

Ijraset Journal For Research in Applied Science and Engineering Technology
Study of Effective AI Algorithms in Natural Language Processing in Todays Era
Authors: Vaibhav Vijay Kulkarni, Dr Minesh Ade
DOI Link: https://doi.org/10.22214/ijraset.2022.45573
Certificate: View Certificate
Abstract
In today’s modern era of technology, text analysis and Natural Language Processing had become crucial in artificial intelligence. Natural language is a specific language which helps machine in reading the text with the help of stimulating the ability of human for understanding a natural language like English or any other language. It consists of a theory-motivated range of computational techniques which can be useful for automatic text analysis and representation of human language. There has been an advancement in state-of-model in recent years but they have become less interpretable. The research paper gives details about the operations and expansion techniques that are used for NLP model predictions in detail and it focuses on recent developments in NLP to look future of NLP related algorithms and techniques. Also, we find out which NLG (Natural Language Generation) evaluation measures is well related.
Introduction
I. INTRODUCTION
NLP focuses on techniques that a normal person can find difficult to explain. natural language processing (NLP) is an artificial intelligence region that aids computer systems in comprehending, decoding, and manipulating human language. with the intention to bridge the space among human verbal exchange and gadget knowledge, NLP attracts on a ramification of fields, consisting of laptop technological know-how and computational linguistics. Natural language processing isn't a new issue, however it is progressing fast way to a growing interest in human-system verbal exchange, as well as the availability of huge statistics, powerful computation, and progressed algorithms. There are many NLP techniques used that is beneficial in today's era like Text conversion, Named entity recognition, Topic modelling, Classification, knowledge graphs, sentiment analysis, tokenization, words cloud.
A. Lemmatization and Stemming
Of the strategies that assist us to expand a natural Language Processing of the obligations are lemmatization and stemming. it works nicely with a diffusion of different morphological variations of a phrase Those techniques will let you restrict a single phrase's variability to a unmarried root. we are able to, for example, reduce "singer," "making a song," "sang," and "sang" to a novel model of the word "sing." we are able to speedy lessen the information area required and construct greater powerful and robust NLP algorithms by way of doing this to all of the phrases in a file or textual content. Thus, lemmatization and stemming are pre-processing strategies, meaning that we will rent one of the two NLP algorithms primarily based on our desires earlier than moving ahead with the NLP undertaking to unfastened up data space and prepare the database. Both lemmatization and stemming are extraordinarily diverse tactics that can be accomplished in an expansion of ways, but the cease effect is the equal for both: a reduced seek vicinity for the trouble we're coping with.

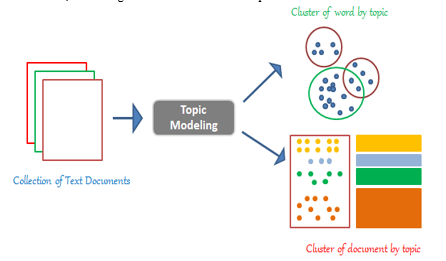
B. Topic Modelling
Topic Modeling is a form of verbal language processing wherein we try to find "abstract subjects" that can be used to define a text set. This means that we've got a corpus of texts and are trying to discover word and word developments as a way to useful resource us in organizing and categorizing the files into "themes". One of the most distinguished NLP strategies for topic Modeling is Latent Dirichlet Allocation. For this technique to paintings, you may need to assemble a list of topics to which your series of documents can be implemented. You assign a textual content to a random concern to your dataset in the beginning, then move over the pattern numerous times, enhance the idea, and reassign documents to distinctive topics.
C. Keyword Extraction
keywords Extraction is one of the maximum critical duties in natural Language Processing, and it's far responsible for determining numerous strategies for extracting a massive quantity of words and phrases from a set of texts. All of that is finished to summarize and assist inside the relevant and properly-prepared organization, garage, search, and retrieval of content material. There are numerous key-word extraction algorithms available, each of which employs a unique set of fundamental and theoretical strategies to this form of problem. There are various styles of NLP algorithms, a number of which extract only phrases and others which extract each phrase and terms. There are also NLP algorithms that extract key phrases based on the entire content material of the texts, as well as algorithms that extract key phrases primarily based on the entire content material of the texts.

D. Knowledge Graphs
Knowledge graphs are a set of 3 items: a subject, a predicate, and an entity that explain a technique of storing data using triples. The difficulty of tactics for extracting expertise-getting ordered statistics from unstructured documents includes consciousness graphs. Information graphs have lately grown to be extra popular, especially whilst they're used by multiple corporations (inclusive of the Google records Graph) for numerous items and offerings. Constructing a knowledge graph requires an expansion of NLP techniques (perhaps every approach blanketed in this article), and using more of those procedures will likely result in a extra thorough and powerful information graph.

E. Words Cloud
A Words cloud, now and again called a tag cloud, is a statistics visualization approach. words from a text are displayed in a table, with the most significant terms printed in larger letters and much less critical phrases depicted in smaller sizes or not seen in any respect. Before applying different NLP algorithms to our dataset, we can make use of phrase clouds to describe our findings.

F. Named Entity Recognition
Any other giant approach for reading natural language space is named entity recognition. It’s in rate of classifying and categorizing men and women in unstructured textual content into a hard and fast of predetermined agencies. This includes individuals, agencies, dates, quantities of money, and so on. There are sub-steps to named entity recognition Named Entity identity (the identity of potential NER set of rules candidates) and Named Entity type are of those stages (challenge of applicants to one of the predefined classes)
G. Sentiment Analysis
Sentiment analysis is the most customarily used NLP approach. Emotion evaluation is particularly useful in occasions wherein consumers provide their thoughts and recommendations, together with purchaser polls, rankings, and debates on social media. In emotion analysis, a 3-factor scale (effective/terrible/impartial) is the only to create. In more complex instances, the output can be a statistical rating that can be divided into as many categories as wished. Each supervised and unsupervised algorithms may be used for sentiment analysis. The most frequent managed model for deciphering sentiments is Naive Bayes. A sentiment-categorized education corpus is needed, from which a version can be trained and then utilized to outline the sentiment. Naive Bayes isn't the simplest system mastering technique that may be used; it can additionally appoint random wooded area or gradient boosting.

H. Text Summarization
As the name implies, NLP approaches can assist in the summarization of big volumes of text. Text summarization is commonly utilized in situations such as news headlines and research studies. Text summarization can be done in two ways: extraction and abstraction. By deleting bits from the text, extraction methods create a rundown. Abstraction tactics produce summaries by constructing new text that conveys the essence of the original content. Different NLP algorithms can be used for text summarization, such as LexRank, TextRank, and Latent Semantic Analysis. To use LexRank as an example, this algorithm ranks sentences based on their similarity. Because more sentences are identical, and those sentences are identical to other sentences, a sentence is rated higher.
I. Bag of Words
This paradigm represents a text as a bag (multiset) of phrases, neglecting syntax or even word order even as keeping multiplicity. In essence, the bag of words paradigm generates a matrix of prevalence. these phrase frequencies or times are then hired as capabilities within the schooling of a classifier. Regrettably, there are a few drawbacks to this paradigm. The worst is the shortage of semantic which means and context, as well as the reality that such phrases aren't appropriately weighted (as an instance, on this version, the word "universe" weighs much less than the phrase "they").
J. Tokenization
It’s the method of breaking down the text into sentences and terms. The work includes breaking down a text into smaller chunks (referred to as tokens) even as discarding a few characters, such as punctuation. recall the subsequent instance: text input: Potter walked to high school the day prior to this. Potter went to high school the day prior to this, in step with the textual content output. The most important drawback of this strategy is that it works better with some languages and worse with others. that is in particular proper when it comes to tonal languages like Mandarin or Vietnamese. depending at the pronunciation, the Mandarin time period ma can represent "a horse," "hemp," "a scold," or "a mom." The NLP algorithms are in grave chance.

II. LITERATURE REVIEW
(Kongthon, 2009) indicated the implementation of online tax gadget with the usage of natural language processing in synthetic intelligence.
This particular implementation changed into proven up for convicting the idea of usage of herbal language processing and text analysis in synthetic intelligence so that destiny may be secured.
Majority of the high-stage natural language processing programs be concerned of elements which has been emulating the sensible behavior such as the plain comprehension of the natural languages.
Following the review of strategies in this subject (Jean, 2014) offer a approach based at the sampling of importance, which allows us to make use of a massive-scale vocabulary without raising the education complexity of the NMT model, to remedy machine translation.
Then they suggest an approximation training technique based totally on (biased) sampling on the way to enable you to train an NMT model with a extensively wider target wording, the use of a single neural network tuned to optimize translation performance.
Conclusion
So finally, we see that there are many algorithms used in NLP and these algorithms even as Natural language processing (NLP) is a fairly new subject of studies and alertness in evaluation to other information technology approaches, there have been enough successes to suggest that NLP-primarily based information access technology will stay a prime vicinity of studies and development in statistics systems now and inside the future. those were some of the top NLP strategies and algorithms which can play a decent role in the success of NLP. according to the studies carried out it could be simply said that NLP is plenty better strategies as NLP is having ability for spotting the textual content and speech additionally and other method along with textual content mining best deals with the assessment of text high-quality. For NLP machine you\'re having much less knowledge requirement of abilities like NLTK, proficiency in neural networks while in textual content mining you are having requirement of expertise approximately exceptional factors together with cosine similarity or characteristic hashing, textual content processing, like Perl or python
References
[1] Marina Danilevsky, Kun Qian, Ranit Aharonov, Yannis Katsis, Ban Kawas, Prithviraj Sen IBM Research – Almadem 2020 A Survey of the State of Explainable AI for Natural Language Processingmdanile@us.ibm.com, {qian.kun,Ranit.Aharonov2}@ibm.com yannis.katsis@ibm.com, {bkawas,senp}@us.ibm.com [2] Miruna-Adriana Clinciu Edinburgh Centre for Robotics Heriot-Watt University University of Edinburgh mc191@hw.ac.uk Arash 2019 Eshghi Heriot-Watt University Edinburgh, United Kingdom a.eshghi@hw.ac.uk 2017 Helen Hastie Heriot-Watt University Edinburgh, United Kingdom h.hastie@hw.ac.uk 2019 A Study of Automatic Metrics for the Evaluation of Natural Language Explanations [3] Bryar Ahmad Hassan MSc. Software Engineering - University of Southampton, UK (2013) Artificial Intelligence Algorithms for Natural Language Processing and the Semantic Web Ontology Learning [4] Xueming Luo, Siliang Tong, Zheng Fang, and Zhe Qu Forthcoming Marketing Science June 2019 Machines versus Humans: The Impact of AI Chatbot Disclosure on Customer Purchases [5] LUCAS GLASS, Global Head of Analytics Center of Excellence, IQVIA GARY SHORTER, Head of Artificial Intelligence, R&D, IQVIA RAJNEESH PATIL, Head of Process Design & Analytics, Centralized Monitoring, Services, IQVIA 2012 AI IN CLINICAL DEVELOPMENT [6] Aastha Tyagi Amity University Noida, India ISSN: 2278-0181 IJERTV10IS090156 (This work is licensed under a Creative Commons Attribution 4.0 International License.) Published by : www.ijert.org Vol. 10 Issue 09, September-2021 Review Study of Natural Language Processing Techniques for Text Mining [7] Franca Dipaola 1,2,*, Mauro Gatti 3 , Veronica Pacetti 4 , Anna Giulia Bottaccioli 5 , Dana Shiffer 1,2 , Maura Minonzio 1,2, Roberto Menè 3 , Alessandro Giaj Levra 1 , Monica Solbiati 6 , Giorgio Costantino 6 , Marco Anastasio 7 , Elena Sini 8 , Franca Barbic 1,2 , Enrico Brunetta 1,2 and Raffaello Furlan 1,2 14 October 2019 Artificial Intelligence Algorithms and Natural Language Processing for the Recognition of Syncope Patients on Emergency Department Medical Records [8] Hee Yun Seol,1,2 Mary C Rolfes,3 Wi Chung,1 Sunghwan Sohn,4 Euijung Ryu,5 Miguel A Park,6 Hirohito Kita,6 Junya Ono,7 Ivana Croghan,8 Sebastian M Armasu,5 Jose A Castro-Rodriguez,9 Jill D Weston,1 Hongfang Liu,4 Young Juhn 10 January 2020 Expert artificial intelligence-based natural language processing characterises childhood asthma [9] Bita Akram, Spencer Yoder, Cansu Tatar, Sankalp Boorugu, Ifeoluwa Aderemi, Shiyan Jiang North Carolina State University bakram@ncsu.edu, smyoder@ncsu.com, ctatar@ncsu.edu, sboorug@ncsu.edu, sboorug@ncsu.edu, iwaderem@ncsu.edu, sjiang24@ncsu.edu September – 2016 Towards an AI-Infused Interdisciplinary Curriculum for Middle-grade Classrooms [10] Daniel Jurafsky Stanford University James H. Martin University of Colorado at Boulder December 30, 2020 Speech and Language Processing [11] ALZAHRAA SALMAN Master in Computer Science, TCSCM August 10, 2020 Test Case Generation from Specifications Using Natural Language Processing [12] Bhargav Chinnapottu Govardhan Arikatla Faculty of Computing, Blekinge Institute of Technology, 371 79 Karlskrona, Sweden Movie prediction based on movie scripts using Natural Language Processing and Machine Learning Algorithms [13] Erik Cambria School of Computer Engineering, Nanyang Technological University Bebo White SLAC National Accelerator Laboratory, Stanford University 11 April 2014 Jumping NLP Curves: A Review of Natural Language Processing Research [14] Paul D. Callister 2020 Law, Artificial Intelligence, and Natural Language Processing: A Funny Thing Happened on the Way to My Search Results [15] Emma Strubell University of Massachusetts Amherst October 2019 Machine Learning Models for Efficient and Robust Natural Language Processing [16] Jacques Bughin, Brussels Eric Hazan, Paris Sree Ramaswamy, Washington, DC Michael Chui | San Francisco Tera Allas | London Peter Dahlström | London Nicolaus Henke | London Monica Trench | London JUNE 2017 ARTIFICIAL INTELLIGENCE THE NEXT DIGITAL FRONTIER? [17] Kyung-Min Lee 1 , Jong-Bok Ahn1 , Deok-In Kim2 , In-Young Kim2 , Chul-Won Park1 1Gangneung-Wonju National University 150 Namwon-ro Heungeop-myeon, Wonju City, South Korea point2529@naver.com; ajb30735@naver.com; cwpark1@gwnu.ac.kr 2Urimalsoft 1 Gangwondaehak-ro, Chuncheon City, South Korea deokin.kim@urimalsoft.com; urimalsoft@urimalsoft.com Proceedings of the 4th World Congress on Electrical Engineering and Computer Systems and Sciences (EECSS’18) Madrid, Spain – August 21 – 23, 2018 MVML 108-1 Voice Pattern Recognition using CNN for Simple Command of Smart Toy [18] ROBERTO NAVIGLI Universit`a di Roma La Sapienza Navigli, R. 2009. Word sense disambiguation: A survey. ACM Comput. Surv. 41, 2, Article 10 (February 2009), Word Sense Disambiguation: A Survey [19] Jiangcheng Xu, Yun Zhang , Jiale Han[a], Haoran Qiao, Chengyun Zhang, Jing Tang, Xi Shen , Bin Sun , Silong Zhai, Xinqiao Wang, Yejian Wu , Weike Su, Hongliang Duan October 2015 New Application of Natural Language Processing?NLP?for Chemist: Predicting Intermediate and Providing an Effective Direction for Mechanism Inference [20] University Archives and Special Collections, University of Saskatchewan, Saskatoon, Canada 2020 Natural Language Processing and Machine Learning as Practical Toolsets for Archival Processing [21] Sarah Graham1,2 & Colin Depp1,2,3 & Ellen E. Lee1,2,3 & Camille Nebeker4 & Xin Tu1,2 & Ho-Cheol Kim5 & Dilip V. Jeste1,2,6,7 # Springer Science+Business Media, LLC, part of Springer Nature 2019 Artificial Intelligence for Mental Health and Mental Illnesses: an Overview [22] Fern Halper SAS ThoughtSpot, Inc. Vertica 2017 Advanced Analytics: Moving Toward AI, Machine Learning, and Natural Language Processing
Copyright
Copyright © 2022 Vaibhav Vijay Kulkarni, Dr Minesh Ade. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET45573
Publish Date : 2022-07-13
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online