

Ijraset Journal For Research in Applied Science and Engineering Technology
Customizable Sign Language Gesture Prediction for Assistive Devices Using Machine Learning
Authors: Ujwal Sharma, Om Tiwari, Riddhesh Sankhe, Sneha M Yadav
DOI Link: https://doi.org/10.22214/ijraset.2024.60791
Certificate: View Certificate
Abstract
The objective of this investigate consider is to move forward human-computer interaction by presenting an progressed machine learning approach that predicts hand developments in real-time. By utilizing a mix of computer vision and cutting-edge models such as CNNs and RNNs, the framework shows exact comprehension of different hand signals. Assessments uncover that exchange learning and information increase strategies move forward show generalization. Emphasizing the conceivable impact on areas such as robots and virtual reality, the think about gives a premise for future advancements in user-friendly HCI
Introduction
I. INTRODUCTION
Human Computer Interaction (HCI) has ended up an critical viewpoint of advanced innovation, empowering clients to associated with computers through natural and helpful modes of communication. This report centers on the part of sign dialect in human-computer interaction (HCI) frameworks. Human-computer interaction (HCI) could be a field of ponder that looks at how individuals associated with computer frameworks, and how computer frameworks can be outlined to encourage such intuitive. Over the past few decades, computer frameworks have ended up an necessarily portion of our day by day lives, and the require for viable and proficient interaction between people and computers has gotten to be progressively critical. In this setting, the part of sign dialect in HCI frameworks has picked up increasing attention in later a long time.
Sign dialect may be a visual dialect that employments a combination of hand motions, facial expressions, and body developments to communicate. It is the foremost expressive strategy of communication among hearing impeded individuals and plays a pivotal part in empowering them to associated with the hearing world. In any case, the utilize of sign dialect as a mode of communication between normal and hard of hearing individuals postures a few challenges. One of the key challenges is the acknowledgment of sign dialect, because it requires the capacity to precisely decipher the meaning of hand gestures. Sign dialect acknowledgment (SLR) frameworks have been created to address this challenge. Past ponders have utilized sensor-based SLR frameworks that required endorsers to wear coloured gloves or utilize sensors on their fingers. Be that as it may, these frameworks were badly designed and more restrictive for underwriters. In differentiate, computer vision-based procedures utilize uncovered hands without sensors or coloured gloves and are cheaper and more versatile compared to sensor-based methods.
Hand signals, a essential angle of human communication, offer an intuitively way to communicate eagerly and commands. Tackling the control of machine learning and computer vision, analysts have endeavored to create frameworks able of precisely deciphering and reacting to these motions in real-time. The objective of these endeavors is to form interfacing that are not as it were proficient but too natural, permitting clients to associated with innovation in a way that mirrors the way they normally communicate with each other.
This paper digs into the domain of machine learning-based hand motion forecast, pointing to upgrade the field of HCI. By understanding and anticipating hand motions, we open the entryway to a plenty of applications, extending from immersive virtual reality encounters to more compelling human-robot collaborations. This presentation gives a see into the centrality of hand-based intelligent, setting the arrange for a comprehensive investigation of the techniques and headways within the machine learning space that contribute to the advancement of brilliantly frameworks for human-computer interaction.
As we dive more profound, we'll reveal the challenges, methodologies, and results related with executing these innovations, eventually clearing the way for a more characteristic and user-friendly interaction worldview.
II. LITERATURE REVEIW
Paper[1]- Arpita and Akshit used Google's mediapipe to identify sign dialects in a research article they released. The suggested demonstration had an average exactness of 99% and seemed to be quite strong, productive, and precise.
The innovation is now more comfortable and user-friendly thanks to the implementation of Support Vector Machine (SVM) calculation, which enables real-time precise position without the need for any wearable sensors.
Paper [2] In Wang and Popovic's real-time hands monitoring implementation, the color design associated with the hands was recognized using the K-Nearest Neighbors (KNN) method; nonetheless, the framework demands continuous replenishment of hands streams. Regardless, in the research done by Rekha et al.
Paper [16] -Pavlovic et al. examined several approaches to hand gesture interpretation in human-computer interaction in a 1997 study. The paper discusses the benefits and drawbacks of employing a 3D model or an image representation of the human hand.Despite providing more accurate depictions of gestures using the hands, 3-dimensional models confront computational difficulties that hinder real-time processing for human-computer interaction. Jiyong along with others
Paper [17] - Created a real-time system using Hidden Markov Models (HMMs) for continual Chinese Sign Language (CSL) recognition. The framework took as entry data that had not been processed from a 3-D tracker and two Cyber-Gloves. Using the Energetic Programming (DP) method, the preparatory phrases were divided into basic components, and the Welch-Baum computation was employed for estimation. The test comes about appeared a acknowledgment rate of 94.7% utilizing 220 words and 80 sentences.
III. DRAWBACKS IN EXISTING SYSTEM
The existing drawbacks in the current structure prevent it from being as valuable as it may be. First of all, its limited adaptability cannot keep up with changing customer demands and technological advancements. Clients frequently experience difficulties while attempting to explore interacting, which can lead to unpleasant experiences and the requirement for customization options. There are still many unanswered questions about information security and protection from possible compromises and vulnerabilities. The framework, which relies on manual forms rather than utilizing machine learning techniques for efficient task execution, requires insights and computerization. Its drawbacks are further exacerbated by compatibility problems, adaptability problems, and high maintenance expenses. The system's inefficient aspects are compounded by antiquated development stacks and insufficient documentation, while resistance to change and availability concerns limit its ability to adapt to changing client needs and stay up to date with industry advancements.
IV. PROPOSED SYSTEM
The recommended framework highlights how important it is to use the MediaPipe framework, a well-known open-source technology created by Google. This framework recognizes points of interest in the hand and manages palm localization well. MediaPipe Hands uses a pipeline for machine learning made up of linked models. One model is devoted to palm detection; it creates an aligned hand bounding box by using the complete image. Using the cropped region that the palm detector provides, another model concentrates on hand key point recognition, producing extremely precise 3D hand key points. With up to 100 photos each gesture, this technology enables the extraction of 21 important points from the hand, resulting in the creation of an extensive database. The spatial information is represented by the coordinates [x, y, z], where x and y are normalized to the range [0.0, 1.0] according to the image's width and height, respectively.
- Facial Recognition: A student’s computer or smartphone front camera is equipped with a webcam. Face recognition technology is employed to identify the user, verifying their identity by matching it with trained data set matching with the co oridnates .If the match is successfully the user is assigned with the alphabet and the following words are formed .
- Design Detail: Hand recognition and land markers that indicate independent models provide the foundation of the machine learning pipeline of the hand tracking the system.Following identifying the hand, the standard procedure is to look for landmarks in the present frame.
V. METHODOLOGY USED
STAGE 1: The MediaPipe framework allows programmers to build multi-modal (video, audio, and any time series data) cross-platform machine learning pipelines. 38 models for tracking and human body recognition are freely available on MediaPipe, and they are all trained on the largest and most diverse dataset on Google. MediaPipe pipelines are made up of nodes on a graph, which are typically specified in a pb.txt file.
One of the many interconnected models that make up the Media Pipe Hands machine learning pipeline is a palm identification model, which uses the full image to generate an optimal bounding box for the hand. An alternative model, the hand landmark model, uses the cropped image inside the box's boundaries to generate remarkably realistic 3D hand key points.We may obtain up to 100 images using this way.
These coordinates are represented as [x, y, z], where x and y are normalized to [0.0, 1.0]. Point of interest extraction takes 10 to 15 minutes, depending on the dataset's estimated size. Each image in the dataset is processed through stage 1 in order to aggregate all of the information focuses into a single record, with previous stage taken into consideration the finder's x and y arrangements.
The x and y arranges were normalized and pointless spots were expelled some time recently part the information record into preparing and approval sets. 80% of the information was utilized for preparing the show with diverse optimization and misfortune capacities, whereas 20% was utilized for show approval.
Machine learning calculations were utilized to perform prescient investigation of different sign dialects, with profound neural systems (DNN) demonstrating to be the foremost viable. Compact models comprising of numerous layers of neural systems organized in profundity and width are utilized by profound neural systems (DNNs), which are a sort of machine learning calculation. These systems are competent of analyzing and preparing information based on its person components, such as the pitch of a sound, when displayed with data.
STAGE 2: The detector's x and y coordinates are gathered and saved in a file, just like in step 1. Next, the data is examined for null entries resulting from blurry photos, and the Pandas library is used to eliminate these rows. After the preprocessing stage, the data is divided into a train set (75%) and a validate set (25%) after being scaledaccording to the model.

As the first layer, the convolutional layer uses mathematical operations called convolutions to extract features from input images while maintaining pixel associations. Convolution is essential to neural networks, especially CNNs, as it allows them to handle small squares of input data and learn characteristics from images. The last pooling or convolutional layer provides the input for the fully connected layer; the output is flattened there before being fed into the fully connected B.Support Vector machine (SVM):
Support Vector Machines (SVMs) play a significant part in hand gesture-based computer interaction, advertising a strong arrangement for signal acknowledgment. In this application, SVMs are utilized as directed machine learning calculations. The method starts with the securing of a dataset containing hand signal pictures or video arrangements.
Preprocessing steps, counting resizing and normalization, improve the data's pertinence. Include extraction takes after, including the recognizable proof of key angles like hand shape and movement directions. Each motion is alloted a name for classification. The SVM is at that point prepared on a part dataset, learning a choice boundary that successfully separates different motion classes within the include space. Relegate names to each test in your dataset comparing to the hand gesture it speaks to. For case, each motion could be alloted a one of a kind course name. Preparing the SVM:
Part your dataset into preparing and testing sets. The preparing set is utilized to prepare the SVM, and the testing set is utilized to assess its execution.Feed the preparing information (features) and comparing names into the SVM algorithm.The SVM learns a decision boundary that best isolates the diverse classes (signals) within the include space.Testing and Evaluation:
Utilize the testing set to assess the SVM's execution on unseen data.Measure measurements such as exactness, accuracy, review, and F1 score to check how well the SVM can classify hand signals.

Evaluation metrics such as accuracy and precision gauge the SVM's performance on a testing set. In real-time scenarios, the trained SVM processes live video feed, enabling the recognition of gestures. The recognized gestures can be linked to specific commands, facilitating user interaction with computers. Continuous optimization, including parameter tuning, ensures the system's adaptability and effectiveness over time, making SVMs a valuable tool for hand gesture recognition in computer-based interface.
VII. RESULT AND DISCUSSION
A confusion matrix may be a principal device within the assessment of the execution of a classification calculation. It gives a point by point breakdown of the model's forecasts and the genuine results, making a difference to evaluate the model's exactness, exactness, review, and other execution measurements. The network is especially valuable in scenarios where the classification assignment includes numerous classes
Consolidating the results of a classification operation into a square matrix is what the confusion matrix does. Among its essential parts are:
- True Positives (TP): Cases where the model predicts the positive class with accuracy.
- True Negatives (TN): Cases where the model predicts the negative class with accuracy.
- False Positives (FP): Cases in which the model predicts the positive class erroneously (Type I error).
- False Negatives (FN): Those cases in which the model predicts the negative class inaccurately (Type II).
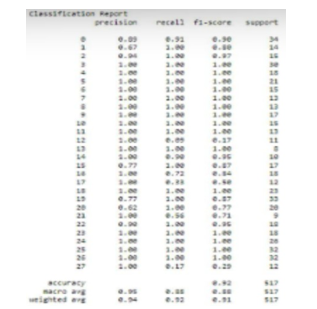
Precision is the degree to which positive projections are accurate. TP/(TP+FP) = precision. Stated differently, recall assesses the classifier's accuracy in identifying every positive example. It is computed by dividing the total number of true positives and fraudulent negatives in each class by the number of true positives.
FN: Inaccurate Negatives Recall: The percentage of positives that were effectively identified. Recall is equal to TP divided by (TP+FN). The F1 score is a statistic that uses a weighted harmonic mean to integrate recall and precision into a single value. Since F1 scores take precision and recall into account while generating scores, they are generally lower than accuracy measures. Instead of using global accuracy for comparing classifier models, use the average weighted of F1 scores.
A. Confusion Matrix
Within the domain of human-based computer interaction (HCI), a disarray lattice serves as a principal algorithmic apparatus for assessing the efficacy of classification frameworks planned to translate client intelligent. This handle starts by characterizing the pertinent classes or categories, frequently speaking to particular sorts of client behaviors or input modalities. In this way, a dataset is amassed, comprising labeled occurrences of client intelligent that span the characterized classes. Preprocessing steps, on the off chance that essential, point to upgrade the data's highlights for eThe genuine client intelligent are at that point encouraged, permitting the conveyed classification show to anticipate the comparing classes based on client input. The disarray framework is developed by comparing these forecasts with the ground truth, labeling occurrences as Genuine Positives, Genuine Negatives, Untrue Positives, or Untrue Negatives. From this framework, key execution measurements such as precision, exactness, review, and F1 score are calculated, advertising a quantitative evaluation of the model's interaction acknowledgment capabilities. The resulting investigation of the perplexity lattice guides assist cycles and refinements to the show, guaranteeing persistent enhancement in precisely translating and reacting to differing client intelligent inside the HCI space.
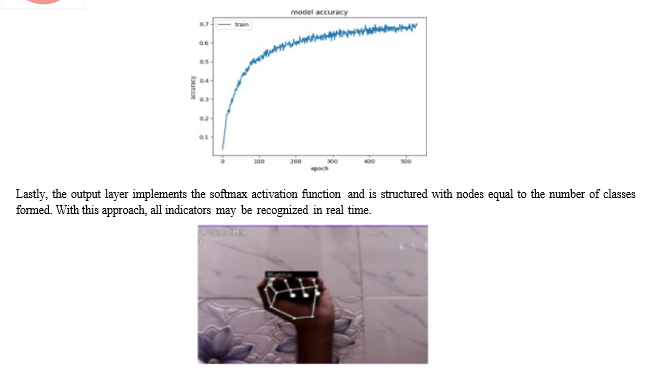
B. Model Accuracy
A measure of accuracy for models shows how many of the model's predictions were successful out of all the forecasts that it produced. While it is a popular statistic when evaluating a model's performance, it does not constitute the only one.
Several layers, including the dropout and dense layers, are used to train the model. Between the last layer that is hidden and the output layer, as well as throughout the first two hidden layers, the dropout technique is used. In addition, the forty percent dropout rate and a weight restrictions are applied to these layers. There are two types of hidden dense layers: the first has 20 nodes and uses the constant activation functioning, while the second has ten nodes and uses the identical technique.

Conclusion
In conclusion, sign language prediction holds immense potential for cultivating inclusivity and availability in communication, bridging crevices for people with hearing disabilities. The improvement of precise and effective sign dialect expectation frameworks has the capacity to enable hard of hearing and hard-of-hearing communities by giving them with a implies to connected consistently with the broader computerized world. The application of progressed innovations, such as machine learning and computer vision, in this space has appeared promising comes about, empowering the acknowledgment and translation of complex sign motions. As these frameworks proceed to advance, they contribute not as it were to encouraging communication but too to advancing a deeper understanding and appreciation of differing languages and societies established in sign. Whereas strides have been made, continuous inquire about and advancement are basic to address the complexity and changeability inalienable in sign dialects, guaranteeing that prescient models can adjust to diverse marking styles and motions. Eventually, the interest of exact sign language expectation isn\'t simply a mechanical challenge but a commitment to building a more comprehensive and even handed society where communication boundaries are decreased for everybody.
References
[1] Sharmila Rathod, Akanksha Shetty, Akshaya Satam, Mihir Rathod,Pooja Shah, Recognition of American Sign Language us- ing Image Processing and Machine Learning, IJCSMC, 2019. [2] Arpita Halder, Akshit Tayade, Real-time Vernacular Sign Lan- guage Recognition using MediaPipe and Machine Learning, IJRPR, 2021. [3] Indriani, Moh.Harris, Ali Suryaperdana Agoes, Applying Hand Gesture Recognition for User Guide Application Using Mediapipe, ISSAT, 2021. [4] Adarsh Vishwakarma, Niraj Yadav, Prajnay Yadav, Vaibhav Singh, Sign Language Recognition Using Mediapipe Framework with Python, IJSRD, 2021. [5] “Mediapipe,”Google,[Online].Available: https://mediapipe.dev/images/mobile/handlandmarks.p ng [6] Murakami K, Taguchi H., Gesture recognition using recurrent neu- ral networks, ACM SIGCHI conference on Human factors in computing systems, 1991. [7] Wang RY, Popovi´c J, Real-time hand-tracking with a color glove, 2009. [8] Rekha J, Bhattacharya J, Majumder S, Hand gesture recognition for sign language: a new hybrid approach., IPCV, 2011. [9] Kurdyumov R, Ho P, Ng J, Sign language classification using we- bcam images., 2011. [10] Tharwat A, Gaber T, Hassanien AE, Shahin MK, Refaat B, Sift- based arabic sign language recognition system., Springer Afro- European conference for industrial advancement, 2015. [11] Baranwal N, Nandi GC, An efficient gesture based humanoid learning using wavelet descriptor and MFCC techniques., Int J Mach Learn Cybern , 2017 [12] Elakkiya R, Selvamani K, Velumadhava Rao R, Kannan A, Fuzzy hand gesture recognition based human computer interface intelli- gent system, UACEE Int J Adv Comput Netw Secur, 2012. [13] Ahmed AA, Aly S, Appearance-based Arabic sign language recog- nition using hidden markov models., IEEE International Con- ference on Engineering and Technology (ICET) , 2014. [14] R. Sharma, R. Khapra, N. Dahiya, Sign Language Gesture Recog- nition, 2020. [15] W. Liu, Y. Fan, Z. Li, Z. Zhang, Rgbd video based human hand tra- jectory tracking and gesture recognition system in Mathematical Problems in Engineering., 2015. [16] Pavlovic, V, Sharma, R., Huang T, Visual Interpretation of Hand Gestures for Human-Computer Interaction (HCI): A Review., IEEE TOPAMI, 1997. [17] Jiyong, M.W., Gao, Jiangqin, Wu Chunli, Wang, A Continuous Chinese sign language recognition system in Automatic Face and Gesture Recognition., Fourth IEEE International Conference of 2000, 2000. [18] Vogler, C.M., Dimitris, Handshapes and Movements: Multiple- Channel American Sign Language Recognition Gesture-Based Communication in Human-Computer Interaction., Springer Berlin Heidelberg, 2004. [19] Gunasekaran, K., Manikandan, R., Sign Language to Speech Translation System Using PIC Microcontroller, International Journal of Engineering and Technology (IJET), 2013. [20] Kalidolda, N., Sandygulova, A., Towards Interpreting Robotic Sys- tem for Finger spelling Recognition in Real-Time ACM/IEEE International Conference on Human-Robot Interaction Companion, 2018. [21] Sunitha K. A, Anitha Saraswathi.P, Aarthi.M, Jayapriya. K, Lingam Sunny, Deaf Mute Communication Interpreter- A Review, International Journal of Applied Engineering Research, 2016. [22] Mathavan Suresh Anand, Nagarajan Mohan Kumar, Angappan Ku- maresan, An Efficient Framework for Indian SignLanguage Recog- nition Using Wavelet Transform Circuits and Systems, 2016.
Copyright
Copyright © 2024 Ujwal Sharma, Om Tiwari, Riddhesh Sankhe, Sneha M Yadav. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET60791
Publish Date : 2024-04-22
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online