

Ijraset Journal For Research in Applied Science and Engineering Technology
Crowd Anomaly Detection Using Machine Learning
Authors: Dr. Kavuri. K.S.V.A. Satheesh, Sk. Waaheda Zeenathul Quraan, G. Mercy Jasper, Ch. Sai Teja, Ch. Sai Vignesh, V. Lohith
DOI Link: https://doi.org/10.22214/ijraset.2024.59849
Certificate: View Certificate
Abstract
Surveillance videos have become crucial objects for ensuring the safety and security of crowded places such as concerts, subways, airports, and many others. In recent times, the installation of security cameras has rapidly increased in both public and private places. The complexity of finding the anomaly will increase drastically as the amount of footage increases and there may be occlusions for the analysis of the video, which consumes both time and may result in false detections. To overcome these drawbacks, we have produced an approach using machine learning algorithms. In this approach, we use the background subtractor for the elimination of the static things in the video frames and concentrate on the dynamic things. Secondly, we extract the spatio-temporal features from the individual frame to increase the efficiency of the detection. This approach is evaluated using the UCSD Dataset, which comprises 50 training and 48 testing samples. The effectiveness of this approach has been testified against metrics such as F1 score, Recall, Precision, and Accuracy
Introduction
I. INTRODUCTION
The biggest challenges of anomaly identification in crowds are false positives, background clutter, and occlusion. The goal of recent technological developments has been to increase crowd anomaly detection's efficacy. Machine learning has recently advanced quickly in addressing these difficulties with the use of algorithms that can discern between normal and aberrant behavior and evaluate complex data patterns.
We have mainly used machine learning methods, such as the k-neighbors and decision tree classifiers, to improve the ability to distinguish between normal and aberrant behavior. The uploaded video frames' attributes are utilized to train the decision trees. The characteristics include human activities, spatiotemporal elements, etc. As a result, by training the classifier on various kinds of video frames, we may raise its performance. We are utilizing the K-Neighbors classifier, which can recognize patterns in the frames that contradict each other as well as the commonalities between typical video frames.
Our method additionally makes use of the background subtractor, which distinguishes between dynamic and static items individually. It is crucial for crowd anomaly identification because, when we remove the static elements from the video frames, we may reduce the amount of time needed. There will be many video frames with static and dynamic patterns.
II. LITERATURE REVIEW
Recently, computer vision has become interested in identifying dense and crowded areas. Problems such as classifying videos according to crowded groups [1], estimating crowd sizes [2], and determining the targets of individuals in the crowd are research topics of science. The most popular are color flow as ARG ET AL or other types of spatioLemoryporal Adam. [3] Use histograms to check the potential of the visual field. Kim and Grauman [4] use a combination of PCA models to model local optical properties and use Markov random fields (MRFs) to maintain global consistency. Mehran et al. [5] are inspired by classical group behavior studies, which use concepts such as relationships to describe the behavior of groups. Boiman and Irani [6] used spatiotemporal patches and reported areas as disparities that could not be reconstructed using data from previous frameworks. Spatiotemporal gradients, whose statistics are modeled using integrated HMMs, were proposed in [7] to detect anomalies in crowded conditions. We identify three characteristics that an agent should have: 1) a common model of the appearance and quality of the crowd model; 2) physical detection capabilities; and 3) spatial anomalies. We then propose to use dynamic texture (DT) as a representation [8]. We then introduce DT-based spatial and temporal normality models. Temporal normality is modeled using a combination of DT [9] (MDT), and spatial normality is measured using an MDTbased discriminative saliency detector [10].
Basic facts and performance evaluation procedures regarding adverse events are provided. Finally, the vulnerability detection algorithm is tested against the previous algorithm to create a set of security measures against which future algorithms can be compared. ?
III. PROPOSED METHODOLOGY
The methods we have employed for our approach are described in this section. Our approach consists of four steps. First, the input video frames undergo data preparation. Second, the spatiotemporal and optical flow patterns are extracted from the preprocessed data. Third, the k-neighbor and decision tree classifiers serve as the foundation for the model's definition. Fourth, the model is evaluated by running the trained model against the testing video frames.
A. Data Preprocessing
The UCSD dataset, which was collected via a stationary camera with several camera angles, is the primary dataset that we used for our project. It is made up of the Ped1 and Ped2 datasets.
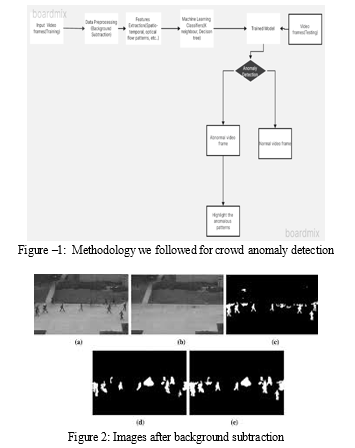
B. Feature Extraction
Following the preprocessing stage, features including the optical flow, spatiotemporal, and histogram of oriented graphics (HOG) are extracted using the preprocessed data. The features that characterize optical flow calculate object motion between frames and produce an optical flow vector between the motions.
We can increase the range of genuine detections by using the spatio-temporal characteristics, which include information about each frame's spatial and temporal aspects. The process of extracting spatial characteristics from video frames involves the usage of HOG.
The OpenCV library is used for the feature extraction in our project which contains functions such as “cv2.calcOpticalFlowFarneBack()” for optical flow features and “cv2.HOGDescriptor()” for the HOG extraction.
C. Defining Model
In our model, we have used machine learning classifier models such as the decision tree classifier and k-neighbour classifier.
- Decision Tree Classifier: Following the second stage of feature extraction, the retrieved features are fed into the classifier, which uses them to categorize the video frames and differentiate between normal and anomalous frames. While learning, the classifier differentiates the frames recursively according to their region, captured motion, and other factors, ultimately creating a decision tree. In the end, it has a decision tree with leaf nodes, each of which includes roots representing features and leaves representing flag values denoting normal or deviant behavior. For this distinction, the decision rules are the primary source of dependence for the decision tree classifier.
- K-Neighbours Classifier: We have also employed k-neighbors in our project to improve our outcomes. K-Nearbors functions by identifying patterns in the video frames and calculating the distance for the "Euclidean Distance" feature. Any frame that is more than this Euclidean distance is regarded as abnormal.
We utilized the sci-kit-learn library, which has pre-defined models for the trees and neighbors, to create the classifier.
D. Testing the model
Using the preprocessed data from steps one through two, we trained our model in the third phase. We now use the testing movies in the dataset to test our trained model. The testing films are occasionally pre-processed, but they are also assessed against the model, and pre-process extraction must be done if necessary. The computation of accuracy and efficiency among several metrics, including accuracy, F1score, and recall, is highlighted in the results. Following testing, we can apply our model to video clips. When we provide our video sample, the model does the classification and, if any anomalies are found, the anomalous patterns are indicated as seen below with a white rectangular box.

Conclusion
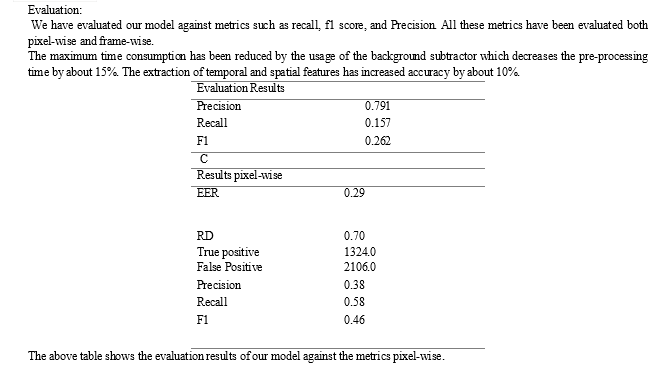
We developed a model that makes use of machine learning techniques like decision trees and k-neighbor classifiers. We tested our technique on the UCSD dataset, which is a benchmark dataset. One of the main factors in the time consumption decrease has been the use of background subtractors. The classifiers perform tasks on the entire dataset, look for patterns in the video clips, and construct a decision tree with features at the root and final values representing normal and abnormal. We documented the outcomes of both pixel-wise and frame-wise evaluations of our model using measures including precision, recall, and F1 score.
References
[1] S..Ali and. Shah. A lagrangian particle dynamics approach for crowd flow segmentation and stability analysis. In CVPR, pages 1–6, 2007. [2] D. Kong, D. Gray, and H. Tao. Counting pedestrians in crowds using viewpoint invariant training. In BMVC,2005. [3] A. Adam, E. Rivlin, I. Shimshoni, and D. Reinitz. Robust real-time unusual event detection using multiple fixed-location monitors. PAMI, 30(3):555–560, March 2008. [4] J. Kim and K. Grauman. Observe locally, infer globally: A space-time mrf for detecting abnormal activities with incremental updates. In CVPR, pages 2921–2928, 2009. [5] R. Mehran, A. Oyama, and M. Shah. Abnormal crowd behavior detection using the social force model. In CVPR, pages 935–942, 2009. A. Adam, E. Rivlin, Shimshoni and D. Reinttiz “Robust Real-Time Unusual Event Detection”, March 2008 [6] O. Boiman and M. Irani. Detecting irregularities in images and video. IJCV, 74(1):17–31, August 2007. [7] L. Kratz and K. Nishino. Anomaly detection in extremely crowded scenes using spatio-temporal motion pattern models. In CVPR09, pages 1446–1453, 2009. [8] G. Doretto, A. Chiuso, Y. N. Wu, and S. Soatto. Dynamic textures. IJCV, 51(2):91–109, 2003. [9] A. B. Chan and N. Vasconcelos. Modeling, clustering, and segmenting video with mixtures of dynamic textures. PAMI, 30(5):909–926, May 2008. [10] D. Gao and N. Vasconcelos. Decision-theoretic saliency: computational principle, biological plausibility, and implications for neurophysiology and psychophysics. Neural Computation, 21:239–271, Jan 2009
Copyright
Copyright © 2024 Dr. Kavuri. K.S.V.A. Satheesh, Sk. Waaheda Zeenathul Quraan, G. Mercy Jasper, Ch. Sai Teja, Ch. Sai Vignesh, V. Lohith. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET59849
Publish Date : 2024-04-05
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online