

Ijraset Journal For Research in Applied Science and Engineering Technology
Detection of Diabetic Retinopathy Using Deep Learning
Authors: Prof. Bhavya M R, Anush M, Gagan Raj, H Gowtham, Yashwanth U
DOI Link: https://doi.org/10.22214/ijraset.2022.45597
Certificate: View Certificate
Abstract
Diabetic retinopathy is one of the most dangerous complications of diabetes, leading to permanent blindness if left untreated. One of the major challenges is early detection, which is very important for the success of treatment. Unfortunately, accurate identification of the stage of diabetic retinopathy is notoriously tricky and requires expert human interpretation of fundus images. Simplifying the detection step is essential and can help millions of people. Convolutional Neural Networks (CNNs) have been successfully used in many neighboring subjects and for the diagnosis of diabetic retinopathy itself. However, the high cost of large annotated datasets as well as inconsistencies between different clinicians hinders the implementation of these methods. In this paper, we propose an automatic method based on deep learning to detect the stage of diabetic retinopathy using a single human fundus image. In addition, we propose a multi-stage transfer learning approach that uses similar datasets with different labels. The presented method can be used as a screening method for the early detection of diabetic retinopathy with a sensitivity and specificity of 0.99 and is ranked 54 out of 2943 competing methods (quadratic weighted kappa score 0.925466) on the APTOS 2019 Blindness Detection Dataset (13,000 images).
Introduction
I. INTRODUCTION
Diabetic retinopathy (DR) is a fast-spreading disease across the globe, which is caused by diabetes. The DR may lead the diabetic patients to complete vision loss. In this scenario, early identification of DR is more essential to recover the eyesight and provide help for timely treatment. The detection of DR can be manually performed by ophthalmologists and can also be done by an automated system. In the manual system, analysis and explanation of retinal fundus images need ophthalmologists, which is a time-consuming and very expensive task, but in the automated system, artificial intelligence is used to perform an imperative role in the area of ophthalmology and specifically in the early detection of diabetic retinopathy over the traditional detection approaches. Recently, numerous advanced studies related to the identification of DR have been reported.
II. RELATED WORK
[1]From this paper we actually come to know what actually Diabetic Retinopathy is and the main cause of it is damaged of blood vessel which leads to blindness [2]. This paper mainly focuses on classifying the disease into different stages the stages are No Diabetic Retinopathy, Mild Diabetic Retinopathy, Moderate Diabetic Retinopathy, high Diabetic Retinopathy, Severe Diabetic Retinopathy to classify this methods used like Vgg 16, Vgg 19 which leads to build Deep Learning model. According to this Vgg model the Diabetic Retinopathy model scale it and makes the classification and according to the study this method has more accuracy compared to other models. [3] From this paper we got to know how basically segmentation of blood vessels can be done from fundus images. Here they have used Gaussian mixture model and also pixel based classification is used and we got to know that the algorithm is less dependent on training data so segmentation time could be less.[6] From this paper, we came to know the present systematic automated approaches to diabetic eye disease detection from several aspects. This survey provides a comprehensive synopsis of diabetic eye disease detection approaches. In this paper, they have used deep learning methodology and initially a keyword search was conducted using ten academic databases considering our specific review target. Seven filters were applied to select the primary review target [4, 5]. From this paper our main objective is to detect neovascularization in optic disc region (NVD) for color fundus retinal image. They have used support vector machine methodology for the detection. The author proposes an automatic image processing procedure for NVD detection, which includes feature extraction, feature selection and machine learning classification. The proposed algorithm achieves high sensitivity on both training set and test set. The future work of this research will expand to neovascularization elsewhere (NVE) detection [5].
In this paper deep convolution neural network (CNN) is adapted to achieve pixel-wise exudate identification. In order to achieve pixel-level accuracy meanwhile to reduce computing time, potential exudate points are first extracted with opening algorithm.
The methodology used to achieve this task is deep learning. The method achieves a high pixel-wise accuracy for training set and test set. The future work of this research can involve testing methods on more publicly available databases. [6] The proposed method in this paper employs structured learning to capture the optic disk edge information because the proposed algorithm belongs to supervised methods the trained edge detection plays an important role in performance of the proposed system. In this paper a novel method for the improvement in the detection of micro aneurysms in funds images has been proposed. On screening it detects the small red dots on the retinal funds images to give earliest possible sign of the diseases. The proposed algorithm consists of two stages. The first stage is comprised of image preprocessing and fractal analysis of retinal structure. The second stage aims at detection of a typical shape of micro aneurysms as the abnormal retinal image goes through canny edge detection and morphological reconstruction. The implemented algorithm has achieved a best operating sensitivity and a specificity which makes it feasible for diabetic retinopathy screening. [8] The paper indicates that hemorrhages are detected methods are at good accuracy &fast in execution of retinal image. There is a wide scope for future expansion of this algorithm by classifying Diabetic Retinopathy images into mild, severe and moderate by obtaining features from extracted hemorrhages.
III. METHODOLOGIES

A. Collection Datasets
- We are going to collect datasets for the prediction from the kaggle.com
- The data sets consists of 5 Classes
B. Data Pre Processing
- In data pre-processing we are going to perform some image pre-processing techniques on the selected data
- Image Resize
- And Splitting data into train and test
C. Data Modelling
- The splitted train data are passed as input to the CNN algorithm, which helps in training.
- The trained chest x ray data evaluated by passing test data to the algorithm
- Accuracy is calculated
D. Build Model
- Once the data is trained and if it showing the accuracy rate as high, then we need to build model file
IV. MODELING AND ANALYSIS
A. CNN
- Convolutional Neural Networks have the following layers
a. Step 1: Convolution Layer: Convolutional neural networks apply a filter to an input to create a feature map that summarizes the presence of detected features in the input.
b. Step 2: ReLU Layer: In this layer, we remove every negative value from the filtered images and replaces them with zeros.It is happening to avoid the values from adding up to zero. Rectified Linear unit (ReLU) transform functions only activates a node if the input is above a certain quantity. While the data is below zero, the output is zero, but when the information rises above a threshold. It has a linear relationship with the dependent variable.
???????c. Step 3: Pooling Layer: In the layer, we shrink the image stack into a smaller size. Pooling is done after passing by the activation layer. We do by implementing the following 4 steps:
- Pick a window size (often 2 or 3)
- Pick a stride (usually 2)
- Walk your Window across your filtered images
- From each Window, take
a. Step 4: Fully Connected Layer: The last layer in the network is fully connected, meaning that neurons of preceding layers are connected to every neuron in subsequent layers. This mimics high-level reasoning where all possible pathways from the input to output are considered. Then, take the shrunk image and put into the single list, so we have got after passing through two layers of convolution relu and pooling and then converting it into a single file or a vector.

a. Step 1: Convolution Layer: Convolutional neural networks apply a filter to an input to create a feature map that summarizes the presence of detected features in the input.
b. Step 2: ReLU Layer: In this layer, we remove every negative value from the filtered images and replaces them with zeros.It is happening to avoid the values from adding up to zero. Rectified Linear unit (ReLU) transform functions only activates a node if the input is above a certain quantity. While the data is below zero, the output is zero, but when the information rises above a threshold. It has a linear relationship with the dependent variable.
c. Step 3: Pooling Layer: In the layer, we shrink the image stack into a smaller size. Pooling is done after passing by the activation layer. We do by implementing the following 4 steps:
- Pick a window size (often 2 or 3)
- Pick a stride (usually 2)
- Walk your Window across your filtered images
- From each Window, take the maximum value
d. Step 4: Fully Connected Layer: The last layer in the network is fully connected, meaning that neurons of preceding layers are connected to every neuron in subsequent layers.
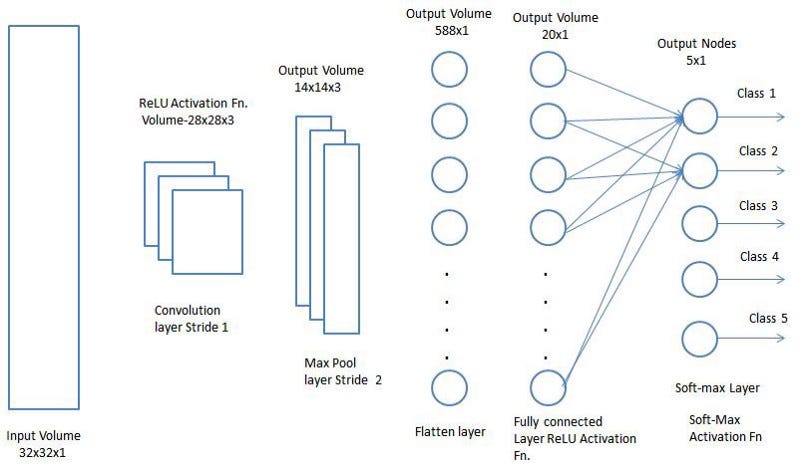
This mimics high-level reasoning where all possible pathways from the input to output are considered.
Then, take the shrunk image and put into the single list, so we have got after passing through two layers of convolution relu and pooling and then converting it into a single file or a vector.
V. EXPERIMENT AND RESULT
Test Cases
|
Test Case
|
Test Purpose |
Test condition |
Expected outcome |
Actual result |
Pass or Fail |
|
Load Images data
|
Upload Diabetic retinopathy images data |
Check for data |
Uploaded successfully |
Image is loaded Successfully. |
Pass
|
|
Load Images data
|
Upload Diabetic retinopathy images data |
Check for data |
Uploaded successfully |
Image format not supported, Open cv is not working. |
Fail |
|
Pre -Processing |
Apply methods like, noise removal, gray conversion |
Pre-processing for image |
Image are converted successfully
|
As Expected.
|
Pass
|
|
Pre -Processing |
Apply methods like, noise removal, gray conversion |
Pre-processing for image |
Image are converted successfully
|
Opencv library is nt detecting image and pre processing it |
Fail |
|
Apply feature classification using cnn |
Feature extraction is done for pre processed image |
Check for feature extarction |
Feauture extraction data is complete |
As Expected.
|
Pass
|
|
Detecting object using neural network |
Train model |
Check for model loss and accuracy |
Model trained successfully |
Model trained successfully |
Pass
|
|
Diabetic retinopathy image as input |
Detect the given object |
Check for classification with accuracy |
Predicted result |
Result is shown.
|
Pass
|
VI. RESULTS AND DISCUSSION:



VII. FUTURE SCOPE
- Fine-tuning the current network parameters to obtain a greater accuracy on single-channel images.
- Using all the channels instead of a single channel enables the network to learn more features thereby decreasing over-fitting by increasing the complexity of data.
- Working with alternate image pre-processing techniques to improve noise reduction
Conclusion
This paper presents the design, architecture, and implementation of deep convolutional neural networks for automatic detection and classification of diabetic retinopathy from color fundus retinal images. It also discusses the customized CNN metric used to evaluate the prediction results. This research involves three major CNN models, designing their architectures and finding the corresponding scores. The best score of 96% is obtained by the ensemble of these three models.
References
[1] Diabetic Retinopathy Detection Using VGG-NIN a Deep Learning Architecture (2021). [2] Blood Vessel Segmentation of Fundus Images by Major Vessel Extraction and Sub-Image Classification (2013). [3] Machine Learning Based Automation Neovascularization Detection on Optic Disc Region (2017). [4] Exudate Detection for Diabetic Retinopathy with Convolution Neural Networks (2017). [5] Automatic detection of diabetic Eye Disease through Deep Learning using Fundus Images: A Survey (2017). [6] Optic Disk Detection in Fundus Image Based on Structured Learning (2017). Author: Zhun Fan, Yibiao Rang, Xinye Cai Jiewei Lu, Wenji Li, Huibiao Lin, Xinjian Chen. [7] Detection of Retinal Micro Aneurysms using Fractal Analysis and Feature Extraction Technique (2013). [8] Dynamic Thresholding Technique for Detection of Hemorrhages in Retinal Images (2014).
Copyright
Copyright © 2022 Prof. Bhavya M R, Anush M, Gagan Raj, H Gowtham, Yashwanth U. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET45597
Publish Date : 2022-07-13
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online