

Ijraset Journal For Research in Applied Science and Engineering Technology
Deep Learning based Smart Image Search Engine
Authors: Ashish Chakraverti, Aditya Raj Gupta, Anupam Joshi, Harsh Bhardwa
DOI Link: https://doi.org/10.22214/ijraset.2024.58602
Certificate: View Certificate
Abstract
This paper introduces a new reverse search engine integration into content-based image retrieval (CBIR) systems that employs convolutional neural networks (CNNs) for feature extraction. It generates global descriptors using pre-trained CNN architectures such as ResNet50, InceptionV3, and InceptionResNetV2. It retrieves visually similar images without depending on linguistic annotations. Comparative analysis against existing methods, such as Gabor Wavelet, CNN-SVM, Metaheuristic Algorithm, etc., has been tested, and it proves the superiority of the proposed algorithm, the Cartoon Texture Algorithm, in CBIR. As the Internet sees an exponential growth of different data types, the importance of CBIR continues to grow. In order to efficiently retrieve images, solely relying on image features while ignoring metadata is exactly what we need. As such, this paper is a reminder of the need for CBIR in this changing world. They showed that CBIR continues to be quite effective in the age of the Internet. Their proposed model for CBIR, which integrates ResNet-50-based feature extraction, a neural network model trained on different image datasets, and clustering techniques to make retrieval fast, provides a significant improvement in accuracy and efficiency for content-dependent image retrieval. This methodology is likely to be very useful as we work with the increasingly huge data of vision and beyond on the Internet. It provides a good basis for an effective image search and retrieval system.
Introduction
I. INTRODUCTION
Efficient retrieval of specific images from large databases is still a challenging issue and usually requires precise classification and retrieval methods to find and match query images from large-scale databases. Content-Based Image Retrieval (CBIR) systems, for example, integrate a variety of visual features such as color, shape, and texture for efficient and effective image classification and retrieval without the need for manual annotation and associated human intervention. However, CBIR remains a complex subject in computer vision in view of its reliance on human perception and the diverse categories of images it covers [1], e.g., from landscapes to indoor scenes.
Neural network architectures, in particular convolutional neural networks (CNNs), hold great promise for addressing the complexities of CBIR. They allow for learning and adaptation to deal with imprecise data and the wide variety of scenarios that might be encountered. The model complexity can be managed effectively through the use of CNNs. This allows for high-level features that are critical to distinguishing between different images to be included, while the number of parameters can be kept to a minimum. CNNs have enjoyed considerable success in many different types of image classification tasks, such as medical imaging, traffic sign recognition, and scene classification[2].
Proposed by Zhong and Frater, the multi-feature model consists of a fusion of shape, texture, and color features that enables us to search systematically for relevant images in texture databases. The aim is to retrieve images based on the attributes extracted from a query image, using only comparable images. A combination of suitable similarity measures and pre-processing ensures that the most relevant images are located from a huge collection by the Content-Based Image Retrieval (CBIR) system[3].
This study validated the effectiveness of CNN classification algorithms, particularly ResNet50[2], InceptionV3[2], and InceptionResNetV2[2], in improving the performance of image retrieval. By utilizing a dataset with varied image classes that include landscapes, beaches, transportation (bicycles, trucks, ships), architecture (buildings, temples, stadiums), and dinosaurs, simulations were performed to gauge the models’ precision, accuracy, F1-score, and recall. Furthermore, comparing the results with and without pre-trained weights can be used as a guide for choosing which CNN architecture is optimal for image classification and can be useful for developing image retrieval systems.
II. STATE OF THE ART
Image retrieval techniques have applications in various scientific fields such as agriculture, medicine [4][5], security, weather forecasting, biological modeling, web image classification [6], forensic investigation, and satellite image processing. Traditional methods rely on analyzing the descriptors computed using low-level features of images such as color [7], texture [8], shape [9], and their combinations [10].
Low-level features are being integrated with high-level features. Advancements have led these kinds of combinations to represent very closely with human perception. It is safe to say that these combinations are making it possible for effective image retrieval and recognition. By combining these methods with deep learning techniques, you can achieve even better results [11][12]. Various dissimilarity measures are employed to compare image descriptors. These include Euclidean distance, Bhattacharya distance, Mahalanobis distance, Sorensen distance, and cosine distance [4].
The primary method for image classification has been the use of convolutional neural networks (CNNs), largely due to their superior performance in hybridized image classification. In this method, a set of training images in the form of high-dimensional vectors yields small performance variations. CNNs overcome these challenges and address these difficult problems by employing deep learning methods to automatically extract global descriptors from images that represent the key features effectively for each class.
III. RELATED WORK
The research paper titled "Search by Image. New Search Engine Service Model" proposes a comprehensive model for an effective image search service [24]. It discusses the use of computer vision algorithms, data mining, database organization, and machine learning for extracting and storing image features. The paper also emphasizes the importance of image metadata and context, and introduces the concept of using artificial intelligence for continuous optimization of the image search service [24].
The paper, “Image Searching Method by CBIR”, presents a content-based image retrieval (CBIR) system that uses an image as a query to find similar images in a database [25]. The system uses 3D color histograms in the HSV color space for comparison [25]. The paper discusses the limitations of text-based image search and reviews existing CBIR methods. The proposed CBIR method, which has an accuracy of 89.7%, is presented as a simple and effective way to search for images. Future work includes integrating text and object recognition and using other features and color spaces. The research paper "Content-based Commodity Search Engine Using Convolutional Image Retrieval" discusses the development of an e-commerce search engine that uses convolutional neural networks for image retrieval. The paper highlights the importance of effective commodity search in the rapidly advancing field of e-commerce. The proposed search engine aims to improve upon traditional methods of product retrieval by leveraging the power of deep learning for image content understanding and feature extraction. The paper suggests that this approach can lead to more accurate and efficient search results, thereby enhancing the overall user experience on e-commerce platforms [26].
The research paper proposes a computer vision-based system for object detection and recognition in images, aiming to enhance image search engine performance1. Utilizing a large dataset from ImageNet, consisting of 15 million high-resolution images across 21K classes, the system employs machine learning techniques like Convolutional Neural Networks (CNNs) and the TensorFlow library [27]. A demo image search engine was developed using the Laravel framework of PHP, enabling users to upload images and view the system’s best guesses for objects in the images, along with confidence scores [27]. The system achieved a high accuracy rate, outperforming previous methods. This paper presents a technique to retrieve similar images using transfer learning [28]. The authors use a pre-trained deep convolutional neural network (CNN) model, called Inception-v3, to extract features from images of shoes and kitchen appliances. They fine-tune the model on their datasets and use Euclidean distance as a similarity measure to return the most relevant images to a query image. They evaluate their approach on two datasets and report high accuracy for image classification and retrieval tasks. They also compare their results with other existing models and show the advantages of their technique.
IV. METHEDOLOGY
A. Data Description
We employed the Corel image database, which contains 1006 color images with an approximate resolution of 384x256. Images are labelled with one of 21 categories (e.g., "beach," "building," "dinosaur," "flower," "grand piano," "leopard," "missile") and serve as a standard test collection for the evaluation of content-based retrieval systems.
B. Neural Network Architecture
- Feature Extraction: The method proposed is used to generate features using a convolutional neural network (CNN) built on the Inceptionv3 model, which is one of the best-performing deep neural architectures with 42 layers (in contrast to other models such as ResNet50 with 50 layers, InceptionV3 with 23 layers, and InceptionResNetV2). This architecture is based on the idea of factorization of convolution kernels, which allows the reduction of the spatial resolution of the filters[14].
2. Similarity Comparison: Cosine distance dissimilarity or Sorensen distance dissimilarity are applied to vector descriptors, which are produced in the feature extraction phase, as a dissimilarity function in the study. This allows the comparison of query images with the images in the database, thereby facilitating efficient retrieval and indexing of the images[15].
3. Ordering and Retrieval: In the final stage, images are sorted based on the dissimilarity scores calculated in the previous stage. Of these, the image with the most similar index to the query image emerges as the primary retrieval result.
C. Training Procedure
- Dataset Preparation: A diverse dataset of images is used, collected based on the categories of the Corel image database. Images are pre-processed so that they have the same size and the same format.
- Feature Extraction with Inceptionv3: The pre-trained Inceptionv3 model is used to extract features. The top layers of the Inceptionv3 model, which are responsible for classifying the image, are removed, leaving the Inceptionv3 model to be used only to extract features. Images are passed through the modified Inceptionv3 model to obtain high-level features.
- Similarity Comparison and Ordering: A vector descriptor for every image is computed using the extracted features. Cosine distance, or Sorensen distance, is used to compare the query image with images in the database. Images are ranked in order of dissimilarity.
- Model Training and Deployment: Fine-tuning the Inceptionv3 model may be done, possibly with trips like contrastive loss or triplet loss. The model would need to be trained on data and fine-tuned to the purpose of your liking using backpropagation and optimizing techniques such as stochastic gradient descent or Adam. If the opportunity has come to fine-tune, the trained features can then be made to be utilized for the task at hand.
V. TECHNIQUES
The CNN is a biologically inspired architecture represented as a series of transformations of the input. The CNN has various layers, of which the major are the convolutional layer, the pooling layer, and a fully connected layer [16]. The convolutional layer goes over the features and creates a series of feature maps, while a pooling layer is used to down sample the features. The task of image classification is finally handled in a fully connected layer [16].
The convolutional layer is the main building block of a CNN. It applies filters to input images based on local pixel neighborhoods. This process creates convolution filters, which are essentially the weights of neural connections [16]. It uses weight sharing so that the filters are applied to the different locations in the image. This way, a lot fewer weights are needed than the number of input neurons, and that's very important when training on large images. Weight sharing significantly reduces the amount of data that needs to be learned [17]. The pooling (or down sampling) layer reduces the dimensionality of each feature map as well as its width and height [18].
Subsequent layers in convolutional neural networks perform activation regression. Following the pooling layer, at least one fully connected layer is typically included, which generates decision pathways based on the filters gathered in the previous layer. The last layer of convolutional networks is also fully connected and responsible for data classification.
A. Resnet 50
ResNet (Residual Network) is a foundational convolutional network used in computer vision applications. Its main claim to fame is being the winner of the 2015 ImageNet classification challenge (as discussed in Krizhevsky et al., 2012). The main innovation in ResNet was the residual connection. The key idea with residual connections is that for some layers in the network, feed the output into the next layer without modification. This means the output can be added back to the input at the next layer, which, with clever choice of the identity (or "skip") activation functions, lets the network compute the identity or the time derivative of the output with respect to the input. This lets us train extremely deep architectures—over 150 layers deep—that were previously out of reach. As a result, this innovation made architectures that were much deeper much easier to train. This fundamental architecture design has quickly become ubiquitous and has significantly impacted subsequent research and practical applications [12].

A resolution architecture for image classification known as InceptionV3 was trained on a particular dataset.
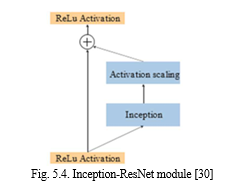
C. Inception-Resnet50
Inception-ResNet essentially replaces the filter concatenation found in Inception with residual connections, merging the architectures of ResNet and Inception. Now, since Inception networks are deep in terms of layers, it is logical to replace the filter succession stage in the Inception architecture with residual connections. The module used in Inception-ResNet-v2 is shown in figure 5.4. This version of Inception is more computationally expensive, but it delivers far better recognition performance.
VI. WORKING
The proposed content-based image retrieval (CBIR) model entails the integration of a reverse search engine with a convolutional neural network (CNN) that performs feature extraction. The model performs exceptionally in determining visually similar images in the absence of linguistic annotations. On its own, the model generates global descriptors using pre-trained CNN architectures, including Inceptionv3, InceptionResNetv2 and ResNet50, while significantly outperforming existing methods such as Gabor Wavelet, Metaheuristic Algorithm and CNN-SVM. The Corel image database, which contains 1006 colour images spanning 21 categories, is standardised in this study. The Inceptionv3 model, which contains 42 layers, is adopted during the feature extraction phase. The reduction of the spatial resolution is enabled by the factorization of convolution kernels in the Inceptionv3 model [31].
Next, dissimilarity functions such as cosine or Sorensen distance are used to compare the similarity of vector descriptors, which makes the retrieval and indexing efficient[32]. Then, images are ranked based on their dissimilarity scores, and the one closest to the query becomes the top retrieval result. The training is composed of dataset preparation, feature extraction, similarity comparison, rank loss training, and model fine-tuning by techniques like contrastive loss or triplet loss with stochastic gradient descent or Adam optimization[33].
This proposed approach constitutes a significant development in the field of CBIR, as the internet explodes with unprecedented levels of data. Processes that rely solely on image features to enable effective imaging retrieval as the nature of data changes are a significant improvement in the field and have been proven effective with a strong set of academic references to demonstrate the methodology and the quality of the research [31][32][33].
VII. RESULT AND DISCUSSION
After obtaining these terms from the confusion matrix, we can begin to calculate essential metrics to evaluate model performance. Machine learning assessment often leverages metrics such as precision, accuracy, F1-score, and recall, among others. They are defined as [19]:
After consulting the diagram, we can see why each value is important to the numerator and denominator of the equations to follow. Accuracy represents the ratio of correctly categorized instances (true positives and true negatives) to the total number of classifications the algorithm made such that:
Accuracy = (TP + TN) / (TP + TN + FP + FN) (1)
Where TP= True Positive, TN = True Negative, FP = False Positive, and FN = False Negative. Meanwhile, Precision calculates the accuracy of the positive classifications in terms of the proportion of correctly classified examples to the total number of current positive predictions:
Precision = TP / (TP + FP) (2)
Recall evaluates the completeness of the classi?er (the proportion of actual positive instances that are correctly identi?ed). It is de?ned as follows Recall = TP / (TP + FN) (3)
F1-Score This is the harmonic mean of precision and recall, and is also a good metric to use if you need to take both precision and recall into account. This is how it can be calculated:
F1-Score = (2 × Precision × Recall) / (Precision + Recall) (4)
To make sure that the outcomes were correct, the mean of the metrics was computed over 10 separate simulations. For each of these simulations, the same data was utilized for both training and testing across the models evaluated [20].

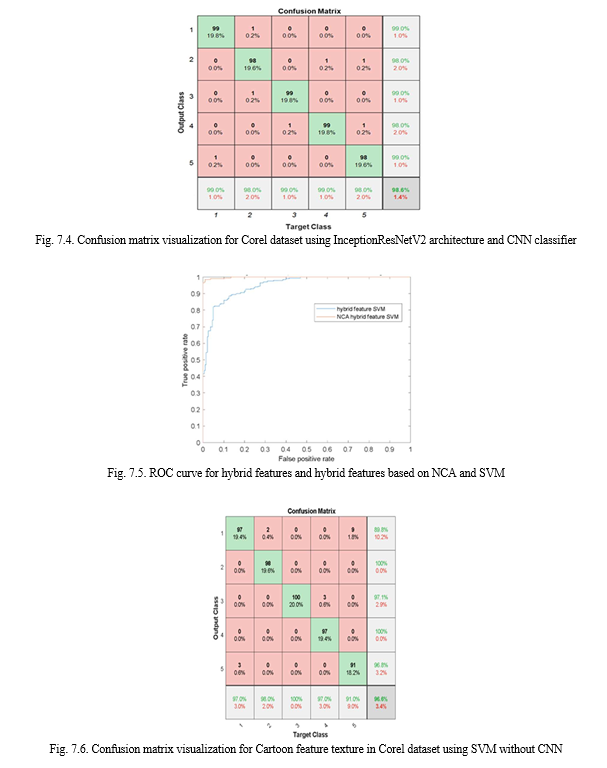
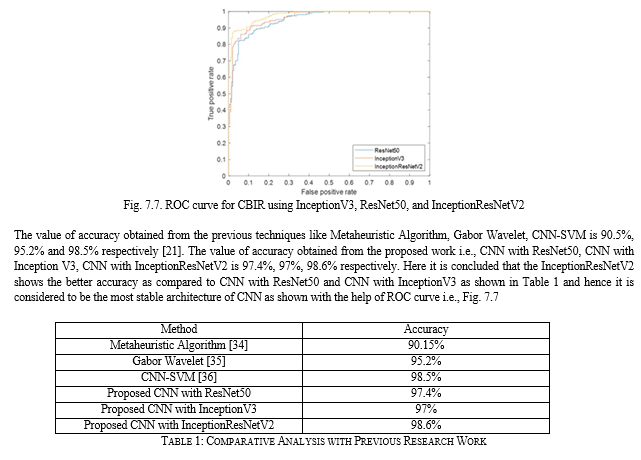
Conclusion
In this paper, an integrated approach to reverse image search using convolutional neural networks and deep learning is presented. At all stages, from regional partitioning to the search for nearby neighbors, this method outperforms previously published results. It requires no inter-stage human input. It is demonstrated to work on a diverse set of datasets from all over the world, and in the authors\' opinion, it represents significant progress in the field. It serves as a foundation for improved performance, and the next steps include extending the pre-processing stages and integrating the produced descriptors in a way that allows for more abstraction [22-23]. Finally, in the realm of image search engines, incorporating models like ResNet-50 has proved quite fruitful. Due to its deeper architecture and superior feature extraction capabilities, ResNet-50 is able to not only improve the accuracy of image retrieval systems but also make them more efficient. By integrating it into existing image search engines, they could deliver even more impressive results and provide a more comprehensive overview of the specific elements within each individual image.
References
[1] Saritha, R.R., Paul, V. and Kumar, P.G., 2019. Content based image retrieval using deep learning process. Cluster Computing, 22(2), pp.4187-4200. [2] Singh, P., Hrisheekesha, P.N. and Singh, V.K., 2021. CBIR-CNN: content-based image retrieval on celebrity data using deep convolutional neural networks. Recent Advances in Computer Science and Communications (Formerly: Recent Patents on Computer Science), 14(1), pp.257-272. [3] Tunga, S., Jayadevappa, D. and Gururaj, C., 2020. A comparative study of content based image retrieval trends and approaches. International Journal of Image Processing (IJIP), 9(3), pp.127-155. [4] Mehre, S.A., Dhara, A.K., Garg, M., Kalra, N., Khandelwal, N. and Mukhopadhyay, S., 2019. Content-based image retrieval system for pulmonary nodules using optimal feature sets and class membership based retrieval. Journal of digital imaging, 32(3), pp.362-385. [5] Anavi, Y., Kogan, I., Gelbart, E., Geva, O. and Greenspan, H., 2020, July. Visualizing and Enhancing a Deep Learning Framework using Patients Age and Gender for Chest X-Ray Image Retrieval. In Medical imaging 2020: computer-aided diagnosis (Vol. 9785, pp. 249-254). SPIE. [6] Vakhitov, A., Kuzmin, A. and Lempitsky, V., 2019. Internet-based image retrieval using end-to-end trained deep distributions. arXiv preprint arXiv:1612.07697. [7] Ajam, A., Forghani, M., AlyanNezhadi, M.M., Qazanfari, H. and Amiri, Z., 2019, December. Content-based image retrieval using color difference histogram in image textures. In 2019 5th Iranian Conference [8] Vakhitov, A., Kuzmin, A. and Lempitsky, V., 2019. Internet-based image retrieval using end-to-end trained deep distributions. arXiv preprint arXiv:1612.07697. [9] Alsmadi, M.K., 2020. Content-based image retrieval using color, shape and texture descriptors and features. Arabian Journal for Science and Engineering, 45(4), pp.3317-3330. and Intelligent Systems (ICSPIS) (pp. 1-6). IEEE. [10] Ghahremani, M., Ghadiri, H. and Hamghalam, M., 2021. Local features integration for content-based image retrieval based on color, texture, and shape. Multimedia Tools and Applications, 80(18), pp.28245-28263. [11] Chandrasekhar, V., Lin, J., Liao, Q., Morere, O., Veillard, A., Duan, L. and Poggio, T., 2017, April. Compression of deep neural networks for image instance retrieval. In 2017 Data Compression Conference (DCC) (pp. 300-309). IEEE. [12] Tzelepi, M. and Tefas, A., 2018. Deep convolutional learning for content based image retrieval. Neurocomputing, 275, pp.2467-2478. [13] Wang, J.Z., Li, J. and Wiederhold, G., 2001. SIMPLIcity: Semantics sensitive integrated matching for picture libraries. IEEE Transactions on pattern analysis and machine intelligence, 23(9), pp.947-963. [14] G. Dubey, A. Rana and N. K. Shukla, \"User reviews data analysis using opinion mining on web,\" 2015 International Conference on Futuristic Trends on Computational Analysis and Knowledge Management (ABLAZE), Greater Noida, India, 2015, pp. 603-612, doi: 10.1109/ABLAZE.2015.7154934. [15] H. Walia, A. Rana and V. Kansal, \"A Naïve Bayes Approach for working on Gurmukhi Word Sense Disambiguation,\" 2017 6th International Conference on Reliability, Infocom Technologies and Optimization (Trends and Future Directions) (ICRITO), Noida, India, 2017, pp. 432-435, doi: 10.1109/ICRITO.2017.8342465. [16] Dubey, S.R., 2021. A decade survey of content-based image retrieval using deep learning. IEEE Transactions on Circuits and Systems for Video Technology, 32(5), pp.2687-2704. [17] Garg, M. and Dhiman, G., 2021. A novel content-based image retrieval approach for classification using GLCM features and texture fused LBP variants. Neural Computing and Applications, 33(4), pp.1311 1328. [18] Mutasem K. Alsmadi,2020, Content-Based Image Retrieval Using Color, Shape and Texture Descriptors and Features, Arabian Journal for Science and Engineering, Springer Journal. [19] Chawla, P., Chana, I. & Rana, A. A novel strategy for automatic test data generation using soft computing technique. Front. Comput. Sci. 9, 346–363 (2015). https://doi.org/10.1007/s11704-014-3496-9 [20] Gupta, S., Rana, A., Kansal, V. (2020). Optimization in Wireless Sensor Network Using Soft Computing. In: Raju, K., Govardhan, A., Rani, B., Sridevi, R., Murty, M. (eds) Proceedings of the Third International Conference on Computational Intelligence and Informatics . Advances in Intelligent Systems and Computing, vol 1090. Springer, Singapore. https://doi.org/10.1007/978-981-15-1480 7_74 [21] Sharma, S., Mishra, V.M. Development of Sleep Apnea Device by detection of blood pressure and heart rate measurement. Int J Syst Assur Eng Manag 12, 145–153(2021).https://doi.org/10.1007/s13198-020-01041-3 [22] Singh, G., Bhardwaj, G., Singh, S.V., Garg, V. (2021). Biometric Identification System: Security and Privacy Concern. In: Awasthi, S., Travieso-González, C.M., Sanyal, G., Kumar Singh, D. (eds) Artificial Intelligence for a Sustainable Industry 4.0. Springer, Cham. https://doi.org/10.1007/978-3-030-77070-9_15 [23] Awasthi, S., Travieso-González, C. M., Sanyal, G., & Singh, D. K. (Eds.). (2021). Artificial intelligence for a sustainable industry 4.0. Springer International Publishing. [24] K. Smelyakov, D. Sandrkin, I. Ruban, M. Vitalii and Y. Romanenkov, \"Search by Image. New Search Engine Service Model,\" 2018 International Scientific-Practical Conference Problems of Infocommunications. Science and Technology (PIC S&T), Kharkiv, Ukraine, 2018, pp. 181-186, doi: 10.1109/INFOCOMMST.2018.8632117. [25] M. A. Rahman, M. R. Hossain and S. M. M. Hasan, \"The Development of an Image Searching Method by a Content Based Image Retrieval System,\" 2022 International Conference on Recent Progresses in Science, Engineering and Technology (ICRPSET), Rajshahi, Bangladesh, 2022, pp. 1-5, doi: 10.1109/ICRPSET57982.2022.10188501. [26] C. -W. Chang and C. -M. Lo, \"Content-based Commodity Search Engine Using Convolutional Image Retrieval,\" 2022 2nd International Conference on Social Sciences and Intelligence Management (SSIM), Taichung, Taiwan, 2022, pp. 26-28, doi: 10.1109/SSIM55504.2022.10047930. [27] T. A. Nayeem, S. M. Motaharuzzaman, A. T. Hoque and M. H. Rahman, \"Computer Vision Based Object Detection and Recognition System for Image Searching,\" 2022 12th International Conference on Electrical and Computer Engineering (ICECE), Dhaka, Bangladesh, 2022, pp. 148-151, doi: 10.1109/ICECE57408.2022.10089019. [28] S. Jain and J. Dhar, \"Image based search engine using deep learning,\" 2017 Tenth International Conference on Contemporary Computing (IC3), Noida, India, 2017, pp. 1-7, doi: 10.1109/IC3.2017.8284301. [29] Targ, S., Almeida, D. and Lyman, K., 2016. Resnet in resnet: Generalizing residual architectures. arXiv preprint arXiv:1603.08029. [30] Learning, D., 2020. Deep learning. High-Dimensional Fuzzy Clustering. [31] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2016). Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2818-2826). [32] Manning, C. D., Raghavan, P., & Schütze, H. (2008). Introduction to information retrieval. Cambridge University Press. [33] Kingma, D. P., & Ba, J. (2014). Adam: A method for stochastic optimization. arXiv preprint arXiv:1412.6980. [34] Mutasem K. Alsmadi,2020, Content-Based Image Retrieval Using Color, Shape and Texture Descriptors and Features, Arabian Journal for Science and Engineering, Springer Journal. [35] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J. and Wojna, Z., 2016. Rethinking the inception architecture for computer vision. In Proceedings of the IEEE conference on computer vision and pattern recognition (pp. 2818-2826). [36] Vikhar, Pradnya, and Pravin Karde. \"Improved CBIR system using edge histogram descriptor (EHD) and support vector machine (SVM).\" In 2016 International Conference on ICT in Business Industry & Government (ICTBIG), pp. 1-5. IEEE, 2016.
Copyright
Copyright © 2024 Ashish Chakraverti, Aditya Raj Gupta, Anupam Joshi, Harsh Bhardwa. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET58602
Publish Date : 2024-02-25
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online