

Ijraset Journal For Research in Applied Science and Engineering Technology
Alert Message Generation on Detection of Suspicious Activity (Robbery)
Authors: Prof. Prassanna Khandekar, Prof. Manjiri Raut, Niraj Phadtare, Aniket Kalbhor , Prathamesh Nevse, Purandar Devkar
DOI Link: https://doi.org/10.22214/ijraset.2024.60133
Certificate: View Certificate
Abstract
The system aims to give CCTV cameras the ability to detect suspicious activity, without human intervention. The goal of this paper is to identify suspicious activity for Surveillance and alert the shop owners when suspicious activity is detected. Electronic Article Surveillance (EAS) systems are widely used in today’s retail stores, but this system is not capable enough as the shoplifters can easily remove the tag or label from the product. Hence, this system aims to take real-time videos from CCTV as an input and pass it to the CNN model created with the help of transfer learning and detect ‘Shoplifting’, ‘Robbery’ or ’Break-In’ in the store and notify it to the owners as soon as it occurs. Finally the main motive is to provide a system that detects suspicious activities without human intervention and generates alert, thus making a huge revolution in today’s surveillance system.
Introduction
I. INTRODUCTION
The proposed system, Activity Detector and Alert Gen- erator (ADAG) is aimed to use Closed Circuit Television (CCTV) which is readily available in most of the shops. It aims to give CCTV cameras the ability to detect suspicious activity, without human intervention. The goal of this paper is to help shop owners detect shoplifting, when it happens, in real time and get an alert about it.
Electronic Article Surveillance (EAS) [1] alarm systems are widely used in today’s retail stores, that warns the security person when a shoplifter tries to leave a store with a product having an active tag or label attached to it. But this system is not capable enough as the shoplifters can easily remove the tag or label from the product. Therefore there is a compelling need for a system that can detect shoplifters based on their suspicious behavior in the store.
The developed system can take real-time videos from CCTV as an input, it then takes frames from the video and gives it to the CNN model. This CNN model takes a single frame as input, passes it through some operation to detect the occurrence of ‘Shoplifting’, ‘Robbery’ or ’Break- In’ in the store and produces a video with labelled frames as output. Each output frame is either annotated with ‘Normal’, ‘Shoplifting’, ‘Robbery’ or ’Break-In’ tags along with the probability. An alert message is sent to the shop owner when there is a change in the label from ‘Normal’ to ‘Shoplifting’, ‘Robbery’ or ’Break-In’. For frames with ‘Normal’ tag, message is not sent.
For training the model this paper uses transfer learning using pre-trained ImageNet weights, instead of training the CNN model from scratch. The first step is to extract frames from real time video. (i.e. video taken from CCTV). Second step is to pass the frame to trained CNN model. Third step is to push the predicted label for each frame to Queue. The fourth step is to repeat step 3 for ‘k’ frames.
The fifth and final step is to select the label with the highest probability corresponding to the mean of the last ‘k’ predictions. If the difference between sum of probabilities of other classes label and probability of predicted class is greater than 80%, display the frame with predicted class label and send an alert message, else display ‘Normal’ message.
Thus, providing a system that determines suspicious activity is a must in today’s world and hence this system delivers such services of tackling all such deception and forgery and thus making a huge revolution in today’s surveillance system.
II. LITERATURE REVIEW
Since the past two decades due to the arrival of various information system and technology, there has been a great increase and development in Surveillance system [2]. There have been drastic changes in surveillance system and also the various ways in which they are implemented.
There are various methods such as Motion Detection [3] [4], Object Detection [3] [5], Object Tracking [3], Concept of Fractal [6], and also various clustering techniques [7] used to achieve utmost accuracy Various businesses whether large scale or small scale has started increasingly using the managerial database to store the numerous accumulated large amount of marketing data, so to keep the information sorted in order, yet still there are various losses and shoplifting, robbery, break-in in the store are a few to name. Various management related tools and policies such as supply chain management, customer relationship management [8], demand management, and customer demand management etc. started being used so as to increase the potential of scale and have a proper track. This entire factor aggregated to purpose a better system to provide targeted surveillance.
Keeping track of sales and customer relationships is one thing and keeping track of people’s or customer’s activity is another. The last decade witnessed the extensive use of surveillance system in various public spaces by the use of CCTV and drones [3]. After the events like Mumbai Terror Attack from 2011, there has been great increasing demand for a behavior surveillance system that guarantees the peoples safety in the public areas. It should also include public spaces like football grounds, cricket stadiums, music concerts and places where people gather in large numbers such as malls. Such places lack to have proper surveillance that ensures the safety of the people. This paper proposes the utilization of the current surveillance system and upgrading it to a point where it can detect suspicious activity of the people.
In this paper the goal is find a new approach to maximize the accuracy of detecting a suspicious activity rather than using the previously tested methods like SVM [9] [10], genetic algorithm [11], continuous action detection of actions of interest among actions of non-interest [4], video visual analytics system [12] and also posture-representation techniques [13] all the result in predicting the movement of the customer [10] [6] and also the network concepts [8], random forest algorithm [7], and deep learning based fusion system [14]. Human tracking and motion detection, as well as behavior analysis are widely researched topics [15] [16]. Human tracking [17] [18] is also one of the aspects that help determine the behavior of a person. It acts as a comprehensive framework for tracking a human motion. For human tracking basically five-point tracker is used along with clustering algorithm. Suppose five points are marked at various body parts such as right shoulder, left shoulder, waist and both the knees respectively. At a regular interval the reading are taken. A person moving rapidly showing no interest in products would have coordinated at distance and a person showing an interest in a product, waiting to check it out would form a cluster and all this analysis would help in customer behavior detection. Human gesture and also motion detection made it possible for natural interaction between human and computers. Various application have been developed using human motion and gesture detection thus giving a boost to use this technology more and more.
A new machine learning based sensing system is used to check the facial detection of a customer this system’s implementation along with Human Gesture and detection proposes a complete solution for the shop owners and thus depicts whether a customer is interested or not in a particular product [19]. This same can also be used for surveillance, as a person not having in intentions of buying would make suspicious face gesture [20] and thus can be kept an eye on. Using Machine Learning and deep learning algorithms makes it easy for the actual interaction between human and computers. This system thus proves to be trust worthy and worth putting time in.
Robbery is a global problem. It’s an open social problem. Although a growing number of CCTV cameras are being installed at public places (such as airports, banks, shopping malls, etc.), yet the conventional surveillance systems that rely on human operators are inefficient in detecting rare anomalous events, such as robbery, in real-time. Recently, three-stream C3D+LSTM network [21] have shown promising results in large-scale video analysis tasks. So, a robust and efficient automated surveillance system, able to accurately detect any robbery attempt from the CCTV footage [22], and can respond effectively (e.g., raise alarm, lock the vault, call police, release tear gas, etc.) to foil the plot is needed.
Finally, it is noticed that the current CCTV system requires a security guard to constantly monitor all the activities. The efficiency of the guard deteriorates after some time due to which the robbery in the shop might go undetected. The EAS system is also inefficient as the thief can remove the active tag or label on the product easily. Some proposed system like Human Detection and Tracking on Surveillance Video [2], Human Motion Analyzer [13], Suspicious Behaviour Recognition based on Face Features [20] had a very limited scope and could not detect ’Shoplifting’, ‘Robbery’ and ‘Break-In’. Other systems such as Three-Stream C3D+LSTM [21] showed very less accuracy hence could not be practically implemented. Therefore, the main motivation of this paper is to give CCTV cameras the ability to detect suspicious activities such as ‘Shoplifting’, ‘Robbery’ and ‘Break-In’ in real-time, without human intervention and notifying the shop owners. Thus, making a huge revolution in today’s surveillance system.
III. ACTIVITY DETECTOR AND ALERT GENERATOR (ADAG)
It is said that retail industry loses $30 billion every year due to shoplifting. Closed Circuit Television (CCTV) can be used for monitoring people’s behavior. So, CCTV cameras must be given the ability to detect suspicious activity, without human intervention. The goal of this paper is to help shop owners detect shoplifting, when it happens, in real time.
Electronic Article Surveillance (EAS) alarm systems are widely used in today’s retail stores, that warns the security person when a shoplifter tries to leave a store with a product having an active tag or label attached to it. But this system is not capable enough as the shoplifters can easily remove the tag or label from the product. Therefore, there is a compelling need for a system that can detect shoplifters based on their suspicious behavior in the store.
The idea of this paper is to use Computer Vision (CV) which is widely used to extract useful information from image or video. CV is a subset of Artificial Intelligence (AI) and Machine Learning (ML).
Until recently, CV had very limited capabilities, but after the invention of deep learning and neural network, it has taken a leap further. It is seen that CV is able of surpass humans in certain areas related to labelling and detecting objects. This paper aims to propose a system using Convolution Neural Network, which detects suspicious activity of customer and notifies the shop owner. Certain suspicious activities of shoplifter that the images in the dataset consists are; seeing on the left and right and putting the item inside bag or pocket, travelling in groups (lifter distractor), watching the staff not the product, lurking in corners, taking advantage of crowd during peak hours, person carrying large bag or wearing large coats and someone who is not a typical customer (e.g. teenage boys entering in ladies store) etc.
To further increase the efficiency of the system we can classify the shoppers as goal-oriented, disoriented, looking for help and casual shoppers. The goal-oriented shopper knows what he needs to buy and walks to the product at a faster speed. The disoriented shopper does not know what to buy and walks at slow speed, looking left and right, in this scenario the system might identify them as a potential shoplifter, which is not the case. Looking-for-help-shopper who will ask the staff for help in finding a particular product.
The last one is casual shopper who is looking for attractive offers and with no intention of buying a particular product. It is noted that speed of walking can be and important distinction between goal-oriented and disoriented shoppers. It is observed that the type of behaviors discussed above might not always indicate shoplifters, but only can detect potential shoplifters. Lastly it is concluded that, the behavior is not sufficient criteria for alerting the owner of shoplifters, robbers and break-in in the store. The system should only alert the owner about shoplifting when the shoplifter hides the product inside bag or inside clothes i.e. when the product gets hidden from the view of all CCTV cameras.
The system can identify robbers as they tend to cover their face with cloth and point a gun at the shop owner. Break-in generally happens when the shop is closed i.e. at night.
Thus, providing a system that determines suspicious activity for surveillance is must in today’s world and hence this system delivers such services of tackling all such deception and forgery and thus making a huge revolution in today’s surveillance system.
A. Database Collection
The database contains images collected from Google and categorized into 3 classes Shoplifting (960 Images), Robbing (2073 Images) and Break-In (1136 Images).
B. Images Preprocessing
The collected images from Google were of different resolutions and formats. All the images were resized to 224x224 to standardize them. After that they were converted to RGB format. Then the process of data augmentation is done to avoid overfitting or underfitting. In data augmentation, rotation - 30, zoom - 0.15, shear range - 0.15, width and height shift - 0.2, and flip operations were performed on each image. It is then given as input to the Convolutional Neural Network (CNN).
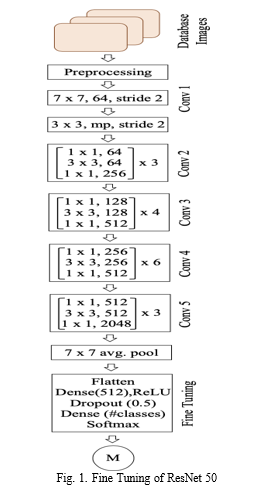
C. Model Training
For training the model transfer learning is used by using pre-trained ImageNet weights, instead of training the CNN model from scratch. In this phase ResNet50 is used which works as a backbone model, this paper has not changed any layers up to the Global Average Pooling (GAP) layer. Then adding average pooling with pool size = (7,7), after that doing flattening, then Dense layer - 512, Dropout Layer - 0.5 and finally the Dense layer, followed by SoftMax activation function and removed the Fully Connected layer. The full architecture is depicted in Fig. 1.
A model (M) is generated by training the CNN with 80 epoch. This paper evaluates the performance of the model in two phases. The first phase consists of evaluating the performance on the test set of images collected from Google. Considering the accuracy, precision and recall of the system as the evaluation metric. To show the trade-off between true positive and false positive rate plotting the Receiver Operating Characteristics (ROC) curve. Finally, the plotted precision-recall and area under curve is used to analyze the performance of the model.
The second phase consists of providing real-time videos as input to the system. The frames are extracted from a live video stream source (S). The extracted frame is then pre-processed by first resizing it (the frame is resized to the size of the image provided during the training phase of the model), followed by RGB channel ordering.
Each frame extracted and preprocessed from the real-time video is given to the model, which then predicts its class label. The label of the class with the highest probability is returned by the model. The same process is repeated for all the frames from the real-time video. For every input frame, its predicted class along with its probability is displayed on the output frame.
Therefore, the output video is in the form of a series of frames with its class label and probability. A ‘prediction flickering’ problem is noticed with this method. Due to this a frequent change is seen in the output label
D. Principle of Rolling Averaging
The principle of rolling average is used to reduce the flickering effect. It is also known as moving average or running average. It reduces the fluctuations in the output of a time series data. A queue (Q) of size k=64 is maintained to represent a subset of input time series data to apply rolling averaging. The last ‘k’ predictions from the Q are used to calculate the mean. The output frame is labelled by selecting the class label (L) of largest corresponding probability. The mathematical process is depicted in Fig. 2.
 Fig. 2. Mathematical Representation. Pci is the Probability of Suspicious Activity ‘ci’
Fig. 2. Mathematical Representation. Pci is the Probability of Suspicious Activity ‘ci’
E. Summary of Proposed Method
- Extracting frames from real time video. (i.e. video taken from CCTV)
- Pass the frame to trained CNN model.
- Push the predicted label for each frame to Q.
- Repeat step 3 for ‘k’ frames.
- Select the label with the highest probability corresponding to the mean of the last ‘k’ predictions. If the difference between the sum of probabilities of other classes label and probability of predicted class is greater than 80%, display the frame with predicted
IV. RESULTS AND DISCUSSION
The developed system can take real-time videos from CCTV or pre-recorded videos as an input, it then takes frames from the video and gives it to the CNN model. This CNN model takes a single frame as input, passes it through some operation to detect the occurrence of ‘Shoplifting’, ‘Robbery’ or ’Break-In’ in the store and produces a video with labelled frames as output. Each output frame is either annotated with ‘Normal’, ‘Shoplifting’, ‘Robbery’ or ’Break- In’ along with the probability. An alert message is sent to the shop owner when there is a change in the label from ‘Normal’ to ‘Shoplifting’, ‘Robbery’ or ’Break-In’. For frames with ‘Normal’ tag message is not sent. For sending the message to the shop owner Twilio API is used.
The collected images from Google are split into training and testing set in a ratio of 80:20. Hence the training of CNN model is done with 80% of images while the testing is done with 20% of images. The proposed model gives an accuracy of 89% for the testing set. As the accuracy is not the only criteria for model evaluation. Hence, this paper also considers other parameters like precision, recall, f1-score and support as shown in Table I to further evaluate the model. As it is clear from the table the average precision across all the classes is 91.66%, which shows us that out of the predicted positive, 91.66% are actually positive. It is observed that the average recall is 86% which tells us that number of true positives out of the total actual positives. The average f1- score is 88.33% which gives us a balance between precision and recall. Overall from the results we conclude that the model is highly capable of classifying the different classes. Fig. 3 shows the learning curve, which depicts the learning performance in terms of learning experience over time. It has 4 parameters Validation Loss, Validation Accuracy, Training Loss and Training Accuracy. The graph clearly depicts that the Validation and Training Accuracy increased with the number of epochs, which is a clear indicator that the model is efficient. It is also clear that the Validation and Training Loss has decreased with the number of epochs, which also indicates that the model has high efficiency.
Finally, to analyze the result Receiver Operating Characteristics (ROC) curve and Precision-Recall curve are plotted, they are shown in Fig. 4 and Fig. 5 respectively. The ROC curve seen in Fig. 4 is close to the top left corner which
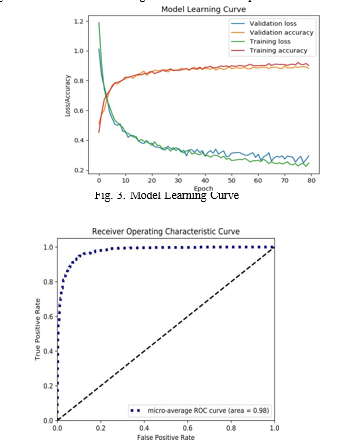

indicates that the performance of the model is accurate. The Area Under the Curve (AUC) is 98% which indicates the model is accurate in predicting the classes. The Precision- Recall Curve in Fig. 5 shows that the Average Precision (AP) score over all classes is 95%. The classification accuracy of the three classes is represented by the Confusion Matrix in Fig. 6
The comparison of different classification algorithms along with their accuracy are shown in Table II. In the previous study YouTube-Robbery dataset was used which comprised of 124 untrimmed CCTV videos for both robbery and normal activities. It is observed that C3D + SVM has the lowest accuracy of 52.27%, IDT-FV + C3D + SVM achieves an accuracy of 59.09%, C3D + LSTM has 63.64% accuracy, a significant improvement in accuracy is seen in Two-Stream C3D + SVM and IDT-FV + SVM i.e. 72.73%.
The best accuracy on video dataset is seen in Three-Stream C3D+LSTM [21] with 75% accuracy. Each stream in the three-stream architecture is comprised of C3D followed by an LSTM with SoftMax activation. Even after using 3 streams
i.e. RGB, optical flow and foreground masks the method shows very less accuracy than the proposed system.
This paper aimed to improve the accuracy by training the model on Images collected from Google using transfer learning on pre-trained ImageNet weights, with some modifications, instead of training the CNN model from scratch. It is observed that the proposed model shows high accuracy of 89% as compared to other algorithms
V. FUTURE SCOPE
Shoplifting, Robbery and Break-In images are down- loaded from Google hence they are heterogeneous. The images might contain noise, some of the images might be blur, also they may be of low resolution. Hence to improve the performance of the model we need to train CNN with proper images. Therefore, the future scope of the project is to have a high quality dataset which contains real life Shoplifting, Robbery and Break-In images. Also flickering effect is seen in the output video, which can be further minimized by making a proper selection of a subset of frames from the queue.
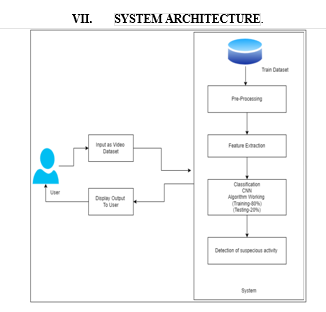
VI. METHODOLOGY
Generating alert messages upon detecting suspicious activity such as robbery requires a robust methodology to ensure timely and accurate notifications. Here's a general methodology you can follow:
- Suspicious Activity: Clearly define what constitutes suspicious activity related to robbery in your context. This could include actions such as unauthorized access, forced entry, unusual movement patterns, or tampering with security systems.
- Choose Detection Methods: Implement various detection methods such as video surveillance, motion sensors, sound detectors, or biometric systems to identify suspicious activity.
- Establish Thresholds: Set thresholds for each detection method to distinguish normal behavior from potentially suspicious behavior. This could involve parameters like motion speed, sound intensity, or access frequency.
- Data Collection and Analysis: Continuously collect data from your detection systems and analyze it in real-time or periodically. Use techniques such as anomaly detection, pattern recognition, or machine learning algorithms to identify suspicious patterns or deviations from normal behaviour.
- Integration with Alert System: Integrate your detection systems with an alert generation system. This could be a centralized security control panel or a software application designed to handle alerts. Ensure compatibility with various communication channels such as SMS, email, phone calls, or push notifications.
- Define Alert Criteria: Establish criteria for triggering alerts based on the severity and certainty of detected suspicious activity. For example, a single motion detected in a restricted area might trigger a low-level alert, while multiple simultaneous detections could trigger a high-level alert.
- Prioritize Alerts: Implement a prioritization system to distinguish between different types of alerts based on factors such as location, time of day, or the number of sensors triggered. This helps security personnel respond more effectively to critical situations.
- Customize Alert Messages: Tailor alert messages to provide relevant information to recipients, including the nature of the detected activity, the location, and any additional contextual details that could aid in response efforts.
- Testing and Validation: Regularly test your alert generation system under various scenarios to ensure reliability and effectiveness. Conduct validation exercises with security personnel to evaluate response times and the accuracy of alert notifications.
- Continuous Improvement: Continuously monitor the performance of your alert generation system and seek feedback from security personnel to identify areas for improvement. Update your methodology and technologies as needed to adapt to evolving threats and operational requirements
Conclusion
This paper proposed a system that gives CCTV cameras the ability to detect suspicious activity, without human intervention. The goal of this paper is achieved which was to generate alert on detection of suspicious activity. It is achieved by taking real-time videos from CCTV as an input and pass it to the CNN model and predict ‘Shoplifting’, ‘Robbery’ or ’Break-In’ in the store and notify it to the owners as soon as it occurs. The collected images from Google are split into training and testing set in a ratio of 80:20. An accuracy of 89% on the testing set was seen in the result. Various other measures like precision, recall, f1-score were also considered. The only limitation of the system is the flickering effect, which can be further minimized by making a proper selection of a subset of frames from the queue. From the overall observed results, it can be said that the model achieved better accuracy than the previously tested results and can be used for detecting suspicious activity of customer. Finally, it is concluded that providing a system that determines customer behavior and detect suspicious activities without human intervention is a huge revolution in today’s surveillance system
References
[1] S. Karuppuswami, M. I. M. Ghazali, S. Mondal, and P. Chahal, “Wireless eas sensor tags for volatile profiling in food packages,” in 2018 IEEE 68th Electronic Components and Technology Conference (ECTC), pp. 2174–2179, 2018. [2] M. Popa, L. Rothkrantz, Z. Yang, P. Wiggers, R. Braspenning, and C. Shan, “Analysis of shopping behavior based on surveillance system,” in 2010 IEEE International Conference on Systems, Man and Cybernetics, pp. 2512–2519, 2010. [3] N. Dawar and N. Kehtarnavaz, “Continuous detection and recognition of actions of interest among actions of non-interest using a depth camera,” in 2017 IEEE International Conference on Image Processing (ICIP), pp. 4227–4231, 2017. [4] C.-H. Chuang, J.-W. Hsieh, and K.-C. Fan, “Suspicious object detec- tion and robbery event analysis,” in 2007 16th International Confer- ence on Computer Communications and Networks, pp. 1189–1192, 2007. [5] Y. Kaneko, “Fractal analysis of a grocery store shopping path,” in 2015 2nd Asia-Pacific World Congress on Computer Science and Engineering (APWC on CSE), pp. 1–7, 2015. [6] H. Valecha, A. Varma, I. Khare, A. Sachdeva, and M. Goyal, “Pre- diction of consumer behaviour using random forest algorithm,” in 2018 5th IEEE Uttar Pradesh Section International Conference on Electrical, Electronics and Computer Engineering (UPCON), pp. 1– 6, 2018. [7] Y. Zuo, K. Yada, T. Li, and P. Chen, “Application of network analysis techniques for customer in-store behavior in supermarket,” in 2018 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 1861–1866, 2018. [8] Y. Zuo and K. Yada, “Using statistical learning theory for purchase behavior prediction via direct observation of in-store behavior,” in 2015 2nd Asia-Pacific World Congress on Computer Science and Engineering (APWC on CSE), pp. 1–6, 2015. [9] S. Peker, A. Kocyigit, and P. E. Eren, “An empirical comparison of customer behavior modeling approaches for shopping list prediction,” in 2018 41st International Convention on Information and Com- munication Technology, Electronics and Microelectronics (MIPRO), pp. 1220–1225, 2018. [10] X. Chen, Y. Li, and T. Hu, “Solving the supermarket shopping route planning problem based on genetic algorithm,” in 2015 IEEE/ACIS 14th International Conference on Computer and Information Science (ICIS), pp. 529–533, 2015. [11] A. H. Meghdadi and P. Irani, “Interactive exploration of surveillance video through action shot summarization and trajectory visualization,” IEEE Transactions on Visualization and Computer Graphics, vol. 19, no. 12, pp. 2119–2128, 2013. [12] W. Lao, J. Han, and P. H. De With, “Automatic video-based human motion analyzer for consumer surveillance system,” IEEE Transac- tions on Consumer Electronics, vol. 55, no. 2, pp. 591–598, 2009. [13] N. Dawar and N. Kehtarnavaz, “Action detection and recognition in continuous action streams by deep learning-based sensing fusion,” IEEE Sensors Journal, vol. 18, no. 23, pp. 9660–9668, 2018. [14] W. Liang, Z. Wu, J. Cao, and J. Gu, “Understanding customer behavior in shopping mall from indoor tracking data,” in 2018 IEEE 22nd International Conference on Computer Supported Cooperative Work in Design ((CSCWD)), pp. 648–653, 2018. [15] Y. Chen, J. Zhang, M. Guo, and J. Cao, “Understanding customer behaviour in urban shopping mall from wifi logs,” in 2017 IEEE In- ternational Conference on Pervasive Computing and Communications Workshops (PerCom Workshops), pp. 50–53, 2017. [16] J. Kaewyotha and W. Songpan, “A study on the optimization algorithm for solving the supermarket shopping path problem,” in 2018 3rd International Conference on Computer and Communication Systems (ICCCS), pp. 11–15, 2018. [17] S. K. Teoh, V. V. Yap, and H. Nisar, “A non-overlapping view human tracking algorithm using hsv colour space,” in 2019 International Conference on Green and Human Information Technology (ICGHIT), pp. 97–102, 2019. [18] N. Zerrouki, F. Harrou, Y. Sun, and A. Houacine, “Vision-based human action classification using adaptive boosting algorithm,” IEEE Sensors Journal, vol. 18, no. 12, pp. 5115–512
Copyright
Copyright © 2024 Prof. Prassanna Khandekar, Prof. Manjiri Raut, Niraj Phadtare, Aniket Kalbhor , Prathamesh Nevse, Purandar Devkar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET60133
Publish Date : 2024-04-10
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online