

Ijraset Journal For Research in Applied Science and Engineering Technology
Book Recommendation System Using Machine Learning Algorithms
Authors: Sakshi Ghanwat, Swapnil Pokale, Vaishnavi Tilekar, Shrutika Patil, Prof. Vinita Kute
DOI Link: https://doi.org/10.22214/ijraset.2025.66996
Certificate: View Certificate
Abstract
The book suggestion system has become a useful tool in today\'s extensive digital landscape, assisting consumers in finding books that suit their individual tastes. User profiles, which contain personal information like reading preferences, genres of interest, ratings and reviews are analyzed by this system using algorithms. By seeing trends and patterns in user behavior, user profile data improves the system\'s capacity to offer tailored recommendations. In these systems, recommendation algorithms are based on collaborative filtering, content- based filtering and hybrid techniques. While content- based filtering examines book attributes to recommend related books, collaborative filtering depends on user preference similarities. By integrating both methods, hybrid systems provide a more sophisticated strategy that raises user satisfaction and suggestion accuracy [1][2]. User profiling in which a structured profile gathers and updates data over time as user interactions continue, is a crucial component of book recommendation systems. Because of this dynamic process, systems can adjust to changing preferences and make sure that recommendations are still applicable. Research indicates that adding contextual, behavioral and demographic information to user profiles improves suggestion accuracy even further [3]. Modern book recommendation systems use advanced machine learning to analyze user profiles based on reading history, preferences and behaviors, creating personalized suggestions that cater closely to individual tastes. By combining hybrid filtering and deep learning algorithm such as CNN and RNN, these systems make book discovery more intuitive, helping readers find books they’re likely to enjoy.
Introduction
I. INTRODUCTION
Book recommendation systems have become essential tools for both readers and publishers. By making recommendations for books based on user preferences, reading histories and demographics book recommendation systems have become indispensable resources for both publishers and readers. These systems recommend books using a variety of methods, including hybrid approaches, content-based filtering and collaborative filtering. While content-based filtering recommends books with features similar to what a user has previously liked, collaborative filtering is based on patterns in the behavior of users with similar likes [6]. By combining the advantages of both techniques, hybrid approaches overcome drawbacks such as the "cold start" issue, which occurs when there is not enough user data to provide insightful recommendations and increase the precision and applicability of recommendations [4]. Natural language processing (NLP) and machine learning approaches have been used in book recommendation systems in recent years. The algorithm can better grasp each book's thematic core by analyzing book descriptions, genres and reviews thanks to natural language processing (NLP), which can help with individualized recommendations. [5] A key component of how book recommendation systems work is user profiles. These profiles usually include demographic information, age, region, favorite genres and reading history [7]. The system can provide suggestions that fit the user's reading habits and preferences by keeping track of their profile. Furthermore, the system can adjust to changing preferences and make increasingly accurate recommendations over time thanks to ongoing tracking of user behavior, including book ratings, reviews and the amount of time spent on each book [8].
II. RELATED WORK
Recommendation systems are critical tools for filtering information and delivering personalized content to users. Traditional recommendation algorithms, such as collaborative filtering (CF), content-based filtering (CBF) and hybrid techniques are frequently used for personalized recommendations. CF makes suggestions based on user-item interactions, identifying trends among users with similar tastes. For example, collaborative filtering has been effectively used to book recommendation systems such as Goodreads, where user ratings and reviews play an important role [9]. On the other hand, it uses item attributes and textual information to recommend related books. Studies that use natural language processing (NLP) have shown success in extracting meaningful keywords from book descriptions to aid in this task. Recent improvements include hybrid systems that combine CF and CBF with deep learning approaches, such as convolutional.
Convolutional neural networks (CNN) and recurrent neural networks (RNN) can increase recommendation accuracy by learning complex user-item interactions [10].Integrating user profiles into recommendation systems has gained popularity because it improves personalization by taking into account individual interests, demographics and reading habits. User profiles can store both explicit preferences (e.g. preferred genres, authors) and implicit interactions (e.g. reading history, time spent on each book). Studies have investigated adaptive learning algorithms for dynamically building and updating user profiles, capturing users' changing preferences over time[11].Profiles include demographic and psychographic information, such as reading habits and emotional preferences have also been demonstrated to increase recommendation accuracy.[12]
III. MODULES AND METHODOLOGY
The book recommendation system can be divided into the following modules:
A. User Profile Module
This module gathers data from users, including their reading history, ratings and preferences. It employs a user-friendly interface to facilitate input, ensuring that the data collected is comprehensive and accurate.
B. Item Profile Module:
This module catalogs the books available in the system, including metadata such as title, author, genre, summary and user ratings. This information is essential for the content-based filtering aspect of the recommendation system.
C. Collaborative Filtering Module
This module analyzes user-item interactions to identify patterns among users with similar tastes. It employs algorithms such as k-Nearest Neighbors (k-NN) or Matrix Factorization techniques to generate recommendations based on the preferences of similar users.
D. Content-Based Filtering Module:
In this module, the system analyzes the content of the books to recommend similar items basedon the user’s reading history. Natural Language Processing (NLP) techniques are utilized to extract features from the book descriptions, allowing for the identification of similar books.
E. Hybrid Recommendation Module:
This module combines the outputs of both the collaborative filtering and content-based filtering modules. A weighted scoring mechanism isapplied to integrate the results, providing users with a balanced set of recommendations that account for both user preferences and book characteristics.We can use deep learning approaches such as CNN and RNN algorithams
1) CNN
CNN can be applied to analyze book descriptions and user reviews to extract key features and patterns. These features help in understanding the content and context of the text data to enhance content-based recommendations. The CNN model processes text data such as book summaries and user reviews to find relevant keywords and phrases that align with user preferences.
2) RNN
User Behavior Analysis RNNs, specifically with LSTM (Long Short-Term Memory) units are used to analyze sequential data such as user reading history and rating patterns. This helps capture the flow and context in user interactions over time.LSTM networks can be used to predict future preferences based on a user's reading and rating history, enabling a more dynamic and personalized recommendation experience.
3) NLP
NLP Techniques for Sentiment Analysis are integrated with DL models to process and analyze user ratings. Sentiment analysis helps identify positive, neutral or negative opinions in user reviews, contributing to user profile enhancement.This data is used to adjust and personalize recommendations by understanding user sentiment towards specific books, genres or authors.
F. Evaluation Module
To assess the effectiveness of the recommendation system, this module employs metrics such as Mean Absolute Error (MAE), Precision, Recall and F1 Score to refine thesystem further.
IV. METHODOLOGY
Developing a book recommendation system requires a systematic approach that combines data mining, preprocessing and algorithmic techniques to generate personalized book recommendations In this section, we describe the steps taken to design and implement the proposed system, focusing on collaborative filtering, content-based filtering and hybrid approaches.
A. Data collection and preprocessing:
The first step in building a recommender system is to collect user experience data, which typically includes user ratings, reviews and preferences related to books. This data is collected from publicly available datasets or from user interactions on book platforms such as Goodreads or Amazon [1].
B. The Preprocessing Phase
Includes cleaning the data by removing duplicates, handling missing values and standardizing the data format to improve the quality of the input data for the algorithm [2]. Furthermore, a user profile is created to store information about the user's preferences, behavior and reading habits.
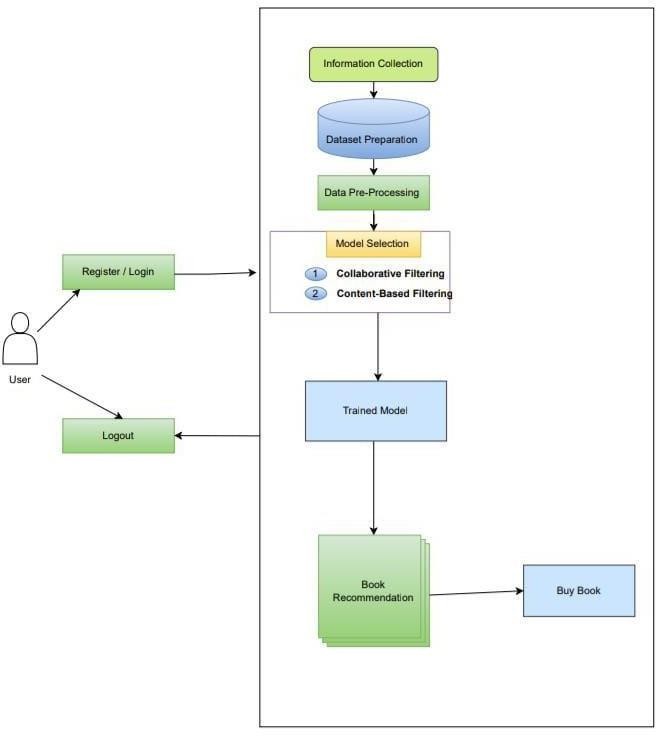
V. SYSTEM ARCHITECTURE
A. User Profile Module
The User Profile Module is a crucial component that gathers and manages user information to create a personalized reading experience. It begins by collecting detailed user data, including demographic information (such as age, gender and location), reading preferences (like favorite genres, authors and book formats) and a history of previously read books. The system continuously updates the user profile based on interactions with the platform, such as ratings, book reviews and books added to their reading list. This dynamic update mechanism ensures that the system reflects the user’s evolving tastes and interests, allowing for more accurate recommendations over time.
B. Book Database
The Book Database serves as the backbone of the recommendation system, housing a comprehensive collection of book- related information. This database includes metadata for each book, such as the title, author, genre, publication date, summary, cover image and language. It also incorporates user generated content, such as ratings and reviews, which provide insights into the popularity and reception of each book. By storing and organizing this wealth of information, the database supports efficient data retrieval and enhances the system’s ability to match books to user preferences based on multiple criteria.
C. Collaborative Filtering Component
The Collaborative Filtering Component focuses on analyzing user behavior to generate personalized book recommendations. It employs techniques like user-based and item-based collaborative filtering to identify patterns in how users interact with books.
D. Content -Based Filtering Component
The Content -Based Filtering Component focuses on analyzing the intrinsic features of books to create recommendations based on the user’s individual preferences. It evaluates characteristics of each book, such as genre, author, keywords, plot elements and writing style. By building a profile of the user’s favorite features, the system can suggest similar books that align with their tastes.
E. Hybrid Recommendation System
The Hybrid Recommendation System integrates the strengths of both collaborative filtering and content based filtering to generate more accurate and diverse recommendations. This component takes the outputs from both filtering techniques and combines them into a unified list of suggested books.
F. User Interface
The User Interface is designed to be intuitive and user friendly, offering a seamless experience for users to interact with the recommendation system. It provides a clear layout where users can view personalized book recommendations, search for specific titles and explore various book categories. The interface also incorporates social features, enabling users to share their favorite books, reviews and recommendations with friends or through social media platforms. Feedback mechanisms are integrated to gather user opinions on the recommended books, allowing the system to understand how well the suggestions align with their preferences. This feedback is crucial for retraining of each method, such as the cold-start problem in collaborative filtering or the lack of diversity in content based filtering. Over time, the system applies machine learning algorithms to analyze user feedback and interactions, allowing it to adapt and refine its recommendations continuously. This adaptive learning capability ensures that the system becomes more effective at predicting user preferences as more data is collected.
G. Feedback Loop
Collects user feedback on recommendations to continually improve the recommendation algorithms. Utilizes feedbackto retrain the model and enhance user experience
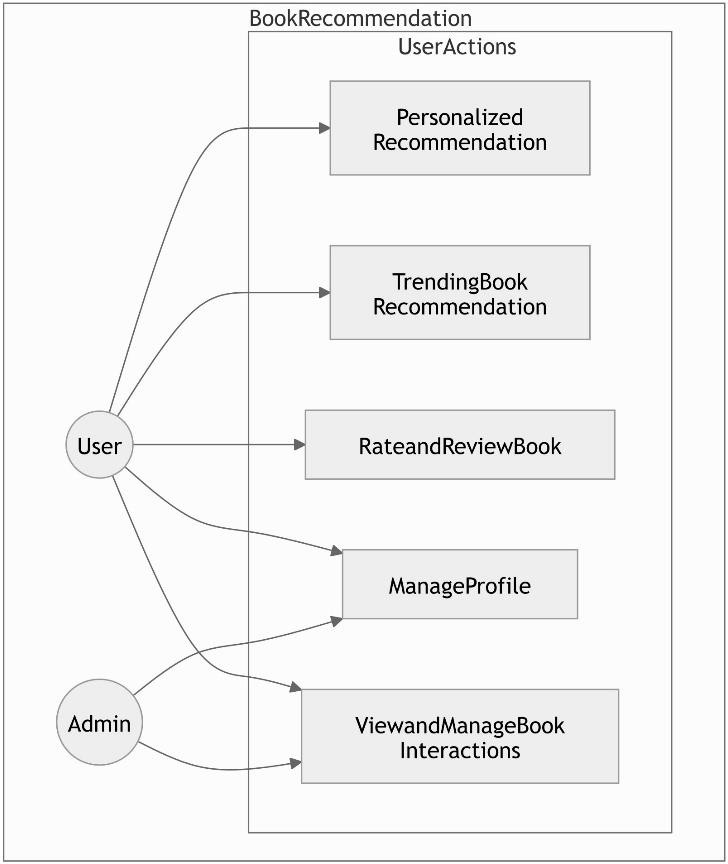
Fig. Use Case daigram
Conclusion
The implementation of a book recommendation system with user profile integration has proven to be a significant enhancement in providing personalized experiences to users. By leveraging user profiles, which store information such as reading preferences, past interactions and demographics the system can offer more accurate and relevant book recommendations. This personalized approach not only improves user satisfaction by reducing the time spent searching for books but also encourages increased engagement with the platform. Integrating user profiles enables the system to evolve with the user\'s changing preferences, ensuring recommendations remain dynamic and tailored to individual tastes.With continuous updates and improvements, such a system can adapt to diverse user needs and become an essential tool in the digital reading ecosystem.
References
[1] Baeza-Yates, R., & Ribeiro-Neto, B. (2011). Modern Information Retrieval: The Concepts and Technology behind Search. Addison-Wesley. [2] Ricci, F., Rokach, L., & Shapira, B. (2015).Recommender Systems Handbook. Springer. [3] Koren, Y., Bell, R., & Volinsky, C. (2009). Matrix factorization techniques for recommender systems. Computer, 42(8), 30-37. [4] Adomavicius, G., & Tuzhilin, A. (2005). Toward the Next Generation of Recommender Systems: A Survey of the State- of-the-Art and Possible Extensions. IEEE Transactions on Knowledge and Data Engineering, 17(6), 734–749. [5] Aggarwal, C. C. (2016). Recommender Systems: The Textbook. Springer. [6] Bobadilla, J., Ortega, F., Hernando, A., & Gutiérrez, A. (2013). Recommender systems survey. Knowledge-Based Systems, 46, 109–132. [7] Pazzani, M. J., & Billsus, D. (2007). Content-based recommendation systems. In The Adaptive Web (pp. 325– 341). Springer. [8] Ricci, F., Rokach, L., & Shapira, B. (2011). Introduction to recommender systems handbook. In Recommender systems handbook (pp. 1–35). Springer [9] Ekstrandt al. (2011). Collaborative filtering recommender systems. Foundations and Trends in Human–Computer Interaction, 4(2), 81-173. [10] Zhang, S., et al. (2019). Deep learning-based recommender system: A survey and new perspectives. ACM Computing Surveys (CSUR), 52(1), 1-38. [11] Agarwal, R., et al. (2020). Dynamic user profile modeling for personalized recommendations in the domain of books. Information Processing & Management, 57(3), 102217. [12] Musto, C., et al. (2017). A multi-dimensional approach to user profiling in content-based recommender systems. ACM Transactions on Internet Technology (TOIT), 17(1), 1- 24.
Copyright
Copyright © 2025 Sakshi Ghanwat, Swapnil Pokale, Vaishnavi Tilekar, Shrutika Patil, Prof. Vinita Kute. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET66996
Publish Date : 2025-02-17
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online