

Ijraset Journal For Research in Applied Science and Engineering Technology
Dialearner: Predicting Diabetes with Machine Learning
Authors: Pranjal Jagtap, Vaishnavi Kad, Pratiksha Nimbalkar, Yashshree Shah, Arunadevi Khaple
DOI Link: https://doi.org/10.22214/ijraset.2024.62381
Certificate: View Certificate
Abstract
In the medical field, it is essential to predict diseases early to prevent them. Diabetes is one of the most dangerous diseases all over the world. In modern lifestyles, sugar and fat are typically present in our dietary habits, which have increased the risk of diabetes. To predict the disease, it is extremely important to understand its symptoms. Currently, machine-learning (ML) algorithms are valuable for disease detection. Diabetes, in all its types, costs countries of all income levels unacceptably enormous personal, societal, and economic expenses. The proposed system can help doctors to make data-driven decisions and enhance patients’ treatment. Several machine learning algorithms that are Decision Tree, Support Vector Machine, Random Forest, Artificial Neural Network, k-Nearest Neighbors, Logistic Regression, and Naive Bayes are used. Evaluation metrics such as accuracy, precision, recall, and F1-score are utilized to assess the model\'s predictive capability. Cross-validation techniques are employed to ensure robustness and generalizability. The proposed model holds significant promise in facilitating early detection and intervention for individuals at risk of developing diabetes, thereby improving patient outcomes, and reducing healthcare burden. Future research directions may include incorporating additional features and exploring ensemble learning techniques to further enhance predictive accuracy and reliability.
Introduction
I. INTRODUCTION
In the world of growing data, hospitals are deliberately adopting big data technologies. Early detection of diabetes is vital so that patients can take necessary actions at an early stage and potentially prevent or delay health complications such as cardiovascular disease, neuropathy, nephropathy, and eye disease arise from diabetes. Early diagnosis of Diabetes diseases helps to minimize the risk of patients having more complex health issues and medical costs. To apply machine learning algorithms for diabetes prediction, a significant amount of medical and patient data is collected and preprocessed. This data may include patient demographics, medical history, genetic information, lifestyle Factors. The collected data is then split into training and testing sets. Machine learning models, such as SVM, KNN, Naive Bayes, and Random Forest, are trained on the training data and evaluated on the testing data using appropriate performance metrics like accuracy, precision, recall, and F1-score. Once the machine learning models are trained and evaluated, they can be used to predict an individual's risk of developing diabetes based on their unique set of features. Machine learning has emerged as a powerful tool in healthcare, offering the potential to transform the way we approach diabetes risk assessment. Dialearner aims to accurately classify individuals at risk of developing diabetes based on their clinical profiles. Evaluate the performance of Dialearner against existing methods and assess its potential impact on improving patient outcomes and healthcare efficiency. we present the methodology employed in developing Dialearner, including dataset selection, model training, evaluation, and deployment. Early detection and symptomatic treatment are essential to ensure the healthy life and well-being of prediabetic patients. An intelligent medical diagnosis system based on symptoms, signs.
II. MOTIVATION
By Improving prediction and management there is motivation to reduce the economic burden on healthcare system and individuals. With the growth of electronic health records, wearable devices and patient generated data, there is wealth of health information available. Motivation comes from desire to harness this data for improved diabetes prediction and care.
III. OBJECTIVE
- To classify individuals into one of two categories - diabetic or non-diabetic.
- To assess the risk and enable early intervention, medical management to prevent or better manage the condition.
IV. METHODOLOGY
A. Data Collection
The process involves gathering relevant datasets, cleaning them,enhanching predictive performance through features, and dividing the dataset into training and testing sets for evaluation of the model’s performance.
B. Model Selection
Start with simple models like Logistic Regression, Naive Bayes for initial experimentation. Explore more complex algorithms like Random Forest, Decision Trees, Support Vector Machines (SVM). Combine multiple models for better predictive performance, such as using a Voting Classifier or Bagging and Boosting techniques.
C. Model Evaluation and Tuning
Use techniques like k-fold cross-validation to assess model performance and generalize well to unseen data. Optimize model hyperparameters using techniques like grid search or random search to improve model performance. Choose appropriate evaluation metrics such as accuracy, precision, recall, F1-score, or area under the ROC curve (AUC) depending on the problem's requirements and class imbalance.
D. Deployment and Monitoring
Deploy the trained model into production environments, such as web applications or healthcare systems, ensuring seamless integration. Continuously monitor model performance and retrain the model periodically with new data to maintain its accuracy and reliability. Ensure compliance with ethical guidelines and regulations, especially regarding privacy and fairness.
V. SYSTEM ARCHITECTURE
A. System Architecture
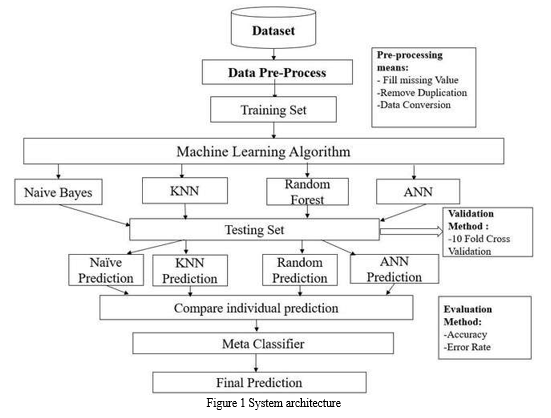
In this work we propose a model using random forest and decision tree develop a system that can predict the likelihood of an individual developing diabetes based on various health-related parameters The project starts with data collection, where relevant datasets containing features such as age, BMI, glucose levels, blood pressure, etc., are gathered. These datasets are then preprocessed to handle missing values, outliers, and normalized for consistency. Feature engineering is performed to extract new features or transform existing ones. A variety of machine learning algorithms are experimented with, including logistic regression, decision trees, random forests, support vector machines. The trained models are then evaluated using metrics such as accuracy, precision, recall, F1-score, and area under the ROC curve (AUC-ROC). In this random forest gives the high accuracy than another algorithm. These models are trained on the preprocessed data and evaluated using cross-validation techniques to ensure robustness and generalizability. The best-performing model is deployed for real-time predictions. Testing and validation are crucial to ensure reliability and accuracy. A comprehensive report is prepared, and future enhancements are discussed for further effectiveness in diabetes prediction and early intervention.
B. Flow chart
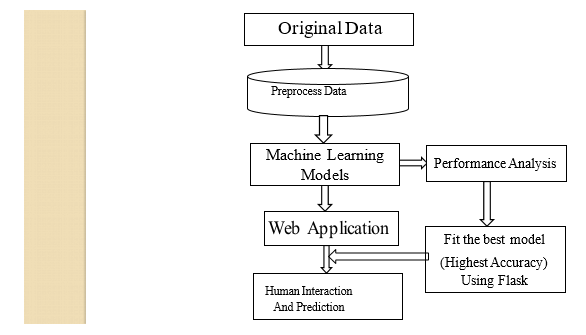
This diagram shows the layout and workflow of our system. In this work we propose a model using random forest and decision tree develop a system that can predict the likelihood of an individual developing diabetes based on various health-related parameters. A variety of machine learning algorithms are experimented with, including logistic regression, decision trees, random forests, support vector machines. The trained models are then evaluated using metrics such as accuracy, precision, recall, F1-score, and area under the ROC curve (AUC-ROC). In this random forest gives the high accuracy than another algorithm. These models are trained on the preprocessed data and evaluated using cross-validation techniques to ensure robustness and generalizability. The best-performing model is deployed for real-time predictions. Testing and validation are crucial to ensure reliability and accuracy. The prediction of diabetes using machine learning is an important application of artificial intelligence in healthcare. Diabetes is a chronic medical condition that affects millions of people worldwide. Machine learning models can be trained to analyze various data points and make predictions about the likelihood of an individual developing diabetes.
VI. APPLICATIONS
- Patient Education and Engagement: Educating and engaging patients in self-care by providing them with personalized insights and actionable recommendations.
- Clinical Decision Support: Assisting healthcare professionals in diagnosing and managing diabetes by providing decision support tools that integrate patient data, research findings, and clinical guidelines.
- Telemedicine and Remote Monitoring: Enabling telemedicine platforms to remotely monitor patients with diabetes, allowing healthcare providers to intervene as needed and reduce the need for in-person visits.
- Treatment Response Prediction: Anticipating how individual patients will respond to various diabetes treatments, such as insulin therapy or oral medications, and adjusting treatment plans accordingly.
- Personalized Risk Assessment: Providing individuals with a personalized risk assessment based on their medical history, genetics, lifestyle, and other relevant data, which can guide healthcare decisions.
VII. RESULTS
- Model Performance: The ML models, including logistic regression, random forest, support vector machines (SVM), and neural networks, were trained and evaluated on a dataset comprising clinical features such as glucose levels, BMI, age, insulin and family history. Evaluation metrics such as accuracy, precision, recall, and F1-score were utilized to assess the performance of each model intuitive user interface with features for adding, removing, and updating products.
- Performance Evaluation Metrics: Employed a range of performance evaluation metrics to assess the efficacy of our model in predicting diabetes. These metrics include accuracy, precision, recall, F1-score, and area under the receiver operating characteristic curve (AUC- ROC).
- Clinical Implications: An advanced recommendation system that provides personalized product recommendations to customers based on their browsing history, purchase behavior, and preferences. The recommendations should be accurate and tailored to each customer.
- Ethical Considerations: The deployment of machine learning models such as Dialearner in healthcare settings necessitates careful consideration of ethical implications. Issues related to algorithmic bias, fairness, transparency, and patient autonomy must be meticulously addressed to safeguard against unintended consequences and ensure equitable healthcare delivery.
- Data Privacy and Security: Protecting patient privacy while allowing data sharing for model training and validation is a significant challenge that requires robust privacy-preserving techniques and secure data management practices.
VIII. FUTURE SCOPE
The journey of Dialearner is far from over. In the future, we aim to predict the diabetes in less time also increase the accuracy rate. Develop models that can be applied globally, considering diverse populations and healthcare systems. This includes addressing the unique challenges and the risk factors in different regions Investing further research and development to improve the accuracy and efficiency of machine learning algorithms.
Conclusion
In conclusion, the prediction of diabetes using machine learning algorithms offers promising potential for assisting in medical diagnoses. Various machine learning models, including Naive Bayes, Random Forest, and Decision Tree, K-Nearest Neighbors can be employed to predict diabetes based on relevant patient features. After using all these patient records, we can build a machine learning model (Random Forest, KNN, Decision Tree) to accurately predict whether the patients in the dataset have diabetes or not along with that we were able to draw some insights from the data via data analysis and visualization. Random forest models allow clinicians to gain insights into the factors influencing diabetes risk prediction.
References
[1] Usama Ahmed, Ghassan F. Issa3 “Prediction of diabetes empowered with fused machine learning” in 2022 [2] Santosh Kumar Sharma, “A Diabetes Monitoring System and Health-Medical Service Composition Model in Cloud Environment” in 2023 [3] SHIRINA SAMREEN, “Memory-Efficient, Accurate and Early Diagnosis of Diabetes Through a Machine Learning Pipeline Employing Crow Search-Based Feature Engineering and a Stacking Ensemble” in 2021 [4] Sajida Perveen, Muhammad Shahbaz, “Handling Irregularly Sampled Longitudinal Data and Prognostic Modeling of Diabetes Using Machine Learning Technique” in 2022. [5] Giovanniannuzzi, Andrea Apicella, “Impact of Nutritional Factors in Blood Glucose Prediction in Type 1 Diabetes Through Machine Learning” in 2023 [6] Phuwadol Viroonluecha, Esteban Egea-Lopez, “Evaluation of Offline Reinforcement Learning for Blood Glucose Level Control in Type 1 Diabetes” in 2023 [7] Mohammad Tariqul Islam, “DiaNet: A Deep Learning Based Architecture to Diagnose Diabetes Using Retinal Images Only” in 2021 [8] Radwa Marzouk, Ala Saleh Alluhaidan, Sahar A. El_Rahman, “An Analytical Predictive Models and Secure Web-Based Personalized Diabetes Monitoring System” in 2022 [9] Giovanni Annuzzi, Andrea Apicella, “Impact of Nutritional Factors in Blood Glucose Prediction in Type 1 Diabetes Through Machine Learning” in 2023 [10] Md. Kamrul Hasan, Mahmudul Hasan, “Diabetes Prediction using Ensembling of Different Machine Learning Classifiers” in 2020.
Copyright
Copyright © 2024 Pranjal Jagtap, Vaishnavi Kad, Pratiksha Nimbalkar, Yashshree Shah, Arunadevi Khaple. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET62381
Publish Date : 2024-05-19
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online