

Ijraset Journal For Research in Applied Science and Engineering Technology
CareConnect: Improving Patient Appointment Scheduling using Markov Decision Process with K-Means Algorithms
Authors: Dr. Priyadarshan Dhabe, Sarthak Madhikar, Tejas Gambhir, Sushrut Patil, Aman Manakshe, Mehvish Mukadam
DOI Link: https://doi.org/10.22214/ijraset.2024.62714
Certificate: View Certificate
Abstract
In the healthcare sector, the number of patients has increased by a significant amount in the last decade which has resulted in overcrowding of hospitals and clinics. Using machine learning (ML) in this domain has proven very useful for both doctors and patients. This research mainly focuses on designing an algorithm for appointment scheduling for doctor’s which helps them prioritize patients based on their medical conditions and history which will give them an idea of which patient needs attention on a priority basis. The study implements various machine learning algorithms such as K-means clustering, which clusters patients into three classes of priority, Markov’s Decision Process (MDP) is used to define the problem and Q-Learning is used to solve it. Using these techniques the research aims to develop a system which automatically books an appointment with a doctor based on inputs given to certain questions related to their medical conditions.
Introduction
I. INTRODUCTION
In the growing sector of healthcare, the efficient utilization of resources is important for providing quality patient care. One major aspect that significantly influences the operational efficiency of healthcare facilities is patient appointment scheduling. The complex nature of healthcare demands a practical approach to appointment scheduling that goes beyond traditional methods. This research paper focuses on merging new technologies and algorithmic methodologies, proposing a precise approach to patient appointment scheduling.
The scheduling of patient appointments is a complex task influenced by various factors such as the severity of the medical condition, resource availability, and patient preferences. Conventional scheduling systems often struggle to balance these factors, leading to negligible utilization of resources and increased patient dissatisfaction. In response to these challenges, this research introduces a novel approach that combines a Prioritization Algorithm, Markov's Decision Process (MDP), and the K-means Algorithm to enhance the efficiency and effectiveness of patient appointment scheduling.
The Prioritization Algorithm aims to categorize patients based on the urgency of their medical needs, considering factors such as medical history, severity of the condition, and historical appointment data. This prioritization ensures that patients with critical conditions receive timely care while optimizing resource allocation. Markov's Decision Process is then employed to model the dynamic nature of patient scheduling, taking into account the uncertainty and variability inherent in healthcare systems. By considering the sequential decision-making process in appointment scheduling, MDP provides a framework for optimizing schedules over time.
Furthermore, the integration of the K-means Algorithm helps to cluster patients with similar needs and preferences. This clustering allows healthcare providers to streamline appointment scheduling by grouping patients with common requirements, thus reducing wait times and enhancing overall patient satisfaction.
With merging of these three methodologies, this research aims to develop an adaptive patient appointment scheduling system. The proposed system is expected to be dynamic, responding to real-time changes in patient conditions, resource availability, and other factors. The proposed approach not only addresses the challenges of current scheduling systems but also strives to set a new standard for patient-centric, resource-efficient healthcare delivery.
This paper also discusses Prioritization Algorithm, Markov's Decision Process, and the K-means Algorithm which are the building blocks of the model. It also presents the methodology employed in integrating these approaches and discusses the potential benefits and challenges associated with their implementation in the healthcare context.
II. RELATED WORK
[1]In this research, researchers are aiming to figure out the best way to schedule patient appointments to maximize the average profit over the long term. The system assumes a fixed number of staff members, and each patient necessitates a random number of visits with a designated time gap between each visit. The representation of the scheduling system takes the form of a decision-making game, wherein the state encompasses the prevailing schedule and the quantity of new arrivals. However, finding the absolute best strategy is too complicated due to the large number of possible situations. So, they come up with a practical strategy, called the IP, to make scheduling decisions. The researchers compared how well the strategy works against three other known methods such as the Next day policy, Next available day Policy, and the Shortest Queue policy. The IP strategy (and a modified version called the GIP) is designed to schedule appointments as each patient shows up. It's important to note that our model doesn't consider every possible issue that can happen in real-life scheduling, like patients not showing up, cancellations, or rescheduling.[2]The researchers employed various clustering techniques, such as k-means and mean shift, to organize and comprehend data pertaining to patients in chemotherapy clinics. Specifically, they observed that the mean shift algorithm proved to be effective in ascertaining the number of groups (clusters) of patients and identifying the membership of each group. To test their ideas, they made up information for 150 pretend patients, considering three factors: how long the treatment takes, the seriousness of the health condition, and the type of cancer. Using k-means clustering, they grouped these 150 patients into 70 clusters. Then, they applied a mathematical model to these clusters to see how fast the computer could figure things out. The newly devised method draws inspiration from the concept of "cellular manufacturing," assigning one nurse to a cohort of patients sharing similar characteristics throughout the entirety of their treatment. Each group is based on factors like how long their treatment is, how serious their health condition is, and the type of cancer they have. The results of their study showed that this new approach works better than the current method in terms of finding good solutions and doing the calculations quickly.[3] The researchers created a special way of solving the problem of scheduling physicians, and they used a mix of two techniques: continuous linear programming and a method known as Greedy Randomized Adaptive Search Procedure (GRASP). Imagine the scheduling problem like putting together a big puzzle. The linear programming part helps build a general plan for when doctors are needed. Then, the GRASP part comes in to organize the detailed schedules based on the big plan. It's like having a master plan (thanks to linear programming) and then using a smart method (GRASP) to fill in the specific details of who works when. So, they developed a new way to solve this scheduling puzzle by combining these two methods. Their approach looks for different good solutions and explores different possibilities to find the best overall plan for scheduling doctors.[4] In this research, a scheduling methodology that integrates machine learning and mathematical programming was formulated to minimize waiting time for higher priority outpatients. The planning process underwent a two-phase division. Initially, two clustering methods, K-means clustering and agglomerative hierarchical clustering respectively, were employed and compared. The aim was to categorize patients into classes based on priority and determine the most efficient grouping pattern. Transitioning to the subsequent stage, the scheduling issue was conceptualized as a Markov Decision Process (MDP), due to the inherent uncertainty in patient arrivals, which requires a decision at the end of each day based on the observed total demands. Confronted with the difficulties arising from the extensive range of possibilities, often termed as the curse of dimensionality, the researchers utilized a method to assess the optimal solution for MDP. Drawing insights from the MDP results, a comparative policy was then suggested for the strategic planning of various classes of outpatients. The scheduling procedure was tested using the dataset provided by Alizadehsani et al. (2013), providing practical insights into the effectiveness of the developed approach.[5] In this paper, the authors present a methodology aimed at improving the efficiency of Emergency Departments (EDs) by employing Deep Reinforcement Learning (DRL) for patient scheduling. The study utilizes a Markov Decision Process (MDP) framework to model the intricate challenges associated with patient scheduling in Emergency Departments (EDs). Within this MDP framework, the authors then implemented Deep Q-Networks (DQN) as a key component of their scheduling strategy.In conclusion, this research paper presents a novel and promising approach to enhance the efficiency of Emergency Departments (EDs) through the use of Deep Reinforcement Learning (DRL) techniques. By employing a Markov Decision Process (MDP) framework and Deep Q-Networks (DQN) for patient scheduling, the authors have demonstrated the potential to significantly improve ED operations.
III. METHODOLOGY
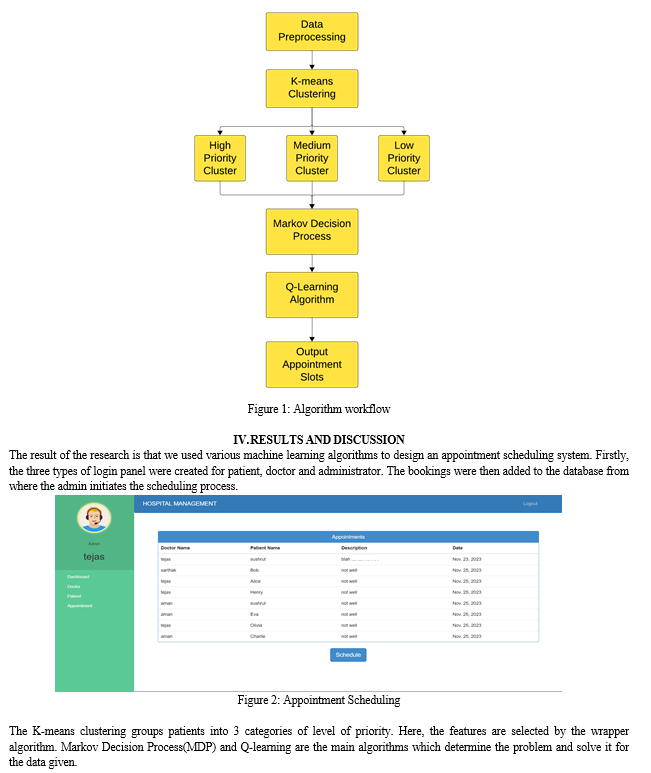
In this research, we have used k-means algorithm and markov decision process (MDP) with Q learning for patient scheduling and prioritization. The proposed model initiates when a patient books an appointment of a particular doctor by adding all the essential details, which gets stored in the database. SQLite is the database which is used to store all the details of patients and their medical condition. The administrator needs to login to access the information and perform any changes or view the appointments. The scheduling process is also initiated at this point.
A list is fetched from the database and selects features for the scheduling model. Wrapper’s algorithm is used for feature selection, it is a type feature selection method used in machine learning and data analysis to choose the best subset of features or variables for the proposed model.
Once the scheduling process is completed it generates a list of scheduled appointments and then adds it to the database and stores in that form. The User interface displays the scheduled appointment of the patient.
A. K-Means Clustering
K-means clustering is a well-known method in machine learning for grouping data points into clusters. It works by first randomly choosing K points as cluster centers. Then, every data point is allocated to a cluster whose center is nearest to it. The cluster centers undergo updates based on the points within their respective clusters, and these iterations persist until the process converges. To decide on the right number of clusters (K), the 'Elbow Method' is commonly used. In this study, we applied the elbow method and determined that three clusters were optimal. We labeled these clusters as High Priority, Medium Priority, and Low Priority. This approach helps organize data points into meaningful groups, making it easier to analyze and understand patterns in the data.



Conclusion
This research project dives into the domain of healthcare appointment scheduling, driven by the growing number of patients seeking medical attention. To counter the challenges posed by overcrowded hospitals and clinics, the study focuses on leveraging machine learning (ML) algorithms to design an innovative appointment prioritization system for doctors. The primary objective is to assist healthcare providers in efficiently allocating their time and resources by categorizing patients based on their medical history and conditions. By employing K-means clustering, Markov\'s Decision Process (MDP), and Q-learning, the research aims to automate appointment bookings according to patients\' medical profiles. Integrating advanced methodologies such as the Prioritization Algorithm for urgency-based categorization and MDP for dynamic scheduling, this research seeks to revolutionize the conventional approach to healthcare scheduling. Through K-means clustering, the model efficiently groups patients with similar needs, facilitating streamlined scheduling and resource optimization. This approach not only addresses the existing challenges of patient prioritization and resource allocation but also adapts to real-time changes in patient conditions, ushering in a more responsive and patient-centric healthcare scheduling system. By providing insights from various studies and cutting-edge technologies like reinforcement learning techniques observed in Deep Reinforcement Learning (DRL) and Deep Q-Networks (DQN), this research explores the domain of healthcare appointment scheduling. The proposed model aims to set goals by not just tackling the inefficiencies of current scheduling systems but by developing a more adaptive and resource-efficient healthcare delivery model. It holds the promise of enhancing patient outcomes while optimizing operational efficiencies in healthcare facilities.
References
[1] Yu, S., Kulkarni, V.G. and Deshpande, V., 2020. Appointment scheduling for a health care facility with series patients. Production and Operations Management, 29(2), pp.388-409. [2] Heshmat, M., Nakata, K. and Eltawil, A., 2018. Solving the patient appointment scheduling problem in outpatient chemotherapy clinics using clustering and mathematical programming. Computers & Industrial Engineering, 124, pp.347-358. [3] Cildoz, M., Mallor, F. and Mateo, P.M., 2021. A GRASP-based algorithm for solving the emergency room physician scheduling problem. Applied Soft Computing, 103, p.107151. [4] Yousefi, N., Hasankhani, F. and Kiani, M., 2019. Appointment scheduling model in healthcare using clustering algorithms. arXiv preprint arXiv:1905.03083. [5] Lee, S. and Lee, Y.H., 2020, March. Improving emergency department efficiency by patient scheduling using deep reinforcement learning. In Healthcare (Vol. 8, No. 2, p. 77). MDPI. [6] Ala, Ali, et al. \"Optimization of an appointment scheduling problem for healthcare systems based on the quality of fairness service using whale optimization algorithm and NSGA-II.\" Scientific Reports 11.1 (2021): 19816. [7] Azadeh, A., Farahani, M. H., Torabzadeh, S., & Baghersad, M. (2014). Scheduling prioritized patients in emergency department laboratories. Computer methods and programs in biomedicine, 117(2), 61-70. [8] Squires, M., Tao, X., Elangovan, S., Gururajan, R., Zhou, X., & Acharya, U. R. (2022). A novel genetic algorithm based system for the scheduling of medical treatments. Expert Systems with Applications, 195, 116464. [9] Qu, X., Peng, Y., Shi, J., & LaGanga, L. (2015). An MDP model for walk-in patient admission management in primary care clinics. International Journal of Production Economics, 168, 303-320. [10] Dai, Jiajun, Na Geng, and Xiaolan Xie. \"Dynamic advance scheduling of outpatient appointments in a moving booking window.\" European Journal of Operational Research 292.2 (2021): 622-632 [11] Srinivas, Sharan, and A. Ravi Ravindran. \"Optimizing outpatient appointment system using machine learning algorithms and scheduling rules: A prescriptive analytics framework.\" Expert Systems with Applications 102 (2018): 245-261. [12] Golmohammadi, Davood, Lingyu Zhao, and David Dreyfus. \"Using machine learning techniques to reduce uncertainty for outpatient appointment scheduling practices in outpatient clinics.\" Omega (2023): 102907.
Copyright
Copyright © 2024 Dr. Priyadarshan Dhabe, Sarthak Madhikar, Tejas Gambhir, Sushrut Patil, Aman Manakshe, Mehvish Mukadam. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET62714
Publish Date : 2024-05-25
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online