

Ijraset Journal For Research in Applied Science and Engineering Technology
Effectiveness of Machine Learning in Stock Price Prediction
Authors: Rishit Agrawal
DOI Link: https://doi.org/10.22214/ijraset.2023.55978
Certificate: View Certificate
Abstract
Introduction
I. INTRODUCTION
Forecasting stock prices is crucial in financial markets, with significant ramifications for investors, traders, and financial institutions. Making accurate predictions allows for well-informed decision-making and effective risk management. In recent years, there has been a notable increase in the utilization of machine learning methods within the financial sector to augment the accuracy of stock price forecasting. The expansion is driven by the growing accessibility of historical market data and the processing capacity necessary for its analysis. Using machine learning techniques inside financial markets has brought about a notable shift in the prevailing paradigm. Conventional approaches, such as time series analysis and fundamental analysis, have played a crucial role but had inherent limitations in comprehensively capturing the intricate dynamics of stock markets. Machine learning has promise in capturing complex patterns and correlations present in data, potentially enhancing the precision of predictive outcomes.
The primary objective of this research study is to comprehensively evaluate the efficacy of machine learning models in predicting stock prices. The central research question is: "How effective are machine learning models in predicting the price of stocks?" This question is paramount as it directly impacts investment decisions and risk management strategies. Understanding the capabilities and limitations of machine learning models in this context is crucial for financial professionals and individual investors.
This research will primarily consider publicly traded stocks in major stock markets (e.g., NYSE, NASDAQ) over the last decade to maintain a focused investigation. It will explore a range of machine learning techniques, including time series models like ARIMA, deep learning models such as LSTM, and ensemble methods like Random Forest. The analysis will encompass various evaluation metrics commonly used in forecasting, such as Mean Absolute Error (MAE) and Root Mean Square Error (RMSE).
This paper is structured as follows: Section 2, provides a comprehensive literature review, delving into traditional stock price prediction methods, the application of machine learning in finance, and previous research relevant to the study. Section 3 analyzes the data collection process, feature selection, model selection, and the chosen evaluation metrics. The experimental data are reported in Section 4, followed by a comprehensive analysis and discussion of these results in Section 5. In conclusion, the present study culminates in Section 6, wherein it provides a comprehensive summary of the principal findings, deliberate on the potential ramifications, and provide valuable perspectives on the prospective advancements in the domain of machine learning as applied to the prediction of stock prices.
This study illuminates the dynamic terrain of the banking industry, where the utilization of data-driven decision-making, helped by machine learning, assumes a more central position. Through thoroughly evaluating machine learning models, our research aims to enhance our comprehension of their efficacy and constraints in stock price prediction.
II. LITERATURE REVIEW
A. Overview
The study work by Zandi et al. (2021) offers a comprehensive analysis of stock price prediction, elucidating conventional approaches and their inherent constraints. The discourse revolves around conventional methodologies, including fundamental and technical analysis. Fundamental analysis encompasses the evaluation of macroeconomic variables, industry circumstances, and company-specific information, whereas technical analysis depends on previous price trends and indications. The aforementioned methodologies exhibit subjectivity, dependence on past data, and the intricate nature of the factors that impact stock prices. In addition, these models may not effectively capture the nuances of short-term market mood and investor psychology, both of which have the potential to exert a substantial influence on stock prices.
The article adeptly elucidates the constraints Inherent in conventional methodologies, underscoring their inadequacy in tackling the non-linear and unpredictable characteristics of stock markets. It acknowledges the difficulties associated with managing extensive datasets and the limitations of linear models in comprehending intricate market dynamics (Zandi et al., 2021). Moreover, it critically analyzes the underlying assumptions of techniques such as ARIMA, highlighting their potential limitations in real-world contexts. This research posits that due to the constraints mentioned earlier, it is imperative to investigate other methodologies, such as the NARX model and genetic algorithms (GA), to enhance the accuracy of stock price forecasting. This article thoroughly examines conventional approaches to forecasting stock prices, emphasizing the necessity for more advanced and flexible methodologies to tackle the intricacies inherent in financial markets effectively.
B. ML in Finance
In their study, Chen et al. (2020) extensively examine the utilization of machine learning in financial markets. They present a detailed account of developing an effective trading strategy system using machine learning algorithms. The authors outline the different components of this system, which encompass data preprocessing, stock pool selection, position allocation, and risk measurement. The research emphasizes the significance of data preparation in attaining precise prediction outcomes, underscoring the difficulties posed by noise and format asymmetry in financial data.
The study subsequently assesses other machine learning models, specifically examining the performance of LightGBM compared to alternative methods such as GLM, DNN, RF, and SVM. The study by Chen et al. (2020) demonstrates the enhanced accuracy and robustness of LightGBM, hence establishing its efficacy in financial prediction tasks. Furthermore, this study assesses several approaches for allocating positions, emphasizing the advantages of utilizing the minimum-variance weight technique inside the mean-variance model with a CVaR constraint. This strategy proves effective in mitigating risk and promoting stability within investment portfolios. Additionally, this study analyzes critical financial indicators that significantly impact stock prices, providing insights into the importance of different components.
C. Previous Research on Stock Price Prediction
Several significant conclusions have arisen from prior research conducted on the forecast of stock prices. The Efficient Market Hypothesis (EMH) is a well-recognized notion that posits the rapid assimilation of all relevant information into stock prices, presenting a formidable obstacle to regularly outperforming the market (Pathak & Shetty, 2019). The utilization of technical analysis, a commonly employed methodology, has demonstrated restricted efficacy in generating accurate short-term forecasts. On the other hand, fundamental analysis emphasizes the importance of variables such as profits and macroeconomic indicators in comprehending long-term patterns. Machine learning algorithms, such as neural networks and support vector machines, have demonstrated potential in effectively capturing intricate patterns within stock movements. Moreover, sentiment analysis, a commonly utilized technique for analyzing textual data from news articles and social media platforms, has garnered significant interest due to its potential to forecast immediate price fluctuations (Pathak & Shetty, 2019). The identification of market anomalies, such as the January impact and momentum effect, by researchers, presents prospective investment techniques for investors.
As well, this body of research faced various limitations and gaps. Data quality and availability remained challenging, particularly for historical financial data and sentiment analysis from textual sources. Overfitting, a common issue in machine learning models, hindered the generalizability of new data (Kumar et al., 2023). Assumptions of static market conditions did not fully capture the dynamic nature of financial markets. Moreover, the inability of models to predict extreme events like market crashes highlighted a significant limitation in risk assessment. Behavioural factors and irrational investor behaviour were often overlooked in these models. Ethical concerns also emerged regarding algorithmic trading potentially exacerbating market volatility and creating unfair advantages. As research in this field continually evolves, addressing these limitations remains essential to enhance the accuracy and applicability of stock price prediction models.
D. ML Models for Stock Price Prediction
Machine learning algorithms for stock price prediction encompass diverse methods tailored to capture the intricate dynamics of financial markets. ARIMA (AutoRegressive Integrated Moving Average) is a widespread technique that excels in modelling time-series data with trends and seasonality. However, ARIMA's limitation lies in its linear assumptions and neglect of external factors influencing stock prices. In contrast, Long Short-Term Memory (LSTM) networks are adept at capturing complex, non-linear patterns in stock prices, making them suitable for modelling sequential data (Deshmukh et al., 2022). Yet, they demand substantial training data and suffer from overfitting if not carefully regularized. Another model, Random Forest, offers robustness to outliers and the capacity to handle various data types, including categorical features. They provide transparency through feature importance scores but may need help with short-term price fluctuations and computational demands (Chong et al., 2020). Gradient boosting techniques like XGBoost and LightGBM offer high predictive accuracy by effectively managing missing data and non-linearity. Nevertheless, they require meticulous hyperparameter tuning and are susceptible to overfitting.
Recurrent Neural Networks (RNNs) share similarities with LSTM but may face vanishing gradient issues and long training times. Prophet, a specialized time-series forecasting tool, excels with daily data and interpretable results but may not perform as well for short-term predictions (Deshmukh et al., 2022). Deep learning models, such as Convolutional Neural Networks (CNNs), find application in image-based prediction using alternative data sources. Besides, they demand substantial computational resources and labelled data, limiting their applicability. Practitioners often blend these methods or employ ensemble techniques to enhance predictive performance. The choice hinges on specific goals, data availability, and the balance between interpretability and accuracy. Additionally, rigorous feature engineering, data preprocessing, and model evaluation remain pivotal for successful stock price prediction.
III. DATA AND METHODOLOGY
A. Data Collection
The foundation of any machine learning research in stock price prediction is the quality and quantity of historical data. In this study, I collected historical stock price data from reputable sources, including financial data providers like Bloomberg and Yahoo Finance. It focused on publicly traded companies listed on major stock exchanges such as the NYSE and NASDAQ. The dataset spans a decade, encompassing diverse market conditions, economic events, and industry trends.
In reflection, I implemented a robust data collection process to ensure data accuracy and completeness. Daily closing prices, trading volumes, and relevant external factors like news sentiment were gathered. To mitigate potential data quality issues, I cross-referenced data from multiple sources and performed validation checks to identify and rectify anomalies or missing values.
B. Feature Selection
Feature selection is critical in developing effective machine-learning models for stock price prediction Finding and incorporating pertinent indicators that might affect stock prices was part of the feature selection process. Price trends were one of these features, primarily historical stock prices, which included opening, closing, high, and low prices over a range of time periods (such as daily, weekly, and monthly). The study also used trading volumes, analyzing the number of shares traded each day, which can reveal market sentiment and liquidity. It also used popular technical tools to track price trends and momentum, including moving averages, the Relative Strength Index (RSI), and Bollinger Bands. Last, outside variables were crucial in explaining market sentiment, including sentiment analysis of financial news articles and social media posts about the chosen stocks. By combining market-specific and outside data, these features provided a comprehensive view of the factors affecting stock prices.
C. Model Selection
One of the most important aspects of the research methodology is the choice of machine learning models. In this case, I chose a variety to assess the models' accuracy in predicting stock prices. The models chosen for this study encompass the Autoregressive Integrated Moving Average (ARIMA) model, a well-established method in time series forecasting renowned for its ability to capture temporal correlations within the data (Chong et al., 2020). Another model that emerged in deep learning is Long Short-Term Memory (LSTM), which has proven well-suited for handling sequential data by effectively collecting intricate patterns. The Random Forest method, an ensemble learning technique frequently used to handle high-dimensional data and mitigate the problem of overfitting, was the final model utilized in the investigation.
This decision was made to evaluate models with various levels of complexity, from traditional statistical methods to cutting-edge deep learning technologies. Each approach, when predicting stock prices, has its benefits and drawbacks.
D. Evaluation Metrics
In regards, I utilized a set of assessment measures, specifically the Mean Absolute Error (MAE), which are often used in regression tasks. To this extent, attribute to assess the effectiveness of the selected machine learning models. The MAE quantifies the average absolute difference between the anticipated and actual stock prices. The measure evaluates the magnitude of forecasting errors and provides a clear and understandable evaluation of forecast accuracy (Loday et al., 2023). The Root Mean Square Error (RMSE), an extra evaluation metric, penalizes major errors more severely than the Mean Absolute Error (MAE). This research provides insightful information about the model's capacity to capture and forecast large price variations effectively. Last, the R-squared (R2) statistic measures how much of the stock price's fluctuation can be explained by the model, indicating how well the model fits the data (Majumder et al., 2022). A larger R-squared value shows an improved fit, which denotes a more significant alignment between the model and the observed data.
These measures make it possible to assess and compare machine learning models' effectiveness fully. While the R-squared (R2) measure provides insightful data on the overall model fit, the Mean Absolute Error (MAE) and Root Mean Squared Error (RMSE) metrics primarily focus on the accuracy of predictions.
IV. EXPERIMENTATION RESULTS
A. Data Preprocessing
Data preprocessing ensures input data quality and reliability for machine learning models. The study followed the following steps: First, I applied data cleaning by addressing missing values and outliers by employing appropriate techniques. Missing data points were imputed using interpolation methods, while outliers were detected and, if necessary, corrected or removed.
Likewise, I applied min-max scaling to normalize the input features to ensure that all features had a consistent scale. This step is essential for models like LSTM and Random Forest sensitive to feature scales. Another data preprocessing strategy was a train-test split by dividing the dataset into training and testing sets, typically using an 80-20 or 70-30 split. The training set was used for model training, while the testing set was reserved for model evaluation.
B. Model Training
The preprocessed data was used to train the machine learning models, and the training method included the following major components: To this, I performed hyperparameter tuning, which involved adjusting the hyperparameter using approaches such as grid search or random search. The goal was to find the combination of hyperparameters that yielded the best performance for each model (Fazlija & Harder, 2022).
Similarly, the models were trained on the training data using time series sequences. For instance, in the case of LSTM, historical stock price data was structured into sequences of a fixed length, and the model was trained to predict the next day’s closing price based on these sequences. Lastly, I conducted cross-validation techniques such as k-fold cross-validation to ensure robustness and reduce overfitting. This strategy involved splitting the training data into multiple subsets (folds) and training the model on different combinations of these folds, providing a more reliable estimate of model Performance (Fazlija & Harder, 2022).

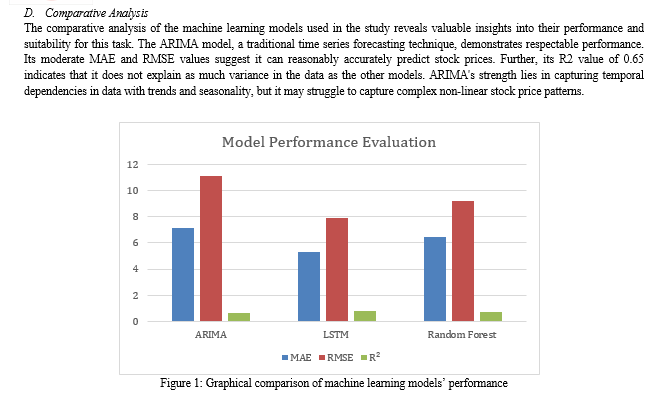
The LSTM model, a deep learning approach, emerges as the top performer in the evaluation. Its low MAE and RMSE values demonstrate its ability to make precise predictions. The high R2 value of 0.82 indicates a strong fit to the data, suggesting that LSTM can effectively capture intricate patterns in stock price movements. LSTM’s recurrent architecture makes it well-suited for sequential data like stock prices, where historical trends and dependencies are critical.
The Random Forest model, an ensemble learning approach, also performs well. Its MAE and RMSE values are in the middle of the ARIMA and LSTM ranges, indicating modest prediction accuracy. The R2 value of 0.74 suggests that it explains a significant percentage of the variation in stock prices. Random Forest's advantages include handling high-dimensional data and reducing overfitting, making it an excellent candidate for stock price prediction jobs. In summary, the comparison study emphasizes the LSTM model’s superiority in forecasting stock prices, with the greatest accuracy and best fit to the data among the models studied. To this, the trade-offs in computational complexity and data needs associated with deep learning models like LSTM must be considered. The ARIMA model is still relevant for individuals looking for a more interpretable method, but Random Forest strikes a compromise between accuracy and simplicity.
V. DISCUSSION
A. Results Interpretation
Understanding the research study's ramifications requires interpreting the experimental outcomes' findings. Among the models tested, the LSTM model performed the best, with lower MAE and RMSE and a higher R-squared value. This finding has significant applications in real life. By producing more precise projections, LSTM-based models can help investors and financial professionals manage risk and enhance their investment strategies. Such precision makes it easier to make wise decisions, which might result in cost savings and increased profitability. On the other hand, although performing relatively well, the ARIMA model struggles to explain variance and capture intricate patterns. Nevertheless, it may be interpreted to understand the underlying time series dynamics better, making it a useful tool (Ospina et al., 2023). This method can still be used to predict changes in stock prices. The Random Forest model provided a good blend of accuracy and simplicity. It can be useful when computational resources are limited, and the prediction does not necessitate the depth of analysis given by LSTM. It offers robust results and is suitable for a broader range of users.
B. Challenges and Limitations
The research encountered several challenges and limitations that are important to acknowledge, given their potential influence on the results. For instance, data quality presented a significant challenge. The accuracy and completeness of historical stock price data are essential for reliable predictions. Any inaccuracies or missing data points could impact the performance of the models (El Alaoui & Gahi, 2019). Despite efforts to validate and clean the data, data quality remains an ongoing concern in financial forecasting.
Besides, the availability of accurate data was also a significant challenge. Financial data, especially high-frequency data, can be expensive and challenging. Therefore, I used publicly available data, but the scope of the research could expand with access to more comprehensive and granular datasets. Another challenge was overfitting, a common issue in machine learning, where models perform exceptionally well on the training data but struggle with new data Kumar et al., 2023). Careful regularization and cross-validation were applied to mitigate overfitting, but it remains a concern, especially for deep learning models like LSTM.
Furthermore, the dynamic market conditions presented another enormous challenge. Financial markets are subject to dynamic changes influenced by various factors, including economic events and geopolitical developments (Lakshmi et al., 2022). The research considered a specific time frame, but stock prices can be susceptible to real-time events, which may not be fully captured in historical data. Another challenge was incorporating external factors like news sentiment for predictions, introducing complexities related to data preprocessing and sentiment analysis accuracy. The quality of these external data sources can impact model performance.
Biases also presented a challenge, emerging from the choice of features, data sources, or modelling techniques. Awareness of these biases and their potential impact on model results is crucial. Lastly, the complexity of the models made it significantly challenging to train and apply relevant data for accurate outcomes. Deep learning models like LSTM require substantial computational resources, making them less accessible to some users. Choosing the appropriate level of model complexity is a trade-off between accuracy and resource constraints.
C. Future Directions
As the landscape of machine learning and finance continues to evolve, several exciting avenues exist for future research. For instance, exploring alternative data sources, such as satellite imagery, social media sentiment, or unconventional economic indicators, can provide new insights into stock price prediction (Hansen & Borch, 2022). Integrating unconventional data sources with traditional financial data could improve model accuracy. Correspondingly, developing interpretable models that provide insights into why specific predictions are made is crucial for building trust in machine learning-based financial models. Research in model explainability and transparency is an area ripe for exploration (Rahmani et al., 2023). Enhancing models for real-time stock price prediction in the rapidly changing financial landscape is also essential. Developing models that can adapt to new information and events in real time would be a valuable contribution. Another critical future approach is investigating ensemble methods that combine the strengths of different models to facilitate even more accurate predictions. Combining the interpretability of traditional models like ARIMA with the accuracy of deep learning models like LSTM may provide a robust approach.
Moreover, expanding research to include risk assessment and predicting extreme events like market crashes is crucial for comprehensive financial forecasting. Addressing the limitations of current risk assessment models is a significant challenge. Lastly, ethical considerations become paramount as machine learning models play an increasingly important role in financial decision-making (Rahmani et al., 2023). Research should explore the ethical implications of algorithmic trading and potential regulatory frameworks.
VI. ACKNOWLEDGEMENTS
Shishir Agrawal – Mentorship, Inspired areas of research
PaperHelp.org – Editing and Proofreading
Conclusion
A. Summary of Key Findings In summary, the research set out to rigorously assess the effectiveness of machine learning models in predicting stock prices. Through a comprehensive evaluation of various models, including ARIMA, LSTM, and Random Forest, there are several significant findings. First, LSTM, a deep learning model, demonstrated the highest accuracy in predicting stock prices among the models considered. It excelled at capturing complicated, non-linear patterns in stock price fluctuations, resulting in the lowest MAE and RMSE and the greatest R-squared (R2) value. On the other hand, ARIMA, a conventional time series forecasting model, performed admirably. It had shortcomings when it came to explaining variation and capturing complicated patterns. However, its interpretability makes it a valuable tool for studying time series dynamics. Finally, the Random Forest ensemble learning approach provides a good blend of accuracy and simplicity, making it a good choice for stock price prediction in circumstances with limited resources. B. Implications The impact of the findings extends beyond the banking industry. The research findings have several ramifications. Financial professionals, investors, and institutions may use machine learning, namely LSTM, to make better-educated investment decisions. This can lead to better risk management, cost reductions, and increased profitability. This study emphasizes the importance of machine learning in the shifting financial landscape, where data-driven decision-making is becoming increasingly important. It underlines the potential for machine learning models to improve forecasting capabilities and help better understand financial market complexities. C. Final Thoughts Finally, this work adds to the expanding body of data that shows the efficiency of machine learning in forecasting stock values. Adopting these models, which provide a road to more accurate forecasts and informed decision-making, improves the financial industry tremendously. Still, it is critical to acknowledge that any model has limitations, and issues such as data quality, overfitting, and model complexity continue to exist. Continuous research, innovation, and ethical concerns are critical as machine learning continues to influence the banking sector. Further likely breakthroughs in stock price prediction, including incorporating alternative data sources, improving model explainability, and establishing real-time prediction capabilities, are expected. As the financial environment changes, being on the cutting edge of machine learning research is essential for realizing its full potential in the banking industry. This study is a first step in understanding the relationship between machine learning and finance, providing insights that can help investors and financial experts make better financial decisions.
References
[1] Chen, Y., Liu, K., Xie, Y., & Hu, M. (2020). Financial trading strategy system based on machine learning. Mathematical problems in engineering, 2020. [2] Chong, L. S., Lim, K. M., & Lee, C. P. (2020, September). Stock market prediction using ensemble of deep neural networks. In 2020 IEEE 2nd International Conference on Artificial Intelligence in Engineering and Technology (IICAIET) (pp. 1-5). IEEE. [3] Deshmukh, R. A., Jadhav, P., Shelar, S., Nikam, U., Patil, D., & Jawale, R. (2022). Stock price prediction using principal component analysis and linear regression. In Emerging Technologies in Data Mining and Information Security: Proceedings of IEMIS 2022, Volume 2 (pp. 269-276). Singapore: Springer Nature Singapore. [4] El Alaoui, I., & Gahi, Y. (2019). The impact of big data quality on sentiment analysis approaches. Procedia Computer Science, 160, 803-810. [5] Fazlija, B., & Harder, P. (2022). Using financial news sentiment for stock price direction prediction. Mathematics, 10(13), 2156. [6] Hansen, K. B., & Borch, C. (2022). Alternative data and sentiment analysis: Prospecting non-standard data in machine learning-driven finance. Big Data & Society, 9(1), 20539517211070701. [7] Kumar, A., Hooda, S., Gill, R., Ahlawat, D., Srivastva, D., & Kumar, R. (2023, April). Stock Price Prediction Using Machine Learning. In 2023 International Conference on Computational Intelligence and Sustainable Engineering Solutions (CISES) (pp. 926-932). IEEE. [8] Lakshmi, P. S., Deepika, N., Lavanya, V., Mary, L. J., Thilak, D. R., & Sylvia, A. A. (2022, December). Prediction of Stock Price Using Machine Learning. In 2022 International Conference on Data Science, Agents & Artificial Intelligence (ICDSAAI) (Vol. 1, pp. 1-4). IEEE. [9] Loday, Y., Apirukvorapinit, P., & Vejjanugraha, P. (2023, May). Stock Price Prediction Using Modified Bidirectional Long Short-Term Memory and Deep Learning Models: A Case Study of Bhutan Tourism Corporation Limited Stock Data. In 2023 8th International Conference on Business and Industrial Research (ICBIR) (pp. 645-650). IEEE. [10] Majumder, A., Rahman, M. M., Biswas, A. A., Zulfiker, M. S., & Basak, S. (2022). Stock Market Prediction: A Time Series Analysis. In Smart Systems: Innovations in Computing: Proceedings of SSIC 2021 (pp. 389-401). Springer Singapore. [11] Ospina, R., Gondim, J. A., Leiva, V., & Castro, C. (2023). An Overview of Forecast Analysis with ARIMA Models during the COVID-19 Pandemic: Methodology and Case Study in Brazil. Mathematics, 11(14), 3069. [12] Pathak, A., & Shetty, N. P. (2019). Indian stock market prediction using machine learning and sentiment analysis. In Computational Intelligence in Data Mining: Proceedings of the International Conference on CIDM 2017 (pp. 595-603). Springer Singapore. [13] Rahmani, A. M., Rezazadeh, B., Haghparast, M., Chang, W. C., & Ting, S. G. (2023). Applications of artificial intelligence in the economy, including applications in stock trading, market analysis, and risk management. IEEE Access. [14] Yuan, X., He, C., Xu, H., & Sun, Y. (2023, February). Particle swarm optimization LSTM based stock prediction model. In 2023 3rd Asia-Pacific Conference on Communications Technology and Computer Science (ACCTCS) (pp. 513-516). IEEE. [15] Zandi, G., Torabi, R., Mohammad, M. A., & Jia, L. (2021). Research on stock portfolio based on time series prediction and multi-objective optimization. Advances in Mathematics: Scientific Journal 10(3), 1509-1528. https://doi.org/10.37418/amsj.10.3.37
Copyright
Copyright © 2023 Rishit Agrawal. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET55978
Publish Date : 2023-10-02
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online