

Ijraset Journal For Research in Applied Science and Engineering Technology
Captcha Recognition Using CNN
Authors: V. Manga, Dr. P. Sruthi, A. Nithin, N. Sanjay, G. Srikanth
DOI Link: https://doi.org/10.22214/ijraset.2024.60158
Certificate: View Certificate
Abstract
Tests that are automated and intended to tell humans from machines are called CAPTCHAs. Computers find it harder to solve them, which prevents programs from abusing online services and consuming internet resources, but humans can solve them with ease. Convolutional neural nets could be used to efficiently and automatically complete the CAPTCHA tests. The highly precise CAPTCHA recognition techniques currently in use can be structurally complex. Consequently, our group investigated an alternative method for resolving CAPTCHAs: enhancing accuracy by using image processing and a Convolutional Neural Network, which is more efficient in terms of run time and structural complexity. Our networks were also evaluated using CAPTCHA datasets that included background noise and character adhesion.
Introduction
I. INTRODUCTION
The purpose of CAPTCHA, or the Fully Automated Public Turing Test that Tells Computers and Humans Apart, is to prevent automated programs from wasting network resources by frequently accessing websites quickly. Most online service providers have used CAPTCHA testing before permitting a user to complete certain operations, including filling out a form. Of all the CAPTCHAs, the most popular ones use low-resolution, distorted characters with adhesions between characters and background noise that the user has to read and accurately write into an input box. For humans, this job is rather easy—it takes a median of 10 seconds to complete [1]. However, computers find it challenging because of the noise—it is difficult for a programme to distinguish the characters from the background. Convolutional Neural Networks (CNN) could, however, allow computers to perform these CAPTCHA tests quickly and correctly. Developing a quick, easy, and reliable way to identify CAPTCHAs can help with both the construction if new, more secure CAPTCHAs and ensuring the accuracy of the safety of the ones that already exist. Numerous other domains, such as handwriting recognition and license plate identification, could potentially benefit from the same methodology used for CAPTCHA recognition. Our work aims to optimize a CNN model in terms of accuracy, structural simplicity, and training data requirements. Additionally, in an effort to improve model performance and minimize the quantity of training data needed, we experimented with preprocessing the CAPTCHA images using methods like Fourier Transform. Absolutely Automated Public Turing Test to Tell Computers and Humans Apart, or CAPTCHA, is a commonly used technique to stop automated bots from visiting websites or performing particular tasks. By posing problems that are simple for people to answer but complex for robots, the intention is to distinguish between automated systems and human users. It is difficult for automated computers to correctly identify these deformed characters since they are purposefully bent and hidden by background noise. Still, most people can understand the content really easily. One kind of deep learning technique that is especially useful for image recognition applications is Convolutional Neural Networks (CNNs).
II. RELATED WORK
- “How good are humans at solving CAPTCHAs,”
Humans can easily complete captchas, but machines find them difficult. All of the new research, however, has concentrated on making them difficult for machines to understand. In this study, we provide the first thorough evaluation of captchas from the perspective of humans, estimating the amount of friction a captcha causes the average user. We gathered volunteers for this study from Amazon Mechanical Turk as well as an unofficial captcha-breaking business. They were asked to complete over 38,000 captchas using the 21 most popular captcha schemes—13 picture schemes—that were disseminated and 8 audio schemes. The resulting data is analyzed, and it shows that humans frequently struggle with captchas—audio captchas being especially challenging. We also discover certain demographic tendencies, such as the fact that non-native English speakers perform less accurately and slower over all on captcha systems that are English-centric. The evidence from 14,000,000 eBay captcha samples gathered over a week suggests that the solving accuracies found in our study are fairly close to real-world values and that improving audio captchas should be a primary priority because approximately 1% of all captchas are presented as audio rather than visuals.
In conclusion, our research suggests that using Mechanical Turk instead of an underground service can help an attacker answer captchas more successfully.
When it comes to solving traditional text-based CAPTCHAs, humans typically do well. These CAPTCHAs are difficult for automated computers to interpret correctly because they usually have deformed text characters that are hidden by background noise. Deciphering the warped text and typing it into the input box is a very simple operation for most humans, especially those with normal vision. Research indicates that most users are able to rapidly and accurately solve CAPTCHAs. For instance, studies show that it typically takes a human being ten seconds to do a CAPTCHA assignment. This shows that humans are generally good at reading the text and telling it apart from the backdrop, even with the deliberate distortions and noise added to make the task difficult.
2. “Using gradient-based learning for document identification,”
Multilayer neural networks that have been trained using the back-propagation algorithm provide the best example of a successful gradient-based learning approach. If the network architecture is appropriate, gradient-based learning techniques can be utilized to synthesis a complex decision surface that needs minimal preprocessing to classify high-dimensional patterns, such as handwritten characters.
This work examines several approaches to handwritten character identification and contrasts them using a common handwritten digit recognition problem. We show that convolutional neural networks—which are designed expressly to manage the diversity of 2D shapes—perform better than all other approaches. Field extraction, language modeling, and segmentation recognition are a few of the elements that make up practical document recognition systems. Such multimodule systems can be globally trained with gradient-based techniques to minimize an overall performance metric, thanks to a novel learning paradigm known as graph transformer networks (GTN). There is an explanation of two online handwriting recognition systems. Tests show the benefits of global training and the adaptability of network transformer networks. Additionally, a graph transformer network of reading a bank cheque is explained. It offers record accuracy for both personal and business assessments by fusing convolutional neural network character recognizers with global training methodologies. It reads millions of checks every day and is used in commerce. Using machine learning algorithms, especially those based on gradient descent optimization techniques, to train models that can automatically identify and categorize documents based on their content is known as gradient-based learning for document identification. Documents are usually represented using this method as high-dimensional feature vectors, where each feature represents particular traits or patterns found in the text of the document. Word frequencies, n-grams, semantic embeddings, and other representations generated from the document text are examples of these attributes. A model, like a neural network or support vector machine, is trained by iteratively changing its parameters in order to minimize a loss function that measures the difference between the model's predictions and the actual document labels.
3. “Recognizing multi-digit numbers from street view photos with deep convolutional neural networks,”
It is difficult to recognize random multi-character writing in unconstrained natural photos. We tackle an equally difficult sub-problem in this field, which is the recognition of random multi-digit digits from Street View pictures, in this paper. The localization, segmentation, and recognition processes are usually handled separately in traditional methods to this problem. In this research, we provide a unified approach that incorporates all three processes using a deep convolutional neural network that interacts directly with the picture pixels. Large-scale distributed neural networks are trained on high-quality photos using the Disbelief implementation of deep neural networks. We find that the deeper the convolutional network, the better this technique works; the deepest architecture we trained, with eleven hidden layers, yielded the best results. Using the SVHN dataset, which is accessible to the public, we test this method and obtain over 96% accuracy in identifying entire street numbers. We show that we outperform the state-of-the-art with 97.84% accuracy on a per-digit recognition task. We additionally assess this methodology on an even more demanding dataset produced from Street View photography, which includes several tens of millions of annotations for street numbers, and we attain an accuracy rate of 90%. We apply the suggested system to synthetic distorted text from reCAPTCHA in order to investigate its applicability to more general text recognition tasks. ReCAPTCHA, which uses twisted language to distinguish between humans and automated programs, is one of the safest reverse Turing tests. On the most challenging reCAPTCHA category, we record a 99.8%. Based on our assessments of the two tasks, we have found that the suggested system can perform as well as, or better than, human operators under certain operational parameters.
4. “CAPTCHA recognition method based on LSTM RNN”
One kind of hard artificial problem-based network security measure is the fully automated public Turing test, or CAPTCHA, which is used to distinguish between computers and people. Research on the adoption of CAPTCHA requires that it be made more secure and that some challenging issues be resolved. First, state-of-the-art CAPTCHA recognition techniques are examined. After that, a recognition technique built on a recurrent neural network (RNN) done with long short-term memory (LSTM) blocks is discussed. The third area of study is feature extraction for CAPTCHA recognition. A last suggestion is made for a decoding method to improve the recognition rate. The suggested recognition method's efficiency is demonstrated by the experimental findings. It has been demonstrated that an image's grey value can be a relatively helpful RNN characteristic. Additionally, with minimal temporal complexity, the suggested decoding algorithm achieves good recognition rates. Deep learning architectures such as long-sequence trainable neural networks (LSTM RNNs) are ideal for tasks like speech recognition, language translation, and sequence prediction because they are specifically made to handle sequential data with long-range dependencies. LSTM RNNs are trained on a dataset of CAPTCHA images in the context of CAPTCHA recognition in order to identify the temporal patterns and structures contained in the distorted text. Because LSTM RNNs can capture and retain information over longer sequences than standard feedforward neural networks, they can handle the variable-length nature of CAPTCHA problems with effectiveness. In training, the network steadily improves its capacity to produce precise predictions about the characters in the CAPTCHA by learning how to iteratively update its internal state depending on the input sequence of picture pixels.
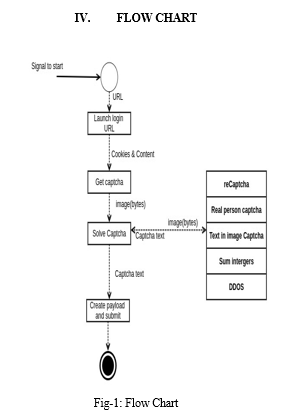
III. METHODOLOGY
- Data Collection: Using this module, we will upload CAPTCHA image dataset to application.
- Data Preprocessing: with the help of this module, we will examine every CAPTCHA image. Once Preprocessing has been applied, we will take features out of every review.
- Train CNN Algorithm: we are training the CNN algorithm with the dataset.
- Predict Captcha: we are predicting the CAPTCHA by giving the test images.

Conclusion
Text-based CAPTCHAs are the most widely used type of CAPTCHA, despite being the least secure option. This is because they are inexpensive, easily accessed, and simple to use. It is necessary to make changes to text-based CAPTCHAs since they are less secure and more susceptible to assaults than planned. By identifying their vulnerabilities, it\'s possible to enhance the security of text-based CAPTCHAs by developing more accurate and efficient solutions. All things considered, CNN is a quick and accurate way to identify CAPTCHAs; further advancements in its application could increase the security for text-based CAPTCHAs. Our group built three CNN networks that are structurally more effective than many of the existing methods of high accuracy CAPTCHA recognition, and investigated them on three different CAPTCHA datasets to see if CNN networks with shorter runtimes and less structural complexity could be used to accurately recognize CAPTCHAs with character adhesions as well as background noise. With only 1070 samples chosen for training from each dataset, the findings demonstrate that these networks, albeit having less structural complexity, are nevertheless able to achieve high recognition accuracy, as seen by Network 1\'s 94.67% accuracy on the first dataset. More training, in our opinion, could considerably enhance accuracy even in low-accuracy situations. These findings suggested that, in comparison with two datasets, the third dataset—which consists of all 26 upper case and lower-case letters and 10 digits randomly punctuated by character adhesions, slants, and dots and lines in the background as distractions—was significantly more difficult for the models to recognize and required more training to achieve the desired accuracy. We continue to work on the open issue of text-based CAPTCHA security in the future.
References
[1] Burstein, E., Bethard, S., Mitchell, J.C., Jura sky, D., Fabry, C. (2010) How good are humans at solving CAPTCHAs? a large-scale evaluation. IEEE S&P ’10. [2] LeCun, Y., Bottom, L., Bengio, Y., Haffner, P. (1998) Gradient-based learning applied to document recognition. Proceedings of the IEEE. [3] Goodfellow, I.J., Bulatov, Y., Ibra, J., Arnoud, S., Shet, V. (2014) Multi-digit number recognition from street view imagery using deep convolutional neural networks. ICLR. [4] Zhang, L., Huang, S.G., Shi, Z.X., Hu, R.G. (2011) CAPTCHA recognition method based on LSTM RNN. Pattern Recoin., 1: 40–47. [5] Yan, J., Ahmad, A.S.E. (2008) A low-cost attack on a Microsoft CAPTCHA. Proceedings of the ACM Conference on Computer and Communications Security, 543–554. [6] Stark, F., Hazira’s, C., Triebel, R., Cremers, D. (2015) Captcha recognition with active deep learning. GCPR Workshop on New Challenges in Neural Computation. [7] Wang, J., Qin, J.H., Xiang, X.Y., Tan, Y., Pan, N. (2019) CAPTCHA recognition based on deep convolutional neural network. Math. Bioscan. Eng., 16: 5851–5861. [8] Kaggle. (2018) CAPTCHA Images. https://www.kaggle.com/fournierp/captcha-version-2-images. [9] Kaggle. (2020) CaptchaImages1070. https://www.kaggle.com/datascientistsohail/captchaimages1070. [10] Wang, Z., Feng, J., Chen, Y., Li, H., & Zhang, X. (2019). Research on captcha recognition algorithm based on CNN-RNN model. In Proceedings of the 2nd International Conference on Education Innovation and Social Science (pp. 27-31). ACM. [11] Htun, Z. T., Kavipriya, C. K., & Poornima, R. (2021). Convolutional neural network based captcha solver. In International Conference on Computer Communication and Networks (pp. 1-6). IEEE. [12] Liu, Y., Zhang, Y., & Zheng, D. (2020). CAPTCHA recognition using convolutional neural network. In 2020 4th International Conference on Cryptography, Security and Privacy (ICCSP) (pp. 1-5). IEEE. [13] Song, J., & Wu, Z. (2019). A captcha recognition model based on improved CNN. In 2019 International Conference on Computational Science and Engineering (CSE) and 2019 International Conference on Embedded and Ubiquitous Computing (EUC) (pp. 67-71). IEEE. [14] Wang, C., & Wang, Z. (2020). Captcha recognition method based on lightweight convolutional neural network. In International Conference on Neural Information Processing (pp. 229-239). Springer, Cham. [15] Zhu, Y., Liu, L., & Li, L. (2020). Research on captcha recognition method based on CNN. In International Conference on Intelligent Computing (pp. 112-121). Springer, Cham. [16] Kim, D. H., & Kim, J. H. (2019). A study on captcha recognition using deep learning. In Proceedings of the 2019 International Conference on Information and Communication Technology Convergence (ICTC) (pp. 603-606). IEEE. [17] Choudhary, A., & Rani, R. (2021). A novel captcha recognition using CNN and LSTM. In 2021 3rd International Conference on Intelligent Sustainable Systems (ICISS) (pp. 811-814). IEEE. [18] Pan, X., & Liu, X. (2017). Research on captcha recognition based on deep learning. In 2017 IEEE International Conference on Smart Computing (SMARTCOMP) (pp. 1-6). IEEE. [19] Wang, J., & Zhao, H. (2018). Research on captcha recognition based on deep learning. In 2018 3rd International Conferenc
Copyright
Copyright © 2024 V. Manga, Dr. P. Sruthi, A. Nithin, N. Sanjay, G. Srikanth. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET60158
Publish Date : 2024-04-11
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online