

Ijraset Journal For Research in Applied Science and Engineering Technology
Content Based Image Retrieval Using Colour and Shape Features
Authors: Kalavakuri Sheela
DOI Link: https://doi.org/10.22214/ijraset.2025.66916
Certificate: View Certificate
Abstract
Advances in image acquisition and storage technology have led to tremendous growth in significantly large and detailed image databases. These images, if analyzed, can reveal useful information to the human users. Content based image retrieval (CBIR) deals with the extraction of implicit knowledge from the image database. Feature selection and extraction is the pre-processing step of CBIR. Obviously this is a critical step in the entire scenario of CBIR. Though there are various features available, the aim is to identify the best features and thereby extract relevant information from the images and these features are compared with the query image features and retrieve the images closely relative to the query image. Index terms
Introduction
I. INTRODUCTION
The emergence of multimedia, the availability of a large digital archives, and the rapid growth of World Wide Web (WWW) have recently attracted research efforts in providing tools for effective retrieval of image database. Efficient image classification and accessing tools are of predominant importance in order to fully utilize the increasing amount of digital data available on the Internet and digital libraries. Recent years have seen a growing interest in developing effective methods for searching large image databases. Image databases are utilized in diverse areas, such as advertising, medicine, entertainment, crime detection, digital libraries. Retrieval of image data has traditionally been based on human insertion of some text describing the picture, which can then be used for searching by using keyword based search methods. However, as the databases grow larger, the traditional keywords based method to retrieve a particular image becomes ineffective and suffers from the following limitations 1) It is difficult to express visual content like color, texture, shape, and object within the image precisely. 2) For a large data set, it requires more experienced labor and need very large, advanced keyword systems. 3) Further, the keywords increase linguistic barrier to share image data globally. To overcome several of these limitations, CBIR approach has emerged as a promising alternative. CBIR is very active research topic in recent years. In CBIR, images are classified by its own visual contents, such as color, texture, and shape. The main advantage of CBIR is its ability to support visual queries. The challenge in CBIR is to develop the techniques that will increase retrieval accuracy and reduce the retrieval time. The Content description may represent color, shape, texture, region or spatial features, etc. Such feature vector of every individual image is stored in the image feature database. For a given query image, feature vector is calculated in same manner as that of database image. Similarity between query and database image is calculated by finding the distance between feature vectors of these two images. If the distance is small we consider corresponding image in the database matches the query. The search is usually based on similarity rather than on exact match and retrieval results are ranked according to a similarity index.fig.1.shows the block diagram consisting of following main blocks. Functions of each block are as Follows
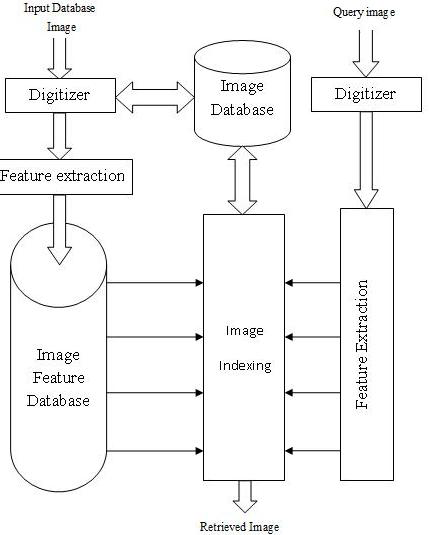
Fig.1. Architecture of the image retrieval
Image database: The comparison between query image and database image can be done directly pixel by pixel which will give precise match but on the other hand, distinguishing objects entirely at query time will limit the retrieval speed of the system. Due to the high expense of such computing, generally this crude method of comparison is not used.
Feature extraction: To avoid above problem of pixel-by-pixel comparison next abstraction level that is used for representing images is the feature level. Feature extraction plays an important role in CBIR to support efficient and fast retrieval of similar images from image databases. Significant features should be extracted from image data. Every image is characterized by a set of features such as texture, color, shape, spatial location etc. These features are extracted at the time of putting new image in image database and stored in image feature database. The query image is processed in the same way as images in the database. Matching is carried out based on the feature database
II. IMAGE RETRIEVAL USING COLOR FEATURE
In content based Image retrieval, color descriptor has been one of the first choices because if one chooses a proper representation, it can be partially reliable even in presence of changes in lighting, view angle, and scale. A color space is defined as a model for representing color in terms of intensity values. In this work, only three dimensional color space, RGB is investigated. Histogram search characterizes an image by its color distribution, or histogram.
Color histogram: An image histogram refers to the probability mass function of the image intensities. This is extended for color images to capture the joint probabilities of the intensities of the three color channels. More formally, the color histogram is defined by,
Where A, B and C represent the three color channels (R, G, B) and N is the number of pixels in the image. Computationally, the color histogram is formed by discretizing the colors within an image and counting the number of pixels of each color.
Color histogram distance measure: There are several distance formulas for measuring the similarity of color histograms.Essentially, the color distance formulas arrive at a measure of similarity between images based on the perception of color content. The distance formula that have been used for image retrieval Manhattan distance. This distance function is computationally less expensive than Euclidean distance. This is more moderate approach by using sum of the absolute differences in each feature, rather than their squares, as the overall measure of dissimilarity. This sum of absolute distance in each dimension is sometimes called the city block distance or the Manhattan distance and is defined as
Where n is the number of variables, and xi and yi are the values of the ith variable, at points x and y respectively
III. IMAGE RETRIEVAL USING SHAPE FEATURES
Finding the similarity between shapes is a fundamental problem, with applications in computer vision, molecular biology, computer graphics, and a variety of other fields. A challenging aspect of this problem is to find a suitable shape representation that can be constructed and compared quickly, while still distinguishing between similar and dissimilar shapes

Fig.2. Algorithm for D2 shape distribution
shape representation that can be constructed and compared quickly, while still distinguishing between similar and dissimilar shapes.
D2 shape distribution: To compute the D2 shape feature for a shape of an image , the image is first converted into an unoriented point set representation by sampling the geometry of the image by generating points at random location on every surface of the image. Different edge detection techniques are used to get the point set. Figure 2 is showing the algorithm for the D2 shape distribution. The D2 shape function is a 1D histogram generated by counting the population of the point-pair distances that falls within a certain distance interval. Figure 3 and Figure 4 are representing the point set representations of the animal and airplane respectively. As it is based on the unoriented point set representation, it is insensitive to the orientation of the surfaces in the original image.
Computing Shape descriptor: There are numerous shape-based similarity measures developed for images. Present work focuses on the shape distribution , D2. An image is made up of a finite number of vertices and faces. Theoretically, on those faces lie an infinite
number of points. The distances between all pairs of points on the surface of the image have a probability distribution. This probability distribution is D2, called a shape distribution because it is based on a feature of

Fig.3. Point set generated for Animation
the image shape, i.e. distances between all pairs of points.Figure 4 are the shape descriptors of the animal and airplane respectively.D2 shape distribution is distinctive for each, and therefore represents the images overall shape, i.e.it can be used as a shape descriptor.
Similarity measure: Selection of a suitable distance metric or similarity measure between a query image and each of the database images plays a key role in CBIR. Both, query image and each database image are represented by their corresponding feature vectors. The distance between the corresponding feature vectors measures the similarity between a query image database image. This distance function is computationally less expensive than Euclidean distance. This is more moderate approach by using sum of the absolute differences in each feature, rather than their squares, as the overall measure of dissimilarity. This sum of absolute distance in each dimension is sometimes called the city block distance or the Manhattan distance.
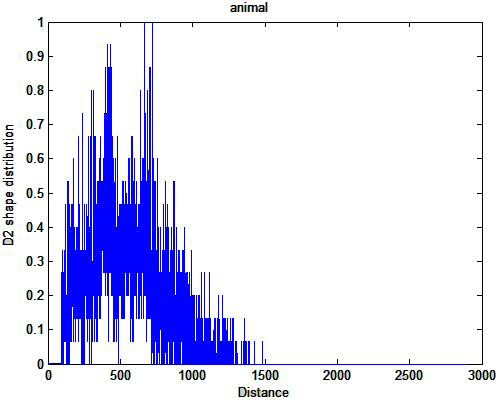
Fig. 4.Shape descriptor for Animal
IV. IMAGE RETRIEVAL USING COLOR AND SHAPE FEATURES
The color features and shape features can be combined to create an even more powerful characterization of image content. In certain situations, color and shape alone do not sufficiently describe a region of interest or object within an image. We combined the color and shape features obtained from the earlier experiments.
Weight assignment: we use the two or more features to retrieve the images. It is an intractable problem for retrieval system and users. Assign different weight [1; 4] to these features in retrieval, will get different results. In order to rightly use these low-level image features and solve feature weight assignment problem, Distance formula for the combined feature can be calculated as
V. RESULTS
For evaluation of the proposed method, some query images were selected randomly from a 1000 image subset of the database. The images in the database have different shapes and are categorized in 18 classes. Each class contains 40-100 pictures in JPG format. Within
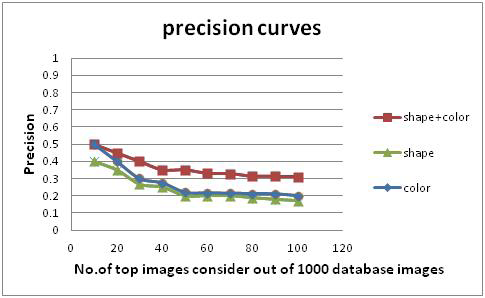
Fig.5. Comparison of the Retrieval Precision of different Features
this database, it is known whether any two images are of the same category. In particular, a retrieved image is considered a match if and only if it is in the same category as the query. This assumption is reasonable, since the 15 categories were chosen so that each depicts a distinct semantic topic. Figure 5and Figure 6illustrates query results of our indexing-retrieval program developed based on the Color Histogram, D2 shape distribution and combination of these two color and shape features. Each query results in a pre selected number of retrieved images which are illustrated and listed in ascending order according to the distance between indexing vectors of the query and retrieved images.
Precision and Recall: Performance evaluation experiment based on image features is used to evaluate the retrieval performance of different features on the same image database, which uses the same similarity measure. The experiment selects three methods for image retrieval which are color histogram, D2 shape distribution and combined features (color + shape). Figure 5 and Figure 6 compares the overall average retrieval precision and recall of the three distinct image categories from top 10, 15,…50 returned images. Here, we use Manhattan distance to shape for similarity measure. The experiment results indicate that the precision of color feature is superior to shape feature with the same number of returned images, the retrieval results obtained from combined features fits more closely with human perception than the retrieval result obtained from single-feature. When N increases, the precision of a same feature presents downtrend, the reason is that ground truth set keeps invariable while N increases, after sorting, the most correct images line in the front of the queue. The closer to the end of the queue, the accurate probability is lower. So N is bigger, precision is lower. Recall tends to increase as the number of retrieved images increase.
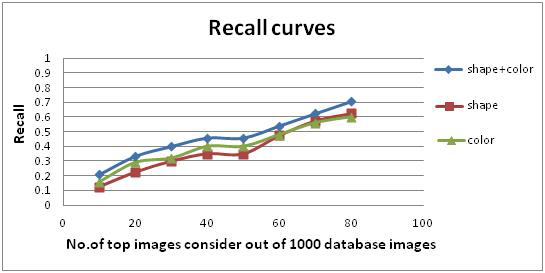
Fig. 6. Comparison of the Retrieval Recall of different Features
Conclusion
Present work describes the research and development of content based image retrieval system particularly image retrieval systems namely feature extraction and similarity measurement. Several new techniques, which are efficient both in terms of retrieval accuracy and retrieval time, are presented. A detailed study of the retrieval performance D2 shape distribution function and distance metric such as Manhattan distance for shape and color image retrieval is presented. A large shape database of images derived from the Princeton web site is used to check the retrieval performance. This study has clearly demonstrated that retrieval performance not only depends on a good set of features but also on use of suitable similarity measure. The investigation carried out in the present work leaves tremendous scope for extension and applications in the field of digital image processing and pattern recognition, the present work also leaves enough scope for further research in the direction of obtaining scale invariant shape features for content based image retrieval. Further research could be carried out on extending the present retrieval system for the 3D models, which need prerequisite knowledge about the polygons, and computer graphics. Significant research outputs are expected in near future with the use of other shape describing functions A2, which can be used for scale invariant.
References
[1] M.J Swain and D.H Ballard,”color indexing”,intl J.comput.vis.7(1),112(1991). [2] B.M.Mehtre, M.S.kankanhalli, A.D Narasimhulu and G.C.Man, ”color matching for image retrieval”, pattern recognition let.16,325 331(march 1995). [3] Anil K.Jain, Aditya Vailaya, ”Image retrieval using color and shape”,pattern recognition,vol.29,no.8,pp.1233-1244,1996. [4] R. Osada, T. Funkhouser, B. Chazelle and D. Dobkin, ”Matching 3D Models with Shape Distributions”, Shape Matching Int., 154-166. (2001). [5] T. Funkhouser, P. Min, M. Kazhdan, J. Chen, A. Halderman, D.Dobkin, D. Jacobs, ”A Search Engine for 3d Models”, ACM Transactions on Graphics. pp. 83-105 (2003). [6] D. Barker, ”Methods for Content-Based Retrieval of 3D Model”, 2nd Annual Conference on Multimedia Systems (January, 2003). [7] P. Shilane, and T.Funkhouser, ”Selecting Distinctive 3D Shape Descriptors for Similarity Retrieval”, Shape Modeling International. (June, 2006). [8] Conrado R. Ruiz Jr, Rafael Cabredo, Levi Jones Monteverde,Zhiyoung Huang, ”Combining Shape and Color for Retrieval of 3D Models”, ncm, pp.1295-1300, 2009 Fifth International Joint Conference on INC, IMS and IDC,2009. [9] The image database is available on http://www.cs.cmu.edu/ cil/v images.html.
Copyright
Copyright © 2025 Kalavakuri Sheela. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET66916
Publish Date : 2025-02-11
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online