

Ijraset Journal For Research in Applied Science and Engineering Technology
Domain Adaptation and Semantic Drawing Driven Sketch-to-Photo Retrieval using Collaborative Generative Representation Learning
Authors: Dr K Sujatha, Koulik Ghsoh , Aneesh Anand
DOI Link: https://doi.org/10.22214/ijraset.2024.61734
Certificate: View Certificate
Abstract
Sketch-based face recognition is an interesting task in vision and multimedia research yet it is quite challenging due to the great difference between face photos and sketches. In this paper we propose a novel approach for photo-sketch generation aiming to automatically transform face photos into detail-preserving personal sketches. Unlike the traditional models synthesizing sketches based on a dictionary of exemplars we develop a fully convolutional network to learn the end-to-end photo-sketch mapping. Our approach takes whole face photos as inputs and directly generates the corresponding sketch images with efficient inference and learning in which the architecture is stacked by only convolutional kernels of very small sizes. The exemplar-based method is most frequently used in face sketch synthesis because of its efficiency in representing the nonlinear mapping between face photos and sketches. However, the sketches synthesized by existing exemplar-based methods suffer from block artifacts and blur effects. In addition, most exemplar-based methods ignore the training sketches in the weight representation process. To improve synthesis performance, a novel joint training model is proposed in this paper, taking sketches into consideration. First, we construct the joint training photo and sketch by concatenating the original photo and its sketch with a high-pass filtered image of their corresponding sketch. Then, an offline random sampling strategy is adopted for each test photo patch to select the joint training photo and sketch patches in the neighboring region. Finally, a novel locality constraint is designed to calculate the reconstruction weight, allowing the synthesized sketches to have more detailed information
Introduction
I. REAL TIME USE CASES
Face sketches and face photos can be converted into one another. As the technology of face photo-to-sketch synthesis becomes more mature, it is widely used in digital entertainment, public security law enforcement, and case investigation . For example, the suspect’s face photos taken by surveillance cameras often have the conditions of occlusion and low resolution, which affect face recognition. Law enforcement agencies have to ask artists to draw face sketches of suspects based on eyewitness accounts and surveillance videos. However, there is a large modal gap between face photos and face sketches, so it is difficult to achieve accurate recognition. Therefore, it can solve the above problems quickly by converting face sketches to face photos. Meanwhile, sketches are more artistic than photos in digital entertainment, as more users upload their sketch portraits to social platforms.
II. INTRODUCTION
Face sketch synthesis is a key branch of face style transformation, which generates face sketches for given input photos with the help of face photo-sketch pairs as the training dataset . It has achieved wide applications in both law enforcement and digital entertainment. For example, sketches drawn according to the description of victims or witnesses can help identify a suspect by matching the sketch against a mugshot dataset from a police department. Face sketch synthesis reduces the texture discrepancy between photos and sketches for the face recognition procedure and thus increases the recognition accuracy . In digital entertainment, people are increasingly preferring to use face sketches as their portrait in social media; the sketch synthesis technique can also simplify animation production During the past two decades, various sketch synthesis methods have been proposed. The exemplar-based method is an important category of existing synthesis approaches. It synthesizes sketches for test photos by utilizing photo-sketch pairs as training data. The exemplar-based method mainly consists of neighbor selection and reconstruction weight representation . In the neighbor selection process, K nearest training photo patches are selected for a test photo patch. In the reconstruction weight representation, a weight vector between the test photo patch and the selected photo patches is calculated.
The target sketch patch can be obtained using weighted averaging of the K training sketch patches corresponding to the selected photo patches with the calculated weight vector. The final sketch is obtained by averaging all the generated sketch patches. Face sketch recognition involves matching two face images from different modalities; one is a face drawing created by a professional artist based on a witness statement, and the other is the corresponding image from the agencys department database. Some facial sketches are depicted for illustrative purposes, as given in Figure 1. Due to the partial and approximate nature of the eyewitnesss description, face sketches are less detailed than their corresponding photos. Due to the modality disparities between face photos and sketch images, classic homogeneous face recognition algorithms perform badly in face sketch recognition . To overcome this challenge, soft computing models have been utilized. Existing methods for face sketch recognition are resolved in three ways, which are synthesis-based, projection-based, and optimization-based. In the first category, synthesis-based methods, also known as generative methods, are used to transform one of the modalities into the other (photo to sketch or vice versa) prior to matching. Projection-based techniques utilize soft computing approaches to reduce the differences between sketch and photo features projected in a different space. The final category, which is optimization-based, focuses on fine-tuning the parameters using optimization methods. In other words, the objective is to maximize the similarity between the sketch and its photo, maximizing the weights of their extracted features. How can we visualize a scene or object quickly? One of the easiest ways is to draw a sketch. Compared to photography, drawing a sketch does not require any capture devices and is not limited to faithfully sampling reality. However, sketches are often simple and imperfect, so it is challenging to synthesize realistic images from novice sketches. Sketchbased image synthesis enables non-artists to create realistic images without significant artistic skill or domain expertise in image synthesis. It is generally hard because sketches are sparse, and novice human artists cannot draw sketches that precisely reflect object boundaries. A real-looking image synthesized from a sketch should respect the intent of the artist as much as possible, but might need to deviate from the coarse strokes in order to stay on the natural image manifold. In the past 30 years, the most popular sketchbased image synthesis techniques are driven by image retrieval methods such as Photosketcher and Sketch2photo . Such approaches often require carefully designed feature representations which are invariant between sketches and photos. They also involve complicated post-processing procedures like graph cut compositing and gradient domain blending in order to make the synthesized images realistic. The formulation of face sketches based on learning from the reference photos and their corresponding forensic sketches has been an active field since the last two decades. It helps the law enforcement agencies in the search, isolation, and identification of suspects by enabling them to match sketches against possible candidates from the mug-shot library and/or photo dataset of the target population . Forensic or artist sketches are also used in animated movies and/or during the development of CGI-based segments . Presently, many persons like to use a sketch in place of a personal picture as an avatar or a profile image. Therefore, a ready-made scheme to furnish a sketch from a personal picture, without involving a skilled sketch artist, would come in handy . Since 2004, exemplar-based techniques incorporating patch-matching algorithms have been most popular. Photos and corresponding sketches were identically divided into a mosaic of overlapping patches. For each patch of the photo, its nearest patch in all training sketches according to a given property, for example, the Markov random field (MRF) , the Markov weight field (MWF), or spatial sketch denoising (SSD), was searched for and marked. This principle was applied successively to all photos and sketches in the training set. Hence, a dictionary was developed. For each test photo patch, a suitable patch was first searched for in the photo and its corresponding patch in the dictionary was selected as part of the resulting sketch
III. MOTIVATION
With the advancements in generation and its technology, humans are finding ways to make their lives faster, efficient and hassle-free. Graphics is a way of portraying text with ease and better understandability. Blender, Adobe Photoshop, Coreldraw, etc. are still used as conventional ways to render graphics. However, the time and effort required to render files in these software is very high. The learning curve of these software is also a limitation for a naive user. These software also need systems with technical specification that are graphic focused and uncompromisable. This professional software also come with a high price tag that is not affordable by most of the users. Besides, these software are not explicitly crafted to convert sketches into equivalent images. Hence they are not a logical solution for converting sketches into images
IV. OBJECTIVES
- To generalization ability of our model to other groups.
- To update the contextual associations between newly derived descriptions and the features.
- To adapt a more efficient linear-based attention scheme which effectively permits long sequence interactions on large inputs.
- To provide better fine-grained feature and to produce high-quality results.
- To optimize the latent vector to minimize the error for the given image.
V. PROBLEM STATEMENT
Edges, boundaries and contours are important subjects of study in both computer graphics and computer vision. On one hand, they are the 2D elements that convey 3D shapes, on the other hand, they are indicative of occlusion events and thus separation of objects or semantic concepts. In this paper, we aim to generate contour drawings, boundary-like drawings that capture the outline of the visual scene. Prior art often cast this problem as boundary detection. However, the set of visual cues presented in the boundary detection output are different from the ones in contour drawings, and also the artistic style is ignored
VI. EXISTING SYSTEM
Query by Image Content (QBIC), subsequently known as Content-Based Image Retrieval (CBIR), offers an advantageous solution in a variety of applications, including medical, meteorological, search by image, and other applications. Such CBIR systems primarily use similarity matching algorithms to compare image content to get matched images from datasets. They essentially measure the spatial distance between extracted visual features from a query image and its similar versions in the dataset. One of the most challenging query retrieval problems is Facial Sketched-Real Image Retrieval (FSRIR), which is based on content similarity matching. These facial retrieval systems are employed in a variety of contexts, including criminal justice. The difficulties of retrieving such sorts come from the composition of the human face and its distinctive parts. In addition, the comparison between these types of images is made within two different domains. Besides, to our knowledge, there is a few large-scale facial datasets that can be used to assess the performance of the retrieval systems. The success of the retrieval process is governed by the method used to estimate similarity and the efficient representation of compared images. However, by effectively representing visual features, the main challenge-posing component of such systems might be resolved. Hence, this paper has several contributions that fill the research gap in content-based similarity matching and retrieval. The first contribution is extending the Chinese University Face Sketch (CUFS) dataset by including augmented images, introducing to the community a novel dataset named Extended Sketched-Real Image Retrieval (ESRIR). The CUFS dataset has been extended from 100 images to include 53,000 facial sketches and 53,000 real facial images. The paper second contribution is presenting three new systems for sketched-real image retrieval based on convolutional autoencoder, InfoGAN, and Vision Transformer (ViT) unsupervised models for large datasets. Furthermore, to meet the subjective demands of the users due to the prevalence of multiple query formats, the third contribution of the paper is to train and assess the performance of the existsing models on two additional facial datasets of different image types. Recently, the majority of people have preferred searching for brand logo images, but it may be tricky to separate certain brand logo features their alternatives and even from other features in an image. Thus, the fourth contribution is to compare logo The associate editor coordinating the review of this manuscript and approving it for publication was Abdel-Hamid Soliman E. S. Sabry et al. Image Retrieval Using Convolutional Autoencoder, InfoGAN, and Vision Transformer Unsupervised Models image retrieval performance based on visual features derived from each of the three suggested retrieval systems. The paper also presents cloud-based energy and computational complexity saving approaches on large-scale datasets. Due to the ubiquity of touchscreen devices, users often make drawings based on their fantasies for certain object image searches. Thus, the existsing models are tested and assessed on a tough dataset of doodle-scratched human artworks. They are also studied on a multi-category dataset to cover practically all possible image types and situations. The results are compared with those of the most recent algorithms found in the literature. The results show that the existsing systems outperform the recent counterparts. This article might serve as the basis for a broad range of appli- cations that employ features to classify and retrieve objects in images. According to the findings, the key engine of the entire process is the capacity of extraction methods to adequately to increase performance accuracy. Aiming for model general- ity, experiments demonstrate various retrieval process hurdles that significantly influence the retrieval accuracy for faces and objects in different images. The ESRIR dataset, which includes 53,000 face sketches and 53,000 real facial images, has been presented to the community in order to increase the scale of facial sketched-real image retrieval. Besides, three different image retrieval systems have been existsing in this paper based on convolutional autoencoder, InfoGAN, and ViT. The existsing models have been trained with six different datasets, including the introduced ESRIR dataset. According to the findings, InfoGAN and ViT retrieval sys- tems are more successful in differentiating freehand facial sketch drawings and objects on CUFSF, and the 256_Object Categories datasets. Besides, their outstanding performance on ESRIR dataset is independent of the applied augmentation and visual scene transformations. On the ESRIR dataset, the ViT system achieves about a 1.183 F-score value, whereas the InfoGAN system reaches around a 1.272 F-score.
The ViT retrieval system outperforms the other ones on the too- challenging QuickDraw-Extended dataset. The ViT system successfully retrieved images for the 10 query images from the QuickDraw-Extended dataset with an F-score of around 0.81.
The use of other distance metrics in place of the Euclidian distance utilized in this article for convolutional autoencoder, InfoGAN, and ViT instances, is one of the additions to this paper. As an alternative, combined feature extraction algorithms, such as capsule networks, might be employed in conjunction with the ones recommended in this article to investigate and benefit from their efficacy and results. Additionally, several artificial intelligence methods might be investigated on different other datasets. The authors would like to acknowledge the Princess Nourah bint Abdulrahman University Researchers Supporting Project number (PNURSP2023R66), Princess Nourah bint Abdul- rahman University, Riyadh, Saudi Arabia.
VII. DRAWBACKS OF EXISTING SYSTEMS
- Cannot be implemented real time
- Calculations become complex if values are uncertain and/or outcomes are linked.
- Higher correlation in prediction errors
- Identification of the inconsistencies in the data is very difficult
- Problems existing in their respective network structures.
- Difficult to be used in large-scale parallel computing.
- High memory consumption during construction.
VIII. PROPOSED SYSTEM
With the development of data-driven intelligent era, learning the mapping between sketches and images requires a suitable training dataset which contains sketch image pairs. We propose the Collaborative Generative Representation Learning technique to create a reasonable sketch of the corresponding image and encourage robustness to achieve small perturbations. We usually pay attention to the iconic aspects of an object when scanning an image. Due to the inherent domain gap between sketches and photos, the sketches. Like a Neural Net, the structure has a skip layer connection, which can skip the pooling step and transmit information that is more complete so that the neural network can operate on the lower image features. In the non-skip layer connection of neural networks, with the pooling of hidden layers, the neurons will have more advanced features, meaning that they analyze a larger range of data in the original image and operate according to the advanced features extracted from the large range of regions in the original image. However, this also means that the neural network may directly remember the original images advanced features and make judgments based on them, representing overreliance on the advanced features. As a result, the neural network cannot recognize small images well. It is expected that the neural network will tend to use skip layer connections when identifying small images and nonskip layer connections when identifying large images, so that it will not miss small nodule diagnosis because of excessive dependence on advanced features. Neural Net adds noise layer by layer in the training field; the deeper the hidden layer, the greater the effect of the noise. However, the skip layer connection in the Neural Net is equivalent to skipping part of the hidden layer, which results in the information transmitted by this connection being less affected by noise and having higher confidence. Conversely, information transmitted by the hidden layer of the non-skip layer connection is highly affected by noise and has low confidence. Therefore, the judgment of the Neural Net depends more on the information from the skip layer connection type, and it can work well in identifying small images. Large images are easy to identify because of their large amount of information. Noise has little effect on this information, and the hidden layers in the non-skip layer connection type still work well in identifying large images.
IX. ADVANTAGES OF PROPOSED SYSTEM
- Boost their performance on very high-dimensional datasets.
- Helps to lessen the workload associated with computing while simultaneously enhancing detecting capabilities.
- Simplicity and Explainability.
- Reveal the highly nonlinear Relationship
- Can effectively guide the label assignment and boost the label confidence.
- Simplify the implementation process..
X. PROPOSED ALGORITHM
The Proposed algorithm is a Collaborative Generative Representation Learning Neural Network Algorithm. This algorithm has been chosen for the following benefits
- Collaborative Generative Representation Learning Neural Network Advantages
- Ability to learn and model non-linear and complex relationships.
- When an item of the neural network declines, it can continue without some issues by its parallel features.
- Learn from events and make decisions through commenting on similar events.
XI. MODULES
- Module 1 : Image Preprocessing
Pre-processing is a common name for operations with images at the lowest level of abstraction both input and output are intensity images. These iconic images are of the same kind as the original data captured by the sensor, with an intensity image usually represented by a matrix of image function values (brightnesses). The aim of pre-processing is an improvement of the image data that suppresses unwilling distortions or enhances some image features important for further processing. Histogram equalization provides a sophisticated method for modifying the dynamic range and contrast of an image by altering that image such that its intensity histogram has the desired shape.
The primary objective of pre-processing is to refine image data, suppressing undesired distortions while accentuating crucial image features essential for subsequent processing stages. Among the array of pre-processing techniques, histogram equalization stands out as a sophisticated method for adjusting the dynamic range and contrast of an image. By reshaping the intensity histogram, histogram equalization effectively transforms the image, optimizing its visual clarity and enhancing the prominence of relevant features, thus improving the overall quality of image data for subsequent analysis and interpretation.

2. Module 2 : Feature Extraction
Feature extraction is a part of the dimensionality reduction process, in which, an initial set of the raw data is divided and reduced to more manageable groups. So when you want to process it will be easier. The most important characteristic of these large data sets is that they have a large number of variables. These variables require a lot of computing resources to process.
So Feature extraction helps to get the best feature from those big data sets by selecting and combining variables into features, thus, effectively reducing the amount of data. These features are easy to process, but still able to describe the actual data set with accuracy and originality.
Feature extraction plays a pivotal role in the dimensionality reduction process, a crucial step in handling large datasets efficiently. Initially, raw data undergoes partitioning and transformation into more manageable subsets, facilitating easier processing. The hallmark of such datasets is their multitude of variables, demanding substantial computing resources for processing. Feature extraction addresses this challenge by identifying and amalgamating variables into meaningful features, thereby substantially reducing data volume. These extracted features are designed to retain the essence and fidelity of the original dataset while being easier to process. They strike a balance between simplicity and representational power, enabling accurate depiction of the underlying dataset characteristics. Through this process, feature extraction streamlines computational tasks and enhances the effectiveness of subsequent analysis and modeling techniques.
3. Module 3 : Sketch to Image Prediction
Neural Network is recognized as the feature learner that typically consists of two parts, and has a tremendous capacity to automatically draw out essential feature from input data. The first step is feature extractor, which involves a convolutional layer and pooling layers, and automatically learn the characteristics from raw data. Then fully connected layer executes the classification from the first part relying on the learned attributes. The input layer is composed of the individual values that denote the smallest unit of input whereas the output layer comprises as many outputs as categories exist in the particular classification problem. The convolutional layer performs an activity of convolution to limited localized regions through transforming a layer to the preceding layer. This is used specifically for extracting the feature from the raw data. Pooling layers are employed after convolutional layers, that minimizes the amount of parameters associated and minimize computational complexity The fully connected layer then employs learned attributes for classification. Input layers represent individual input values, while output layers correspond to classification categories. This architecture efficiently processes vast datasets, enabling nuanced pattern recognition and classification across diverse domains.

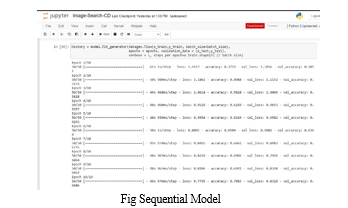
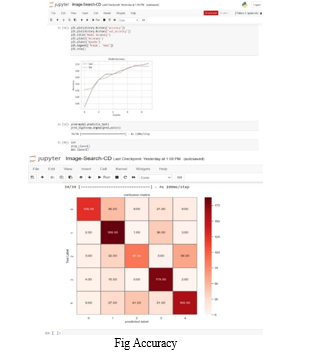
???????XII. FUTURE WORK
In future work we will further improve our loss function and try various databases in our experiments and we may explore about the relation between our work and those involved with non-photorealistic rendering.
Optimizing the algorithms and techniques for real-time implementation to process images efficiently and promptly, which is particularly crucial for applications requiring rapid image processing, such as video processing or real-time monitoring systems. Enhancing feature extraction methods by incorporating deep learning-based feature extraction techniques or exploring domain-specific feature extraction algorithms could potentially improve the extraction of relevant information from images.Implementing dynamic histogram equalization methods that adaptively adjust the histogram based on local image characteristics could potentially enhance the contrast and dynamic range of images more effectively.
Conclusion
In this paper we propose an end-to-end fully convolutional network in order to directly model the complex nonlinear mapping between face photos and sketches. From the experiments we find out that fully convolutional network is a powerful tool which can handle this difficult problem while providing a pixel-wise prediction both effectively and efficiently. Accuracy Measurement Using - model.fit_generator : 1) Analysis of model performance based on testing results, including strengths, weaknesses, and potential areas for improvement. 2) This analysis informs future iterations of model development and optimization.
References
[1] D. V. Lindberg and H. K. H. Lee, “Optimization under constraints by applying an asymmetric entropy measure,” J. Comput. Graph. Statist., vol. 24, no. 2, pp. 379–393, Jun. 2015, doi: 10.1080/10618600.2014.901225. [2] B. Rieder, Engines of Order: A Mechanology of Algorithmic Techniques. Amsterdam, Netherlands: Amsterdam Univ. Press, 2020. [3] I. Boglaev, “A numerical method for solving nonlinear integro-differential equations of Fredholm type,” J. Comput. Math., vol. 34, no. 3, pp. 262–284, May 2016, doi: 10.4208/jcm.1512-m2015-0241. [4] Hayato Arai,Yuto Onga,Kumpei Ikuta,Yusuke Chayama,Hitoshi Iyatomi,Kenichi Oishi Disease-Oriented Image Embedding With Pseudo-Scanner Standardization for Content-Based Image Retrieval on 3D Brain MRI IEEE Access, 2021 [5] Luqing Luo,Zhi-Xin Yang,Lulu Tang,Kun Zhang An ELM-Embedded Deep Learning Based Intelligent Recognition System for Computer Numeric Control Machine Tools IEEE Access, 2020 [6] Mohamad M. Al Rahhal,Yakoub Bazi,Norah A. Alsharif,Laila Bashmal,Naif Alajlan,Farid Melgani Multilanguage Transformer for Improved Text to Remote Sensing Image Retrieval IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2022 [7] Jahanzaib Latif,Chuangbai Xiao,Shanshan Tu,Sadaqat Ur Rehman,Azhar Imran,Anas Bilal Implementation and Use of Disease Diagnosis Systems for Electronic Medical Records Based on Machine Learning: A Complete Review IEEE Access, 2020 [8] Tengfei Wu,Lu Leng,Muhammad Khurram Khan,Farrukh Aslam Khan Palmprint-Palmvein Fusion Recognition Based on Deep Hashing Network IEEE Access, 2021 [9] Zhenghang Yuan,Lichao Mou,Qi Wang,Xiao Xiang Zhu From Easy to Hard: Learning Language-Guided Curriculum for Visual Question Answering on Remote Sensing Data IEEE Transactions on Geoscience and Remote Sensing, 2022 [10] Arka Ujjal Dey,Ernest Valveny,Gaurav Harit EKTVQA: Generalized Use of External Knowledge to Empower Scene Text in Text-VQA IEEE Access, 2022 [11] Naushad Varish,Arup Kumar Pal,Rosilah Hassan,Mohammad Kamrul Hasan,Asif Khan,Nikhat Parveen,Debrup Banerjee,Vidyullatha Pellakuri,Amin Ul Haqis,Imran Memon Image Retrieval Scheme Using Quantized Bins of Color Image Components and Adaptive [12] Ali Ahmed,Sharaf J. Malebary Query Expansion Based on Top-Ranked Images for Content-Based Medical Image Retrieval IEEE Access, 2020 [13] Khawaja Tehseen Ahmed,Humaira Afzal,Muhammad Rafiq Mufti,Arif Mehmood,Gyu Sang Choi Deep Image Sensing and Retrieval Using Suppression, Scale Spacing and Division, Interpolation and Spatial Color Coordinates With Bag of Words for Large and Complex Datasets IEEE Access, 2020 [14] N. F. Soliman, M. Khalil, A. D. Algarni, S. Ismail, R. Marzouk and W. El-Shafai, Efficient HEVC steganography approach based on audio compression and encryption in QFFT domain for secure multimedia communication, Multimedia Tools Appl., vol. 80, no. 3, pp. 4789-4823, 2020. [15] W. El-Shafai, Joint adaptive pre-processing resilience and post-processing concealment schemes for 3D video transmission, 3D Res., vol. 6, no. 1, pp. 1-13, Mar. 2015. [16] K. Seetharaman and M. Kamarasan, Statistical framework for image retrieval based on multiresolution features and similarity method, Multimedia Tools Appl., vol. 73, pp. 1943-1962, Dec. 2014. [17] X.-Y. Tong, G.-S. Xia, F. Hu, Y. Zhong, M. Datcu and L. Zhang, Exploiting deep features for remote sensing image retrieval: A systematic investigation, IEEE Trans. Big Data, vol. 6, no. 3, pp. 507-521, Sep. 2020.
Copyright
Copyright © 2024 Dr K Sujatha, Koulik Ghsoh , Aneesh Anand. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET61734
Publish Date : 2024-05-07
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online