

Ijraset Journal For Research in Applied Science and Engineering Technology
Domain Specific Adaptation of an Open-Source LLM (Large Language Model)
Authors: Ms. Shraddha Mankar , Kshitij Kamble , Rohan Pathak, Atharva Kadam, Atharva Gogawale
DOI Link: https://doi.org/10.22214/ijraset.2024.58734
Certificate: View Certificate
Abstract
This research project delves into the investigation of the integration of Large Language Models (LLMs), exemplified by models such as ChatGPT, within the realm of domain-specific conversation applications, with a focus on discerning their substantive impact on user interactions within specialized contexts. The abstract conscientiously recognizes the rapid strides in LLM development and their intrinsic potential to augment domain-specific applications. A meticulous literature review is conducted to discern and expound upon prevailing trends and findings in LLM application, establishing a robust foundation for the ensuing methodology of the study. The research employs a thorough and comprehensive implementation strategy, strategically addressing the multifaceted challenges encountered during the intricate process of LLM integration, while simultaneously harnessing performance metrics and soliciting user feedback to ensure a nuanced and holistic assessment. The ensuing discussion section meticulously scrutinizes the obtained results, thereby providing profound insights into the far-reaching implications of LLM integration in domain-specific settings, thereby making a notable contribution to the burgeoning field of conversational AI. In summary, this research not only elucidates the practical nuances of LLM utilization but also delineates potential avenues for further exploration and development within this dynamic field.
Introduction
I. INTRODUCTION
In the contemporary landscape marked by the ascendancy of advanced natural language processing, the pivotal role played by Large Language Models (LLMs) comes into sharp relief as these transformative tools revolutionize the intricate fabric of conversational artificial intelligence. This multifaceted and ambitious research project embarks on a comprehensive and nuanced exploration into the expansive application of LLMs, with notable examples such as ChatGPT, operating within the intricate domain-specific context of conversation applications. As communication technologies undergo perpetual evolution, the discernible potential of LLMs not only to augment but fundamentally transform user engagement and comprehension becomes increasingly manifest, underscoring their significance in the current technological milieu. Positioned at the intersection of cutting-edge technology and user experience enhancement, this research aims to delve deeply into the intricate process of integrating LLMs into the domain-specific landscape of conversational applications, undertaking a meticulous evaluation and thorough scrutiny of their discernible impact on the dynamics of user interactions within these specialized contexts. Through a strategic harnessing of the formidable and sophisticated capabilities inherent in these models, the research aspires not only to unravel but also to elucidate novel and groundbreaking insights into the intricacies of specialized conversations, thereby making a significant and enduring contribution to the broader discourse surrounding the pragmatic implementation of LLMs in a diverse array of real-world applications. This in-depth investigation is poised not merely to illuminate but to magnify the transformative possibilities that LLMs hold, propelling the refinement and advancement of domain-specific conversational experiences to unprecedented heights, thus shaping the trajectory of conversational AI and technological innovation in ways that were previously unexplored.
II. LITERATURE REVIEW
A. Llama 2: Open Foundation and Fine-Tuned Chat Models
The research paper titled "Llama 2: Open Foundation and Fine-Tuned Chat Models" delves into the exploration and evaluation of LLama 2 as a Large Language Model (LLM), emphasizing its remarkable power and versatility. The paper sheds light on the model's strengths, elucidating its robust capabilities, and highlights the incorporation of Reinforcement Learning with Human Feedback (RLHF) in the training process, contributing to the model's refinement. However, the research also identifies certain limitations, including the potential for non-factual generation, such as unqualified advice, and a tendency to hallucinate after prolonged conversations. Additionally, the model's concentration on English-language data is acknowledged as a limitation. This comprehensive overview provides a glimpse into the advancements and challenges presented by LLama 2, offering valuable insights into its capabilities and areas for potential improvement.
B. Cramming: Training a language model on a single GPU in one day
The research paper, titled "Cramming: Training a Language Model on a Single GPU in One Day," delves into the challenging endeavor of training transformer models with limited computational resources. The observations highlight the difficulty and suboptimal outcomes associated with such constrained training efforts. The focus is on the concept of "Cramming," exploring the constraints and hurdles involved in training language models within the limitations of a single GPU and a compressed one-day timeframe. This concise overview sets the tone for an examination of the challenges inherent in efficient language model training with constrained compute capacity.
???????C. QLoRA: Efficient Finetuning of Quantized LLMs
The research paper titled "QLoRA: Efficient Fine-tuning of Quantized LLMs" introduces a method for the fine-tuning of Quantized Large Language Models (LLMs) with notable advantages. Notably, the approach allows for fine-tuning on significantly reduced VRAM, minimizing computational resource requirements without a substantial loss in performance. However, the research identifies a limitation as quantized, fine-tuned models are unable to achieve the performance levels of their non-quantized counterparts. Additionally, the paper acknowledges the existence of alternative methods, such as Parameter Efficient Fine Tuning (PEFT), indicating a diverse landscape of approaches in the realm of efficient fine-tuning for language models.
III. METHODOLOGY
A. Architecture
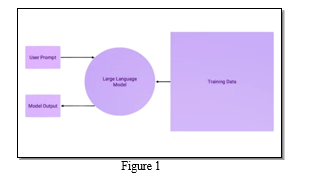
- User Prompt: User prompts within the cybersecurity domain might involve queries related to specific threats, vulnerabilities, or the overall security posture of a system. Users may seek information on recent cyber attacks, emerging trends, or guidance on mitigating potential risks. The language model needs to be attuned to the terminology and intricacies of cybersecurity to provide accurate and relevant responses.
- Training Data: Given that the training data predominantly comprises highly detailed Threat Intelligence security reports, the language model gains a deep understanding of the nuances and complexities inherent in the cybersecurity landscape. The dataset likely includes information on malware analysis, intrusion detection, threat actors, and various attack vectors. Continuous updates to this dataset are crucial to keep the model abreast of the rapidly evolving cybersecurity threats and technologies.
- Large Language Model (LLM): The LLM serves as a pivotal component in your architecture, acting as the core engine for processing and generating responses based on user prompts within the cybersecurity domain. Trained on the highly detailed Threat Intelligence security reports, the LLM possesses a profound understanding of the intricacies of cybersecurity language and concepts. Its sophisticated algorithms and neural network architecture enable it to analyze user prompts and produce coherent, contextually relevant summaries. The LLM, being the heart of the system, is responsible for translating the acquired knowledge from the extensive training data into actionable and insightful information for users.
- Model Output: The model output, in this context, would generate concise and informative summaries of the complex Threat Intelligence reports. It should distill key insights, highlight critical vulnerabilities, and present actionable information for cybersecurity professionals. The output needs to convey a comprehensive understanding of the security reports, ensuring that users receive valuable and timely information to inform their decision-making processes.
B. Data Flow Diagram
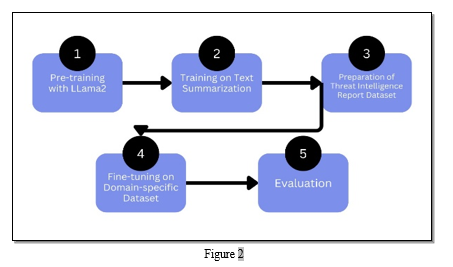
The project methodology involves a systematic approach to harnessing the potential of pre-trained Large Language Models (LLMs), specifically LLama2, for the critical task of text summarization within the realm of cybersecurity threat intelligence reports. The outlined steps are as follows:
- Pre-training with LLama2: Acquiring a pre-trained Large Language Model (LLM), in this case, LLama2, serves as the foundational step. Pre-training involves exposing the model to a vast corpus of diverse textual data, enabling it to learn general language patterns, grammar, and context. This initial phase provides the LLM with a broad understanding of language structures, allowing it to capture the intricacies of various text types.
- Training on Text Summarization: Once pre-trained, the LLM is directed towards specialized training for text summarization. This involves fine-tuning the model using datasets specifically designed for summarization tasks. The objective is to adapt the LLM to the unique challenges posed by summarizing lengthy and complex texts, with a focus on distilling essential information accurately and concisely.
- Preparation of Threat Intelligence Report Dataset: A crucial aspect of the methodology is the curation of a comprehensive dataset tailored for threat intelligence reports. This dataset mirrors the diversity and complexity of real-world cybersecurity narratives, encompassing various threat scenarios, language structures, and contextual nuances. The prepared dataset becomes the bedrock for training the LLM to excel in summarizing content specific to the cybersecurity domain.
- Fine-tuning on Domain-specific Dataset: Fine-tune the LLM using the prepared threat intelligence report dataset. This process involves exposing the model to the nuances and intricacies of cybersecurity language, ensuring that the LLM becomes adept at extracting relevant and actionable insights from domain-specific content.
- Evaluation: Rigorously evaluate the fine-tuned model to assess its performance. Metrics such as precision, recall, and F1 score may be employed to quantify the model's effectiveness in generating concise and accurate summaries of cybersecurity threat intelligence reports. This step is crucial in gauging the model's readiness for real-world applications and identifying areas for further refinement.
IV. EXPECTED OUTCOME
In response to the growing complexity of cyber threats, this project endeavors to create a specialized language model adept at summarizing Threat Intelligence reports and articles. As the digital landscape continues to evolve, the need for efficient analysis and comprehension of extensive threat-related information becomes increasingly paramount. Recognizing this, the project aims to address the challenges posed by information overload in the cybersecurity domain by developing a tailored solution that streamlines the process of extracting key insights from voluminous reports. This specialized language model is anticipated to serve as a pivotal tool, facilitating a more expeditious and insightful approach to threat analysis.
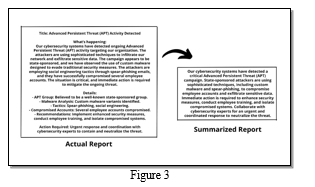
The envisioned output of this initiative is a language model that not only meets but exceeds expectations in its ability to automate the summarization of Threat Intelligence materials. The benefits are twofold: firstly, the acceleration of threat analysis through the model's capacity to swiftly distill pertinent information, and secondly, the consequential improvement in decision-making processes. By efficiently extracting and presenting crucial insights from lengthy reports, this language model is poised to become an invaluable asset to the cybersecurity community. The impact is significant, offering professionals a powerful tool to fortify defense mechanisms against the dynamic and evolving landscape of cyber threats, ultimately contributing to a more resilient and proactive cybersecurity posture.
V. FUTURE SCOPE
The future scope for the project holds promising avenues for expansion and enhancement. Firstly, there is potential for continual refinement and optimization of the specialized language model through ongoing updates and iterations. Continuous training with updated Threat Intelligence data and incorporating user feedback can enhance the model's summarization capabilities, ensuring it remains effective in addressing emerging trends and threat landscapes.
Additionally, the project could explore the integration of advanced natural language processing (NLP) techniques, including sentiment analysis and entity recognition, to provide a more comprehensive understanding of threat reports. This expansion could enable the model to not only summarize information but also discern the sentiment and identify key entities involved in the reported threats, adding a layer of contextual richness to the summaries.
Collaboration with cybersecurity experts and organizations could offer opportunities for real-world testing and validation, ensuring the language model aligns with the practical needs of the cybersecurity community. Moreover, considering the global nature of cyber threats, multilingual support could be a valuable future addition, allowing the model to analyze and summarize Threat Intelligence reports in various languages.
Finally, exploring potential integrations with existing cybersecurity platforms or tools would be beneficial, enabling seamless incorporation of the language model into existing workflows and enhancing its usability for cybersecurity professionals. The continuous evolution of the cybersecurity landscape ensures a dynamic future scope for the project, presenting opportunities for innovation and adaptation to meet evolving challenges in the realm of threat intelligence.
Conclusion
In conclusion, this project endeavors to revolutionize cybersecurity threat intelligence analysis by harnessing the advanced capabilities of LLama2-7B for automated text summarization. By integrating state-of-the-art language models, we aim to streamline the often time-intensive process of distilling actionable insights from voluminous threat intelligence reports. The project\'s methodology encompasses pre-training, domain-specific fine-tuning, and rigorous evaluation, ensuring the tool\'s adaptability and effectiveness. Through this initiative, we aspire to empower cybersecurity professionals with a specialized and efficient summarization tool, enhancing their ability to swiftly extract critical information from complex narratives. As the cybersecurity landscape continues to evolve, this project represents a significant stride towards optimizing the utilization of advanced language models for real-world cybersecurity applications.
Copyright
Copyright © 2024 Ms. Shraddha Mankar , Kshitij Kamble , Rohan Pathak, Atharva Kadam, Atharva Gogawale . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET58734
Publish Date : 2024-03-02
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online