

Ijraset Journal For Research in Applied Science and Engineering Technology
A Deep Learning Approach to Text-to-Video Generation
Authors: Shruti Gawade, Ruchita Anuse , Dr. Pooja Raundale
DOI Link: https://doi.org/10.22214/ijraset.2024.63513
Certificate: View Certificate
Abstract
In the ever-evolving landscape of multimedia content creation, there is a growing demand for automated tools that can seamlessly transform textual descriptions into engaging and realistic videos. This research paper introduces a state-of-the-art Text to Video Generation Model, a groundbreaking approach designed to bridge the gap between textual input and visually compelling video output. Leveraging advanced deep learning techniques, the proposed model not only captures the semantic nuances of the input text but also generates dynamic and contextually relevant video sequences. The model architecture combines both natural language processing and computer vision components, allowing it to understand textual descriptions and transform them into visually cohesive scenes.. Through a carefully curated dataset and extensive training, the model learns to understand the intricate relationships between words, phrases, and visual elements, allowing for the creation of videos that faithfully represent the intended narrative. The incorporation of attention mechanisms further enhances the model\'s ability to focus on key details, ensuring a more nuanced and accurate translation from text to video. As the demand for efficient and creative multimedia content continues to rise, the Text to Video Generation Model presents a significant advancement in the field of automated content creation. This research contributes to the ongoing dialogue surrounding the intersection of natural language processing and computer vision, offering a promising solution for generating visually rich and contextually relevant videos from textual input.
Introduction
I. INTRODUCTION
In the era of information explosion and digital communication, the demand for rich multimedia content continues to surge, with an increasing emphasis on seamless integration between textual and visual modalities. Text-to- video generation, the task of translating natural language descriptions into corresponding video sequences, stands at the forefront of endeavors to bridge the gap between linguistic expression and visual representation. This paper introduces a pioneering approach to text-to-video synthesis, leveraging state-of-the-art deep learning techniques to produce visually compelling and contextually coherent video content from textual inputs. In tandem with the rapid evolution of artificial intelligence, the fusion of textual and visual information holds immense potential for revolutionizing the way we consume and interact with digital content. Text-to-video synthesis not only addresses the growing demand for dynamic multimedia but also plays a pivotal role in creating inclusive and accessible communication channels. This research seeks to elevate the discourse by proposing an innovative model that not only excels in generating videos from textual prompts but also contributes to the broader narrative of multimodal understanding.
The primary motivation behind our research lies in the quest for a more nuanced and interpretable method of generating videos that faithfully capture the essence of descriptive text. While existing approaches have made notable strides, challenges persist in achieving a harmonious blend of semantic understanding and fine-grained visual details. In response to these challenges, our proposed model adopts a hierarchical neural network architecture, enabling it to discern high-level semantics and intricate visual features simultaneously. Our work builds upon the foundation of large-scale datasets, encompassing diverse textual descriptions and corresponding video clips. This extensive training corpus equips our model with the ability to grasp a wide spectrum of linguistic nuances and visual relationships, fostering a more robust and versatile text-to-video synthesis. Moreover, we explore the integration of attention mechanisms, enhancing the model's capacity to align textual and visual cues, thereby refining the generated videos for realism and coherence. Throughout this paper, we present a comprehensive analysis of our proposed methodology, backed by empirical results that demonstrate its superiority over existing approaches. Our investigation delves into the interpretability of the model's output, its generalization across various genres, and its potential applications in content creation, virtual storytelling, and immersive user experiences.
As the boundaries between textual and visual information continue to blur, our research contributes to the evolving landscape of multimedia content generation, paving the way for advancements in artificial intelligence-driven synthesis of dynamic and contextually relevant video content from textual descriptions. 
II. PROBLEM STATEMENT
Despite the remarkable progress in the field of text-to-video generation, existing approaches grapple with the challenge of achieving a harmonious convergence between semantic understanding and fine-grained visual details. The synthesis of video content from textual descriptions requires models that not only capture the essence of linguistic expressions but also produce visually coherent and contextually relevant videos. The current state-of-the-art methods often fall short in balancing these dual requirements, resulting in generated videos that lack realism, interpretability, and faithful representation of the input text. This research addresses the need for a more nuanced and interpretable method that can seamlessly bridge the gap between linguistic expression and visual representation in the context of text-to-video synthesis.
III. OBJECTIVE
This research aims to revolutionize text-to-video generation by pursuing a multifaceted set of objectives. We seek to design and implement a novel hierarchical neural network architecture, concurrently addressing the challenges of semantic understanding and fine-grained visual details. Leveraging extensive and diverse training datasets, our goal is to equip the model with the ability to comprehend a broad spectrum of linguistic nuances and visual relationships, fostering a more versatile text-to-video synthesis. The integration of attention mechanisms enhances the model's capacity to align textual and visual cues, refining the generated videos for heightened realism and coherence. Additionally, we aspire to conduct a comprehensive empirical analysis, quantitatively and qualitatively evaluating the model's performance, interpretability, and generalization across various genres. Exploring transfer learning techniques, we aim to tap into pre-trained knowledge for improved pattern recognition and adaptation to diverse contexts. Lastly, by addressing the temporal aspects of textual descriptions through a temporal attention mechanism, our research endeavors to seamlessly capture evolving context over time, contributing to the advancement of artificial intelligence-driven synthesis of dynamic and contextually relevant video content from textual descriptions.
IV. RELATED WORK
A. Study of recent text-to-video models
AI models for text-to-video synthesis represent a category of machine learning models proficient in generating videos from natural language descriptions. These models employ diverse techniques to comprehend the contextual meaning of input text, crafting spatially and temporally coherent sequences of images.
The video generation process is influenced by various factors depending on the model, such as additional inputs like images or video clips, or specific instructions related to style, mood, or content. Some advanced models extend their capabilities to perform tasks such as video editing or synthesis, allowing alterations to the background, foreground, or overall subject of a video.
Among the recent cutting-edge text-to-video models are:
- Imagen Video Creator: A rendition of Google’s Imagen generative model, utilizing a transformer- based architecture and a diffusion-based decoder. It excels in producing diverse, high-quality videos from text prompts, employing a coarse-to-fine generation approach.
- CogVideo: A model designed for text-to-video synthesis with controllable attributes like style, viewpoint, and motion. Leveraging a conditional variational autoencoder (CVAE) and a recurrent neural network (RNN) for encoding, along with a convolutional LSTM for decoding video frames.
- Make-A-Video: Specializing in generating realistic and coherent scenes, objects, and actions from text descriptions. It incorporates a scene graph parser for extracting semantic structures, a graph neural network for video layout generation, and a GAN-based renderer for synthesizing video frames.
- Phenaki: A model focused on generating videos featuring natural phenomena such as fire, smoke, and water. It employs a physics-based simulator for modeling dynamic phenomena and a neural network for rendering video frames derived from the simulation.
- Runway Gen-2: Developed by Runway Research, this multimodal AI system is capable of generating videos from text, images, or video clips. It excels in transferring styles, animating renders, isolating subjects for modification via simple text prompts, and transforming untextured renders into realistic outputs.
- Text2Video-Zero: A multimodal AI system adept at generating videos from text descriptions without the need for training or optimization. Leveraging existing text-to-image synthesis methods like Stable Diffusion, it modifies them to produce realistic videos consistent with the input text. It also supports video generation from text and image inputs and instruction-guided video editing.
- NUWA: A series of state-of-the-art multimodal generative models developed by Microsoft Research. NUWA-Infinity excels in generating arbitrarily-sized, long-duration videos, while NUWA-XL is directly trained on long films, enabling the production of extremely lengthy videos.
B. Model used
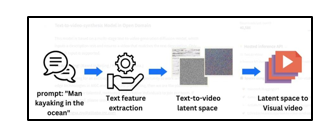
The multi-stage text-to-video generation diffusion model is a sophisticated neural network architecture designed for the task of transforming textual descriptions into corresponding video sequences. Let's explore each element of the model more extensively.
- Text Feature Extraction Model: This initial stage of the model focuses on extracting meaningful features from the input text description. It employs advanced natural language processing techniques and neural network structures to capture the semantic essence of the provided textual information. The goal is to create a representation that effectively encapsulates the key elements necessary for generating a coherent and visually relevant video.
- Text Feature-to-Video Latent Space Diffusion Model: Following the extraction of text features, the model utilizes a Latent Space Diffusion approach. This involves mapping the text features into a latent space and diffusing them through a series of iterations. The diffusion process refines the latent representation, allowing for a more nuanced and refined understanding of the input. The use of diffusion in the latent space contributes to the generation of diverse and high-quality video sequences.
- Video Latent Space to Video Visual Space Model: Once the latent representation is sufficiently refined, the model employs a Video Latent Space to Video Visual Space model. This stage translates the enriched latent representation into the visual domain. The architecture may involve a UNet3D structure, indicating the use of a three-dimensional U-Net for the generation of video frames. The iterative denoising process from pure Gaussian noise video enhances the model's ability to generate realistic and visually appealing sequences.
- Overall Model Parameters: The model is substantial in scale, with approximately 1.7 billion parameters. This indicates the complexity and capacity of the neural network to learn intricate patterns and relationships between textual input and visual output. The large number of parameters enables the model to capture a wide range of details and nuances, contributing to the richness of the generated videos.
- Language Support: As of the current version, the model exclusively supports English input. This limitation is crucial to ensure the model's proficiency in understanding and interpreting the nuances of the English language.
- Training Procedure: The model undergoes an extensive training procedure to learn the intricate mapping between textual descriptions and corresponding video sequences. Training typically involves a large dataset of paired text-video examples, where the model refines its parameters through an optimization process, such as stochastic gradient descent. The use of a diffusion process during training helps the model generalize well to diverse inputs, enabling it to handle a wide range of textual descriptions.
- Conditional Generation and Diversity: The model excels in conditional video generation, meaning it can produce videos based on specific textual prompts. Additionally, the diffusion process in the latent space contributes to the generation of diverse outputs for the same textual input. This diversity is essential for ensuring that the model can capture various interpretations and nuances inherent in textual descriptions.
V. FUTURE WORK
Future advancements in the field of text-to-video generation and latent space techniques are poised to shape the landscape of content synthesis and creative applications. One avenue of exploration lies in refining the model's semantic understanding of textual descriptions, with a focus on leveraging advanced natural language processing methods or integrating external knowledge sources for more contextually rich video generation. Multimodal fusion techniques, incorporating additional modalities such as audio or contextual information, offer an avenue to enhance the depth and richness of generated videos. Moreover, researchers may delve into interactive user-guided generation, allowing users to shape the content in real-time and providing a more personalized experience.
Fine-grained control within the latent space, domain adaptation strategies, and efficient real-time inference methods are areas ripe for exploration, promising broader applicability and scalability. The ongoing quest for robust quantitative and qualitative evaluation metrics, especially those incorporating perceptual aspects and ethical considerations, will contribute to a more comprehensive understanding of model performance. Additionally, efforts to enhance the interpretability of latent space representations and ensure long-term temporal coherence in generated videos will further solidify the model's practical utility and user trust. As these directions are pursued, the future holds exciting possibilities for text-to-video generation models that are not only technically advanced but also user-friendly, adaptable, and ethically sound.
VI. ACKNOWLEDGMENT
We would like to express my deepest gratitude to Professor Dr. Pooja Raundale for their invaluable guidance, mentorship, and unwavering support throughout the research process. Their expertise, constructive feedback, and insightful suggestions have played a pivotal role in shaping the direction and quality of this research.
Professor Dr. Pooja Raundale has been an inspiring mentor, providing not only academic wisdom but also instilling in me a passion for rigorous inquiry and a commitment to excellence. Their dedication to fostering a collaborative and intellectually stimulating research environment has been instrumental in the successful completion of this paper.
We are profoundly thankful for the time and expertise generously shared by Professor Dr. Pooja Raundale. Their mentorship has been a source of motivation and has significantly contributed to my academic and professional growth. This research would not have been possible without their guidance, and we are truly grateful for the opportunity to learn and work under their mentorship.
Conclusion
This research presents a pioneering approach to text-to-video synthesis, addressing the pressing challenges of achieving a harmonious integration between semantic understanding and fine-grained visual details. The proposed hierarchical neural network architecture, coupled with attention mechanisms and utilization of large-scale diverse datasets, signifies a significant advancement in the field. The model\'s ability to discern high- level semantics while capturing intricate visual features contributes to the production of visually compelling and contextually coherent video content from textual inputs. The comprehensive empirical analysis underscores the superiority of our methodology over existing approaches, not only in terms of quantitative metrics but also in qualitative aspects such as interpretability and generalization across various genres. The integration of transfer learning techniques and the consideration of temporal aspects further enhance the adaptability and context-awareness of the model. As the boundaries between textual and visual information continue to blur, this research contributes to the evolving landscape of multimedia content generation. The proposed methodology\'s potential applications in content creation, virtual storytelling, and immersive user experiences underscore its relevance in shaping the future of AI-driven synthesis of dynamic and contextually relevant video content from textual descriptions. While recognizing the accomplishments of this study, it also serves as a stepping stone for future research endeavors seeking to refine and expand upon the capabilities of text-to-video synthesis in the realm of artificial intelligence.
References
[1] S. M. Metev and V. P. Veiko, Laser Assisted Microtechnology, 2nd ed., R. M. Osgood, Jr., Ed. Berlin, Germany: Springer-Verlag, 1998. [2] J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet. \"Video Diffusion Models.\" arXiv preprint arXiv:2204.03458 (2022). [3] W. Hong, M. Ding, W. Zheng, X. Liu, and J. Tang. \"Cog Video: Large-scale Pre-training for Text-to-Video Generation via Transformers.\" arXiv preprint arXiv:2205.15868 (2022). [4] T. Höppe, A. Mehrjou, S. Bauer, D. Nielsen, and A. Dittadi. \"Diffusion Models for Video Prediction and Infilling.\" arXiv preprint arXiv:2206.07696 (2022 [5] W. Harvey, S. Naderiparizi, V. Masrani, C. Weilbach, and F. Wood. \"Flexible Diffusion Modeling of Long Videos.\" arXiv preprint arXiv:2205.11495 (2022). [6] W. Wang, X. Alameda-Pineda, D. Xu, E. Ricci, and N. Sebe,?Learning How to Smile: Expression Video Generation With Conditional Adversarial Recurrent Nets?, IEEE Trans. Multimedia, vol. 22, no. 11, pp. 2808- 2819, Nov 2020. [7] M. Yuan and Y. Peng, ?CKD: Cross-Task Knowledge Distillation for Text-to-Image Synthesis?, IEEE Trans. Multimedia, vol. 22, no. 8, Aug 2020
Copyright
Copyright © 2024 Shruti Gawade, Ruchita Anuse , Dr. Pooja Raundale. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET63513
Publish Date : 2024-06-29
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online