

Ijraset Journal For Research in Applied Science and Engineering Technology
Energy-Efficient Approximate Multiplier with Flexible Precision
Authors: Ayushi Vinodia
DOI Link: https://doi.org/10.22214/ijraset.2024.61704
Certificate: View Certificate
Abstract
The method that can be utilized to increase accuracy and decrease energy use is approximate multiplication. A key component of many error-tolerant applications is multiplication. Approximate multipliers are increasingly utilized in energy-efficient computing for applications tolerant of inaccuracy. Apart from multiplier performance, determining the appropriate approximate multiplier is challenging due to considerations of area and delay. Therefore, selecting the type of approximate full adder (FA) becomes a crucial decision-making factor. These adders are employed for summing partial products in multipliers. This study presents the design and evaluation of an approximate multiplier employing four distinct approximate adders. The design undergoes simulation and synthesis using Xilinx and Model Sim. Compared to previously proposed approximate multipliers, the proposed circuits demonstrate substantial reductions in area, time delay, and power consumption. According to experimental data, the area, latency, and average power consumption of the suggested adjustable approximate multiplier can be lowered by 10%, 34.96 ns, and 300 mW when contrasted to the Wallace tree multiplier.
Introduction
I. INTRODUCTION.
Multipliers play a vital role in various applications like digital signal processing (DSP), computer vision, multimedia processing, image recognition, and artificial intelligence. These applications often require numerous multiplications, leading to significant power usage, especially challenging for mobile devices. Many studies propose reducing power consumption in multiplier circuits to address this issue. One approach is to approximate multiplication, especially for applications where some level of error tolerance is acceptable, such as those related to human perception. Because human senses have limitations, precise computation results may not always be necessary. The approximation multipliers reduce cell space, time delay, and power consumption at the expense of precision [1].
The prevalence of modern computing systems, whether they are pervasive, portable, embedded, or mobile, has sparked a rising need for ultra-low power consumption, compact size, and superior performance. A developing paradigm called approximate computing provides a way to accomplish these goals while compromising arithmetic precision. Many domains, including multimedia and big data analysis, can tolerate a certain level of computational inaccuracies, making them prime candidates for employing approximate computing techniques. focuses primarily on the design of approximate arithmetic units in hardware, including adders and multipliers, at various abstraction levels, including transistor, gate, RTL (Register Transfer Level), and application [2].
An approximate multiplier in VLSI design usually has 3 stages.
- Partial-product generation-input operands are decomposed into smaller sub-multiplications, which are combined to form the full product.
- Accumulation-The input operands are combined to form the full product.
- Final The output is produced depending upon the input operands.
The majority of approximation multipliers shorten the carry chains with configurable errors. When the operand's bit width rises, the algorithms utilized in the designs produce bigger magnitude errors for smaller numbers.
Power area and delay efficiency of approximate multiplier design-Removal partial product generation and accumulation for lower order input operands.
The computational method can therefore be applied to situations where an approximate answer is adequate for the intended purpose, but it also delivers a potentially incorrect result instead of a guaranteed one.
II. METHODS FOR DIGITAL ARITHMETIC [RELATED WORK]
In practically all applications involving digital signal processing, multiplication is a fundamental arithmetic operation. Hardware multipliers are necessary for DSP systems to effectively implement DSP algorithms. The digital processing units' speed is directly impacted by the multiplier's “speed [3–5].
The literature has a large number of fast multipliers that can be utilized to” create an effective digital oscillator [6,7-10]. The addition is the fundamental function of a multiplication algorithm, regardless of the multiplicity technique. We examine the most typical adder architectures in this section. Multi-operand addition methods are utilized to better improve multiplication addition “processes [11].
A. Carry Save Adder (3:2 Adder/3:2 Counter)
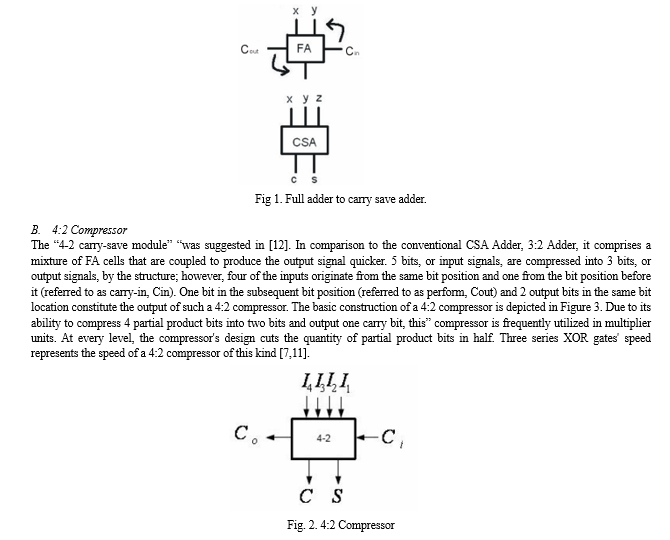
The Carry Save Adder (CSA) belongs to the category of redundant number system adders. It is employed for adding multiple binary vectors, such as x, y, and z, to produce 2 binary vectors—S and C—where x + y + z = S + C. This addition operation can be executed in constant time (O(1)) as the carry bits are preserved in the C vector, eliminating the need for carry propagation. The final binary vectors (S + C) are added using a conventional number system adder, such as the carry look-ahead adder, to yield the result of the multi-operand addition. The FA can be viewed as a 1-bit CSA, as” Fig. 2 illustrates.






Conclusion
In this investigation, several approximation multipliers based on approximation in partial product summation were constructed, assessed, and compared. The architecture may multiply 32-bit input and produce 64-bit output; the design space of approximate multipliers is discovered to be mostly reliant on the type of approximation FA utilized. Compared with the different existing multipliers our proposed multiplier has less area that is several Slice LUT (Look Up Table)- The area is 19200 and utilization is only 10% the minimum is the utilization is the area consumption will be less, time delay is less and power consumption is less which is 34.96 ns, and 300 mW in contrast to the Wallace tree multiplier, Booth multiplier and other existing multiplier which shows that our suggested approximate multiplier is more efficient and flexible.
References
[1] F. Y. Gu, I. C. Lin, and J. W. Lin, \"A Low-Power and High-Accuracy Approximate Multiplier With Reconfigurable Truncation,\" in IEEE Transactions on Very Large Scale Integration (VLSI) Systems, vol. 10, pp. 2022. [2] P. Kulkarni, P. Gupta, and M. Ercegovac, “Trading accuracy for power with an underdesigned multiplier architecture,” in VLSI Design, 2011, pp. 346–351. [3] C. K. Koc, “Parallel Canonical Recording,” Electronics Letters, Vol. 32, No. 22, 1996, pp. 2063-2065. doi:10.1049/el:19961402. [4] A. D. Booth, “A Signed Binary Multiplication Technique,” Quarterly Journal of Mechanics and Applied Mathematics, Vol. 4, No. 2, 1951, pp. 236-240. doi:10.1093/qjmam/4.2.236. [5] C. S. Wallace, “A Suggestion for a Fast Transactions on Electronic Multiplier,” IEEE Computers, Vol. 13, No. 2, 1964, pp. 14-17. doi:10.1109/PGEC.1964.263830. [6] M. D. Ercegovac and T. Lang, “Digital Arithmetic,” Morgan Kaufmann Publishers, Burlington, 2003. [7] D. Villeger and V. G. Oklobdzija, “Evaluation of Booth Encoding Techniques for Parallel Multiplier Implementation,” Electronics Letters, Vol. 29, No. 23, 1993, pp. 2016-2017. doi:10.1049/el:19931345 [8] V. G. Oklobdzija and D. Villeger, “Improving Multiplier Design by Using Improved Column Compression Tree tion and Genand Optimized Final Adder in CMOS Technology,” IEEE Transactions on Very Large Scale Integration (VLSI) Systems, Vol. 3, No. 2, 1995, pp. 292-301. [9] V. G. Oklobdzija, D. Villeger and S. S. Liu, “A Method for Speed Optimized Partial Product Reduction of Fast Parallel Multipliers Using an Algorithmic Approach,” IEEE Transactions on Computers, Vol. 45, No. 3, 1996, pp. 294-306. doi:10.1109/12.485568 [10] P. F. Stelling and V. G. Oklobdzija, “Optimal Circuits for Parallel Multipliers,” IEEE Transactions on Computers, Vol. 47, No. 3, 1998, pp. 273-285. [11] A. Weinberger and J. L. Smith, “An L Addition,” National Bure logic for High-Speed au of Standards Circulation, Vol.591,1985, pp. 3-12. [12] A. Weinberger, “4:2 Carry-Save Adder Module,” IBM Technical Disclosure 3811-3814. [21] D. Villeger and V. G. Oklobdzija, “Analysis of Booth Encoding Ef pressors for Reduction of Partial Products,” 1993 Conference Record of The Twenty-Seventh Asilomar Conference on Signals, Systems, and Computers, Vol. 1, 1993, pp. 781-784. [13] K. N. Singh and H. Tarunkumar, \"A review on various multipliers designs in VLSI,” Annual IEEE India Conference, pp 1-4, 2015 [2] B. Lamba, and A. Sharma, \"A review paper on different multipliers based on their different performance parameter”, 2nd International Conference on Inventive Systems and Control, pp 324-327, 2018. [14] Savita Nair, “A review paper on comparison of multiplier based on performance parameter”, International journal of computer application, vol-2, pp 6-9, 2014. [15] Bhawna Singroul, Pallavee Jaiswal, “A review on performance Evaluation different digital multiplier in VLSI using VHDL”, International Journal of Engineering Research & Technology, vol-7, issue-5,2018. [16] Sumit Vaidya, Deepak Dandekar, “A review on delay performance comparison of multiplier in VLSI circuit design”, International journal of computer network & communication, Vol 2, issue 4, pp 47-55, 2010. [17] Soniya, Suresh Kumar, “A review of different types multiplier and multiplier accumulator unit”, International journal Emerging Trends and technology in computer science, vol-2, issue-4, pp 364-368, 2013. [18] Bhavya Lahari Gundapaneni, JRK Kumar Dabbakutti, “ A review on Booth Algorithm for the design of multiplier”, International Journal of Innovative Technology and Exploring Engineering, vol-8, issue-7, pp 1506-1509, 2019. [19] Kiran Kumar, S. Anusha, G. Y. Rekha, “A design of low power modified Booth multiplier”, International journal of current engineering and scientific research, vol-5, issue-4, pp 287-292, 2018. [20] A. D. BOOTH, “A signed Binary multiplication technique”, in the journal of Mech. APPL. Math, Oxford University Press, vol-4, pp 236-240,1951. [21] Shweta S. Khobragade, Swapnil P. Kormore, “A review on low power VLSI design of Modified Booth multiplier”, International Journal of Engineering and Advanced Technology, vol-2, issue-5, pp 463-466, 2015.
Copyright
Copyright © 2024 Ayushi Vinodia. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET61704
Publish Date : 2024-05-06
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online