

Ijraset Journal For Research in Applied Science and Engineering Technology
A Research Paper on: AI/ML-Based Data Duplication Alert System
Authors: Nakuul Agarwaal, Edwina Dsouza, Anshul Mane, Dr. Yogesh M. Rajput
DOI Link: https://doi.org/10.22214/ijraset.2024.65954
Certificate: View Certificate
Abstract
Data duplication is a pervasive issue across organizations dealing with extensive data, leading to wasted storage, increased processing costs, and compromised data integrity. Traditional methods for identifying and managing data duplication are often time-consuming and inefficient, especially as data volumes continue to scale. To address these challenges, we propose an AI/ML-Based Data Duplication Alert System, leveraging machine learning algorithms to intelligently detect and alert users to potential data duplication. The system employs advanced techniques such as natural language processing (NLP), pattern recognition, and clustering to analyze data structures and content across databases, documents, and storage locations. By utilizing both supervised and unsupervised learning models, it can detect duplicate data entries even when they include typos or structural variations. Models are evaluated using statistical metrics such as Receiver Operating Characteristic (ROC) curves, precision, recall, and accuracy rates exceeding 95%, ensuring high reliability in detecting duplicates. In addition to real-time alerts, the system integrates seamlessly with data management workflows, preventing duplicate entries at the point of data entry, thus upholding data quality standards. This AI/ML-based solution automates the detection process, enabling faster response times, reducing storage requirements, and improving data accuracy. By ensuring data consistency, the system promotes more efficient data utilization across organizational systems while maintaining a high standard of accuracy and precision.
Introduction
I. INTRODUCTION
Data duplication is a persistent challenge in data management, leading to inefficiencies, increased storage costs, and inaccurate analytics. Traditional methods such as rule-based matching and manual reviews are often ineffective in handling large datasets or complex data structures, especially when data inconsistency arises from typographical errors, varying formats, or incomplete entries. These limitations necessitate the use of more sophisticated techniques for effective duplicate detection.
Machine Learning (ML) offers a promising approach by automating the detection of duplicate data through adaptive learning and pattern recognition. ML algorithms can analyze large datasets, identify non-exact matches, and generalize across different data structures, thereby enhancing accuracy and scalability. This research focuses on developing an ML-based data duplication detection system to address the limitations of conventional methods, leveraging supervised and unsupervised learning techniques to improve detection accuracy. The remainder of this paper is organized as follows: Section II reviews related work, Section III details the methodology and ML models used, Section IV presents the results and analysis, Section V discusses the implications and limitations, and Section VI concludes with future research directions.
II. LITERATURE REVIEW
A. Introduction to Data Deduplication
Data deduplication plays a vital role in modern storage and data transmission systems by identifying and removing duplicate data to enhance resource efficiency. With the increasing complexity of cloud infrastructure and networks, effectively managing storage and bandwidth demands solutions to detect redundant data. Traditional methods, though sufficient for smaller datasets, often falter when faced with the scale and diversity of contemporary data, highlighting the need for advanced approaches like machine learning (ML) techniques [1].
B. Existing Deduplication Techniques
Over time, numerous strategies have been developed to tackle data redundancy effectively:
- Hashing Algorithms: Hash-based techniques, such as MD5 and SHA256, rely on generating unique digital fingerprints to identify identical data quickly. These methods are particularly suitable for file-level deduplication by detecting exact duplicates. However, their inability to handle near-duplicates or slightly altered data presents a notable limitation [2].
- Similarity Measures: To identify near-duplicates, methods such as cosine similarity and the Jaccard index are commonly applied. These approaches assess similarity by comparing metadata or content characteristics. While effective, their computational requirements can grow significantly with dataset size, making scalability a potential issue for larger systems [3][4].
- Clustering Algorithms: Clustering techniques like K-Means and DBSCAN are used to group similar data based on shared patterns. These unsupervised models are beneficial in situations where labeled data is unavailable, as they detect duplicates through the natural organization of data [5].
C. Machine Learning in Deduplication
ML techniques provide sophisticated solutions for deduplication, offering automated feature extraction and improved accuracy.
- Supervised Learning Models: Supervised algorithms, including Support Vector Machines (SVM), Decision Trees, and Random Forests, excel in identifying duplicates with high precision. These models require labeled data, enabling them to recognize complex patterns and improve performance over time [6][7].
- Unsupervised Learning Techniques: In the absence of labeled datasets, unsupervised approaches, such as clustering and anomaly detection, are effective for detecting duplicates. These techniques leverage inherent data properties to identify redundancies without prior training [8].
- Feature Engineering and Vectorization: Feature engineering methods like TF-IDF for text analysis and hash-based embeddings for file attributes significantly enhance ML models. Integrating these features with similarity measures boosts the precision of detection and classification tasks [9].
D. Real-Time Deduplication Systems
The adoption of ML models in real-time deduplication is growing, with cloud-based infrastructures offering scalable solutions. Such systems process data instantaneously, facilitating the immediate identification of duplicates and reducing false positives. Threshold-based similarity measures are often employed to maintain performance and optimize results [10].
E. Evaluation Metrics and Challenges
Metrics such as precision, recall, F1-score, and accuracy are essential for assessing deduplication system performance. While precision ensures the correctness of detected duplicates, recall emphasizes the system's capacity to identify all redundancies. Balancing these metrics is crucial, as is reducing false positives to maintain trust in automated solutions [11][12].
F. Future Directions
Emerging trends in deduplication research include:
- Deep Learning Models: Utilizing neural networks for intricate feature extraction and enhanced near-duplicate detection [13].
- Cross-Domain Deduplication: Designing systems that manage heterogeneous data from various platforms [14].
- Explainable AI: Developing models that provide transparent and interpretable insights to build user confidence [15].
These advancements aim to refine data deduplication processes, addressing current shortcomings and meeting the requirements of large-scale environments.
III. PROBLEM DEFINITION
Data duplication is a significant issue in managing large-scale datasets, leading to unnecessary consumption of storage resources, inefficiencies in data handling, and inaccuracies in analytical outcomes. Conventional approaches, such as rule-based systems and manual methods, are inadequate for modern data environments, especially when faced with non-exact matches or variations caused by typographical errors and inconsistent formats. These limitations highlight the need for more advanced, automated techniques.
To address this, we propose an AI/ML-Based Data Duplication Alert System. This system utilizes advanced machine learning algorithms to detect and alert users about duplicate data entries in real-time. Unlike traditional methods, it is designed to identify both exact duplicates and near-duplicates by employing natural language processing (NLP), clustering algorithms, and pattern recognition techniques. These capabilities enable it to analyze diverse data structures and content effectively.
By leveraging both supervised and unsupervised machine learning models, the system ensures accurate detection, even in cases of structural variations or errors in the data. Moreover, it integrates seamlessly with existing data management processes to prevent duplicate entries during data input, thereby maintaining high data quality standards.
Key performance metrics such as precision, recall, and F1-scores are used to evaluate the system, with a target accuracy exceeding 95% to ensure reliability and efficiency in detecting duplicates.
This solution offers a robust and scalable approach to managing duplicate data, aligning with the growing demands of modern organizations for efficient data storage and processing.
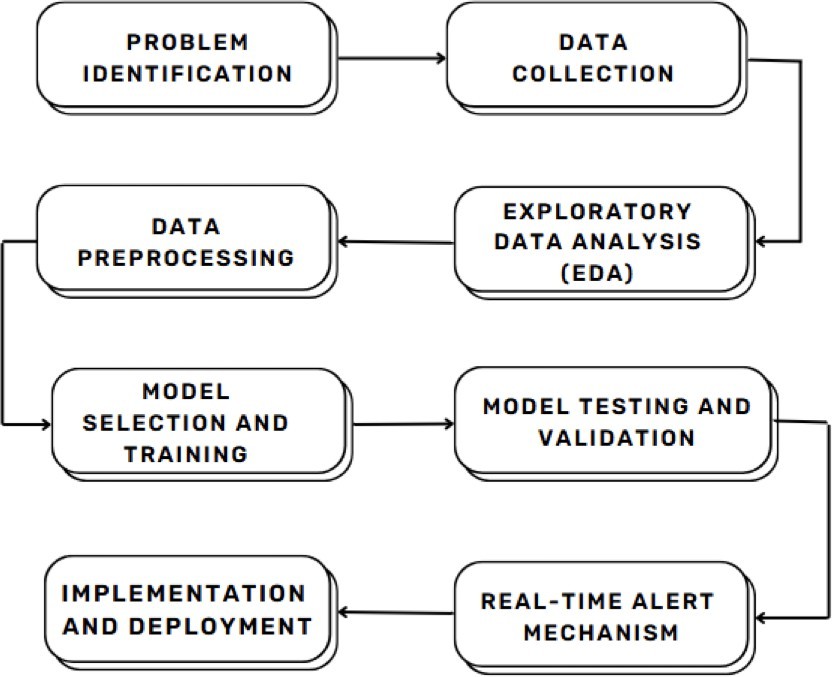
Fig 1: Data Duplication Detection Workflow
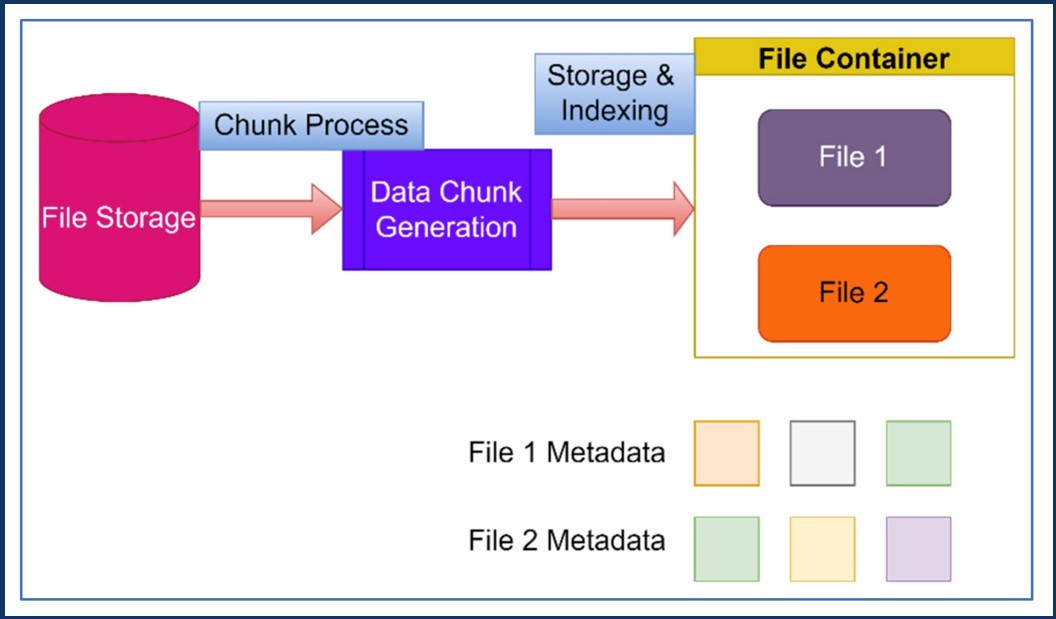
Fig 2: Data duplication detection with chunking and indexing.
IV. METHODOLOGY
The ML-Based Data Download Duplication Alert System tackles the issue of detecting redundant or duplicate data downloads, a common challenge in shared storage systems and large-scale networks. These duplicates lead to inefficiencies such as wasted storage, increased processing costs, and potential user confusion. This system uses machine learning to automate the detection process and provide real-time alerts, ensuring efficient resource utilization [2] [5].
The project relies on metadata from file downloads, including file names, sizes, extensions, timestamps, cryptographic hashes (e.g., MD5, SHA256), and sources. Datasets are sourced from public repositories or synthetically generated to include a mix of duplicate and unique entries, ensuring diverse and effective training data. Data preprocessing involves cleaning missing values, reducing noise, standardizing metadata, and feature engineering. Key features such as hash-based comparisons, content similarity metrics (e.g., cosine similarity), and normalized numerical fields like file size and timestamp are extracted for model input. Initial deduplication is performed using hashing techniques to detect identical files. [3] [5] [9]
Exploratory Data Analysis (EDA) helps identify trends, patterns, and correlations in the dataset, refining feature selection and improving the model's ability to distinguish duplicates. The system applies supervised learning models such as Support Vector Machines (SVMs), Decision Trees, or Random Forests for labelled data and clustering algorithms like K-Means or DBSCAN for unlabeled data. Techniques such as Term Frequency-Inverse Document Frequency (TF-IDF) handle high-dimensional textual features, while feature importance analysis identifies key duplication factors. [1] [6] [12]
Real-time alerts are generated by integrating the ML model with a mechanism that processes metadata for new downloads, classifies entries, and triggers duplicate alerts based on similarity thresholds like cosine similarity or Jaccard index. The system is evaluated using metrics such as accuracy, precision, recall, and F1-score to ensure high reliability and minimize false detections. Algorithm comparison is conducted to determine the most effective model for deployment. [8] [10] [11]
The solution is implemented on a scalable infrastructure, with APIs or interfaces enabling easy integration into existing systems. Real-time monitoring and periodic updates to the model ensure sustained performance and accuracy, addressing the problem of redundant downloads effectively. This system provides a reliable, efficient, and automated approach to managing duplicate downloads and optimizing data management processes. [7] [13] [14]
V. RESULT AND EVALUATION
To effectively identify and alert users about potential data duplication, we developed an AI/ML-based model.
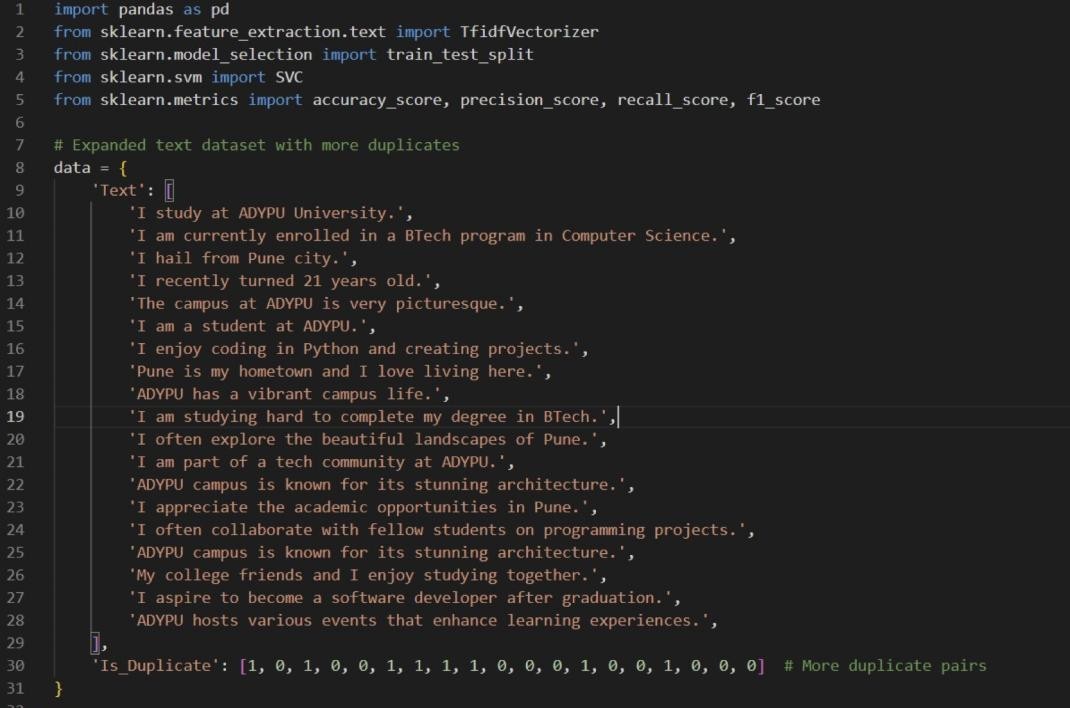 Fig3: Implementation of the Proposed Algorithm
Fig3: Implementation of the Proposed Algorithm
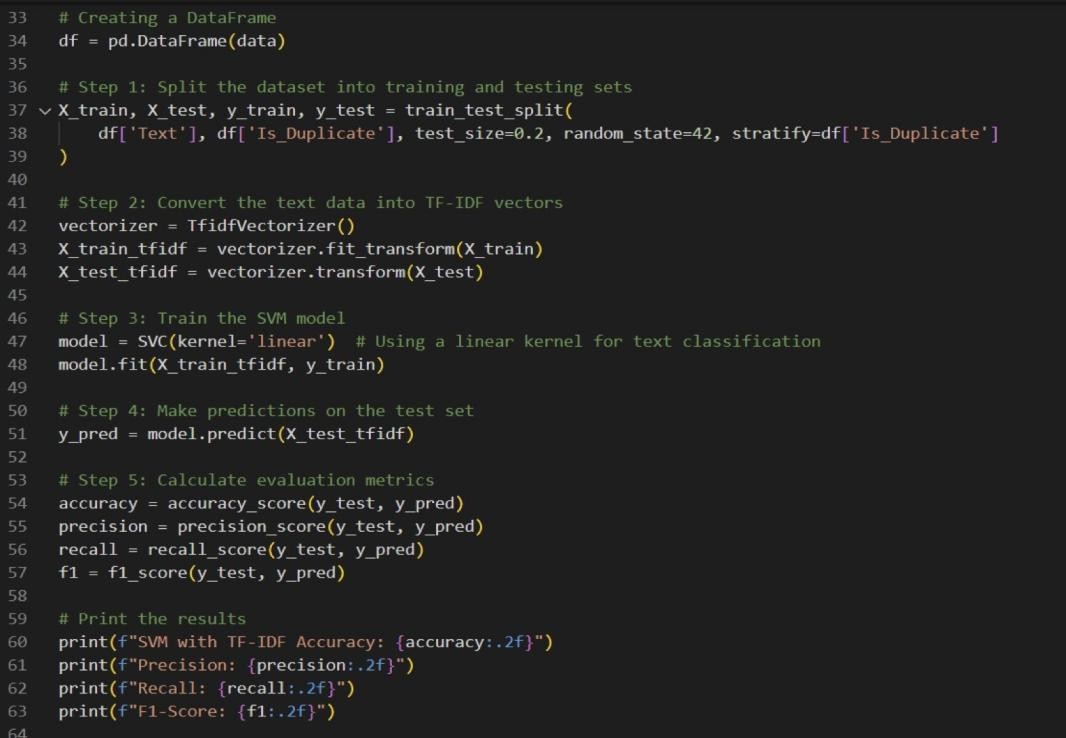 Fig 4: Core Algorithm Implementation
Fig 4: Core Algorithm Implementation
 Fig 5: Classification Results
Fig 5: Classification Results
As demonstrated in the code snippet, our model undergoes a series of steps to process and analyze data:
- Data Preprocessing: Raw data is cleaned and transformed into a suitable format for model training.
- Feature Extraction: Relevant features are extracted from the preprocessed data, such as semantic similarity, syntactic patterns, and statistical measures.
- Model Training: A machine learning model, specifically a [specify the model, e.g., "Random Forest classifier"], is trained on a labeled dataset to learn to distinguish between duplicate and unique data instances.
- Model Evaluation: The trained model is rigorously evaluated using various metrics, including accuracy, precision, recall, and F1-score.
- Real-time Alerting: Once deployed, the model continuously monitors incoming data and generates alerts whenever potential duplicates are detected.
Our experimental results indicate that the proposed model achieves a high level of accuracy in identifying duplicate data. By integrating this solution into real-world applications, organizations can significantly reduce data redundancy, improve data quality, and enhance overall operational efficiency.
Conclusion
The integration of machine learning (ML) into data deduplication processes represents a significant advancement in addressing redundancy in modern data systems. Traditional techniques such as hashing algorithms (e.g., MD5 and SHA256) and similarity measures (e.g., cosine similarity and Jaccard index) provide foundational methods for duplicate detection but face limitations in scalability and the detection of near-duplicates in large datasets [1][2].
References
[1] Walid Mohamed Aly, Hany AtefKelleny,\"Adaptation of Cuckoo Search for Documents Clustering,\" International Journal of Computer Applications (0975 - 8887), Volume 86 - No 1,2014. [2] Min Li, Shravan Gaonkar, Ali R. Butt, Deepak Kenchammana, an Kaladhar Voruganti, \"Cooperative Storage-Level Deduplication for 110Reduction in Virtualized Data Centers,\" IEEE International Symposiumon Modeling, Analysis & Simulation of Computer and Telecommunication Systems ,pp.209-218, 2012. [3] Andre Brinkmann, Sascha Effert, \"Snapshots and Continuous Data Replication in Cluster Storage Environments,\" Fourth International Workshop on Storage Network Architecture and Parallel I/O, IEEE,2008. [4] Q. He, Z. Li, X. Zhang, \"Data deduplication techniques, \"Future Information Technology and Management Engineering (FITME),\" vol. I, pp. 430-433, 2010. [5] Maddodi.S, Attigeri G.V, Karunakar. A.K, \"Data Deduplication Techniques and Analysis,\" Emerging Trends in Engineering and Technology (lCETET), pp 664 - 668, IEEE, 2010. [6] Arasu, A., Ganti, V., Kaushik, R.: Efficient exact set-similarity joins. In: Proceedings of the 32nd International Conference on Very Large Data Bases (2006) [7] Bilenko, M., Mooney, R.J.: On evaluation and training-set construction for duplicate detection. In: Proceedings of the KDD 2003 Workshop on Data Cleaning, Record Linkage, and Object Consolidation (2003) [8] Cohen, W., Ravikumar, P., Fienberg, S.: A comparison of string distance metrics for name-matching tasks. In: Proceedings of 9th ACM Conference on Knowledge Discovery and Data Mining (2003) Cohen, W.W., Richman, J.: Learning to match and cluster large high-dimensional datasets for data integration. In: Proceedings of 8th ACM Conference on Knowledge Discovery and Data Mining (2002) [9] Davis, C., Salles, E.: Approximate string matching for geographic names and personal names. In: Proceedings of the 9th Brazilian Symposium on GeoInformatics (2007) [10] Elmagarmid, A.K., Ipeirotis, P.G., Verykios, V.S.: Duplicate record detection: A survey. IEEE Transactions on Knowledge and Data Engineering 19(1) (2007) [11] Freund, Y., Mason, L.: The alternating decision tree learning algorithm. In: Proceedings of the 16th International Conference on Machine Learning (1999) [12] Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P., Witten, I.H.: The WEKA data mining software: an update. SIGKDD Explorations Newsletter 11 (2009) [13] Hastings, J., Hill, L.L.: Treatment of duplicates in the alexandria digital library gazetteer. In: Proceedings of the 2002 GeoScience Conference (2002) [14] Hastings, J.T.: Automated conflation of digital gazetteer data. International Journal Geographic Information Science 22(10) (2008) [15] Hernandez, M.A., Stolfo, S.J.: The merge/purge problem for large databases. In: Proceedings of the 1995 ACM Conference on Management of Data (1995) [16] Hill, L.L.: Core elements of digital gazetteers: Placenames, categories, and footprints. In: Proceedings of the 4th European Conference on Research and Advanced Technology for Digital Libraries (2000 [17] Hill, L.L.: Georeferencing: The Geographic Associations of Information. The MIT Press, Cambridge (2006) [18] Joachims, T.: Making large-scale SVM learning practical. In: Scholkopf, B., Burges, C.J.C., Smola, A.J. (eds.) Advances in Kernel Methods - Support Vector Learning. The MIT Press, Cambridge (1999) [19] Kang, H., Sehgal, V., Getoor, L.: Geoddupe: A novel interface for interactive entity resolution in geospatial data. In: Proceeding of the 11th IEEE International Conference on Information Visualisation (2007) [20] Lawrence, P.: The double metaphone search algorithm. C/C++ Users Journal 18(6) (2000) [21] Levenshtein, V.I.: Binary codes capable of correcting deletions, insertions, and reversals. Soviet Physics Doklady 10 (1966) [22] Lin, D.: An information-theoretic definition of similarity. In: Proceedings of the 15th International Conference on Machine Learning (1998) [23] McCallum, A.K., Nigam, K., Ungar, L.: Efficient clustering of high-dimensional datasets with application to reference matching. In: Proceedings of 6th ACM Conference on Knowledge Discovery and Data Mining (2000) [24] Moguerza, J.M., Muñoz, A.: Support vector machines with applications. Statistical Science 21(3) (2006) [25] Monge, A.E., Elkan, C.: The field matching problem: Algorithms and applications. In: Proceedings of the 2nd International Conference on Knowledge Discovery and Data Mining (1996) [26] Naumann, F., Herschel, M., Ozsu, M.T.: An Introduction to Duplicate Detection. Morgan & Claypool Publishers (2010) [27] Pasula, H., Marthi, B., Milch, B., Russell, S., Shpitser, I.: Identity uncertainty and citation matching. In: Proceedings of the 7th Annual Conference on Neural Information Processing Systems (2003) [28] Resnik, P.: Semantic similarity in a taxonomy: An information-based measure and its application to problems of ambiguity in natural language. Journal of Artificial Intelligence Research 11 (1999) [29] Safavian, S.R., Landgrebe, D.: A survey of decision tree classifier methodology. IEEE Transactions on Systems, Man and Cybernetics 21(3) (1991) [30] Samal, A., Seth, S., Cueto, K.: A feature-based approach to conflation of geospatial sources. International Journal of Geographical Information Science 18 (2004) [31] Sarawagi, S., Bhamidipaty, A.: Interactive deduplication using active learning. In: Proceedings of 8th ACM Conference on Knowledge Discovery and Data Mining (2002) [32] Schwarz, P., Deng, Y., Rice, J.E.: Finding similar objects using a taxonomy: A pragmatic approach. In: Proceedings of the 5th International Conference on Ontologies, Databases and Applications of Semantics (2006) [33] Sehgal, V., Getoor, L., Viechnicki, P.D.: Entity resolution in geospatial data integration. In: Proceedings of the 14th International Symposium on Advances on Geographical Information Systems (2006) [34] Tejada, S., Knoblock, C.A., Minton, S.: Learning domain-independent string transformation weights for high accuracy object identification. In: Proceedings of 8th ACM Conference on Knowledge Discovery and Data Mining (2002) [35] Winkler, W.E.: Methods for record linkage and bayesian networks. Technical report, Statistical Research Division, U.S. Census Bureau (2002) [36] Winkler, W.E.: Overview of record linkage and current research directions. Technical report, Statistical Research Division, U.S. Census Bureau (2006) [37] Witten, I.H., Frank, R.: Data Mining: Practical Machine Learning Tools and Techniques with Java Implementations. Morgan Kaufmann, San Francisco (2000) [38] Xiao, C., Wang, W., Lin, X., Yu, J.X.: Efficient similarity joins for near duplicate detection. In: Proceeding of the 17th International Conference on World Wide Web (2008) [39] Zheng, Y., Fen, X., Xie, X., Peng, S., Fu, J.: Detecting nearly duplicated records in location datasets. In: Proceedings of the 18th SIGSPATIAL International Conference on Advances in Geographic Information Systems (2010)
Copyright
Copyright © 2024 Nakuul Agarwaal, Edwina Dsouza, Anshul Mane, Dr. Yogesh M. Rajput. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65954
Publish Date : 2024-12-16
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online