

Ijraset Journal For Research in Applied Science and Engineering Technology
Discerning of Gestures using Machine Learning
Authors: Arav Gupta, Rishabh Chauhan
DOI Link: https://doi.org/10.22214/ijraset.2023.51519
Certificate: View Certificate
Abstract
Hand gestures can improve computer vision, and gesture-based innovation can provide a natural way to engage. Deafness is a hearing loss that prevents people from understanding spoken language. Thanks to sign language, the gap in spoken language has also shrunk. Hand gestures are assessed in the same way as sign language is, displaying how deaf people naturally communicate. We propose real-time hand gesture recognition in our study. Deaf people profit from the proposed CNN model design since it will help them overcome communication barriers. The proposed model was able to recognise 11 different gestures with 94.61 percent accuracy using depth images.
Introduction
I. INTRODUCTION
In the comments of Nelson Mandela, ""gets inside his mind" when addressing to a person in his own speech "Speak to him in his own tongue; language has existed since the dawn of society and is essential to human connection. It's a method of communication which allows people to express themselves and comprehend real-world concepts. Books, cell phones, and certainly no word I'm writing would make sense without it. We take it for granted and don't know how valuable it is because it is so embedded in our daily lives. Those with hearing loss are frequently neglected and excluded in today's fast-paced society. They must make an effort to communicate with people who are different from themselves, to bring up their ideas, speak their minds, and express themselves. Despite its status as a foreign language, gesture is often used. Despite the fact that sign language is a form of communication for the deaf, non-sign language users have minimal comprehension of it. As a result, the gap has increased considerably. We suggest a sign language recognition technology to prevent this from happening.
It will be a brilliant way for individuals with hearing disability to engage, as well as for non-sign language users to understand what the letter is saying. Many countries have distinctive sign motions and interpretations.
An alphabet in Korean sign language, for example, will be different from such an alphabet in Indian sign language. While this emphasises the diversity in sign languages, it also emphasises their complexity. To achieve a decent accuracy, deep learning have to be well in gestures. The datasets in our proposed model are developed using American Sign Language.
A sign gesture can be identified for either of the two ways. The first one is a glove-based method, wherein the signer wears data gloves while their hand movements are recorded. The second method relies on vision, which can be classified as static or dynamic recognition. Dynamic is associated with the collection of movements in real time, whereas stable is preoccupied with the representation of movements in two dimensions.
Even though gloves have quite a highest accuracy of over 90%, these are uncomfortable to wear and could be used in humid weather. They are difficult to transport because their use demands the use of a computer. We used static detection of hand gestures in this scenario since it increases accuracy when compared to dynamic hand gestures like the ones for the numbers 1 and 2. We present this study in order to increase accuracy by employing Convolution Neural Networks (CNN).
II. LITERATURE SURVEY
Gloves are difficult to maintain and cannot be used in wet conditions, despite their high level of accuracy (about 90%). They are difficult to transport because they demand the use of a computer. We preferred static hand gesture recognition over dynamic hand gestures like the digits 1 and 2 in this case since it enhances accuracy. The objective of this research is to see if Convolution Neural Networks can be utilised to increase accuracy (CNN).
Real Time Hand Gesture Recognition Based on Deep Learning YOLOv3 Model[1]: In his research paper , they proposed a model based on the YOLOv3 and DarkNet- S3 deep learning models. There proposed model was not tested on the YOLO-LITE model but they achieved a accuracy of 97.68%.
There model could not perform better than GPUs in case of communication with the deaf people, gestures based signaling system, sign language recognition etc.
Problem Can affect and Planned Deaf and Dumb Interaction Aid Implementation in [2]: The author of this study proposed a system to assist communication deaf and dumb individuals engage with normal people by translating hand gestures into meaningful text messages utilizing Indian sign language (ISL). The major goal is to build an algorithms that can instantaneously translate dynamic gestures into text. After testing, the system will be integrated into the Android version and released as something of an application for mobile phones and tablets.
SignPro is a Deaf and Dumb application suite. The author exhibited a sign language application that helps deaf and dumb people communicate the with rest of the world. A critical feature of this technique is the actual gesture to text conversion. Gesture segmentation, gestures matching, and voice conversion are among the processing steps. Various image processing approaches, such as periods, bounding box calculation, skin pigmentation segmentation, and sector expansion, are used to identify motions. Feature point similarity and connection based comparing are two methods for matching gestures. There are two more functions in the app: textual to movement transformation and textual to speech signals.
Anarbasi Rajamohan et al. [4] was using a data ergonomic methodology to detect American Sign Language. The system is made up of a flex sensor, an accelerometer, and a tactile sensor. Hand gestures are collected and translated into code by this sensor. The accuracy of that system was 90 percent.
Semantic Segmentation Increases Real-Time Hand Gesture Recognition[7]. Considering dense optical flow is a costly computing approach that limits real-time performance, the researcher of this research report offered it as an alternative. To identify hands pixel-size, alternative way is to utilise hand classification model using EASSO-Net.
Real-Time Hand Gestures Recognition using Fine- Tuned Convolutional Neural Network[8]. For the recognition of vision based static hand gestures the author introduced a score fusion techniques between two fine-tuned CNNs. One of the advantage is recognition became easier in presence of noise and complex backgrounds. Through these experimented result they showed that HGR performance is better thanAlexNet and VGG-16.
A evaluation of algorithms used to recognise hand gestures[9]. They proposed a model in that they used two datasets and four algorithms (K-NN, Nave Bayes, ANN, and SVM) to perform experiments by using K-fold technique. The results of these experiments enabled them to infer that the ANN model performs exceptionally well. I also learned that data preprocessing and feature extraction are critical steps.
III. DATASET DESCRIPTION
In resolving significant challenge in a study dataset, a substantial role is played. A dataset is very helpful for great studies to achieve more immeasurable confidence. The importance of datasets is underscored by deep learning. It is the primary aspect that enables algorithm training. A number of features is important for boosting the classification rate in deep learning. To cope with depth images, the Senz3d collection of hand movements was used.
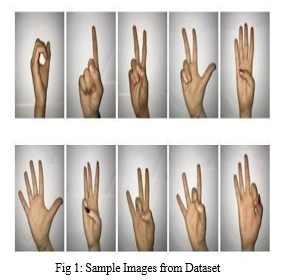
The dataset contains a variety of static movements captured with the Creative Senz3D camera . There are 1320 photos in the dataset. Four separate individuals photos make up the dataset. Each person made 11 different gestures 30 times in a row. Color, depth, and confidence frames are accessible for each sample in the collection. Figure 1 shows a selection of photos from the dataset for hand gesture recognition.
IV. PROPOSED METHODOLOGY
The hand gesture esteem device was developed in our study applying hand identification and pre - processing (resizing all images) as detected using CNN version architectural. However, photo category designs are now separated for the computer imaginative and prescient domain. After acquiring the intensity shot, the hand data was separated. After a few training sets, a skilled CNN version for functional extracting and detection and recognition is generated.
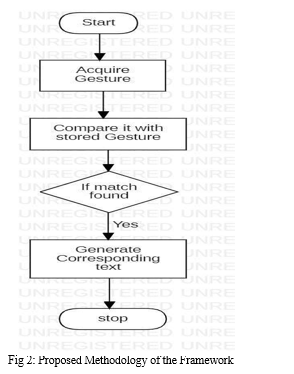
In Fig 2 the block diagram of proposed technique has been shown.
A. Hand Segmentation
To facilitate our research, we retrieved depth pictures from the dataset. In hand gesture recognition, the extraction of the hand region is the most crucial stage. As a result, separating the hand region from the depth map is the first stage in recognising motions. The segmentation process began with depth variable binarization, which eliminates samples with a path way than a specified point predicated on the application. After the depth images were acquired, the hand data was separated using the YCbCr colour palette. It differentiates the fingers from the structure in a simple way. The YCbCr value of the depth picture was altered. Each pixel's YCbCr values got compared with the reference frequencies. The following are the boundary values for each parameter: The Y, Cb, and Cr ranges are as follows: 0 Y 255 and 135 Y C 180 and 85 Cb 135.
B. Preprocessing
When training a convolutional neural network, it can be difficult to know how to appropriately prepare visual data [5]. Because the photos in the training dataset were of different sizes, they had to be scaled before being fed into the model [5].This involves both resizing and cropping techniques during both the training and evaluation of the model [4]. After getting the segmented hand images, the images have been resized to 256×256.
V. PROPOSED CNN MODEL
Artificial intelligence is getting more and more popular. In bridging the gap between human and machine, the International Journal of Computer Applications (0975 – 8887) produced Volume 174, No. 16, January 2021 30 [5]. Computer Vision and supervised learning it has evolved over time, majorly but since to one algorithm – the Convolutional Neural Network [5]. In order to get an enhanced, neural networks have been shown to associated with high levels alternative algorithms over time. Image categorisation is now a significant topic among researchers as neural networks have evolved. The convolution neural network excels machine learning approaches in this field. Figure 3 illustrates CNN's whole work flow for interpreting finger movements.
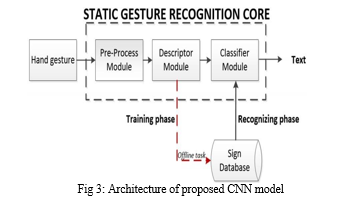
Each input image must go through a succession of convolution, mixing, and recurrent neural network, and even the ReLU functions, where uses probabilistic values to distinguish arm movements. Our proposed Approach design comprises three convolution layers, two convolution and pooling strands, and upsampling. The output level contains 11 nodes. The dataset can be used to recognise 11 gestures, according to these 11 nodes. The dataset was segmented into 816 training shots and the others for validation.
A. Convolution layer
The standardized photographs were delivered into the convolution layer. The graphics were shrunk to 256 × 256 pixels. On the input image, four fully connected layers with a manageable previous layer were applied. A kernel is a gathering of weights, which are just a set of numbers. In the convolution layers, the kernel size has been set to 33%. The image has been transformed by a mathematical kernel. Convolutioning a picture using many filters can achieve threshold method, blur, and sharpness. Three convolutions were used in our proposed methodology. There seem to be 64 filters in the first convolution layer, and 128 filters in the second and third stages. Convolutional layer analyzers identify information that aid classification.
B. Pooling Layer
The pooling layer, like the first, reduces the network and the mounting evidence suggests of features. The dimensionality of feature maps is lessened by pooling them while vital information are conserved. To produce the same number of convolution maps, pooling is administered to each feature space separately. We used two pooling layers in our proposed architecture. Much of the pooling process is deciding on a pooling formula. Among the many pooling types, max- pooling has been chosen. M ax function has already been considered more efficient than other pooling techniques in computer vision applications such as picture categorization. The outputs are shared extracted features that showcase the stack's most notable feature, but instead of batch normalization. Maximum pooling delivers the highest benefit in each bounding box area. The size of the kernel always seems to be smaller than the size of the feature map. The process of dividing the computing power required for processing images by lowering the complexity of the images. It's also useful for extracting important rotational and positioning independent parameters to improve the learning.
C. Fully Connected Layer
The convnet is the final layer in a convolutional neural network. These layers operate similarly to a traditional deep neural network. The completely linked layer connects every neuron in one layer to every synapse in another layer. Whereas convolution, like with the pooling layer, harvests capabilities, completely connected layers classify input based on the functionality extracted by the prior layer. Every one of the compression and pooling layers' composite records are placed in the FC layer.
The flatten matrix is run through an FC layer to categorise the images. The function coding scheme is provided using an absolutely linked layer (FC). This function section shows all of the records that are necessary around the entry. That after circuit has been trained, this feature set is used for categorisation. This layer labels pictures properties using non-linear methods. This layer includes a ReLU activation function and generates a percentage for each of the category labels.
D. ReLU Activation Function
The perceptron in a neural network is in control of increasing the relative balanced input. On the other hand, the reconstructed linear activation function (ReLU) takes to generate output. If somehow the input is positive, this linear function displays the input directly; conversely, it outputs zero. Even though it is comparatively faster and offers higher performance, it became the default algorithm for very many varieties of neural networks[8].
Conclusion
In a neural network, the activation function is in command of transforming the equally average input. The rectified linear activation function (ReLU), but at the other hand, usually produces output. This linear function delivers the input directly if the input is positive; else, it produces zero. This has become the usual algorithm for many machine learning algorithms and it is better to handle and offers positive performance in general.
References
[1] Mujahid, A.; Awan, M.J.;Yasin, A.; Mohammed, M.A.;Damaševi?cius, R.; Maskeli¯unas, R.;Abdulkareem, K.H. Real- Time Hand Gesture Recognition Based on Deep Learning YOLOv3 Model. Appl. Sci.2021,11, 4164. [2] Rafiqul Zaman Khan and Noor Adnan Ibraheem. “Comparitive Study of Hand Gesture Recognition System.” International Conference of Advanced Computer Science & Information Technology, 2012. [3] Arpita Ray Sarkar, G. Sanyal, S. Majumder. “Hand Gesture Recognition Systems: A Survey.” International Journal of Computer Applications, vol. 71, no.15, pp. 25-37, May 2013. [4] Brownlee,J.,2019. Deep Learning for Computer Vision: Image Classification, Object Detection, and Face Recognition in Python. Machine Learning Mastery [5] Saha, S., 2018. A comprehensive guide to convolutional neural networks—the ELI5 way. Towards Data Science, 15 [6] Dnyanada R Jadhav, L. M. R. J Lobo, Navigation of PowerPoint Using Hand Gestures, International Journal of Science and Research (IJSR) 2015. [7] Benitez-Garcia, G. Prudente-Tixteco, L.; Castro-Madrid,L.C. Toscano-Medina, R. Olivares-Mercado, J.; Sanchez-Perez, G.; Villalba, L.J.G. Improving Real-Time Hand Gesture Recognition with Semantic Segmentation. Sensors2021, 21, 356. https://doi.org/10.3390/s21020356 [8] Sahoo, J.P.; Prakash, A.J. P?awiak, P.; Samantray, S Real - Time Hand Gesture Recognition Using Fine-Tuned Convolutional Neural Network. Sensors 2022, 22, 706. https://doi.org/10.3390/s22030706 [9] Paulo Tr. ,F.Riberio, Luis .P.Reis, A comparison of machine learning algorithm applied to hand gesture recognition 2019
Copyright
Copyright © 2023 Arav Gupta, Rishabh Chauhan. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET51519
Publish Date : 2023-05-03
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online