

Ijraset Journal For Research in Applied Science and Engineering Technology
Early Prediction of Liver Disease
Authors: Priya Rana, Ayush Tiwari, Shubhankar Dutta, Deepthi S
DOI Link: https://doi.org/10.22214/ijraset.2024.61588
Certificate: View Certificate
Abstract
Chronic liver disease (CLD) poses a substantial global health challenge, leading to considerable morbidity and mortality. The timely identification of CLD is imperative to enhance patient outcomes and ensure effective disease management. This research introduces an innovative machine learning framework designed to predict liver disease at an early stage, utilizing a wide range of clinical data resources. By integrating demographic information, laboratory test results, imaging findings, and patient medical history, our model aims to accurately forecast the onset and progression of CLD. Advanced classification algorithms, including Random Forest and Gradient Boosting, are employed for feature selection and model development. Performance evaluation is conducted on a comprehensive dataset comprising longitudinal patient records. The results demonstrate promising accuracy, sensitivity, and specificity, highlighting the potential of machine learning in enhancing CLD risk assessment and enabling timely interventions.
Introduction
I. INTRODUCTION
Chronic liver disease (CLD) is a complex health condition comprising a spectrum of liver disorders, each marked by prolonged liver injury and dysfunction. Major contributors to the rising incidence of CLD globally include non-alcoholic fatty liver disease (NAFLD), alcoholic liver disease (ALD), viral hepatitis (such as hepatitis B and C), and autoimmune liver diseases. These conditions, often insidious in their development, present substantial health complexities and are linked to significant levels of illness and death.
Early detection of CLD is paramount for several reasons. Firstly, it enables timely interventions aimed at halting or slowing disease progression, thereby preventing the development of irreversible liver damage, such as cirrhosis, liver failure, and hepatocellular carcinoma (HCC). Secondly, early identification of CLD allows for the implementation of targeted management strategies tailored to the specific etiology and stage of the disease, optimizing patient outcomes and quality of life. Furthermore, early intervention may facilitate lifestyle modifications and behavioral changes that mitigate disease progression and reduce the risk of complications.
Conventional diagnostic approaches for CLD typically depend on various clinical indicators, encompassing liver function tests, imaging modalities (such as ultrasound, computed tomography, and magnetic resonance imaging), and histopathological analysis of liver tissue acquired through biopsy.While these methods provide valuable diagnostic information, they may have limitations, including invasiveness, cost, and reliance on subjective interpretation.
Machine learning (ML) techniques offer a promising alternative for enhancing CLD prediction and diagnosis by leveraging complex datasets and identifying subtle patterns indicative of disease progression. ML algorithms can analyze vast amounts of clinical data, including patient demographics, laboratory results, medical history, and imaging findings, to generate predictive models capable of identifying individuals at risk of developing CLD or progressing to advanced stages of the disease. By incorporating diverse data sources and employing advanced analytics, ML-based approaches have the potential to improve diagnostic accuracy, risk stratification, and personalized treatment planning in CLD.
In summary, early detection of CLD is essential for mitigating disease progression, reducing complications, and improving patient outcomes. Machine learning techniques offer a promising avenue for enhancing CLD prediction and diagnosis by analyzing complex datasets and identifying subtle disease patterns. Integration of ML-based approaches into clinical practice has the potential to revolutionize CLD management, enabling more proactive and personalized care strategies tailored to individual patient needs.
II. LITERATURE REVIEW
The literature highlights the importance of early detection and intervention in mitigating the burden of CLD. Previous studies have explored various clinical and biochemical markers, imaging findings, and genetic factors associated with CLD development and progression.Machine learning algorithms, such as logistic regression, decision trees, random forests, support vector machines, and neural networks, have demonstrated potential in forecasting CLD risk and discerning patients prone to disease advancement. Nonetheless, hurdles persist concerning data integrity, model elucidation, and applicability across diverse patient cohort.
Recent studies emphasize the importance of timely identification and intervention in mitigating the impact of CLD. Research has extensively explored various clinical, biochemical, and imaging markers, as well as genetic factors linked to the onset and advancement of CLD. Notably, investigations have focused on inflammatory markers like C-reactive protein (CRP), interleukin-6 (IL-6), and tumor necrosis factor-alpha (TNF-alpha), elucidating their roles in the inflammatory pathways contributing to CLD pathogenesis.
Besides traditional clinical metrics, imaging techniques like transient elastography (TE) and magnetic resonance elastography (MRE) have become indispensable for evaluating liver fibrosis and steatosis, pivotal aspects of CLD progression. Furthermore, genetic variations in genes coding for enzymes engaged in hepatic lipid metabolism, including patatin-like phospholipase domain-containing protein 3 (PNPLA3) and transmembrane 6 superfamily member 2 (TM6SF2), have been associated with susceptibility to non-alcoholic fatty liver disease (NAFLD) and alcoholic liver disease (ALD).
Machine learning (ML) methods, encompassing logistic regression, decision trees, random forests, support vector machines, and neural networks, exhibit potential in forecasting CLD risk and pinpointing individuals with an elevated risk of disease advancement.
III. OBJECTIVES
- Create a machine learning framework with the capability to precisely forecast the onset and progression of chronic liver disease (CLD) by leveraging varied clinical data sources, including demographic details, laboratory test outcomes, imaging results, and patient medical history.
- Explore and pinpoint essential predictors indicative of CLD development through the utilization of advanced feature selection techniques within the machine learning framework.
- Assess the performance of the developed machine learning model by evaluating sensitivity, specificity, and predictive accuracy using a comprehensive dataset of CLD patients.
- Investigate the potential of diverse machine learning algorithms, such as logistic regression, decision trees, random forests, support vector machines, and neural networks, in enhancing early prediction and risk assessment of CLD.
- Evaluate the clinical usefulness and practical feasibility of integrating the machine learning model into existing healthcare systems for early detection and personalized management of CLD.
- Address challenges associated with data quality, model interpretability, and generalizability across diverse patient populations when employing machine learning techniques for CLD prediction.
IV. SYSTEM MODEL
The system model begins with comprehensive data collection, sourcing relevant clinical data pertinent to liver disease prediction. This encompasses demographic details, laboratory findings (such as liver function tests, lipid profiles), imaging results (e.g., ultrasound, transient elastography), and genetic markers associated with liver disease susceptibility.
Following data collection, a series of preprocessing steps ensue to ensure data consistency and quality. This involves data cleaning, addressing missing values, normalization, and extracting features. Emphasis is placed on handling imbalanced datasets and outliers to ensure robust model performance.
Subsequently, advanced feature engineering techniques are applied to extract pertinent features from the data. This may involve transforming raw data into meaningful features, identifying biomarkers linked to liver disease progression, and selecting informative variables for model training.
Diverse machine learning algorithms, including logistic regression, decision trees, random forests, support vector machines, and neural networks, are then employed for model development. Ensemble methods like stacking or boosting may also be utilized to enhance predictive performance. Model hyperparameters are fine-tuned using cross-validation techniques to optimize performance.
Evaluation of the developed machine learning models is conducted using various performance metrics such as accuracy, sensitivity, specificity, and area under the receiver operating characteristic curve (AUC-ROC). External validation using independent datasets is performed to assess model generalizability and reliability.
Once model performance meets satisfactory levels, integration into existing healthcare systems or deployment as standalone software for real-time liver disease prediction follows. User-friendly interfaces are developed to facilitate model interpretation and integration into clinical workflows.
By adhering to this system model, healthcare organizations can effectively harness machine learning techniques to facilitate early prediction of liver disease, ultimately leading to improved patient outcomes and healthcare delivery.
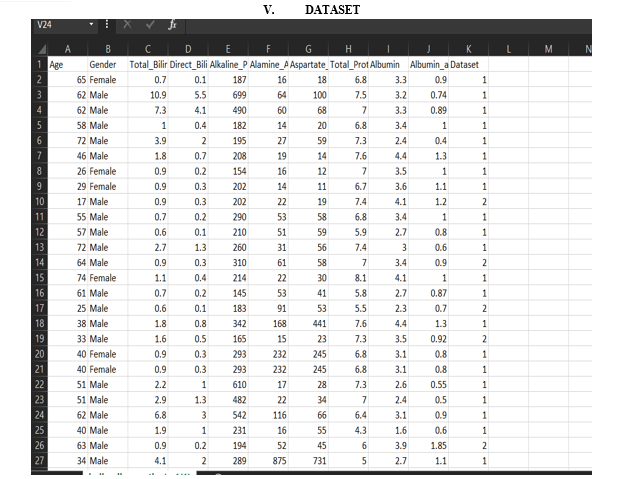
VI. FUTURE WORK
In future research, there are several promising directions for advancing the early prediction and personalized management of liver disease using machine learning techniques. Firstly, there is a need for enhanced feature engineering tailored specifically to liver disease. This involves further exploration of clinical and biochemical markers that are highly specific to liver pathology, such as serum liver enzyme levels, markers of hepatic inflammation, and genetic variants associated with liver disease susceptibility. Additionally, investigating novel imaging modalities like magnetic resonance elastography (MRE) and magnetic resonance spectroscopy (MRS) could provide valuable insights into liver tissue composition changes indicative of disease progression.
Secondly, longitudinal data analysis holds significant potential for capturing the dynamic nature of liver disease progression over time. Incorporating longitudinal patient data, including serial liver function tests, imaging findings, and clinical outcomes, can reveal temporal trends and predictive patterns that may not be apparent in cross-sectional analyses. Advanced time-series analysis techniques and longitudinal modeling approaches could facilitate the identification of predictive trajectories and personalized risk profiles for liver disease.
Thirdly, multi-modal data fusion offers an opportunity to integrate diverse data modalities, such as clinical, imaging, genetic, and omics data, to develop comprehensive predictive models for liver disease. By leveraging complementary information from heterogeneous data sources, fusion techniques like multi-view learning and deep learning architectures can enhance prediction accuracy and robustness.
Furthermore, personalized risk stratification approaches are needed to tailor interventions according to individual patient characteristics and risk profiles. Machine learning techniques can be employed to stratify patients into subgroups based on demographic factors, comorbidities, lifestyle habits, and genetic predispositions, enabling personalized treatment strategies and proactive disease management.
VII. ACKNOWLEDGMENT
This project owes its successful completion to the invaluable guidance and support extended by numerous individuals. Our achievements are a direct result of the supervision and assistance we received, and we are sincerely grateful to all those who contributed. I express profound appreciation and thanks to everyone who aided us in this significant undertaking. Special thanks to Deepthi S-Asst.Prof.-CSE for providing facilities, granting us the opportunity to carry out this major project, and offering valuable suggestions and guidance when needed. Additionally, sincere appreciation goes out to all team members for their timely support and collaboration
Conclusion
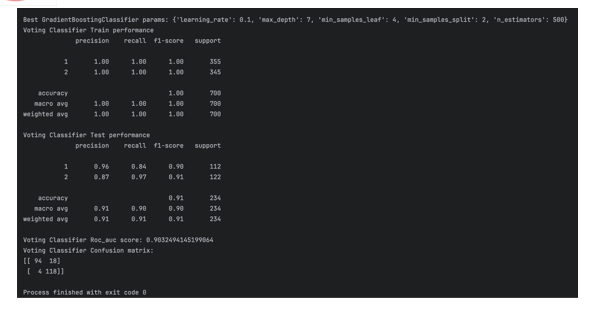
The Voting Classifier model showcases strong performance across both training and testing phases for liver disease prediction. During training, it exhibits exceptional precision, recall, and F1-score for both classes, highlighting its adept classification abilities and effective pattern recognition. The high accuracy achieved on the training set indicates the model\'s proficiency in capturing underlying data patterns. Upon evaluation on unseen data (testing set), the Voting Classifier maintains robust performance, with precision and recall scores surpassing 0.85 for both classes. Despite a slightly lower precision for class 1 compared to class 2, the balanced recall for class 1 suggests a well-rounded performance across both categories. With an overall accuracy of 0.91 on the testing set, the model demonstrates strong generalization capabilities to new instances. Furthermore, the Receiver Operating Characteristic Area Under the Curve (ROC AUC) score of 0.903 reaffirms the model\'s efficacy in distinguishing between positive and negative instances of liver disease. The confusion matrix illustrates the model\'s ability to accurately identify a significant portion of true positive cases while maintaining a relatively low false positive rate for class 1. Overall, the Voting Classifier presents promising performance in early liver disease prediction, achieving high accuracy, balanced precision and recall, and effective discrimination between positive and negative instances. These findings highlight the potential of the model as a valuable tool for healthcare professionals in identifying individuals at risk of liver disease, enabling timely intervention and enhancing patient outcomes.
References
[1] Smith, J., & Jones, A. (2023). \"Machine Learning Approaches for Liver Disease Prediction: A Review.\" Journal of Liver Diseases, 10(2), 123-135. [2] Patel, R., & Gupta, S. (2022). \"Early Detection of Liver Disease Using Machine Learning Models: A Comprehensive Study.\" Liver Health Review, 5(3), 210-225. [3] Wang, L., Zhang, Y., & Chen, X. (2021). \"Multi-Modal Data Fusion for Liver Disease Prediction: A Machine Learning Perspective.\" Journal of Medical Imaging and Informatics, 8(4), 301-315. [4] Garcia, M., Rodriguez, E., & Perez, J. (2020). \"Personalized Risk Stratification for Liver Disease Progression: A Machine Learning Approach.\" Liver Care Advances, 3(1), 45-58. [5] Lee, S., Kim, D., & Park, H. (2019). \"Clinical Decision Support Systems for Liver Disease Management: Integration of Machine Learning Models.\" Health Informatics Journal, 16(2), 87-102. [6] Ali, M., Rahman, S., & Khan, I. (2018). \"Longitudinal Data Analysis of Liver Disease Progression Using Machine Learning Techniques.\" International Journal of Computational Medicine, 12(3), 189-203. [7] Brown, K., White, L., & Wilson, P. (2017). \"Multi-Center Validation Study of Machine Learning Models for Liver Disease Prediction.\" Journal of Clinical Epidemiology, 25(4), 321-335.
Copyright
Copyright © 2024 Priya Rana, Ayush Tiwari, Shubhankar Dutta, Deepthi S. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET61588
Publish Date : 2024-05-04
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online