. W. L. D. Z. C. C. H. J. Z. K. Chen, “Towards Accurate One-Stage Object Detection With AP-Loss,” in 2019 IEEE/CVF Conference on Computer Vision and Pattern Recog- nition (CVPR), Long Beach, CA, USA, 2019. [59] W. D. R. S. L.-J. L. K. L. L. F.-F. J. Deng, “ImageNet: A Large-Scale Hierarchical Image Database, (n.d.) 8,” [Online]. [60] S. D. R. G. A. F. J. Redmon, “You Only Look Once: Unified, Real-Time Object Detection,” in 2016 IEEE Conference on Com- puter Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 2016. [61] A. F. J. Redmon, “YOLOv3: An Incremental Improvement, (n.d.) 6,” [Online]. [62] A. B. a. H.-Y. M. L. C.-Y. Wang, “YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors,” 2022. [Online]. [63] A. B. H.-Y. L. C.-Y. Wang, “Scaled-YOLOv4: Scaling Cross Stage Partial Network,” in 2021 IEEE/CVF Conference on Com- puter Vision and Pattern Recognition (CVPR), 2021. [64] L. B. A. K. D. W. X. Z. T. U. M. D. M. M. G. H. S. G. J. U. N. H. A. Dosovitskiy, “An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale,” 2020. [65] Y. L. R. R. A. H. D. C. J. C.-. l. T. L. G. S.-K. K. R. S. Rao, “An Explainable Transformer-Based Deep Learning Model for the Prediction of Incident Heart Failure,” IEEE Journal of Biomedical and Health Informatics, vol. 26, p. 3362–3372, 2022. [66] F. M. G. S. N. U. A. K. S. Z. N. Carion, “End-to-End Object Detection with Transformers,” 2020. [Online]. Available: https://doi.org/10.48550/ARXIV.2005.12872. [67] N. S. N. P. J. U. L. J. A. G. L. K. I. P. A. Vaswani, “Attention Is All You Need, ArXiv:1706.03762 [Cs],” 2017. [Online]. Available: http://arxiv.org/abs/1706.03762. [Accessed March 4, 2021]. [68] M. Z. X. W. J. D. H. L. P. Gao, “Fast Convergence of DETR with Spatially Modulated Co-Attention, in: 2021 IEEE/CVF Interna- tional Conference on Computer Vision (ICCV),” 2021. [69] Y. L. Y. C. H. H. Y. W. Z. Z. S. L. B. G. Z. Liu, “Swin Transformer: Hierarchical Vision Transformer using Shifted Windows,” in 2021 IEEE/CVF International Conference on Computer Vision (ICCV), 2021. [70] X. Z. T. Y. J. S. Y. Wang, “Anchor DETR: Query Design for Transformer-Based Object Detection,” 2021. [Online]. Available: https://doi.org/10.48550/ARXIV.2109.07107. [71] S. T. L. He, “DESTR: Object Detection with Split Transformer,” in 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2022. [72] X. W. D. &. K. P. Zhou, “Objects as points. arXiv preprint arXiv:1904.07850,” 2019. [Online]. [73] J. &. F. A. Redmon, “YOLOv3: An incremental improvement. arXiv preprint arXiv:1804.02767.,” 2018. [Online]. [74] T.-Y. D. P. G. R. H. K. H. B. &. B. S. Lin, “Feature pyramid networks for object detection,” in In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR)., 2017. [75] S. H. K. G. R. &. S. J. Ren, “Faster R-CNN: Towards real-time object detection with region proposal networks. In Advances in Neural Information Processing Systems (NIPS).,” 2015. [76] N. M. F. S. G. U. N. K. A. &. Z. S. Carion, “End-to-end object detection with transformers. In European Conference on Computer Vision (ECCV),” 2020. [77] A. B. L. K. A. W. D. Z. X. U. T. .. &. H. N. (. Dosovitskiy, “An image is worth 16x16 words: Transformers for image recognition at scale,” 2020. [Online]. Available: arXiv preprint arXiv:2010.11929. [78] W. A. D. E. D. S. C. R. S. F. C.-Y. &. B. A. C. Liu, “SSD: Single shot multibox detector. In European Conference on Computer Vision (ECCV),” 2016. [Online]. [79] A. W. C.-Y. &. L. H.-Y. M. Bochkovskiy, “YOLOv4: Optimal speed and accuracy of object detection. arXiv preprint arXiv:2004.10934.,” 2020. [Online]. [80] J. D. T. D. a. J. M. R. Girshick, “Rich feature hierarchies for accurate object detection and semantic segmentation,” in IEEE conference on computer vision and pattern recognition, 2014. [81] K. H. R. G. a. J. S. S. Ren, “Faster R-CNN: Towards real-time object detection with region proposal networks,” Advances in Neural Information Processing Systems, 2015. [82] P. V. a. M. Jones, “Rapid object detection using a boosted cascade of simple features,” in Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, 2001. [83] R. Girshick, “Fast R-CNN,” in International conference on computer vision, 2015. [84] W. L. e. al., “SSD: Single shot multibox detector,” in European Conference on Computer Vision, 2016. [85] P. D. R. G. K. H. B. H. a. S. B. T.-Y. Lin, “Feature pyramid networks for object detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2017. [86] H. L. X. W. a. X. Y. C. Zhang, “Cross-scene crowd counting via deep convolutional neural networks,” in IEEE Conference on Computer Vision and Pattern Recognition, 2015. [87] S. P. a. V. S. S. S. Sam, “Density-aware object detection in aerial imagery,” in IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 2020. [88] L. S. e. al., “CrowdHuman: A benchmark for detecting human in a crowd,” 2018. [Online]. Available: arXiv preprint arXiv:1805.00123. [89] Q. L. M. Tan, “EfficientNet: Rethinking Model Scaling for Convolu- tional Neural Networks,” 2020. [Online]. Available: http://arxiv.org/abs/1905.11946. [Accessed August 2, 2022].
Copyright
Copyright © 2024 Mahmoud Atta Mohammed Ali, Dr. Tarek Ali, Prof. Mervat Gheith. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET63293
Publish Date : 2024-06-14
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online