

Ijraset Journal For Research in Applied Science and Engineering Technology
An Effective Data-driven Audio Watermarking Technique
Authors: Ishfaq Bashir, Satish Saini
DOI Link: https://doi.org/10.22214/ijraset.2023.54945
Certificate: View Certificate
Abstract
Audio piracy remains a persistent issue, highlighting the crucial need to protect audio signals and respect intellectual property rights. To tackle this challenge, we propose a two-step procedure consisting of intrinsic time scale decomposition (ITD) and Singular Value Decomposition (SVD).In our approach, the audio to be watermarked is initially divided into intrinsic mode functions and a low-frequency residue component using an iterative time scale decomposition technique. Subsequently, we apply Singular Value Decomposition to both the low-frequency component and the watermark. This allows us to embed the watermark within the residue component of the audio.To generate the watermarked audio, we combine the intrinsic mode functions with the watermarked residue component using inverse Intrinsic Time Scale Decomposition. This ensures that the watermark becomes integrated into the audio signal. Notably, our proposed approach effectively addresses computational complexity, a common challenge, while also prioritizing robustness and imperceptibility in line with advanced methods employed in the field.
Introduction
I. INTRODUCTION
Recent years have seen an exponential rise in digital media, and the ease of exchanging digital content via the internet has raised security concerns. Therefore, in light of the current situation, where we routinely transfer sensitive data over unsecure networks, robust security measures are necessary to improve data security and prevent data breaches [1],[2]. When seen in a broader context, security systems can be divided into two groups: information encryption systems and information concealment systems [3]. Fig. 1.1 displays full classification of the watermarking media and the domains of watermarking.
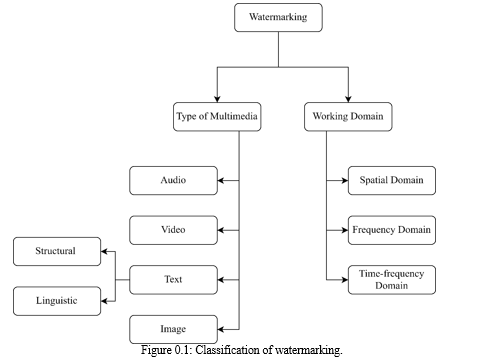
The process of digital watermarking is adding extra data to the host or cover media, which can only be retrieved when the extractor is aware of the embedding method precisely. The cover media, which can be audio, video, image, or text, is crucial to the watermarking process. Imperceptibility and resilience are the two main qualities of digital watermarking [4]. The art and science of steganography involves concealing confidential information in a cover material. The type of cover material used in steganography, whether it be text, audio, video, or images, is unimportant because it just serves as a conduit for the transfer of secret data. Even the fact that sensitive data is being transferred is intended to be concealed using steganography. The study of secret data transmission techniques from sender to legitimate recipient that prevent unauthorized parties from accessing the crucial data being communicated is known as cryptography. In cryptography, immediately important material is transformed into a chain of bits that appears meaningless to an intrusive party [5]. In cryptography, we typically utilize various encryption techniques to protect digital stuff that is sent and delivered. Information concealment encompasses both steganography and digital watermarking, yet their objectives could not be more different. In watermarking, the cover medium is crucial, whereas in steganography, the embedded data is crucial. On the other hand, material that needs to be sent is made to appear worthless in cryptography. Therefore, compared to the other two types of information security methods, cryptography draws more attention from hackers. Each of the three categories has some associated benefits and drawbacks, therefore depending on the application, one or more of the three may be utilized, or two or more may be combined to increase security. The best method for protecting digital data is digital watermarking. The cover media utilized can be text, audio, video, or image, however we primarily employ cover image as the cover medium, giving rise to digital image watermarking. Digital image watermarking has drawn more attention in study than audio, video, or text watermarking.
The two components that make up the fundamental model of digital watermarking are embedding and extraction. A proprietary embedding algorithm is used to implant a watermark into a cover media. The watermarked output is transmitted across an unsecured route. Since the detection mechanism is exclusively known to him, only the authorized user can extract the watermark on the receiver side. Without accurate knowledge of the detection technique, the intrusive party cannot extract the watermark. A secret key can be utilized during the embedding procedure in addition to the watermark. Digital watermarking methods can be used to secure the distributed and transmitted digital content. Combining encryption and watermarking methods can increase security. The following is a discussion of the uses for which digital watermarking is appropriate:
A. Copyright Protection
As a watermark, we can incorporate certain copyright-related information onto the appropriate cover medium. A logo, a special pattern known only to the owner, or any of the owner's private information could be the watermark. The embedded watermark can be removed to settle a dispute regarding ownership.
B. Fingerprinting
We can trace the origin of illegal copies that are being distributed using fingerprinting technology. In copies of data that are transferred and disseminated to numerous clients, the owner incorporates various watermarks. By providing the data to unauthorized users, consumers who have violated their agreements can be easily identified. This strategy is frequently used in online music sales. Additionally, fingerprinting can be used to stop unauthorized redistribution of a legal copy.
C. Copy Control
Watermarking can be used to stop unauthorized copying of digital files. The content that is watermarked cannot be copied in the first place, but even if it is, the watermark will remain intact. The watermark contains information about the owner as well as the number of permitted copies. It aids in locating illicit distribution as well.
D. Broadcast Monitoring
In order for an automated system to verify whether or not commercial commercials are broadcast in accordance with contract, we can apply watermarking in those advertisements. Even outside of TV ads, other TV items can be authenticated via watermarking.
E. Image Authentication and Data Integrity
Digital watermarking also finds applications in authentication of images and tamper detection. The photographs used in military and other sensitive services must be genuine. In courts digital photographs are used as evidences and can be authenticated using digital watermarking. A fragile watermark in particular tells us whether the data has been changed or not and gives information about exact locations being tampered.
F. Medical Safety
So that less data needs to be transmitted, we can utilize watermarking to integrate the electronic health records of patients into their own medical photographs. This is especially crucial in the current climate, in which telemedicine is receiving a lot of attention. We can add a watermark, the patient's case history, and their electronic health record on their own medical photos to increase the security of the medical information system. The only issue with watermarking medical images is that the area of interest needs to be preserved to avoid incorrect diagnosis. Watermarks are therefore inserted in medical photographs either via reversible methods or solely in non-interesting areas (RONI).
II. LITERATURE REVIEW
Byeong-Seob [6] Byeong-Seob proposed a revolutionary digital audio watermarking scheme. The core idea of the proposed method is to propagate an echo by using PN sequences in the temporal domain. This PN sequence acts as a secret key that may be used to decode the encoded information, offering more privacy than regular echo concealment, which lacks such a key.
Y. Xiang [7] presented a productive PN sequence for time-spread echo-based audio watermarking. In the perceptually significant region, the recommended sequence results in an echo kernel with a magnitude response that is less. Its correlation function, which likewise has more large peaks than the prior PN sequence, generates a modified decoding function.
Guang Hua [8] For a time-spread echo-based watermarking method, Guang Hua presented a novel digital FIR filter design. Spectral factorization and convex optimization techniques are specially used to build the design. For time-spread echo-based audio watermarking, it provides a comprehensive, accurate, and flexible solution..
Bassia [9] employed a direct modification of the amplitude values in the time domain, but there was no discernible difference as a consequence. A watermark key that was only known to the copyright holder was used to construct the watermark that was integrated into the audio stream.
Lei et. al. [10] suggested a methodology that incorporates elements of SVD, synchronization coding technique, QIM (Quantization Index Module), and LWT.
This approach performs excellent in parameters of imperceptibility, robustness. The audio segments are first LWT decomposed, and then estimated coefficients that have been previously divided into non-overlapping blocks are created. After that, the watermark is put in the low frequency sub band, and SVD is applied to each block separately. Then, using a QIM method, a watermark that is encrypted and in a random, chaotic sequence is inserted into each value.
Bai Ying Lei et al. [11] Single value decomposition (SVD), which has more sophisticated properties than DCT and DWT, was proposed by Bai Ying Lei et al. as an innovative and significant technique in robust digital watermarking. SVD-DCT employs an improved variant based on synchronization coding techniques. This uses a chaotic sequence as the synchronization code and incorporates it into the host signal after adding a binary watermark to the high frequency section of the SVD-DCT block.
N.J. Harish et al. [12] Based on DWT-SVD-DCT, N.J. Harish et al. developed a hybrid robust watermarking technique. We may use it to learn how to mix several wavelet transformations. The two essential characteristics of copyright protection and resilience are highlighted in this context. This method embeds the main watermark element, which is now visible in the DWT branch of the host pictures DCT domain.
Krishna Rao Kakkirala and Shrinivisa Rao Chalamala et al. [13] A secret sharing technique and a DWT-SVD based on audio watermarking were proposed by Krishna Rao Kakkirala et al. In doing so, they developed a method based on the watermarking of audio streams to add information.
To add information or a watermark, the secret sharing method, a cryptographic technique, is utilized. The DWT and SVD are both used to embed and extract the watermark from the audio stream.
Jose, Rene et al. [14] introduced a unique technique for high payload data concealment for audio broadcasts utilizing OFDM concepts. It is based on modulating the phase components of an audio stream at a selected frequency sample using a reduced arc M-order shift keying (MPSK) modulator. By adjusting the frequencies of various audio signal components, it is straightforward to control perceptual distortion and data hiding payload using this technique.
Ortiz & al [15] introduced a technique for audio watermarking that is robust to irrational attacks. The process involves breaking the audio stream into fragments and applying the Fast Fourier Transform (FFT) to each segment. The resulting frequency coefficients of each segment are then used as the dataset for watermark insertion. Specifically, the frequency coefficient with the highest amplitude is combined with a watermark bit.
Hu & Lee [16] In this technique, the suitable audio clips are first picked out for hiding. Each portion is then separated into frames (non-overlapping). Then, every frame is subjected to an FFT. The watermark bits are subsequently inserted in the reduced frequency parts of the signal.
Sayed & al [17] Based on the values of the energy levels in the FFT domain, suggested a novel method for audio watermarking. This method enables the insertion of two bits in each audio framework by restricting the power of the sub-frames to a Lucas math array and employing a typical embedding mechanism.
Abdel Wahab & al [18] A Singular Value Decomposition (SVD) and FRT (fractional Fourier transform) based audio watermarking technique was put out by Abdel Wahab et al. This technique includes converting the signal into a 2-D matrix and applying an SVD to it. The W (watermark image) grid enlarges the S- matrix. The final matrix is sent through an inverse SVD to make it back into a 1-D matrix.
III. PROPOSED METHOD
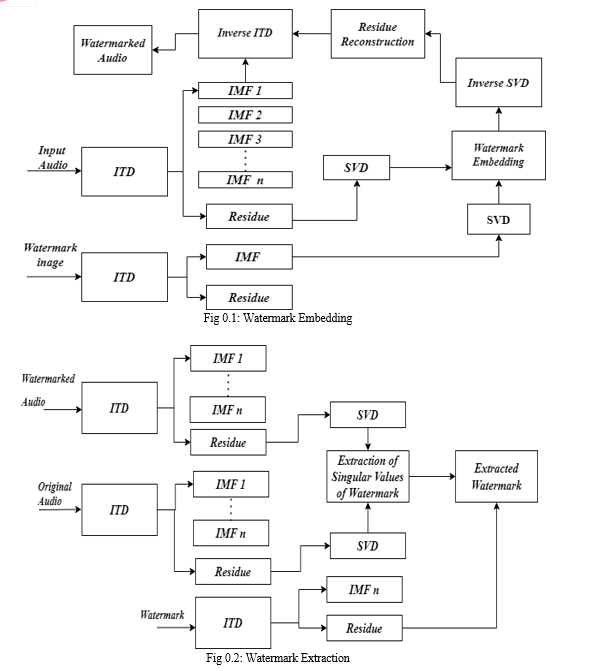
The audio watermarking scheme proposed comprises two main processes: the embedding process and the extraction process. Fig. 3.2 and Fig. 3.3 illustrate the flowchart for each of these processes, respectively. During the embedding process, the audio is decomposed into Intrinsic Mode Functions using Intrinsic Time Scale Decomposition to obtain a residue component with a low frequency.
This residue component contains the owner's watermark, creating the watermarked audio. The extraction process, on the other hand, is used to verify the audio's copyright by extracting the watermark from the watermarked audio and comparing it with the original watermark.
Being low frequency component, it changes the listening experience minutely which is one of the main goals of the audio watermarking. Singular value decomposition is applied to the residue component to obtain three matrices where the S-matrix is used for the embedding purpose due to its excellent properties.
A. Embedding of Watermark
We embed the watermark W into an audio or speech signal S, where S = {s(i), 0?i < length} contains length samples, and the watermark is an N × M matrix given by W = {w (i, j), 0?i < N, 0?j < M}.
The watermark embedding process can be described as follows:
- Step 1: Iterative Time scale decomposition of the audio as well the watermark is performed.
- Step 2: The output of the first step actually generates a band of IMF’s and a low frequency residue component. Here we select this low frequency component from the audio and 1st IMF of the Watermark.
- Step 3: SVD of the Residue and IMF component is performed in order to obtain Singular values.
- Step 4: Add the watermarked singular value bits to the Singular values of the residue component.
- Step 5: Perform the inverse SVD of the Residue component to create the watermarked residue component.
- Step 6: Add the IMF components and the watermarked residue component to generate the watermarked audio.
B. Extraction of Watermark
The process of extracting a watermark is an exact opposite of that of embedding a watermark. Among all the sub-bands, residue is processed to extract the watermark from the watermarked audio using the inverse Intrinsic time scale decomposition technique. Singular value decomposition is applied to the lower frequency band in order to retrieve the watermark.
The entire procedure is encompassed by the steps and the flowchart given below:
- Step 1: Perform the Intrinsic Time scale decomposition of the Watermarked audio and the original Audio.
- Step 2: Generate the Residue component of the both Audio signals and Performed SVD of the each of them.
- Step 3: Extract the Singular values of the watermark from watermarked residue.
- Step 4: Perform inverse SVD using extracted singular values and the original and U and V matrix of the watermark.
- Step 5: Perform the Inverse Iterative time Scale Decomposition to generate the Watermark values in One dimension.
- Step 6: Reshape the Extracted values to form an image form the values which is the watermark that was embedded originally in the audio.
IV. EXPERIMENTAL RESULTS
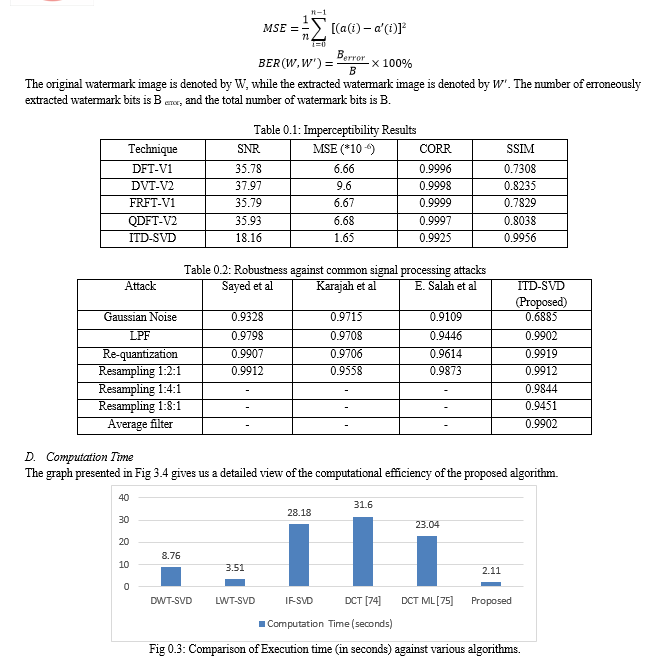
Performance assessment of the proposed scheme is seen in terms of robustness and imperceptibility. Various tests have been carried out on the proposed scheme involving the likes of sound quality assessment material full songs (classical, pop and rock music) and a human voice signal. In our approach for the analysis of the quality of watermarked audio signals, we use SNR MSE SSIM. Also, for reliability evaluation of the extracted watermark, NC and BER are used.
A. Imperceptibility Test
For the measurement and performance test of our proposed approach, SNR measure is applied. Such a metric where the quantity of noise added to the audio file in s the process of watermarking is measured is referred to as an SNR. The desirable feature of SNR is its higher value as it specifies low-level distortion. For better evaluation and analysis of each algorithm, calculation of mean square error is done (MSE), also with the likes of correlation coefficient (CORR) etc. SNR values by our adopted approach remain reasonable with respect to the related work.
???????B. Robustness to Common Signal Processing Attacks
Normalized cross-correlation (NC) and Bit Error Rate (BER) are two commonly used robustness evaluation metrics in the literature for assessing the similarity between extracted and embedded watermarks. A higher NC value indicates a greater similarity between the extracted and embedded watermarks, with a value close to 1 indicating a high level of similarity. Conversely, a lower BER value indicates a higher degree of similarity between the extracted and embedded watermarks, with a value close to zero indicating a high level of similarity.
In our tests, we assume that the watermark is a binary logo with a size of 32×32, and exists if the calculated correlation exceeds a threshold value of 0.7. For a significant amount of similarity between the original and extracted watermark, we desire a value of NC greater than 0.85. If NC exceeds this threshold, the extracted watermark is perceptually similar to the hidden watermark. Additionally, we consider the extraction of the watermark correct if the computed BER value is less than 3. A BER value below this threshold indicates that the detected watermark is perceptually comparable to the embedded one.
For the better assessment of the watermarking scheme, blind attacks (such as noise addition, MP3 compression etc.) and intentional attacks should be taken into account. As such, watermark existence and where it actually exists is not known by non-intentional attacks, however the location and what actually has been embedded is observed by intentional attacks. Common signal processing manipulations, which comprise various different parameters, are as:
- Re-quantization: The 16-bit audio signal with a watermark is subjected to a re-quantization process that reduces it to 8 bits, and subsequently, it is restored to its original 16-bit format.
- Resampling: The audio signals containing a watermark and recorded at the original sampling rate of 44.1 kHz were down-sampled to 22.05 kHz, 11.025 kHz, and 8 kHz, and subsequently up-sampled back to the original sampling rate of 44.1 kHz.
- Additive Noise: White Gaussian noise with a power level equal to 1% of the audio signal's power was introduced.
- Low-pass Filtering: The watermarked audio signals were subjected to low-pass filtering using a second-order Butterworth filter with a cut-off frequency of 4 kHz.
C. Watermark Assessment
The watermark assessment is a crucial component of any application, as it determines the effectiveness and robustness of the chosen methodology, as well as its efficiency and imperceptibility. Several parameters are typically taken into consideration during this process to demonstrate the algorithm's stability and efficiency in black and white (BW) applications. Here we utilize different quality matrices including signal- to- noise ratio (SNR), mean square error (MSE), normalised correlation coefficient (NCC), and structural similarity (SSIM) index. In order to compute the value of SNR its formula is given by

 ???????
???????
Conclusion
Digital watermarking was developed as a solution for copyright assurance and verification of transmitted and disseminated digital information. In addition to making data distribution rapid and easy, the use of the Internet, e-commerce, computerized libraries, and mobile phones has made it difficult to manage security, protection, and copyright issues. The study covered in this thesis looked into the use of digital watermarking for content authentication and copyright protection for distributed and transmitted audio files and speeches. In this thesis, a watermarking system for copyright protection and content verification of audio signals has been proposed, where we used a purely data driven technique, ITD, for embedding robust watermark. The proposed work demonstrates a high speed of embedding and extraction of the watermarks. The method was used to demonstrate the superiority by using various audio signals like pop, folk and speech. All the audios were sampled at sampling frequency ranging from 8Khz to 44.1Khz. All the audios are 16-bit signed mono signals and taken in the wav format. Binary images 20 × 50 was used as watermark in our algorithm. Simulations were run to gauge how well the suggested work would perform. MATLAB 2018a was used to run the simulations. The method demonstrates improved resistance to a variety of signal processing attacks like Re quantization, Resampling, Additive white Gaussian noise and low pass filtering among others. The superiority of the algorithm is mainly in terms of its computation time and can be implemented on devices where processing power is limited. The proposed work may work well when watermarking speeches phone calls etc. for their genuineness. Lately, we have seen various cases where it actually becomes very important for deciding the trail of any convict based on an audio recording from any electronic gadget which has minimal resources. Since machine learning algorithms can appropriately mimic the voices of any individual when trained. So, designing a watermark technique that can confirm any recording of its truthfulness may be what we have been looking for and our proposed method may be a step in right direction.
References
[1] E. Salah, K. Amine, K. Redouane, and K. Fares, “A Fourier transform based audio watermarking algorithm,” Applied Acoustics, vol. 172, p. 107652, 2021. [2] O.-J. Kwon, S. Choi, and B. Lee, “A watermark-based scheme for authenticating JPEG image integrity,” IEEE Access, vol. 6, pp. 46194–46205, 2018. [3] A. F. Abdelnour and I. W. Selesnick, “Design of 2-band orthogonal near-symmetric CQF,” 2001 IEEE International Conference on Acoustics, Speech, and Signal Processing. Proceedings (Cat. No.01CH37221), 2001. [4] M. Charfeddine, E. Mezghani, S. Masmoudi, C. B. Amar, and H. Alhumyani, “Audio Watermarking for security and non-security applications,” IEEE Access, vol. 10, pp. 12654–12677, 2022. [5] S. Bagheri Baba Ahmadi, G. Zhang, S. Wei, and L. Boukela, “An intelligent and blind image watermarking scheme based on hybrid SVD transforms using Human Visual System Characteristics,” The Visual Computer, vol. 37, no. 2, pp. 385–409, 2020. [6] B. S. Ko, R. Nishimura, and Y. Suzuki, “Time-spread Echo method for digital audio watermarking,” IEEE Transactions on Multimedia, vol. 7, no. 2, pp. 212–221, 2005. [7] Y. Xiang, I. Natgunanathan, D. Peng, W. Zhou, and S. Yu, “A dual-channel time-spread Echo method for audio watermarking,” IEEE Transactions on Information Forensics and Security, vol. 7, no. 2, pp. 383–392, 2012. [8] G. Hua, J. Goh, and V. L. Thing, “Time-spread echo-based audio watermarking with optimized imperceptibility and robustness,” IEEE/ACM Transactions on Audio, Speech, and Language Processing, vol. 23, no. 2, pp. 227–239, 2015. [9] P. Bassia, I. Pitas, and N. Nikolaidis, “Robust Audio Watermarking in the time domain,” IEEE Transactions on Multimedia, vol. 3, no. 2, pp. 232–241, 2001. [10] Y.-S. Lee, Y.-H. Seo, and D.-W. Kim, “Blind image watermarking based on adaptive data spreading in n-level DWT sub bands,” Security and Communication Networks, vol. 2019, pp. 1–11, 2019. [11] B. Y. Lei, I. Y. Soon, and Z. Li, “Blind and robust audio watermarking scheme based on SVD–DCT,” Signal Processing, vol. 91, no. 8, pp. 1973–1984, 2011. [12] N. J. Harish, B. B. S. Kumar, and A. Kusagur, “Hybrid Robust Watermarking Technique Based on DWT, DCT and SVD,” International Journal of Advanced Electrical and Electronics Engineering, vol. 2, no. 5, 2013. [13] K. R. Kakkirala and S. R. Chalamala, “Digital Audio Watermarking using DWT-SVD and secret sharing,” International Journal of Signal Processing Systems, pp. 59–62, 2013. [14] J. J. Garcia-Hernandez, R. Parra-Michel, C. Feregrino-Uribe, and R. Cumplido, “High payload data-hiding in audio signals based on a modified OFDM approach,” Expert Systems with Applications, vol. 40, no. 8, pp. 3055–3064, 2013. [15] A. Menendez-Ortiz, C. Feregrino-Uribe, and J. J. Garcia-Hernandez, “Framework for audio reversible watermarking robust against content replacement with signal restoration capabilities,” Journal of the Franklin Institute, vol. 356, no. 12, pp. 6793–6816, 2019. [16] H.-T. Hu and T.-T. Lee, “High-performance self-synchronous blind audio watermarking in a unified FFT framework,” IEEE Access, vol. 7, pp. 19063–19076, 2019. [17] S. M. Pourhashemi, M. Mosleh, and Y. Erfani, “Audio Watermarking based on synergy between Lucas regular sequence and fast Fourier transform,” Multimedia Tools and Applications, vol. 78, no. 16, pp. 22883–22908, 2019. [18] K. M. Abdelwahab, S. M. Abd El-atty, W. El-Shafai, S. El-Rabaie, and F. E. Abd El-Samie, “Efficient SVD-based Audio Watermarking technique in FRT domain,” Multimedia Tools and Applications, vol. 79, no. 9-10, pp. 5617–5648, 2019.
Copyright
Copyright © 2023 Ishfaq Bashir, Satish Saini. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET54945
Publish Date : 2023-07-23
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online