

Ijraset Journal For Research in Applied Science and Engineering Technology
AGRICO - Smart Way of Farming
Authors: Prof. Dipali M. Mane, Gunja Gupta, Akash Shilimkar, Jaai Patwardhan, Trupti Shitole
DOI Link: https://doi.org/10.22214/ijraset.2023.53304
Certificate: View Certificate
Abstract
Research related to agriculture is growing rapidly, the challenges that lie ahead is solved with the help of advancement in technology. It is found that it is very beneficial for the economic growth and development of any nation. Especially in India, it requires the need for good research in order to improve agricultural productivity. In order to enhance the growth and solve the problems in the agricultural sector, the scientists use a variety of data mining methods. Different data mining techniques, like classification or prediction can be used to predict diseases in crops, and losses incurred as a result of these diseases. The diseases can be bacterial, fungal or viral. Some of the common plant diseases are bacterial wilt, black knot, curly top, etc. These diseases are caused by a variety of insects and micro- organisms. Our main focus in this research is on early identification of the diseases and helps the farmers in taking the decision to use the fertilizers that helps to protect the crops so that the diseases are eliminated in the early stage of production and so the farmers can get maximum yield. Ensemble method combines several classifiers to produce one finest predictive model and it is a very important technique in Machine Learning. In this paper, ensemble methods are used to predict the crop disease and an analyse has been done with the help of different classifiers such as Decision Trees, Naive Bayes Classifier, Random Forests, Support Vector Machine and K- Nearest Neighbour. Ensemble models, improves the performance of the classifiers that are weak. Te proposed machine learning approach that aims at predicting the best yielded crop for a particular region by analysing various atmospheric factors like rainfall, temperature, etc., and land factors like soil type including past records of crops grown. Finally, our system is expected to predict the best yielded crop based on dataset we have collected.
Introduction
I. INTRODUCTION
In India, Agriculture plays an important role for the economic development of the country. Crop prediction is a complicated process in agriculture and multiple models have been proposed and tested to this end. In recent times, modern people don’t have the complete awareness about the cultivation of the crops in a right season and at a right location. Due to which modern farmers lack the knowledge of proper selection of crops. Selecting a wrong crop for cultivation may lead to loss in achieving high yield rate and also simultaneously leads to shortage of food. These difficulties imply the need of smart farming which can be achieved with various machine learning algorithm. Machine Learning approaches are used in many fields, ranging from supermarkets to evaluate the behaviour of customers to the prediction of customers’ phone use. Machine learning is also being used in agriculture for several years. One of the most difficult challenges in agriculture is predicting crop production, and numerous models have been presented and confirmed to far. Since agricultural output varies on a variety of variables, including climate, weather, soil, and fertiliser application, this problem necessitates the use of several datasets. This indicates that crop yield prediction is not a trivial task; instead, it consists of several complicated steps. Nowadays, crop yield prediction models can estimate the actual yield reasonably, but a better performance in yield prediction is still desirable. been used for training is used for the performance evaluation purpose.
Machine learning, which is a branch of Artificial Intelligence (AI) focusing on learning, is a practical approach that can provide better yield prediction based on several features. Machine learning (ML) can determine patterns and correlations and discover knowledge from datasets. The models need to be trained using datasets, where the outcomes are represented based on past experience. The predictive model is built using several features, and as such, parameters of the models are determined using historical data during the training phase. For the testing phase, part of the historical data that has not been used for training is used for the performance evaluation purpose.
II. LITERATURE SURVEY
- Pooja Patil and Shivani Turamari presented a paper in 2022, paper name is Weather Forecast Prediction For agriculture published by IJERT Publisher In this paper they used machine learning technique to predict the weather forecasting for agriculture and terrace gardening. It is used to check what atmosphere will be in different lands and to estimate the weather condition for growing plants and Getting Yield.
- Dhanush Vishwakarma presented a system that will recommend the most suitable crop for particular land. Based on the weather parameter and soil content such as rainfall, temperature, humidity and PH. They are collected from V C Farm Mandaya, Government website and whether department. The system uses sensors to collect the necessary input from the farmers, such as temperature, humidity, and PH. The system recommends the crop for farmer and also recommends the amount of nutrients to be add for predicted crop. The system also displays the approximate yield in q/acre, the amount of seed needed to grow I kg/acre, and the crop's market price on the farm.
- .Rishi Gupta and Akhilesh Sharma presented a paper aims at collecting and analysing temperature, rainfall, soil, seed, crop production, humidity and wind speed data in a few regions, which will help the farmers improve the produce of their crops. Firstly, they pre-process the data in a Python environment and then apply the MapReduce framework, which further analyses and processes the large volume of data. Secondly, k-means clustering is used to analyse MapReduce outputs and produces an accurate mean result for the data.After that, they use bar graphs and scatter plots to study the relationship between the crop, rainfall, temperature, soil and seed type of two regions (Ahmednagar, Maharashtra and, Andaman and Nicobar Islands). Further, the system has been used to predict the crops and display them on a Graphic User Interface designed in a Flask environment. The system design is scalable and can be used to find the recommended crops of other states in a similar manner.
- B. Sridevi presented a system for agriculture. Main aim to produce this system is because A Farmer cannot invest a huge amount of money on an equipment like tractor, seed drill, harvester, roller, sprinkler system etc., instead they can provide them a solution by providing a platform for rental service. Though our farmers facing lots of issues, on the other hand the upcoming generation who are trying to involve themselves in farming couldn't approach the process as they don't have much knowledge in that. In order to mitigate the current status, there is a need for better recommendation system to alleviate this situation by helping them to make an informed decision before starting the cultivation of crops. Crop Management app provides a complete feature for Crop prediction, Crop and plant disease Prediction, and displays the soil testing centres.
- Research on the internet of things offers a framework through which farmers can gather significant data about the soil, crops growing in particular regions, and agricultural production and yield. This technology-based farming solution will help farmers make informed agricultural decisions by utilising resource optimisation and clever planning. In addition to improving quality and output, the development of IOT-based intelligent Smart Farming using smart devices is transforming how agriculture is produced by making farming more efficient and cost-effective. Obtaining real-time data on temperature, soil moisture, and humidity to monitor the environment is the aim of this smart agriculture or farming. Sensors for temperature, humidity, and moisture are used to do all of this.
III. SYSTEM METHODOLOGY
We have proposed a system which determines the best-suited crop depending on the percentage of nitrogen, phosphorous, and potassium in the soil; it
- Using weather condition, Soil type and moisture content information we can get to know which crop can be best grown in that particular region. We can generate the farm reports from the data collected and check our productivity.
- ML algorithms: Decision tree, Naïve Bayes, logistic regression also considers temperature, humidity, pH value, and rainfall in the surrounding. So, by considering all these input parameters a perfect crop for cultivation is predicted. This system or application predicts the crop based on the analysis done on the data from the dataset. In order to get the preferred output, we have tested the machine learning model using different algorithms such as Logistic Regression, Decision Tree, Naïve Bayes, and Random Forest; amongst these Random Forest classifier gave the best accuracy. This system also provides live weather prediction using Open Weather API and management of some farming activities. This proposed system reduces the need for costlier hardware and also the time to acquire the knowledge about suitable crops. Figure 1 overall shows the architecture of the proposed model.

Figure 2 shows the main functionalities of the Farm Track system.
IV. IMPLEMENTATION
- Dataset Overview: The first step to start with any machine learning technique is to gather the necessary data together in a file. Here, we have used a dataset from Kaggle. The data is collected in 8 different variables which are nitrogen (N), phosphorus (P), potassium (K), temperature, humidity, pH, rainfall and label.
Here, label is the target variable, i.e., predicted crop. Figure 3 shows the first 10 rows of the dataset.

2. Data Pre-processing: The subsequent step is to pre-process the data. Pre-processing converts the raw data into clean data. The missing values are removed by imputing the null values, if any from the dataset. Also, label encoding method converts word labels into numbers to let the algorithms work on them. For the structured dataset this is an important pre-processing step in supervised learning. This ensures that the data in the dataset are in the specified format for usage in the algorithm.
3. Splitting the Dataset: We need to split the dataset into training and testing before training the dataset for crop prediction.
4. Predicting the Crop: The prediction of suitable crop is dependent on various factors such as N, P, K, temperature, humidity, pH, and rainfall values in order to predict the crop accurately. These factors are given as input to the model. Based on the classification made by the algorithm, it provides a suitable crop to be cultivated by using random forest classifier giving 99.09% accuracy amongst 3 other algorithms which includes Logistic Regression, Decision Tree, Random Forest, and Naïve Bayes. These four classifiers were trained on the dataset.
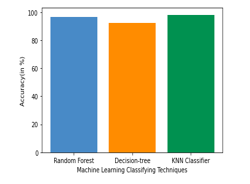

V. ALGORITHMS
A wide range of regression and classification-based prediction algorithms have been utilized to forecast crop yield. In crop yield prediction K-Nearest Neighbours (K-NN), Naïve Bayes, Decision tree (DT), Random Forest (RF), have been employed.
A. Machine Learning Algorithms
The K-NN is used for classification and regression that provides more weightage to close neighbours in making the prediction so that they relate more to the average than distant ones. DT is a model of supervised machine learning model which can be applied to both regression and classification. It consists of three
nodes, namely root node (no incoming edge), decision node (both incoming and outgoing edges) and leaf node (no outgoing edges). In a decision tree, each attribute is divided by each outgoing node into two or more branches according to the splitting criteria.
Breiman et al developed Classification and Regression Trees (CART) which is method of DT induction. which is supposed to nonparametric and generates binary trees from such data by employing the discrete and continuous features.
RF is a powerful tool for the prediction of yield, which has been applied to agricultural research. It generates a wide range of regression trees that are produced by a large set of decision trees for computing regression. The RF is superior to any other decision tree since it performs more precisely, and the bias is compensated for by the single decision tree due to the randomness. Extremely randomized trees (extra tree) (ERT) is an ensemble model as same as RF, but it utilizes unpruned decision trees. It splits the nodes by randomly chosen cut-points and incorporates the complete learning sample.
The number of trees and the number of variables utilized to divide the nodes are set to be the same as those of RF. An ANN is the most commonly utilized machine learning technique to predict crop yield by which the complex nonlinear relationship between input and output can be modelled. It comprises of three layers, including the input layer, hidden layer and output layer. There are numerous factors that have an impact on the performance of ANN, including the number of nodes in the hidden layer, the learning rate, and the training tolerance. The learning rate determines the amount by which the weights change during a series of iterations to bring the predicted value within an acceptable range of the observed value.
Conclusion
Agriculture is the most vital field in the emerging countries like India. Accurate crop yield prediction is still considered as a challenging task due to uncertainty with many factors related to crop production. Machine learning approaches in agriculture will amendment the situation of farmers and supports to improve the yield. For many problems associated with agriculture field, machine learning plays a significant role to overcome these problems. Disease detection is one of the major aspects which is to be addressed at early stage of the crop. So, various techniques of early disease detection techniques are surveyed for different crops. Using Agrico we can perform crop prediction Weather conditions, Soil condition, Diseases information. Also, we provide Market Price analysis and tractor rental services through GPS service. Agrico centralizes, manages, and optimizes the production activities and operations of farms. Crop selection is still remaining as a challenging issue for farmers. This paper focuses on the prediction of crop with the help of machine learning techniques. Several machine learning methodologies were used for the calculation of accuracy of different models. The Random Forest classifier gave the best accuracy. Thus, we have proposed a model that helps the user to predict a suitable crop to cultivate in a wider way and cost efficiently use the system for managing the farm activities as well as getting the live weather conditions of a particular place.
References
[1] Pooja Patil, Shivani Turamari. “Weather forecast Prediction for agriculture” in International Journal of Recent Technology and Engineering (IJRTE), 2022. [2] Rishi Gupta, Akhilesh Sharma. Weather Based Crop Prediction in India Using Big Data Analytics” in IEEE,2021. [3] Vaishnavi and Kishore. “Crop Prediction using Machine Learning” in Institute of Electrical and Electronics Engineers (IEEE), 2020. [4] Agila N, Senthil Kumar P. “An Efficient Crop Identification Using Deep Learning” in International Journal of Recent Technology and Engineering (IJSRTE),2020. [5] Mohammed Ahmed. “Car rental and tracking web-based system using GPS” in IJISCS,2020. [6] Anamika Chauhan “Smart Real Time Weather Forecasting System” in Institute of Electrical and Electronics Engineers (IEEE),2021 [7] Shubham Madan, Pravin Kumar “Prediction of crop and yield in agriculture using machine learning technique” in Institute of Electrical and Electronics Engineers (IEEE),202 [8] Kunal Pahwa, Neha Agarwal “Stock Market Analysis using Supervised Machine Learning” in Institute of Electrical and Electronics Engineers (IEEE) Published Year-2019 [9] Shubham Madan; Praveen Kumar “Analysis of Weather Prediction using Machine Learning & Big Data” in Institute of Electrical and Electronics Engineers (IEEE),2018 [10] Hind Abdalsalam Abdallah Dafallah “Design and implementation of an accurate real time GPS tracking system “in Institute of Electrical and Electronics Engineers (IEEE),2018
Copyright
Copyright © 2023 Prof. Dipali M. Mane, Gunja Gupta, Akash Shilimkar, Jaai Patwardhan, Trupti Shitole. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET53304
Publish Date : 2023-05-29
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online