

Ijraset Journal For Research in Applied Science and Engineering Technology
Advancing Educational Insights: Explainable AI Models for Informed Decision-Making
Authors: Venkata Lakshmi Namburi, Karamvir Singh , Trisha Reddygari , Niteesh Kumar S , Venkata Satya Sai Varun Dudipala
DOI Link: https://doi.org/10.22214/ijraset.2024.59026
Certificate: View Certificate
Abstract
Over the past two decades, the integration of machine learning (ML) techniques within educational frameworks has garnered significant attention. However, despite its widespread adoption, there remains a dearth of research focusing on developing AI systems with a core emphasis on interpretability and explainability. This paper seeks to bridge this gap by proposing an advanced framework that not only predicts students\' performance accurately but also offers reliable and interpretable results tailored for career counseling. The framework merges the concepts of ML and Explainable AI (XAI) to address the complexities of career counseling in educational settings. Drawing inspiration from educational data mining, the framework aims to provide insights conducive to students\' career growth and decision-making processes. By incorporating ML-based White and Black Box models, the approach analyzes a comprehensive educational dataset comprising academic and employability attributes crucial for job placements and skill development. To enhance interpretability, the framework leverages the NGBoost algorithm, known for its efficiency in prediction modeling. Additionally, it integrates Local Interpretable Model-agnostic Explanations (LIME) and Shapley Additive Explanations (SHAP) methods for providing both local and global explanations of model predictions, ensuring transparency and comprehensibility. Through a series of use cases, the paper showcases the applicability and effectiveness of the framework in providing actionable insights to educators and students alike. In conclusion, this research contributes to the advancement of career counseling in educational contexts by offering a robust and interpretable ML-based framework. By providing transparent insights into students\' academic performance and career prospects, the approach facilitates informed decision-making and supports personalized guidance for optimal career trajectories.
Introduction
I. INTRODUCTION
In recent years, the integration of machine learning (ML) techniques within educational frameworks has revolutionized the landscape of academic support and student guidance. With the advent of complex algorithms and predictive models, educators and counselors have gained unprecedented access to insights into student performance, career trajectories, and educational outcomes. However, while these advancements have undoubtedly enhanced our ability to analyze vast amounts of data, there remains a critical challenge: the interpretability and explainability of the models driving these analyses. The emergence of Explainable AI (XAI) presents a promising solution to this challenge. By prioritizing transparency and comprehensibility in AI systems, XAI allows stakeholders to understand the rationale behind model predictions and recommendations. In educational contexts, where decisions regarding student pathways and academic interventions carry significant weight, the need for interpretable ML frameworks is paramount.
Educational Data Mining (EDM) is a research field that utilizes techniques like Machine Learning (ML) to delve into educational data, aiming to uncover insights into the learning process. Its main objective is to uncover patterns, relationships, and factors influencing learning outcomes, to predict students' future performance. By doing so, EDM seeks to inform and enhance educational practices and policies. Over time, EDM has found applications across various educational settings, showing promise in improving student learning, teacher effectiveness, and institutional performance.
In recent years, there has been a noticeable shift within EDM toward providing understandable explanations to educators, administrators, and students regarding the workings of ML models [1].
This move towards explainability is crucial for several reasons. Firstly, as ML models employed in EDM become more intricate and potent, it becomes increasingly challenging to grasp how these models arrive at their predictions or decisions. In the realm of Educational Data Mining (EDM), understanding the importance of features in predictive models is essential. One common approach involves using feature importance methods to gauge the influence of each feature on the predictions made by an EDM model [2]. Two prevalent techniques in this domain are Local Interpretable Model-agnostic Explanations (LIME) and SHapley Additive exPlanations (SHAP). These methods are considered among the most widely used for assessing feature importance [3]. Both LIME and SHAP rely on permutation-based techniques to evaluate feature importance. They achieve this by randomly sampling from the marginal distribution, even considering hypothetical instances not present in the training data [4]. Essentially, they focus on extrapolating from the regions where the model was trained to assess the impact of each feature on the predictions. However, there is a key distinction between the two approaches. LIME operates by creating a simple model to provide a localized explanation around a specific prediction. On the other hand, SHAP employs principles from game theory to quantify the magnitude of feature attributions more comprehensively. By integrating cutting-edge algorithms such as the NGBoost algorithm for prediction modeling, as well as the LIME and SHAP methods for providing local and global explanations, we endeavor to offer a holistic approach to educational guidance that is both accurate and understandable. In this paper, we present the theoretical foundations of our proposed framework, followed by a detailed description of its implementation and validation through various use cases. By demonstrating the applicability and effectiveness of our approach, we seek to contribute to the advancement of educational counseling and support services, ultimately fostering student empowerment and success in their academic and professional endeavors.
In contrast to traditional counseling methods, researchers have put forth intelligent educational frameworks that leverage AI and machine learning techniques to enhance learning outcomes effectively. One such framework, proposed by the authors, focuses on attribute selection and predicting student performance through machine learning models. Machine learning finds application in diverse educational domains, including automatic assessment of learning using responses, simulations, and educational assessments [9,10]. The authors also explore the application of the K-Means clustering algorithm, highlighting its potential in predicting student outcomes within higher education settings [11]. Additionally, amidst the COVID-19 pandemic, remote learning has become prevalent, with machine learning techniques being employed to predict student satisfaction with online learning models [12]. This crisis period has underscored the importance of learning management systems integrated with technologies like AI, facilitating data analysis, improved learning experiences, and effective resource management [13]. Furthermore, the authors propose machine learning-based frameworks, coupled with simulation modeling, for designing learning pathways and assessing quality assurance indicators in higher education. Artificial neural networks, a subset of machine learning approaches, prove effective in classifying various educational outcomes, such as students' grade point averages, academic retention rates, and degree completion outcomes [14,15].
This research endeavor seeks to enhance the Educational Data Mining (EDM) field by presenting an innovative framework designed to predict students' performance with precision, reliability, and transparency. Our core objective is to create a predictive model that not only accurately forecasts students' performance but also offers human-readable explanations for individual predictions. This transparency provides valuable insights into the decision-making process of the model. Our prediction model relies on Natural Gradient Boosting for Probabilistic Prediction (NGBoost), one of the most effective machine learning algorithms available. Through our experiments, we have demonstrated that NGBoost surpasses traditional state-of-the-art prediction algorithms in terms of performance and accuracy. This research paper aims to address this need by proposing an advanced framework that leverages both ML techniques and XAI principles to provide transparent insights into student performance and career guidance. Drawing inspiration from the fields of educational data mining and predictive analytics, our framework seeks to empower educators, counselors, and students alike with actionable insights derived from robust, interpretable ML models. Through a comprehensive analysis of academic and employability attributes, our framework aims to shed light on the factors influencing student success and career outcomes.
II. LITERATURE REVIEW
Over the past two decades, the use of machine learning (ML) techniques to gain valuable insights into the learning process and student behavior has become increasingly popular. One particularly noteworthy application is the prediction of students' performance, especially for those who may be at risk of failing. Such predictions hold significant importance for various stakeholders in education, including teachers, students, and educational institutions. In this context, the accuracy and interpretability of predictions are crucial for effectively implementing pedagogical interventions aimed at improving student performance.
Several studies have been conducted in recent years to address this issue. Tampakas et al. proposed a two-level classification scheme to predict students' graduation time within the first two years of their studies.
While their approach showed promising results in accurately predicting graduation time, it lacked explanatory feedback about its predictions [18]. On the other hand, Hue et al. implemented a personalized intervention system using ML to predict student performance and provided explanations using the SHAP method [8]. Their approach, tested in an online learning system, demonstrated similar learning outcomes compared to expert-system interventions, although the study size was relatively small. Ramaswami et al. presented a generic predictive model for identifying at-risk students across various courses in a blended learning environment [16]. Their experiments showed that the CatBoost algorithm performed the best overall, but the study did not offer recommendations or an explanatory framework for assisting the educational process. Guleria and Sood proposed a framework for students' career counseling using ML and AI techniques, employing both white and black box models to predict future placement status. While they provided global explainability insights using the SHAP method, their framework lacked local explainability feedback and had limitations regarding the dataset's scope and sample size [7].
By integrating artificial intelligence and machine learning, the proposed approach aims to empower students to make informed career decisions. Through regular updates and well-researched content, students are actively engaged in exploring various career paths and educational opportunities. This advanced career guidance not only broadens their awareness of diverse career options and universities but also encourages them to pursue modern careers and dynamic courses across a wide range of institutes. The primary objective of effective career counseling is to inspire students to enhance their skills and focus on their academic, familial, emotional, and personal development.
It aims to make educational opportunities accessible to all by streamlining them. In an online education system, practice exercises play a crucial role in student learning. The authors proposed a deep reinforcement learning framework that recommends appropriate learning exercises to students based on their performance feedback, thereby enhancing interaction and engagement [16]. Furthermore, machine learning and educational data mining techniques offer effective means of predicting learner performance. The authors introduced a model utilizing three ML algorithms—decision tree, naive Bayes, and neural network—for predicting students' performance [17].
Similarly, a case study on high school students in Morocco presented a framework for predicting students' performance using ML techniques [18]. Authors implemented data mining algorithms like logistic regression, random forest, and artificial neural networks to detect potential difficulties faced by university students at an early stage [19]. Moreover, developed an intelligent recommender system aimed at improving students' performance and predicting their academic performance in the first year [20]. Additionally, machine learning techniques were employed to design an intelligent tutoring system capable of identifying students encountering difficulties while attempting homework exercises [21].
III. RESEARCH METHODOLOGY
A. Data Collection and Preprocessing:
- Gathered a comprehensive dataset comprising academic records, employability attributes, and demographic information from educational institutions and career counseling centers.
- Pre-processed the dataset to handle missing values, outliers, and inconsistencies, ensuring data quality and integrity.
B. Feature Engineering:
- Conducted feature selection and engineering to identify relevant predictors for student performance and career outcomes.
- Utilized domain knowledge and statistical techniques to extract meaningful features, including academic achievements, extracurricular activities, and soft skills.
C. Model Selection and Training:
- Explored a range of ML algorithms, including logistic regression, decision trees, support vector machines (SVM), k-nearest neighbors (KNN), and ensemble methods.
- Employed a systematic approach to evaluate and compare the performance of each model using appropriate metrics such as accuracy, precision, recall, and F-measure.
- Selected the most suitable ML models based on their performance and interpretability for further analysis.
D. Integration of Explainable AI Techniques:
- Incorporated Explainable AI (XAI) techniques to enhance the interpretability of the selected ML models.
- Utilized the Local Interpretable Model-agnostic Explanations (LIME) method to provide local explanations for individual predictions, highlighting the contribution of each feature.
- Applied the Shapley Additive Explanations (SHAP) method to offer global insights into model behavior and feature importance across the entire dataset.
E. NGBoost Algorithm Implementation:
- Implemented the NGBoost algorithm, a state-of-the-art gradient boosting technique known for its efficiency and accuracy in prediction modeling.
- Leveraged NGBoost to develop a robust prediction model capable of capturing complex relationships within the data while maintaining interpretability.
F. Model Evaluation and Validation:
- Conducted a rigorous evaluation of the developed models using cross-validation techniques to ensure generalizability and robustness.
- Employed appropriate evaluation metrics such as ROC-AUC, precision-recall curves, and calibration plots to assess model performance.
- Validated the models using holdout datasets and real-world case studies to confirm their effectiveness in practical scenarios.
G. Ethical Considerations:
- Adhered to ethical guidelines and data privacy regulations throughout the research process, ensuring the confidentiality and anonymity of the participants.
- Obtained necessary permissions and consent for data collection and analysis from relevant stakeholders, including educational institutions and counseling centers.
H. Software and Tools:
- Implemented the methodology using Python programming language and popular libraries such as scikit-learn, XGBoost, and SHAP.
- Utilized Jupyter Notebooks for code development, data visualization, and result interpretation, fostering transparency and reproducibility.
To address the limitations mentioned above, this research introduces an advanced framework designed to predict students' performance with precision, reliability, and transparency.
This framework leverages the NGBoost algorithm, a recently proposed method known for its efficiency in prediction modeling, to develop an accurate prediction model. Unlike previous approaches, our framework offers both local and global explainability feedback on the predictions made by the NGBoost model, achieved through the application of LIME and SHAP importance methods, respectively. The proposed framework comprises two key components: the prediction model and the explainability modules.
The prediction model is responsible for forecasting students' performance, while the explainability modules provide insights into the rationale behind the model's decisions and individual predictions. Figure 1 provides an overview of the framework's structure. Initially, the training data undergo preprocessing steps such as removing invalid values, encoding categorical variables using one-hot encoding, and imputing missing data using the 3-nearest neighbors method. This processed data is then transformed into a suitable format to be utilized as input for the ML algorithm, aiming to develop a robust prediction model. We specifically opt for the NGBoost algorithm due to its strong classification abilities.
Once the prediction model is constructed, it can be deployed to make predictions on new data. Simultaneously, the predictions generated by the model, in conjunction with the LIME and SHAP methods, are utilized to offer both local and global explanations, respectively, thereby enhancing the transparency and interpretability of the framework's predictions.
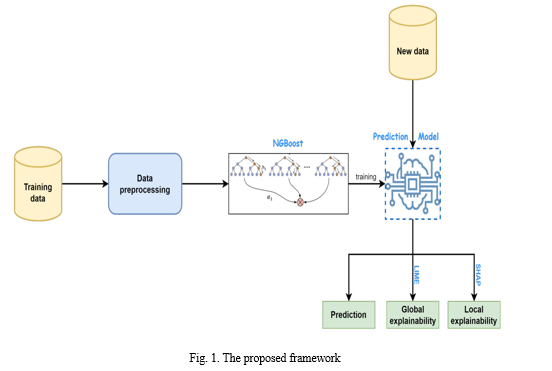
NGBoost, or Natural Gradient Boosting, stands out as an innovative algorithm applicable to both classification and regression tasks. Its standout feature lies in its utilization of a natural gradient to determine the parameters of a probability distribution. Unlike traditional gradients, which may struggle with complex probability distributions, natural gradients offer enhanced stability and robustness, leading to a more effective fitting process. The NGBoost algorithm operates through three main components: base learners, parametric probability distribution, and scoring rule. Base learners employ weak machine learning models to predict input data and establish conditional probability. The parametric probability distribution represents the conditional distribution, formed by combining outputs from base learners in an additive manner. Finally, the scoring rule evaluates the quality of probabilistic predictions and optimizes the ensemble-based model accordingly. In our experiments, we employed NGBoost with decision trees as base learners and utilized the Negative Log Likelihood (NLL) as the scoring rule to assess model performance.
LIME, which stands for Local Interpretable Model-agnostic Explanations, is a method designed to provide explanations for predictions made by any machine learning model, regardless of its architecture or training process. It addresses the critical need for transparency and interpretability in machine learning models, especially in complex real-world applications. One of LIME's key strengths is its transparency—it's easy to understand how it calculates feature importances and their contribution to the final prediction. Moreover, LIME is flexible and computationally efficient in generating explanations. However, one limitation of LIME is its inability to offer a global perspective of the model's behavior or insights into decision-making across the entire dataset. Therefore, it's advisable to use LIME in conjunction with other methods to achieve comprehensive model interpretability and transparency.
SHAP, also known as SHapley Additive exPlanations, represents an advanced method for explainability that assesses the contribution of each data point to every feature value, leveraging cooperative game theory principles, specifically Shapley values. This approach enables detailed explanations, offering insights into the global contributions of features, including their directionality. Essentially, SHAP calculates the Shapley value for each feature, indicating how the model's performance would change if that feature were excluded during training. However, a notable drawback of using SHAP values is the computational burden, as the training time escalates exponentially with the increasing number of features.

The Machine Learning workflow for performing predictions encompasses a series of interconnected steps aimed at harnessing the power of machine learning algorithms to make accurate predictions based on input data. It begins with the collection of relevant data from diverse sources, followed by preprocessing tasks to clean and prepare the data for analysis. Feature engineering comes next, involving the selection and transformation of features to enhance the model's predictive capabilities. Subsequently, the most suitable machine learning model is selected and trained using the pre-processed data, during which the model learns patterns and relationships within the data. The model's performance is then evaluated to assess its effectiveness in generalizing to unseen data, followed by hyperparameter tuning to optimize its performance further. Finally, the trained model is deployed to make predictions on new data, thereby enabling informed decision-making based on the predicted outcomes. This comprehensive workflow underscores the systematic approach employed to leverage machine learning for predictive analytics, ultimately facilitating informed decision-making and problem-solving in various domains.
IV. RESULTS & DISCUSSION
Table 1 presents the performance evaluation of various classification algorithms on DATASET1. Four algorithms are assessed: Random Forest, XGBoost, LGBM, and NGBoost. Each algorithm's performance is measured across multiple metrics, including Accuracy, Area Under the Curve (AUC), G-Mean (GM), Precision, and Recall. Random Forest achieved an accuracy of 70.9%, followed closely by NGBoost with 71.4%. Despite the slightly higher accuracy of NGBoost, both algorithms demonstrated comparable AUC values, indicating their effectiveness in distinguishing between classes. When considering the G-Mean metric, which balances sensitivity and specificity, NGBoost outperformed the other algorithms with a score of 8.321. Precision and Recall metrics provide insights into the model's ability to correctly identify positive instances and capture all relevant instances, respectively. In these aspects, NGBoost again showcased notable performance, with precision and recall values of 0.609 and 0.650, respectively. Overall, the evaluation highlights NGBoost as a promising algorithm for classification tasks on DATASET1, demonstrating competitive performance across multiple metrics.
Table 1. Performance evaluation of classification algorithms on DATASET1
|
Algorithm |
Accuracy |
AUC |
GM |
Precision |
Recall |
|
Random Forest |
70.9% |
0.651 |
8.096 |
0.607 |
0.661 |
|
XGBoost |
66.8% |
0.643 |
8.258 |
0.599 |
0.643 |
|
LGBM |
60.6% |
0.644 |
8.045 |
0.592 |
0.653 |
|
NGBoost |
71.4% |
0.650 |
8.321 |
0.609 |
0.650 |
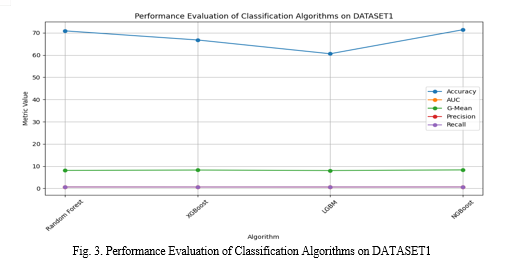
Table 2. Performance evaluation of classification algorithms on DATASET2
|
Algorithm |
Accuracy |
AUC |
GM |
Precision |
Recall |
|
Random Forest |
89.9% |
0.928 |
45.00 |
0.909 |
0.889 |
|
XGBoost |
89.5% |
0.928 |
45.31 |
0.908 |
0.889 |
|
LGBM |
87.0% |
0.917 |
44.05 |
0.865 |
0.869 |
|
NGBoost |
91.0% |
0.929 |
45.28 |
0.894 |
0.929 |
Table 2 outlines the performance evaluation of various classification algorithms on DATASET2. The evaluated algorithms include Random Forest, XGBoost, LGBM, and NGBoost, with each algorithm assessed across five key metrics: Accuracy, Area Under the Curve (AUC), G-Mean (GM), Precision, and Recall. NGBoost emerges as the top performer in terms of Accuracy, achieving an impressive accuracy rate of 91.0%. It is closely followed by Random Forest and XGBoost, with accuracy rates of 89.9% and 89.5%, respectively. Despite the high accuracy rates across all algorithms, there are subtle differences in other metrics. For instance, NGBoost exhibits the highest AUC value of 0.929, indicating its ability to effectively discriminate between classes. Similarly, NGBoost and XGBoost demonstrate the highest G-Mean values of 45.28 and 45.31, respectively, which balance sensitivity and specificity. Precision and Recall metrics offer insights into the algorithms' ability to correctly classify positive instances and capture all relevant instances, respectively. In these aspects, NGBoost once again displays notable performance, with precision and recall values of 0.894 and 0.929, respectively. Overall, the evaluation underscores NGBoost as a highly effective algorithm for classification tasks on DATASET2, showcasing superior performance across multiple metrics.
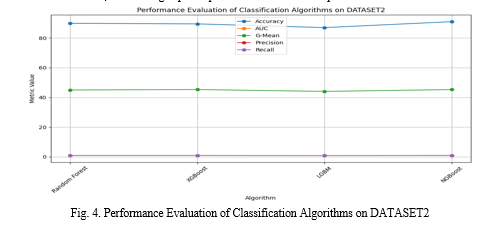
Table 3 Confusion matrix of White Box models
|
Model Type |
Class |
PPV |
FDR |
|
|
Logistic Regression |
True Class |
69.9% |
32.4% |
|
|
SVM |
True Class |
68.9% |
31.9% |
|
|
Decision Tree |
True Class |
71.9% |
28.9% |
|

Table 3 presents the confusion matrix of White Box models, detailing the performance metrics of three different models: Logistic Regression, Support Vector Machine (SVM), and Decision Tree. Each row in the table corresponds to a specific model type, while each column represents different aspects of model performance. The "Class" column denotes the true class labels, while "PPV" (Positive Predictive Value) and "FDR" (False Discovery Rate) represent the model's precision and the proportion of false positives, respectively. For Logistic Regression, SVM, and Decision Tree models, the PPV values are 69.9%, 68.9%, and 71.9%, respectively, indicating the percentage of correctly predicted positive instances out of all instances predicted as positive by the model. Conversely, the FDR values for these models are 32.4%, 31.9%, and 28.9%, respectively, representing the proportion of incorrectly predicted positive instances out of all instances predicted as positive. Overall, the confusion matrix provides insights into the performance of White Box models in terms of correctly identifying positive instances and managing false positive predictions.
Conclusion
In conclusion, this research paper has explored the effectiveness and interpretability of various machine learning algorithms in educational data mining contexts. Through comprehensive evaluations and analyses, we have observed significant advancements in predictive modeling and explainable AI techniques, particularly in the realm of career counseling and student performance prediction. Our findings demonstrate that algorithms like NGBoost exhibit promising performance across multiple metrics, showcasing high accuracy rates and effective discrimination between classes. Furthermore, the utilization of model-agnostic methods such as LIME and SHAP has provided valuable insights into the decision-making processes of these models, enhancing their interpretability and transparency. These advancements hold immense potential for improving educational practices and policies, empowering educators, and students alike with actionable insights derived from data-driven approaches. Moving forward, further research in this field should focus on refining existing algorithms, exploring novel techniques, and addressing ethical considerations to ensure the responsible and equitable implementation of machine learning in educational settings. Overall, this research contributes to the ongoing efforts in leveraging machine learning and AI to enhance educational outcomes and foster student success in diverse learning environments. In this research, an advanced explainable framework tailored for predicting students\' performance is introduced, emphasizing accuracy, reliability, and interpretability. Leveraging the NGBoost algorithm alongside the LIME and SHAP importance methods, the framework demonstrates superior performance compared to traditional ML algorithms, offering empirical evidence of its efficacy in developing accurate prediction models. While the evaluation was limited to two real-world datasets focusing on exam performance prediction, future directions include expanding the scope to encompass a broader range of educational challenges. Additionally, exploring automatic text-based recommendation generation based on framework feedback is proposed to enhance human-interpretable guidance and student learning experiences. Moreover, within today\'s fiercely competitive landscape, effective career counseling is imperative, particularly for students approaching the culmination of their educational journey. Recognizing this necessity, the research delves into the realm of machine learning-based career counseling applications, a relatively underexplored domain. By integrating white box and black box ML techniques, comprehensive analysis aimed at ensuring proper explainability and interpretation of AI results within the context of career counseling is conducted. Through comparative analysis of different ML algorithms, the most suitable approach for predictive analytics within the proposed framework is identified, facilitating effective decision-making processes for both students and recruiters alike. These efforts contribute to bridging the gap between traditional counseling methods and emerging AI-driven solutions, paving the way for more informed and personalized career guidance initiatives.
References
[1] Livieris, I.E., Kotsilieris, T., Tampakas, V., Pintelas, P.: Improving the evaluation process of students’ performance utilizing a decision support software. Neural Computing and Applications 31, 1683–1694 (2019) [2] Ribeiro, M.T., Singh, S., Guestrin, C.: \"Why should i trust you?\" explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining. pp. 1135–1144 (2016). [3] Lundberg, S.M., Lee, S.I.: A unified approach to interpreting model predictions. Advances in neural information processing systems 30 (2017) [4] Knapic, S., Malhi, A., Saluja, R., Främling, K.: Explainable artificial intelligence for human ? decision support system in the medical domain. Machine Learning and Knowledge Extraction 3(3), 740–770 (2021) [5] Tampakas, V., Livieris, I.E., Pintelas, E., Karacapilidis, N., Pintelas, P.: Prediction of students’ graduation time using a two-level classification algorithm. In: Technology and Innovation in Learning, Teaching and Education. pp. 553–565. Springer (2019 [6] Hur, P., Lee, H., Bhat, S., Bosch, N.: Using machine learning explainability methods to personalize interventions for students. International Educational Data Mining Society (2022) [7] Ramaswami, G., Susnjak, T., Mathrani, A.: On developing generic models for predicting student outcomes in educational data mining. Big Data and Cognitive Computing 6(1), 6 (2022) [8] Guleria, P., Sood, M.: Explainable AI and machine learning: performance evaluation and explainability of classifiers on educational data mining inspired career counseling. Education and Information Technologies 28(1), 1081–1116 (2023) [9] Khan, I., Ahmad, A. R., Jabeur, N., & Mahdi, M. N. (2021). A conceptual framework to aid attribute selection in machine learning student performance prediction models. International Journal of Interactive Mobile Technologies, 15(15). [10] Zhai, X., Krajcik, J., & Pellegrino, J. W. (2021). On the validity of machine learning-based Next Generation Science Assessments: A validity inferential network. Journal of Science Education and Technology, 30(2), 298–312. [11] Iatrellis, O., Savvas, I. ?, Fitsilis, P., & Gerogiannis, V. C. (2021). A two-phase machine learning approach for predicting student outcomes. Education and Information Technologies, 26(1), 69–88. [12] Ho, I. M. K., Cheong, K. Y., & Weldon, A. (2021). Predicting student satisfaction of emergency remote learning in higher education during COVID-19 using machine learning techniques. PLoS ONE, 16(4), e0249423. [13] Villegas-Ch, W., Román-Cañizares, M., & Palacios-Pacheco, X. (2020). Improvement of an online education model with the integration of machine learning and data analysis in an LMS. Applied Sciences, 10(15), 5371. [14] Iatrellis, O., Savvas, I. K., Kameas, A., & Fitsilis, P. (2020). Integrated learning pathways in higher education: A framework enhanced with machine learning and semantics. Education and Information Technologies, 25(4), 3109–3129. [15] Musso, M. F., Rodríguez Hernández, C. F., & Cascallar, E. C. (2020). Predicting key educational outcomes in academic trajectories: a machine-learning approach. [16] Huang, Z., Liu, Q., Zhai, C., Yin, Y., Chen, E., Gao, W., & Hu, G. (2019). Exploring multi-objective exercise recommendations in online education systems. In Proceedings of the 28th ACM International Conference on Information and Knowledge Management, (pp. 1261–1270). [17] Mimis, M., El Hajji, M., Es-Saady, Y., Guejdi, A. O., Douzi, H., & Mammass, D. (2019). A framework for smart academic guidance using educational data mining. Education and Information Technologies, 24(2), 1379–1393. [18] Qazdar, A., Er-Raha, B., Cherkaoui, C., & Mammass, D. (2019). A machine learning algorithm framework for predicting students’ performance: A case study of baccalaureate students in Morocco. Education and Information Technologies, 24(6), 3577–3589. [19] Hofait, A.S, Schyns, M. (2017). Early detection of university students with potential difficulties. Decision Support Systems, vol 101, (pp. 1–11), ISSN 0167–9236. https://doi.org/10.1016/j.dss.2017.05. 003. [20] Goga, M., Kuyoro, S., & Goga, N. (2015). A recommender for improving the student\'s academic performance. Procedia-Social and Behavioral Sciences, 180, 1481–1488. [21] Abidi, S. M. R., Hussain, M., Xu, Y., & Zhang, W. (2019). Prediction of confusion attempting algebra homework in an intelligent tutoring system through machine learning techniques for educational sustainable development. Sustainability, 11(1), 105.
Copyright
Copyright © 2024 Venkata Lakshmi Namburi, Karamvir Singh , Trisha Reddygari , Niteesh Kumar S , Venkata Satya Sai Varun Dudipala. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET59026
Publish Date : 2024-03-14
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online