

Ijraset Journal For Research in Applied Science and Engineering Technology
Computer Vision
Authors: Mrs. Arjoo Pandey
DOI Link: https://doi.org/10.22214/ijraset.2023.54701
Certificate: View Certificate
Abstract
Computer vision is a field of artificial intelligence that focuses on enabling computers to understand and interpret visual information from images or videos. It involves developing algorithms and techniques to extract meaningful insights, patterns, and knowledge from visual data, mimicking human visual perception capabilities. The abstract of computer vision encompasses a range of fundamental tasks and objectives, including: Image Classification: Classifying images into predefined categories or classes, such as distinguishing between different objects, animals, or scenes. Object Detection and Recognition: Locating and identifying specific objects within an image or video, often through the use of bounding boxes or pixel-level segmentation. Semantic Segmentation: Assigning semantic labels to each pixel in an image to distinguish between different objects or regions. Image and Video Captioning: Generating textual descriptions or captions that accurately describe the content of an image or video. Image Generation: Creating new images that possess specific characteristics or share similarities with a given set of training images, using techniques like generative adversarial networks (GANs). Face Recognition: Identifying and verifying individuals by analyzing facial features often used for applications like surveillance, biometric authentication, or social media tagging. Pose Estimation: Determining the positions and orientations of human bodies or specific body parts within images or videos, enabling applications like gesture recognition or virtual reality. Tracking and Motion Analysis: Following and analyzing the movement of objects or individuals across frames in a video sequence, allowing applications like object tracking or activity recognition. 3D Reconstruction: Creating three-dimensional models of objects or scenes from two-dimensional image data, enabling applications in augmented reality, virtual reality, or robotics. Visual Understanding and Scene Understanding: Going beyond individual objects and analyzing the overall context, relationships, and semantics of a scene, enabling higher-level understanding of visual data. Computer vision finds applications in various domains, including healthcare, autonomous vehicles, robotics, surveillance, augmented reality, content analysis, and industrial automation. It continues to advance with the emergence of deep learning techniques and the availability of large-scale annotated datasets, leading to significant progress in visual recognition, understanding, and synthesis.
Introduction
I. INTRODUCTION
Computer vision is an interdisciplinary field that combines computer science, artificial intelligence, and image processing to enable computers to understand and interpret visual information from images or videos. It aims to replicate human vision capabilities by developing algorithms and techniques that can analyze, process, and extract meaningful insights from visual data. The primary goal of computer vision is to enable computers to see and understand the visual world just as humans do. It involves tasks such as image classification, object detection, semantic segmentation, image generation, and more. These tasks allow computers to recognize objects, understand scenes, track movement, and make sense of visual data. Computer vision algorithms typically operate on digital images or video frames, analyzing pixel values, colors, textures, shapes, and spatial relationships to extract meaningful information. These algorithms can be trained using machine learning techniques, such as deep learning, where large datasets of labeled images are used to teach the computer how to recognize and interpret visual patterns. The applications of computer vision are vast and diverse. In healthcare, computer vision can aid in medical image analysis, helping to detect diseases or anomalies in medical scans. In autonomous vehicles, computer vision is used for object detection and recognition, enabling cars to perceive their surroundings and make intelligent decisions. Surveillance systems utilize computer vision for detecting and tracking objects or individuals in real-time. Additionally, computer vision has applications in augmented reality, robotics, content analysis, and many other fields. Advancements in computer vision have been fueled by the increasing availability of powerful hardware, the growth of large-scale annotated datasets, and the development of deep learning models. These advancements have led to significant progress in visual recognition, understanding, and synthesis, making computer vision an exciting and rapidly evolving field.
As computer vision continues to advance, it holds the potential to revolutionize various industries, enhance human-computer interaction, and enable new capabilities in areas such as healthcare, transportation, entertainment, and beyond.
II. TYPES OF COMPUTER VISION
There are several types or subfields of computer vision, each addressing different aspects of visual understanding and analysis. Here are some common types of computer vision tasks:
- Image Classification: This task involves categorizing images into predefined classes or categories. For example, classifying images of animals into different species or distinguishing between various objects.
- Object Detection: Object detection focuses on locating and identifying specific objects within an image or video. It typically involves drawing bounding boxes around objects of interest.
- Semantic Segmentation: Semantic segmentation involves assigning semantic labels to each pixel in an image to differentiate different objects or regions. It provides a detailed understanding of the image at a pixel level.
- Instance Segmentation: Instance segmentation goes a step further than semantic segmentation by not only assigning semantic labels but also differentiating between individual instances of objects within an image.
- Object Tracking: Object tracking aims to follow and track the movement of objects across multiple frames in a video sequence. It is particularly useful in applications like surveillance or autonomous vehicles.
- Pose Estimation: Pose estimation is about determining the positions and orientations of objects or specific body parts within an image or video. It is commonly used in applications involving human pose analysis or robotics.
- Image Generation: Image generation involves creating new images that possess specific characteristics or share similarities with a given set of training images. Techniques like generative adversarial networks (GANs) are often used for this purpose.
- Visual Recognition: Visual recognition encompasses a broad range of tasks, including image classification, object detection, and scene understanding. It involves the overall understanding and interpretation of visual content.
III. FLOW DIAGRAM
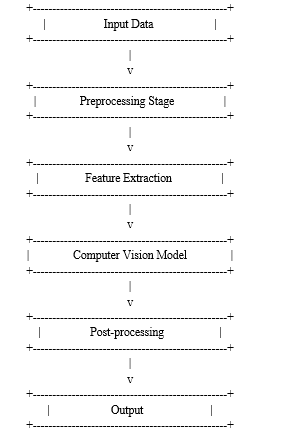
A. Let's Briefly Explain Each Component
- Input Data: This represents the raw visual data, such as images or video frames, that serve as the input to the computer vision system.
- Preprocessing Stage: The input data undergoes preprocessing, which may include operations like resizing, normalization, color space conversion, noise reduction, or any other preprocessing steps specific to the application. This stage prepares the data for further analysis.
- Feature Extraction: In this stage, relevant features are extracted from the preprocessed data. Features can be based on color, texture, shape, edges, or other visual characteristics. The goal is to capture meaningful information that can be used for subsequent analysis.
- Computer Vision Model: This component represents the core of the computer vision system. It encompasses the algorithms, models, and techniques used for specific computer vision tasks, such as image classification, object detection, semantic segmentation, or any other task based on the system's objectives. The model leverages the extracted features to perform the desired analysis.
- Post-processing: The results obtained from the computer vision model are refined and processed further. This stage may involve filtering, thresholding, removing false positives, or applying additional algorithms to enhance the accuracy or quality of the output. Post-processing helps to refine the results and ensure they align with the desired objectives.
- Output: The final output of the computer vision system is produced, which can take various forms depending on the task. It could include classifications, bounding boxes, pixel labels, visualization overlays, or any other visual information generated by the system. The output represents the insights or understanding derived from the visual data.
Please note that the diagram presents a high-level overview, and the specific implementation of a computer vision system may involve additional stages, components, or variations depending on the specific application and requirements.
B. Object Detection and Recognition
This area focuses on developing algorithms and models for accurately detecting and recognizing objects within images or videos. It includes techniques like convolutional neural networks (CNNs), region-based approaches (such as Faster R-CNN), and single-shot approaches (such as YOLO).
C. Image Classification
Image classification involves assigning predefined labels or categories to images. It includes techniques like deep learning-based classification models (e.g., AlexNet, VGGNet, ResNet) and methods utilizing handcrafted features and traditional machine learning algorithms (e.g., Support Vector Machines).
D. Semantic Segmentation
Semantic segmentation aims to assign semantic labels to each pixel in an image, providing a detailed understanding of the image at a pixel level. Deep learning models such as Fully Convolutional Networks (FCNs), U-Net, and Mask R-CNN are commonly used for semantic segmentation.
E. Object Tracking
Object tracking focuses on the task of locating and following objects across frames in a video sequence. It involves algorithms that can handle challenges like occlusion, scale variation, and appearance changes. Tracking-by-Detection methods and tracking algorithms based on optical flow are popular approaches.
F. 3D Computer Vision
3D computer vision deals with reconstructing the three-dimensional structure of objects or scenes from two-dimensional images or videos. Topics in this area include stereo vision, structure from motion, depth estimation, and 3D object recognition.
G. Pose Estimation
Pose estimation involves estimating the position and orientation of objects or human body parts within images or videos. It has applications in augmented reality, robotics, motion capture, and human-computer interaction.
H. Video Analysis
Video analysis aims to extract meaningful information from video data. It includes tasks such as action recognition, event detection, video summarization, and activity forecasting.
I. Deep Learning for Computer Vision
Deep learning has revolutionized computer vision, and research in this area focuses on developing and improving deep neural network architectures for various computer vision tasks. This includes exploring network architectures, regularization techniques, transfer learning, and domain adaptation.
J. Generative Models
Generative models, such as generative adversarial networks (GANs) and variational autoencoders (VAEs), are used to generate new images, enhance image quality, or perform tasks like image-to-image translation and style transfer.
K. Applications of Computer Vision
Computer vision finds applications in various domains, including healthcare (medical image analysis, disease diagnosis), autonomous vehicles, surveillance, augmented reality, robotics, content analysis, and industrial automation.
These are just a few examples of the many research areas and topics within computer vision. The field is vast, and there are ongoing advancements and research efforts across numerous subfields and application domains.
IV. METHODOLOGY
The methodology in computer vision refers to the approach and techniques used to solve a specific problem or perform a particular task within the field of computer vision. It involves a systematic process that encompasses various stages, including data acquisition, preprocessing, feature extraction, model selection, training or learning, evaluation, and validation. Here's a general outline of the methodology in computer vision:
Problem Definition: Clearly define the problem or task to be addressed in the context of computer vision. Determine the specific objectives, requirements, and constraints of the problem you aim to solve.
Data Acquisition: Gather or acquire the relevant data necessary for your computer vision task. This may involve collecting images or video data from various sources, utilizing existing datasets, or generating synthetic data.
Preprocessing: Preprocess the acquired data to enhance its quality and facilitate subsequent analysis. Common preprocessing steps include resizing, normalization, noise reduction, color space conversion, or any other data-specific transformations.
Feature Extraction: Extract meaningful features from the preprocessed data that can be used to represent and characterize the visual information. This step aims to capture important visual cues such as color, texture, edges, or shape. Feature extraction can involve handcrafted features (e.g., SIFT, HOG) or deep learning-based methods that learn features automatically (e.g., convolutional neural networks).
Model Selection: Select an appropriate model or algorithm that aligns with the problem and data characteristics. Depending on the task, this may involve choosing from a range of models such as classification models (e.g., CNNs), object detection models (e.g., Faster R-CNN), or segmentation models (e.g., FCNs).
Training or Learning: Train the selected model using the labeled data. This typically involves optimization techniques such as backpropagation and gradient descent to adjust the model's parameters. For deep learning models, large-scale datasets and specialized frameworks (e.g., TensorFlow, PyTorch) are often used for efficient training.
Evaluation and Validation: Assess the performance and effectiveness of the trained model. This involves evaluating the model's accuracy, precision, recall, F1 score, or other relevant metrics using appropriate evaluation protocols (e.g., cross-validation, hold-out validation). Validation ensures that the model generalizes well to unseen data and can be reliably used for the intended application.
Iterative Refinement: Analyze the results, identify areas of improvement, and refine the methodology iteratively. This may involve fine-tuning the model, adjusting hyperparameters, augmenting the training data, or incorporating feedback from the evaluation phase.
Application Deployment: Apply the developed methodology to real-world scenarios or applications. This may involve deploying the model in a production environment, integrating it with other systems or devices, and addressing any scalability or deployment challenges.
Conclusion
In conclusion, computer vision is a dynamic and rapidly advancing field of artificial intelligence that focuses on enabling computers to understand and interpret visual information from images or videos. It combines techniques from computer science, machine learning, and image processing to replicate human vision capabilities. Computer vision has a wide range of applications across various domains, including healthcare, autonomous vehicles, surveillance, robotics, augmented reality, content analysis, and more. It plays a crucial role in tasks such as object detection and recognition, image classification, semantic segmentation, pose estimation, and 3D reconstruction. Advancements in deep learning, specifically convolutional neural networks (CNNs), have significantly boosted the performance and accuracy of computer vision systems. These models have demonstrated remarkable capabilities in image analysis, achieving human-level or even surpassing human-level performance in specific tasks. However, computer vision still faces challenges such as handling occlusion, variations in lighting conditions, object scale, and viewpoint changes. Researchers continue to work on developing robust and efficient algorithms to address these challenges and improve the performance of computer vision systems. Moreover, the availability of large-scale annotated datasets, improved computational power, and advancements in hardware technologies have propelled the progress of computer vision research and development. The field is characterized by a vibrant research community, frequent publication of new techniques and models, and active collaboration among academia, industry, and open-source communities. As computer vision continues to evolve, it holds immense potential for transforming industries, improving safety and security, enhancing human-computer interaction, and enabling new applications and services. It is an exciting field with promising opportunities for innovation, research, and real-world impact
Copyright
Copyright © 2023 Mrs. Arjoo Pandey. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET54701
Publish Date : 2023-07-08
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online