

Ijraset Journal For Research in Applied Science and Engineering Technology
Common Sense Reasoning on Fully Localized AI; A Novel systematic Survey
Authors: Karunakaran T, Dr. J M Dhayashankar
DOI Link: https://doi.org/10.22214/ijraset.2025.66589
Certificate: View Certificate
Abstract
In the modern world of AI, reasoning is the fundamental building block for it, from conversable AI to tasking robots from simple to humanoid, different decisions need to be made on the basis of the various reasoning which includes common sense. The most advanced systems still struggle with higher levels of reasons with common sense for which human is trivial. The paper brings survey on common sense reasoning that can be fully localized to bring in a state of the art frameworks for common sense reasoning to be fully localized. The paper also tries to bring forward that there is more research scope that can be explored. The paper also brings forward how conversational or task oriented and/or both Common Sense motivates research’s to bring in and explore a well-defined framework that can be applied to conversational AI which human like from simple virtual bots to humanoids or any other robots.
Introduction
I. INTRODUCTION
In the area of Conversable AI one of the aspects is Common Sense reasoning and is becoming more increasingly major focus of research in natural language processing (NLP) and robotics due to heavy hallucination and drifts on information over load. Common Sense in machine intelligence exits for a long time from now, however inculcate Common Sense as knowledge in AI still remains unsettled and exigent issue (Storks, Gao, and Chai 2019). The definition of Common Sense knowledge is took as a knowledge that is external considered in the world that all humans are assumed to co-exist (Liu and Singh 2004). Ironically something like “a person cannot be in two places in an instance locally” this conclusion will be by default given or granted by humans, but an AI or a robotic system will not have a taxonomy or explicit knowledge base as an approach. The references to canonicals (Ilievski Et el; 2021), Gordon and Hobbs (2017), there does not exists a framework or schematic catalogue for Common Sense base knowledge. This Common Sense base of knowledge and inference reasoning over that knowledge to make smart decisions or results in NLP, NLU are highly reaching areas. In a paradigm of neural approaches in conversational AI, Zellers Et el; cites “reasoning being in a neural space” this forms one of the tripartite in neural based conversational AI. Zellers identifies and calls out Common Sense knowledge, “Common Sense knowledge is critical in agents”. We emphasize that the boundary and scope is not adequately available and there is wide area of scope on research to be done in the area of Common Sense reasoning in and most specifically there is a grey area in localization of them, in despite Common Sense has large forums and groups working on different types of reasoning for neural types of models in conversational language processing. The most important aspect of Common Sense reasoning and by the literal definition and structure would require a specific niche external knowledge base in schematic or taxonomy, sources can from varied knowledge artefacts. There can be inference of common sense reasoning while pertaining which will be within the source raw feed as knowledge in training of models. There needs to be fusion of other external knowledge specific in for from of knowledge graphs which drastically will improve the common reasoning and can infer new derivatives using the same which will be tied with the regular approach of the training of data. There are references of Mobile Robots that are used for indoor through Open Mind Indoor Common Sense (OMICS) corpus and which emphasis on the need for task based Common Sense (Rakesh Gupta 2004). The approach of fusion of the dialog based conversable AI in conjunction of using a set of program with schematics for Robot Task Planning to derive knowledge using Common Sense for the actions (Yi Zhou2 2017). The research community predominantly uses commonly used corpus and Common Sense literature are CONCEPTNET (Speer, Chin, and Havasi 2017) and ATOMIC (Sap Et el; 2019a). There are also researchers who are trying to solve the same problem using a different approach using the neural networks (NN) to cipher Common Sense schematically, the most common approach is using transformer architecture (Vaswani Et el; 2017). COMET (Bosselut Et el; 2019) another reference of a well-known usage of transformer model of Neural network trained to derive a Common Sense knowledge base from ConceptNet and ATOMIC corpus, surprisingly has the ability to provide a unique novel schematic of Common Sense knowledge base.
The same was improved by some researchers in the later presentation in conference of 2020 in the name of ATOMIC 2020, this was proposed by Hwang and called them the “COMET” in the conference of ATOMIC 2020. After most of the findings the paper also tries to survey form most of the existing literature that is available in the topics of Common Sense reasoning in context to conversational AI in language models and task based robotics and put forth a discussion on the metrics used to measure and also how are the techniques or models that are used. There are references that are also made from different research which are pertaining to state-of-the-art AI models like BlenderBot3 (Shuster Et el; 2022) and LaMDA (Thoppilan Et el; 2022) which is most popular. The paper also focus on the most common issues to the state of the art benchmarking provided by community to validate and also the problems that are resolved in different paradigm of view point. Once the common problem is identified and discussed then the next issues are categorically discussed with DAG based knowledge graph and fine tuning them to provide a schematic structure to infer the explanations to each of them. The paper also focus on the research community renown benchmarks are published as proof of work, this gives insights of metrics that can be used for qualifying Common Sense knowledge in the true sense.
II. GERUND PROBLEMS WHILE USING CONVERSATIONAL INTELLIGENCE
The conversational intelligence issues with localization will be briefed (1) Conversable Classification, (2) Dialogue adapting models (3) Summarization of dialog systems and (4) Converse based Task (Ref III D). The category would be described with problem and would also provide instances of references of the research work that cover with datasets to bring forward the importance of Common Sense reasoning in locale that is pertaining to each problem. Table 1 lists the surveyed literature organized by these four conversational AI problems.
|
Publications |
Conversable classification |
Dialog Adapting Models |
MCQ |
Summarization of dialog systems |
Converse based Task |
|
Rakesh Gupta & Members (2017) OMICS |
|
|
|
|
X |
|
Young & members (2018) |
|
X |
|
|
|
|
Zhong, Wang, and Miao (2019) - KET |
X |
|
|
|
|
|
Ghosal & members (2020) - COSMIC |
|
X |
|
|
|
|
Majumder & members (2020) - COMPAC |
|
X |
|
|
|
|
Arabshahi & members (2021) - CLUE |
|
X |
|
|
|
|
Feng, Feng, and Qin (2021) - D-HGN |
|
|
|
X |
|
|
Ghosal & members (2021) - CIDER |
X |
|
X |
|
|
|
Li & members (2021) - DialogInfer |
X |
|
|
|
|
|
Qin & members (2021) - TimeDial |
X |
X |
X |
|
|
|
Zhang, Li, and Zhao (2021) - PoDS |
|
|
X |
|
|
|
Zhou & members (2021) |
|
X |
|
|
|
|
Zhou & members (2021) - TBS |
|
X |
|
|
|
|
Zhou & members (2021) - CEDAR |
|
X |
|
|
|
|
Arabshahi & members (2021b) - CORGI |
|
|
X |
|
|
|
Ma & members (2021) |
|
|
X |
|
|
|
Ghosal & members (2022) - CICERO |
|
X |
X |
|
|
|
Li & members (2022) - KEC |
X |
|
|
|
|
|
Sabour, Zheng, and Huang (2022) - CEM |
|
X |
|
|
|
|
Tu & members (2022) - Sentic GAT |
X |
|
|
|
|
|
Varshney, Prabhakar, and Ekbal (2022) - CNTF |
X |
|
|
|
|
|
Xie, Sun, and Ji (2022) - CKE-Net |
|
X |
|
|
|
|
Xu & members (2022) - DMKCM |
|
X |
|
|
|
|
Kim & members (2022b) - SICK |
|
|
|
X |
|
|
Wu & members (2020) - ConKADI |
|
X |
|
|
|
Table 1: Task classification for this paper
A. Conversable classification
The conversable should be in a natural way in a human like and should be able to also pass the Turing test. The conversation should be natural and human like to identify the purpose, emotion, context Et el; These dialogues which form the converse will derive skills of task in which the sequence of each classification including filling the next sequence of words (Mesnil Et el; 2014), intent conversation detection (Siddique Et el; 2021), emotion of the conversation (Zhong, Wang, and Miao (2019), Balahur, Hermida, and Montoyo (2011), Ghosal Et el; (2020) and domain specific classification (Jaech, Heck, and Ostendorf 2016), aware of the environment in robotics (Rakesh Gupta 2004, Yi Zhou2 2017) and there are many others. The most important aspect is the Common Sense reasoning with locale by which the paradigm of understanding the classification of task is done. The human mimic which is understood by the data that is present. The human-human dialog is assumed to be implicitly present in the data (Grice 1975). Modern models like BERT (Devlin Et el; 2018) captures implicit knowledge by design. The models can be used for classification which are typically fine-tuned using feature engineering or from the data from the classification. Researches can find corpus available that can be utilised to understand and fine tune on the basis of the hypothesis. DailyDialogue (Li Et el; 2017) consists of approximately 13K conversations scraped which forms learners as practice for their language in this case English. Mostly the corpus focus on the daily activities that a normal human would perform. One of the popular corpus is Emory Natural Language corpus (Zahiriand Choi 2018), this is from a famous English serial show. This corpus consists of around 12K dialogues, most of them are annotated with the context of emotions on the basis of the local context can also be derived.
B. Dialogue Adapting Models
The type of modelling is like to of a classical natural language task of a specific language with slight modification of changing the sequences of converse from an individual word. This can be utilised for conversable and also task oriented robots as well. Corpus for these conversable models namely MultiWOZ (Budzianowski Et el; 2018), DailyDialogue (Li Et el; 2017), PERSONA-CHAT (Zhang Et el; 2018), ConvAI2 (Dinan Et el; 2020), and Open Mind Indoor Common Sense (OMICS) (Yi Zhou 2017). Most of the legacy systems that are using modelling form a architectures explicitly follow natural language understanding and also typical natural language generation (NLG) (Chen Et el; 2017) and large neural models (Ni Et el; 2022). Most of them have sequence-to sequence model like GPT or BART (Lewis Et el; 2019), which take user converse as input and output responses directly to the user. The similar approach can be augmented with RAG based graph schematic enabling the response candidate to localize and provide converse with common sense. These models can be improvised by augmenting them with schematic RAG based knowledge graph with separate scoring as well Zhou Et el; (2021). Researches have also advanced in the similar approach with conversable Common Sense (Majumder Et el; 2020), however they lack the local and ability to perform Common Sense reasoning that can be localized. The Common Sense with human like interactions would improve and some of the case studies can be demonstrated with the lack of Common Sense and localization is never considered in current research models which is presented later.
C. Summarization of Dialogue Systems
Summarization by definition epigrammatic presentation of content which retains the factual information and is throughout consistent in conveying the message. The more often used in modern days of conversational systems used for teams, webx, zoom Et el; to summarize the meetings. These systems can automatically create key points and actions that were discussed.
The earliest attempts in the research community was the assistant system called CALO (Tur Et el; 2010). The human-human dialogs the most important aspect that can be inferred is that common sense reasoning would produce and productive, accurate, actionable and complete of such summaries. Language models face major challenge in information overload which causes drift and hallucinations and the system must be comprehensible consistent. Intelligible. Logical. Lucid. Meaningful, orderly, rational, reasoned and systematic with the facts to be presented (Qin 2021). Legacy and largest corpus are from ICSI Meetings (Janin 2003) and AMI Meeting (McCowan 2005). The ICSI corpus consists of around 75+ real meetings where there were around 50+ speaker with around 3 to 4 topics. Similarly AMI also contains 95+ hours of content scripts which can be utilized as a multi model with recording instruments with real and different scenario driven discussions among people in a meeting. DialogSum (Chen Et el; 2021) contains 13K conversations taken mostly widely used corpuses like DREAM and DailyDialog. One of the most important corpus is SAMsum which contains around 16K of conversations with prepared summaries with professional linguists (Gliwa Et el; 2019) which forms the training data and test data to infer the quality of model and the outcomes to provide benchmark and certify if they are performing on the expected bench mark. The corpus also consisted of validated data by linguists which are curated with complete typos and local slangs.
This enables the corpus as an appropriate fit for common sense reasoning system training and validation of the conversations between the groups of people in conjunction with using the mostly research widely use ConceptNet corpus (Qin etc. 2021) which makes it more apt to integrate the common sense and conversation summarization, similarly a recent research using the using COMET was used to generate common sense augmentation on the summarization of content Kim Et el; (2022). Even though these works have detail research and work however the common sense with localization conversation is still understudied to a greater extent (Feng and Qin etc. 2021).
III. APPROACHES AND TECHNIQUES OF INFERENCE
The objective is to explore different works that are done as a part of the research by fellow researches on how the learning process is applied as a part of the corpus and different techniques on which a machine can learn and validate. The validate is with the reference actual artefact as a proof of reference ability that the system is behaving as intended, constantly and also the pitfalls by which there is scope of improvements. The main focus and critical hotspot would be on common sense reasoning with localization in the perimeter of conversable artificial technology. The techniques that are explored in this paper is a generalized model tuning approach, schematic DAG based approach and using natural language and its similar algorithms to explain the outcomes.
???????A. Generalized Model Tuning
The research and other engineering community first approach would be on the basis of model fine tuning. The similar approach where in the corpus would be tailored with additional reference annotations in the context of learning of the common sense. This would be done by sub setting the existing large corpus to a scaled down version for instance the corpus that is provided by Ubuntu community, likewise form a daily dialogue etc. on the basis of the chat dialogues likewise (Lowe Et el; 2015). The most common one that is also used is DailyDialogue corpus (Li Et el; 2017) which also has a large corpus of data. The Chinese English learning school retrieval-based corpus which can be also used for this purpose is MuTual corpus referenced as (Cui Et el; 2020). The multi-choice MCQ type of corpus like DREAM corpus (Sun Et el; 2019). The derivative from all the above three is a CIDER corpus (Ghosal Et el; 2021). This consists data set in a triple data store a derivative of ConceptNet form which can be used as an inference to the common sense presentation or outcome over the data and the corpus is referred to CICERO and the paper references (Ghosal Et el; 2022). This is a subset of the larger corpus of CIDER with the linguist interference written scripts that can be inferred in the triplet’s store. There are MCQ type of corpus which is Time-Dial which uses different tasks (Qin Et el; 2021). The approach is on the focus of common sense reasoning which can derive however the localization is subjective to the modified corpus that is taken as a subset (Zhou et al 2021). The researches also collate additional corpus form the Amazon Mechanical Turk corpus named MTurk on the basis of different types of prompting from SoclalQA which can be referred in (Sap Et el; 2019) and (Zhou Et el; 2021). Later this work also creates a corpus called CEDAR a derivative from the ConceptNet for different types of explanations that can be inferred. The corpus was valued from the crowd sourcing community work (Moon Et el; 2019). The above derived to create a human to human interaction conversation using ParlAI as the base system for the research observations (Miller Et el; 2017) subsequently this was refered as Open DialKG, the triple store is later referred as entities that were contributed by the crowd sourcing community. The most important relevant topics for common sense that can be localized is the corpus from MIC which focus on the moral and ethical aspect of reasoning which has scope of localization (Ziems Et el; 2022) This is based on the definition of the rules that are defined as thumb rules which was proposed and published by (Forbes Et el; 2020 and Kim Et el; 2022). The derived work form the above mentioned corpus is Pro-social Dialogue corpus for different types of agents to response which are designed to be safe and can adequately respond to rash and unsafe users who utter unethical and un-warranted terms. Finally using the neuro symbolic methodology named CORGI which uses long and short term memory algorithms was utilized to pre assumed common sense conversations which was properly annotated and inferred results proves algorithmic and mathematically can provide evidences and indicators scientifically (Arabshahi Et el; 2021). This novel approach enables to build efficient and accurate result which are referable.
??????????????B. Schematic Directed acyclic graph Knowledge
The schematic knowledge can be built using different data set sources and mostly the popularly which the research community uses and they can be then directly applied or fused with the existing system which is no method that could be available out of the box to attach the conversation to common sense knowledge to enable reasoning with localization. Hence the application can be only by fusing the available known source which can be applied to the DAG based knowledge graphs. The most popular one is the ConceptNet as well as Atomic by Sap and team in 2019 to adopt common sense reasoning focused research. Some of the legacy adaptation by the research community was in the late 2016 by Young and team to bring forward the common sense which is fused with the DAG knowledge graph as external infusion to the existing model.
Some of them used the algorithm with n-grams to do the sequence matching with the corpus ma and team in 2021 by analysing the proving a zero-shot answering system in conjunction with the language models. The approach was to generate data that is derived from the facts to form synthetic data elements and this would be mapped algorithmically using the neuro symbolic architecture to derive a conjunction between the knowledge source and the other generative techniques. The triple store also enables the DAG based schematic approach to detection of emotion which was researched by Moon and team in 2019, the basis was on a derivative from the existing work of Zhong, Miao and team in 2019. Moon and team in 2019 schematically derived it to be a DAG based graph schema to be trained and to predict the knowledge in a history of conversations that could be later indexed for better follow up and result of the conversation and they use Long and Short term memory models along with BERT. The latest research on BERT by Devlin and team on 2018 has introduced keen interest in the transformer basis of re or pre training the models. The approach can improve by cipher the conversation history along with the facts and extract a BERT ranking system (Zhang, Li, and team 2021). The facts can be defined as part of speech tagging to form a semantic tuple store to inference knowledge (Tu and team 2022). The improvisation of the model with the DAG graph making a network augmentation could bring out the emotions, this fusion is a research of Veli?ckovi´c and team 2017 and . Xie, Sun, and team in 2022 in the ConceptNet to from a composite network in conjunction with generation of common sense which could also be summarised output to make an inference form sematic similarity in the embedded system to extract the summery (Zhou and team 2021). The similar infusion extracted the triples for evaluation of the matrix of the knowledge from ConceptNet corpus (Wu and team 2020) . Researches Varshney, Prabhakar,and team in 2022 have also derived triple store from ConceptNet for better response generation have utilized the similar approach by adding different techniques like named entity awareness and also coreference resolution methods to achieve knowledge extraction. Further an interesting approach of extracting knowledge in a document along with the corpus ConceptNet to from triples and enhance the model for better results (Xu Et el; 2022). Finally a group of researches Gupta, Jhamtani, and team in the year 2022 tried to coherently generated knowledge on the bases of targeted guided response system which could use a multi model and hop between different schemas to connect to the entities using neural methods and provide the results.
???????C. Summarization of conversation systems
The approach earlier explored was the graph based one and have some limitations to extend in the common sense knowledge. The graph based approach could be compute intensive some times. The approach that is prosed by Choi and team in 2022 is on the basis of neural network approach to express the common sense knowledge which can be derived to be localization as well. This explores the future research on focusing on natural languages that could explain the out comes in logical definitions and could even have explainers embedded in them. This also becomes a little difficult to explain the intellectual outcomes in a formal based logic theory outcomes but they could also exhibit common sense factual information that could define rules that are governed for a logical outcome. The similar paradigm of in the similar research was by Bosselut and team in 2019 who infused neural network models to form a common sense form the corpus of COMET which was prominent showing visible and tangible common sense results which had a levy of the other counterpart approaches. The derivative work was form PARA-COMET from team of Gabriel in 2021 with the implementation on in memory inference over paragraph text by Ghosal and team in 2020 which was able to use COMET to extract emotion conversable outcomes on the basis of the data that was fed to the system this was taken from the research approach of Li and team in 2021 using the ATOMIC corpus where they used LTSM and DAG based inference to extract the emotion form the conversations and an extended work also form the same researcher which enhanced in 2022 to enhance the COMET to infer usual emotional utterance through the network. Researches Arabshahi and team in 2021 were using COMET to used templated approach with if and because block on the explanations of the tasks in the conversation. Another method that was proposed by Majumder and team in 2020 which would infused different types of personas using GPT conversable agents using the COMET corpus which was able to generate different types of personas. Finally researcher Kim and team in 2022 utilised the PARA COMET corpus to generate cipher text for summarizing the utterance of conversations.
???????D. Converse based Task for Robot
The legacy of robots started with basic commands and now have improved to conversable task enables. The foundation was formed by Open Mind Indoor Common Sense (OMICS) in 2003 by research community. The common sense captures indoor details of thousands of pieces of common sense knowledge detailing home and others like the office types of environments. The contribution Rakesh Gupta and team to common sense data collection include specific domain localizing to increase the density of the knowledge base, the dynamically prompt of data using the prior available knowledge base from data. The object centric collect of data would focus on the objects and its properties.
They used comprehensive data manual to ensure the quality of knowledge is collected with the said objectives. The derived a structured set of activities that lead to a very deduce knowledge data set. The created knowledge was inferred for different actions. The probability was computed using Bayes formation to tag the room and objects. Although the robot uses the common sense knowledge to a very high level to decide which desires to pursue, it is yet not intelligent enough to actually execute the mid-level actionable which it desires. There was exhibit of common sense which can be utilized to the actual execution of different tasks, like cleaning of bath tub. The possibility of tele-reactive programs frameworks Nils Nilsson (1992; 1994) can also be used to accomplish more different tasks.
IV. BENCHMARKING
There are now communities who provide a platform to crate bench makes like the AI2 institute (Fig 1) which gives insights and benchmarks by community members who contribute to achieve accuracy in different subjects and in our case it is the common sense bench marking. Mostly the benchmark focus on the common sense would be from dialog form where different questions would be asked and answer would be presented. The bench marks are form common sense QA version 2 by Talmor and team in 2022, comm 2 sense by singh and team in 2021, ETHICS benchmarking by Hendycks in 2020 and finally CycIC which is based on a MCQ of single short answers benchmark by Talmor and team in 2018, khot and team 2020, wiogrande, sakguchi and team in 2021. The long answer and sentences by researchers Sap and team in 2019 using Social QA, Huang and team in 2019 by ConsmosQA, Bhagavatula and team in 2019, the SWAG results by Zellers and team in 2018, Zellers and team in 2019 with Hella-SWAG, PIQA by Bisk and team in 2020, Lourie and team in 2021 used rainbow to combine different other benchmarks to form a new benchmarking. A team of researchers including Lin in 2020 used Neuro-Sense masked modelling benchmark to focus on the temporal common sense reasoning. There are some benchmarks which evaluate them however they may also be misleading was presented by Kejriwal and team in 2022 as well. This also encouraged the community of common sense to derive novel approaches to evaluate common sense evaluations in classifications team and one such is the work of Choi in 2022, GRADE corpus by Huang and team in 2020, where in introduced responses with BERT in combination of DAG graph dialogue outcomes. The usage of ConceptNet for common sense outcome as grounding outputs and this was done by model to be trained self-supervised with real conversation with positive, random and negative samplings. Team of Zhou in 2021 have presented metrics for common sense generation that would be trained by human scores. The approach was a multiple in layers with neural network perceptron approach with symbolic infusion. Finally while cross analysing the ConceptNet triple store with history of the responses in conjunction with neural functionalities with DialoGPT by Zang and team in 2019 with scores of outcomes which was from well labelled human in the loop scores.
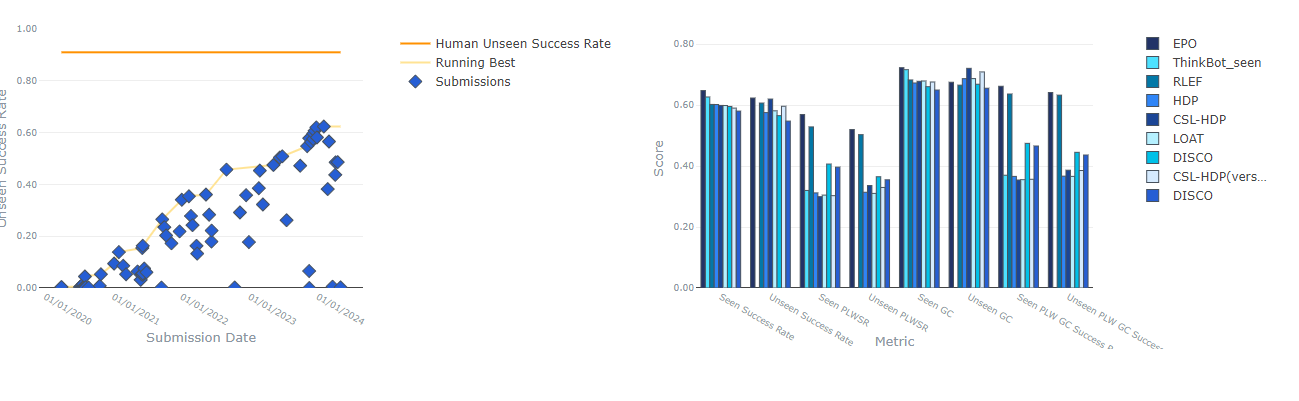 Fig 1 Leader board report
Fig 1 Leader board report
V. COMMON SENSE REASONING OBSERVATIONS
The novel approach of common sense with localization capabilities can be understood by the following models. The BlenderBot3 (BB-3) model (Shuster and team 2022) and LaMDA model which has researched by Thoppilan and team in 2022. BB-3 model is on the elements of OPT models (Zhang and team 2022), this is an open source which is equal to GPT-3. Similarly LaMDA model falls under the trained conversational model with large language around 137 billion parameters. The outcomes and initial observations are discussed which will enable future work to have a more comprehensive analysis in different models of common sense reasoning with localization adaptation in the models.
??????????????A. Blender Bot Model
The BB-3 has around three billion parameters which is available in different community providers like hugging face, even more parameters with 175 billion parameters are also available which as the state of the art results and can perform many tasks with more data sets. They also have a surprising element of common sense reasoning to some level of localization. This has the inference where it can exhibit of feeling nervous when performing in a large crowd of emotion.
However the quality of response is reduced drastically when an inconsistence and out of topic was uttered by the user. There were instances of BB-3 not responding to the context and could sometimes relate to nonsense utterance. The fluid conversations are smooth however this model demonstrates a lack of common sense reasoning and also it was not able to localize. The critical argument was on the aspect of the main component that was necessary for the conversable systems to be efficient and accurate (Cole and team 1995). Most of the evidences illustrate the even the best of the conversational models lack the accurate skills to optimally express the dialog to the intended user hence they also lack the essence of common sense and were not even close to localization of the responses.
??????????????B. LaMDA
This is one of the most important system where in the LaMDA language model (Thoppilan and 2022) which was initial evaluation of common sense reasoning. This consists of various indement demos which is showcased to interact with the large language model. Out of the three environments only one produces the demo dialogues settings which can write textual content freely which is refer as Talk about It (The Dog edition). The demo illustrates the role of tennis balls that were to be discussed about the dogs. Common sense reasoning and its capabilities from the LaMDA model was explicitly put forward and there were topics that violate common sense with localization questions as well and these violations was clearly visible to humans. The language model was also tested for self-awareness and the misunderstandings. In most cases the model was able to converse without any human to notice the variations. Some of the cases were also exhibited that few absurd conversations were noticed due to the lack of factual knowledge feed.
Conclusion
The paper attempts to arrive at a novel approach to common sense reasoning in AI and attempts were made to explore options of localization. The exhaustive study of literate and corpus of famous that can be used for common sense reasoning. We also bring forward the literature on the conversational AI problems and approaches like Conversable Classification, Dialogue adapting models Summarization of dialog systems and Converse based Task were analysed and the different aspects of common sense reasoning with localization was highlighted along with the corpus and other references of artefacts to understand the maturity of the research. There were exhaustive literature references to infer the common sense conversational AI which can be utilised in different above said areas. The future research on the common sense reasoning on conversable generative AI with localization and its outcomes were also presented Blender Bot 3 and LaMDA large language models. Finally we understand the it is taken from legacy systems to the current and there is huge difference in the utilization of them in the modern world, however there seems to be lot of scope that paves ways for research to discover and come with more modern approach.
References
[1] Baker, C. F., Fillmore, C. J., and Lowe, J. B. (1998): The Berkeley FrameNet project. in Proceedings of the COLING-ACL, Montreal, Canada. [2] Barry, B. & Davenport. G. (2002). Why Common Sense for Video Production? (Interactive Cinema Technical Report #02-01). Media Lab, MIT. [3] Cardie, C. (1997). Empirical Methods in Information Extraction, AI Magazine, 65-79. Chklovski, T. and Mihalcea, R. (2002). Building a Sense Tagged Corpus with Open Mind Word Expert. In Pro-ceedings of the Workshop on \"Word Sense Disambigua-tion: Recent Successes and Future Directions\", ACL 2002. [4] Eagle, N., Singh, P., and Pentland, A. (2003). Using Common Sense for Discourse Topic Prediction. Forth-coming MIT Media Lab, Human Design Group Technical Report. [5] Gentner, D. (1983). Structure-mapping: A theoretical framework for analogy. Cognitive Science, 7, pp 155-170. [6] Fellbaum, Christiane. (Ed.). (1998). WordNet: An elec-tronic lexical database. Cambridge, MA: MIT Press. [7] Hovy, E.H. and C-Y. Lin. (1999). Automated Text Sum-marization in SUMMARIST. In I. Mani and M. Maybury (eds), Advances in Automated Text Summarization. Cam-bridge: MIT Press, pp. 81-94. [8] Lenat, D. B. (1995). CYC: A large-scale investment in knowledge infrastructure. CACM 38(11): 33-38. [9] Liu, H., Lieberman, H., Selker, T. (2002). GOOSE: A Goal-Oriented Search Engine With Commonsense. Pro-ceedings of AH2002. Malaga, Spain. [10] Liu, H., Lieberman, H., Selker, T. (2003). A Model of Textual Affect Sensing using Real-World Knowledge. In Proceedings of IUI 2003. Miami, Florida. [11] Liu, H. (forthcoming). Using Common Sense to Improve a Brill-Based Part-of-Speech Tagger. White paper avail-able at: web.media.mit.edu/~hugo/montytagger/ [12] Liu, H., Singh, P. (2002). MAKEBELIEVE: Using Common Sense to Generate Stories. In Proceedings of AAAI-02. Edmonton, Canada. [13] Liu, H., Singh, P. (2003). OMCSNet v1.2. Knowledge Base, tools, and API available at: web.media.mit.edu/~hugo/omcsnet/ [14] Mueller, E. (1999). Prospects for in-depth story under-standing by computer. arXiv:cs.AI/0003003 http://www.signiform.com/erik/pubs/storyund.htm. [15] Resnik, P. (1997). Selectional preference and sense dis-ambiguation. In Proceedings of the ANLP-97 workshop: Tagging text with lexical semantics: Why, what, and how? Washington, DC. 424 [16] Singh, Push, Lin, Thomas, Mueller, Erik T., Lim, Grace, Perkins, Travell, & Zhu, Wan Li (2002). Open Mind Common Sense: Knowledge acquisition from the general public. In Proceedings of ODBASE’02. Lecture Notes in Computer Science. Heidelberg: Springer-Verlag. [17] Various Authors (2003). Common Sense Reasoning for Interactive Applications Projects Page. Retrieved from http://www.media.mit.edu/~lieber/Teaching/Common-Sense-Course/Projects/Projects-Intro.html on 1/9/03. [18] WordNet Bibliography. (2003). Retrieved from http://engr.smu.edu/~rada/wnb/ on 2/24/2003. [19] Bratman, M. 1987. Intention, Plans, and Practical Reason. Cambridge,MA: Harvard University Press. [20] Liu, H., and Singh, P. 2003. OMCSNet: A commonsense inference toolkit. Technical Report SOM02-01, MIT Media [21] Lab Society Of Mind Group. Liu, H.; Lieberman, H.; and Selker, T. 2003. Exploiting agreement and disagreement of human annotators for word sense disambiguation. In Proceedings of the Seventh International Conference on Intelligent User Interfaces (IUI 2003), 125–132. [22] Miller, G. A. 1995. WordNet: A lexical database for english.Communications of the ACM 38(11):39–41. Myers, K., and Konolige, K. 1992. Reasoning with analogical representations. In Nebel, B.; Rich, C.; and Swartout, W., eds., Principles of Knowledge Representation and Reasoning: Proceedings of the Third International Conference (KR92). San Mateo, CA: Morgan Kaufmann Publishers Inc. [23] Nilsson, N. J. 1992. Towards agent programs with circuit semantics. Technical Report STAN–CS–92–1412, Department of Computer Science, Stanford University, Stanford, CA 94305. [24] Nilsson, N. J. 1994. Teleo-reactive programs for agent [25] control. Journal of Artificial Intelligence Research 1:139– 158. Rao, A. S., and Georgeff, M. P. 1995. BDI-agents: from theory to practice. In Proceedings of the First Intl. Conference on Multiagent Systems. [26] Stork, D. G. 1999. The OpenMind Initiative. IEEE Expert Systems and Their Applications 14(3):19–20. [27] Stork, D. G. 2000. Open data collection for training intelligent software in the open mind initiative. In Proceedings of the Engineering Intelligent Systems (EIS2000). Wooldridge,M. 1999. Intelligent agents. InWeiss, G., ed.,Multiagent Systems: A Modern Approach to Distributed Artificial Intelligence. Cambridge, MA, USA: The MIT Press. 27–78. [28] Arabshahi, F.; Lee, J.; Bosselut, A.; Choi, Y.; and Mitchell, T. 2021a. Conversational Multi-Hop Reasoning with Neural Common Sense Knowledge and Symbolic Logic Rules. arXiv preprint arXiv:2109.08544. [29] Arabshahi, F.; Lee, J.; Gawarecki, M.; Mazaitis, K.; Azaria, A.; and Mitchell, T. 2021b. Conversational neuro-symbolic Common Sense reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, 4902–4911. [30] Balahur, A.; Hermida, J. M.; and Montoyo, A. 2011. Detecting implicit expressions of sentiment in text based on commonsense knowledge. In Proceedings of the 2nd Workshopon Computational Approaches to Subjectivity and Sentiment Analysis (WASSA 2.011), 53–60. [31] Bapna, A.; Tur, G.; Hakkani-Tur, D.; and Heck, L. 2017. [32] Sequential dialogue context modeling for spoken language understanding. arXiv preprint arXiv:1705.03455. [33] Bhagavatula, C.; Bras, R. L.; Malaviya, C.; Sakaguchi, K.; Holtzman, A.; Rashkin, H.; Downey, D.; Yih, S. W.-t.; and Choi, Y. 2019. Abductive Common Sense reasoning. arXiv preprint arXiv:1908.05739. [34] Bisk, Y.; Zellers, R.; Gao, J.; Choi, Y.; Et el; 2020. Piqa: Reasoning about physical Common Sense in natural language. In Proceedings of the AAAI conference on artificial intelligence, volume 34, 7432–7439. [35] Bosselut, A.; Rashkin, H.; Sap, M.; Malaviya, C.; Celikyilmaz, A.; and Choi, Y. 2019. Comet: Common Sense transformers for automatic knowledge graph construction. arXiv preprint arXiv:1906.05317. [36] Budzianowski, P.; Wen, T.-H.; Tseng, B.-H.; Casanueva, I.; Ultes, S.; Ramadan, O.; and Ga?si´c, M. 2018. MultiWOZ–a large-scale multi-domain wizard-of-oz dataset for task-oriented dialogue modelling. arXiv preprint arXiv:1810.00278. [37] Chen, H.; Liu, X.; Yin, D.; and Tang, J. 2017. A survey on dialogue systems: Recent advances and new frontiers. Acm Sigkdd Explorations Newsletter, 19(2): 25–35. [38] Chen, Y.; Liu, Y.; Chen, L.; and Zhang, Y. 2021. DialogSum: A real-life scenario dialogue summarization dataset. arXiv preprint arXiv:2105.06762. [39] Choi, E.; He, H.; Iyyer, M.; Yatskar, M.; Yih, W.-t.; Choi,Y.; Liang, P.; and Zettlemoyer, L. 2018. QuAC: Question answering in context. arXiv preprint arXiv:1808.07036. [40] Choi, Y. 2022. The Curious Case of Common Sense Intelligence. Daedalus, 151(2): 139–155. Cole, R.; Hirschman, L.; Atlas, L.; Beckman, M.; Biermann, A.; Bush, M.; Clements, M.; Cohen, L.; Garcia, O.; Hanson, B.; Et el; 1995. The challenge of spoken language systems: Research directions for the nineties. IEEE transactions on Speech and Audio processing, 3(1): 1–21. [41] Cui, L.; Wu, Y.; Liu, S.; Zhang, Y.; and Zhou, M. 2020. MuTual: A Dataset for Multi-Turn Dialogue Reasoning.arXiv:2004.04494 [cs]. ArXiv: 2004.04494. [42] Devlin, J.; Chang, M.-W.; Lee, K.; and Toutanova, K. 2018.Bert: Pre-training of deep bidirectional transformers for languageunderstanding. arXiv preprint arXiv:1810.04805. [43] Dinan, E.; Logacheva, V.; Malykh, V.; Miller, A.; Shuster,K.; Urbanek, J.; Kiela, D.; Szlam, A.; Serban, I.; Lowe, R.; Et el; 2020. The second conversational intelligence challenge(convai2). In The NeurIPS’18 Competition, 187–208.Springer. [44] Feng, X.; Feng, X.; and Qin, B. 2021a. Incorporating commonsenseknowledge into abstractive dialogue summarization via heterogeneous graph networks. In China National Conference on Chinese Computational Linguistics, 127–142. Springer. [45] Feng, X.; Feng, X.; and Qin, B. 2021b. A survey on dialogue summarization: Recent advances and new frontiers. arXiv preprint arXiv:2107.03175. [46] Forbes, M.; Hwang, J. D.; Shwartz, V.; Sap, M.; and Choi, Y. 2020. Social chemistry 101: Learning to reason about social and moral norms. arXiv preprint arXiv:2011.00620. [47] Gabriel, S.; Bhagavatula, C.; Shwartz, V.; Le Bras, R.;Forbes, M.; and Choi, Y. 2021. Paragraph-level commonsense transformers with recurrent memory. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, 12857–12865. [48] Gao, J.; Galley, M.; Li, L.; Et el; 2019. Neural approaches to conversational ai. Foundations and trends® in information retrieval, 13(2-3): 127–298. [49] Ghosal, D.; Hong, P.; Shen, S.; Majumder, N.; Mihalcea, R.; and Poria, S. 2021. CIDER: Common Sense Inference for Dialogue Explanation and Reasoning. arXiv:2106.00510 [cs]. ArXiv: 2106.00510. [50] Ghosal, D.; Majumder, N.; Gelbukh, A.; Mihalcea, R.; and Poria, S. 2020. Cosmic: Common Sense knowledge for emotion identification in conversations. arXiv preprint arXiv:2010.02795. [51] Ghosal, D.; Shen, S.; Majumder, N.; Mihalcea, R.; and Poria, S. 2022. CICERO: A Dataset for Contextualized Common Sense Inference in Dialogues. arXiv preprint arXiv:2203.13926. [52] Ghosh, S.; Vinyals, O.; Strope, B.; Roy, S.; Dean, T.; and Heck, L. 2016. Contextual lstm (clstm) models for large scale nlp tasks. arXiv preprint arXiv:1602.0629. [53] Gliwa, B.; Mochol, I.; Biesek, M.; and Wawer, A. 2019. Samsum corpus: A human-annotated dialogue dataset for abstractive summarization. arXiv preprint arXiv:1911.12237. [54] Gordon, A. S.; and Hobbs, J. R. 2017. A formal theory of Common Sense psychology: How people think people think.Cambridge University Press. Grice, H. P. 1975. Logic and conversation. In Speech acts, 41–58. Brill. [55] Gupta, P.; Jhamtani, H.; and Bigham, J. P. 2022.Target-Guided Dialogue Response Generation Using Commonsenseand Data Augmentation. arXiv preprint arXiv:2205.09314. [56] Hendrycks, D.; Burns, C.; Basart, S.; Critch, A.; Li, J.; Song, D.; and Steinhardt, J. 2020. Aligning ai with shared human values. arXiv preprint arXiv:2008.02275. [57] Huang, L.; Bras, R. L.; Bhagavatula, C.; and Choi, Y. [58] 2019. Cosmos QA: Machine reading comprehension with contextual Common Sense reasoning. arXiv preprint arXiv:1909.00277. [59] Huang, L.; Ye, Z.; Qin, J.; Lin, L.; and Liang, X. 2020. GRADE: Automatic graph-enhanced coherence metric for evaluating open-domain dialogue systems. arXiv preprint arXiv:2010.03994. [60] Hwang, J. D.; Bhagavatula, C.; Bras, R. L.; Da, J.; Sakaguchi, K.; Bosselut, A.; and Choi, Y. 2020. Comet-atomic 2020: On symbolic and neural Common Sense knowledge graphs. arXiv preprint arXiv:2010.05953. [61] Ilievski, F.; Oltramari, A.; Ma, K.; Zhang, B.; McGuinness, D. L.; and Szekely, P. 2021. Dimensions of commonsense knowledge. Knowledge-Based Systems, 229: 107347. [62] Jaech, A.; Heck, L.; and Ostendorf, M. 2016. Domain Adaptation of Recurrent Neural Networks for Natural Language Understanding. In Proceedings of INTERSPEECH. Janin, A.; Baron, D.; Edwards, J.; Ellis, D.; Gelbart, D.; Morgan, N.; Peskin, B.; Pfau, T.; Shriberg, E.; Stolcke, A.; and Wooters, C. 2003. The ICSI Meeting Corpus. In 2003 IEEE International Conference on Acoustics, Speech, and Signal Processing, 2003. Proceedings. (ICASSP ’03)., volume 1, I–I. [63] Kejriwal, M.; Santos, H.; Mulvehill, A. M.; and McGuinness, D. L. 2022. Designing a strong test for measuring true common-sense reasoning. Nature Machine Intelligence, 4(4): 318–322. [64] Khot, T.; Clark, P.; Guerquin, M.; Jansen, P.; and Sabharwal, A. 2020. Qasc: A dataset for question answering via sentence composition. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 34, 8082–8090. [65] Kim, H.; Yu, Y.; Jiang, L.; Lu, X.; Khashabi, D.; Kim, G.; Choi, Y.; and Sap, M. 2022a. ProsocialDialog: A Prosocial Backbone for Conversational Agents. arXiv preprint arXiv:2205.12688. [66] Kim, S.; Joo, S. J.; Chae, H.; Kim, C.; Hwang, S.-w.; and Yeo, J. 2022b. Mind the Gap! Injecting Commonsense Knowledge for Abstractive Dialogue Summarization. arXiv preprint arXiv:2209.00930. [67] Lewis, M.; Liu, Y.; Goyal, N.; Ghazvininejad, M.; Mohamed, A.; Levy, O.; Stoyanov, V.; and Zettlemoyer, L. 2019. Bart: Denoising sequence-to-sequence pre-training for natural language generation, translation, and comprehension. arXiv preprint arXiv:1910.13461. [68] Li, D.; Zhu, X.; Li, Y.;Wang, S.; Li, D.; Liao, J.; and Zheng, J. 2021. Enhancing emotion inference in conversations with Common Sense knowledge. Knowledge-Based Systems, 232: 107449. [69] Li, J.; Meng, F.; Lin, Z.; Liu, R.; Fu, P.; Cao, Y.; Wang, W.; and Zhou, J. 2022. Neutral Utterances are Also Causes: Enhancing Conversational Causal Emotion Entailment with Social Common Sense Knowledge. arXiv preprint arXiv:2205.00759. [70] Li, Y.; Su, H.; Shen, X.; Li, W.; Cao, Z.; and Niu, S. 2017. DailyDialog: A Manually Labelled Multi-turn Dialogue Dataset. arXiv:1710.03957 [cs]. ArXiv: 1710.03957. [71] Lin, B. Y.; Lee, S.; Khanna, R.; and Ren, X. 2020. Birds have four legs?! numersense: Probing numerical commonsense knowledge of pre-trained language models. arXiv preprint arXiv:2005.00683. [72] Liu, H.; and Singh, P. 2004. ConceptNet—a practical commonsense reasoning tool-kit. BT technology journal, 22(4): 211–226. Lourie, N.; Le Bras, R.; Bhagavatula, C.; and Choi, Y. 2021. [73] Unicorn on rainbow: A universal Common Sense reasoning model on a new multitask benchmark. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, 13480–13488. [74] Lowe, R.; Pow, N.; Serban, I.; and Pineau, J. 2015. The ubuntu dialogue corpus: A large dataset for research in unstructured multi-turn dialogue systems. arXiv preprint arXiv:1506.08909. [75] Ma, K.; Ilievski, F.; Francis, J.; Bisk, Y.; Nyberg, E.; and Oltramari, A. 2021. Knowledge-driven data construction for zero-shot evaluation in Common Sense question answering. [76] In Proceedings of the AAAI Conference on Artificial Intelligence, volume 35, 13507–13515. Majumder, B. P.; Jhamtani, H.; Berg-Kirkpatrick, T.; and McAuley, J. 2020. Like hiking? you probably enjoy nature: Persona-grounded dialog with Common Sense expansions. arXiv preprint arXiv:2010.03205. [77] McCowan, I.; Carletta, J.; Kraaij, W.; Ashby, S.; Bourban, S.; Flynn, M.; Guillemot, M.; Hain, T.; Kadlec, J.; Karaiskos, V.; Et el; 2005. The AMI meeting corpus. In Proceedings of the 5th international conference on methods and techniques in behavioral research, volume 88, 100. Citeseer. [78] Mesnil, G.; Dauphin, Y.; Yao, K.; Bengio, Y.; Deng, L.; Hakkani-Tur, D.; He, X.; Heck, L.; Tur, G.; Yu, D.; Et el; 2014. Using recurrent neural networks for slot filling in spoken language understanding. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 23(3): 530–539. [79] Miller, A. H.; Feng, W.; Fisch, A.; Lu, J.; Batra, D.; Bordes, A.; Parikh, D.; and Weston, J. 2017. Parlai: A dialog research software platform. arXiv preprint arXiv:1705.06476. [80] Moon, S.; Shah, P.; Kumar, A.; and Subba, R. 2019. Opendialkg: Explainable conversational reasoning with attentionbased walks over knowledge graphs. In Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics, 845–854. [81] Ni, J.; Young, T.; Pandelea, V.; Xue, F.; and Cambria, E.2022. Recent advances in deep learning based dialogue systems: A systematic survey. Artificial Intelligence Review,1–101. [82] Qin, L.; Gupta, A.; Upadhyay, S.; He, L.; Choi, Y.; and Faruqui, M. 2021. TIMEDIAL: Temporal Commonsense Reasoning in Dialog. arXiv:2106.04571 [cs]. ArXiv: 2106.04571. [83] Reddy, S.; Chen, D.; and Manning, C. D. 2019. Coqa: A conversational question answering challenge. Transactions of the Association for Computational Linguistics, 7: 249– 266. [84] Sabour, S.; Zheng, C.; and Huang, M. 2022. Cem: Commonsense-aware empathetic response generation. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 36, 11229–11237. [85] Sakaguchi, K.; Bras, R. L.; Bhagavatula, C.; and Choi, Y. 2021. Winogrande: An adversarial winograd schema challenge at scale. Communications of the ACM, 64(9): 99–106. [86] Sap, M.; Le Bras, R.; Allaway, E.; Bhagavatula, C.; Lourie, N.; Rashkin, H.; Roof, B.; Smith, N. A.; and Choi, Y. 2019a. Atomic: An atlas of machine Common Sense for if-then reasoning. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 33, 3027–3035. [87] Sap, M.; Rashkin, H.; Chen, D.; LeBras, R.; and Choi, Y. 2019b. Socialiqa: Common Sense reasoning about social interactions. arXiv preprint arXiv:1904.09728. [88] Shuster, K.; Xu, J.; Komeili, M.; Ju, D.; Smith, E. M.; Roller, S.; Ung, M.; Chen, M.; Arora, K.; Lane, J.; Et el; 2022. BlenderBot 3: a deployed conversational agent that continually learns to responsibly engage. arXiv preprint arXiv:2208.03188. [89] Singh, S.; Wen, N.; Hou, Y.; Alipoormolabashi, P.; Wu, T.- L.; Ma, X.; and Peng, N. 2021. COM2SENSE: A commonsense reasoning benchmark with complementary sentences. arXiv preprint arXiv:2106.00969. [90] Speer, R.; Chin, J.; and Havasi, C. 2017. Conceptnet 5.5: An open multilingual graph of general knowledge. In Thirtyfirst AAAI conference on artificial intelligence. [91] Storks, S.; Gao, Q.; and Chai, J. Y. 2019. Commonsense reasoning for natural language understanding: A survey of benchmarks, resources, and approaches. arXiv preprint arXiv:1904.01172, 1–60. [92] Sun, K.; Yu, D.; Chen, J.; Yu, D.; Choi, Y.; and Cardie, C. 2019. DREAM: A Challenge Data Set and Models for Dialogue-Based Reading Comprehension. Transactions of the Association for Computational Linguistics, 7: 217–231. [93] Talmor, A.; Herzig, J.; Lourie, N.; and Berant, J. 2018. Commonsenseqa: A question answering challenge targeting Common Sense knowledge. arXiv preprint arXiv:1811.00937. [94] Talmor, A.; Yoran, O.; Bras, R. L.; Bhagavatula, C.; Goldberg, Y.; Choi, Y.; and Berant, J. 2022. Commonsenseqa 2.0: Exposing the limits of ai through gamification. arXiv preprint arXiv:2201.05320. [95] Thoppilan, R.; De Freitas, D.; Hall, J.; Shazeer, N.; Kulshreshtha, A.; Cheng, H.-T.; Jin, A.; Bos, T.; Baker, L.; Du, Y.; Et el; 2022. Lamda: Language models for dialog applications. arXiv preprint arXiv:2201.08239. [96] Tu, G.; Wen, J.; Liu, C.; Jiang, D.; and Cambria, E. 2022. Context-and Sentiment-Aware Networks for Emotion Recognition in Conversation. IEEE Transactions on Artificial Intelligence. [97] Tur, G.; Stolcke, A.; Voss, L.; Peters, S.; Hakkani-Tur, D.; Dowding, J.; Favre, B.; Fern´andez, R.; Frampton, M.; Frandsen, M.; Et el; 2010. The CALO meeting assistant system. IEEE Transactions on Audio, Speech, and Language Processing, 18(6): 1601–1611. [98] Varshney, D.; Prabhakar, A.; and Ekbal, A. 2022. Commonsense and Named Entity Aware Knowledge Grounded Dialogue Generation. arXiv preprint arXiv:2205.13928. [99] Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A. N.; Kaiser, ?.; and Polosukhin, I. 2017. Attention is all you need. Advances in neural information processing systems, 30. [100] Veli?ckovi´c, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; and Bengio, Y. 2017. Graph attention networks. arXiv preprint arXiv:1710.10903. [101] Wu, S.; Li, Y.; Zhang, D.; Zhou, Y.; and Wu, Z. 2020. Diverse and informative dialogue generation with contextspecific Common Sense knowledge awareness. In Proceedings of the 58th annual meeting of the association for computational linguistics, 5811–5820. [102] Xie, Y.; Sun, C.; and Ji, Z. 2022. A Common Sense Knowledge Enhanced Network with Retrospective Loss for Emotion Recognition in Spoken Dialog. In ICASSP 2022-2022 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), 7027–7031. IEEE. [103] Xu, F.; Zhou, S.; Ma, Y.; Wang, X.; Zhang, W.; and Li, Z. 2022. Open-Domain Dialogue Generation Grounded with Dynamic Multi-form Knowledge Fusion. In International Conference on Database Systems for Advanced Applications,101–116. Springer. [104] Young, T.; Cambria, E.; Chaturvedi, I.; Zhou, H.; Biswas, S.; and Huang, M. 2018. Augmenting end-to-end dialogue systems with Common Sense knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence, volume 32. [105] Zahiri, S. M.; and Choi, J. D. 2018. Emotion detection on tv show transcripts with sequence-based convolutional neural networks. InWorkshops at the thirty-second aaai conference on artificial intelligence. [106] Zellers, R.; Bisk, Y.; Schwartz, R.; and Choi, Y. 2018. Swag: A large-scale adversarial dataset for grounded commonsense inference. arXiv preprint arXiv:1808.05326. [107] Zellers, R.; Holtzman, A.; Bisk, Y.; Farhadi, A.; and Choi, Y. 2019. HellaSwag: Can a machine really finish your sentence? arXiv preprint arXiv:1905.07830. [108] Zhang, S.; Dinan, E.; Urbanek, J.; Szlam, A.; Kiela, D.; and Weston, J. 2018. Personalizing dialogue agents: I have a dog, do you have pets too? arXiv preprint arXiv:1801.07243. [109] Zhang, S.; Roller, S.; Goyal, N.; Artetxe, M.; Chen, M.; Chen, S.; Dewan, C.; Diab, M.; Li, X.; Lin, X. V.; Et el; 2022. Opt: Open pre-trained transformer language models. arXiv preprint arXiv:2205.01068. [110] Zhang, Y.; Sun, S.; Galley, M.; Chen, Y.-C.; Brockett, C.; Gao, X.; Gao, J.; Liu, J.; and Dolan, B. 2019. Dialogpt: Large-scale generative pre-training for conversational response generation. arXiv preprint arXiv:1911.00536. [111] Zhang, Z.; Li, J.; and Zhao, H. 2021. Multi-Turn Dialogue Reading Comprehension With Pivot Turns and Knowledge. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 29: 1161–1173. [112] Zhong, P.; Wang, D.; and Miao, C. 2019. Knowledgeenriched transformer for emotion detection in textual conversations. arXiv preprint arXiv:1909.10681. [113] Zhou, P.; Gopalakrishnan, K.; Hedayatnia, B.; Kim, S.; Pujara, J.; Ren, X.; Liu, Y.; and Hakkani-Tur, D. 2021a. Commonsense-Focused Dialogues for Response Generation: An Empirical Study. arXiv preprint arXiv:2109.06427. [114] Zhou, P.; Gopalakrishnan, K.; Hedayatnia, B.; Kim, S.; Pujara, J.; Ren, X.; Liu, Y.; and Hakkani-Tur, D. 2021b. Think Before You Speak: Using Self-talk to Generate Implicit Common Sense Knowledge for Response Generation. arXiv preprint arXiv:2110.08501. [115] Zhou, P.; Jandaghi, P.; Lin, B. Y.; Cho, J.; Pujara, J.; and Ren, X. 2021c. Probing Causal Common Sense in Dialogue Response Generation. arXiv preprint arXiv:2104.09574. [116] Ziems, C.; Yu, J. A.; Wang, Y.-C.; Halevy, A.; and Yang, D. 2022. The moral integrity corpus: A benchmark for ethical dialogue systems. arXiv preprint arXiv:2204.03021. [117] G. Eason, B. Noble, and I. N. Sneddon, “On certain integrals of Lipschitz-Hankel type involving products of Bessel functions,” Phil. Trans. Roy. Soc. London, vol. A247, pp. 529–551, April 1955. (references) [118] J. Clerk Maxwell, A Treatise on Electricity and Magnetism, 3rd ed., vol. 2. Oxford: Clarendon, 1892, pp.68–73. [119] I. S. Jacobs and C. P. Bean, “Fine particles, thin films and exchange anisotropy,” in Magnetism, vol. III, G. T. Rado and H. Suhl, Eds. New York: Academic, 1963, pp. 271–350.
Copyright
Copyright © 2025 Karunakaran T, Dr. J M Dhayashankar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET66589
Publish Date : 2025-01-20
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online