

Ijraset Journal For Research in Applied Science and Engineering Technology
Enhanced Virtual Try on for Clothing using Deep learning
Authors: Damini Ravindra Dube, Aakanksha Girish Borse, Mansi Pravin Tamkhane, Ruchita Sahebrao Wagh
DOI Link: https://doi.org/10.22214/ijraset.2024.61440
Certificate: View Certificate
Abstract
An increasing number of individuals are shopping online, particularly for clothing. However, while purchasing online, actual try-ons are not allowed, which limits the customer’s ability to see how a garment would appear on them. To enable buyers to virtually try on the desired clothing from an online store, an imagebased try-on system was devised. The ability to practically put on several clothes has increased customer interest in shopping. Image Recognition and Feature Extraction was the important part of the model to get desired outcomes. And To address these problems, we implement the CP-VTON+ (Clothing shape and texture Preserving VTON), which performs substan- tially better than the most advanced in sense of both quantitative and qualitative evaluations. The CP-VTON+ model not only adapt to detangle clothes from the person, but also maintains the clothing’s details on the try-on outcomes.
Introduction

I. INTRODUCTION
In the era of virtual shopping Virtual try-on technology is growing in importance, and as a result, a sizable quantity of research is being focused on this field. In the fashion and retail sectors[11], the idea of virtual try-ons is getting a lot of steam. It presents a fresh approach to age-old problems like fit concerns and the inability to physically interact with garments while purchasing online. Customers may experiment with a wide range of designs, colours, and sizes, browse a broad assortment of clothing options, and make more educated buying decisions from the comfort of their own homes with virtual try-on technology. The difficulties and excessive expense of 3D model-based methods have led to the recent rise in popularity of 2D image-based VTON technology. In the earlier works, there were many system configurations, one of which included an picture of tryon clothes. Having a target person picture had been thought to be useful in several projects. The try-on clothes[4] are first distorted to bring into with the target person (referred to as the Geometric Matching Module (GMM))[13], and then warped clothing is mixed with the target person picture (referred to as the Try-On Module (TOM))[21]. This is a typical processing pipeline for this scenario. We employ this configuration as well.
With its ability to close the gap between traditional brick- and-mortar stores and e-commerce, this technology could improve online purchasing and boost consumer happiness. We will go deeper into the many facets of virtual try-on technology in this research, including its enormous effects on the fashion business[23], its underlying technological workings, the plethora of advantages it provides, and the possible problems that may arise as it develops further. We’ll look at how virtual try-ons are changing the retail scene and how customers interact with fashion.
The majority of current techniques, including CP-VTON+[13] and VITON [7], approach, these writers all made equal contributions. The difficulty of image inpainting using virtual- try-on. To be more precise, these models try to overlay a picture of a latest outfit over the torso of a person dressed in something else. Two main steps are often involved in the models: Two modules are available: 1) Geometric Warping[13], which teaches how to geometrically warp clothing to fit the target Human’s stance and body type, and 2) Try-on, which combines the warped clothes with the target human’s image.
II. IMPORTANT TERMS
A. Virtual Try-on
Research on virtual try-ons [1] stems from vogue editing, which aims to replace items in an efficient manner. Initially, the dimensionality reduction approach and computer graph- ics model are designed for try-on generation. CNNs have made tremendous advancements in learning-based methodolo- gies.These techniques fall into two categories: 2D- and 3D- based[14] techniques. Since 2D approaches capture data in a lightweight manner, they are suitable for real-world scenarios and have gained popularity. Unfortunately, the lack of linked triplet data—that is, a reference individual, a target in-store item, and the individual wearing the item—makes training a 2D-based try- on model still difficult.
B. Feature Extraction
In machine learning, the process of turning raw data into a set of features that are more representative and informative for a given task is known as feature extraction. Reducing the dimensionality[15] of the data while keeping pertinent information is the aim. It is common practice to use feature extraction[15] to different kinds of data, including text, image, and numerical data. By concentrating on the most pertinent information in the data, feature extraction enhances the effectiveness of models and is a critical phase in the machine learning process. The type of data being used and the demands of the work at hand determine which feature extraction technique is best. Feature extraction describes to the predominant method of transforming raw data into usable information of mathematical elements that can be handled while saving the data in the first informational index.
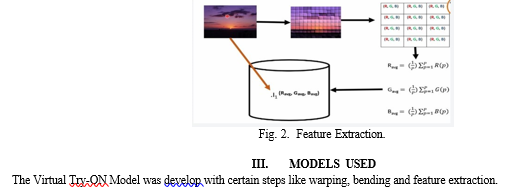
III. MODELS USED
The Virtual Try-ON Model was develop with certain steps like warping, bending and feature extraction.
A. GMM
The majority of the system’s GMM [1] is based on a 2017 publication titled ”Convolutional neural network architecture for geometric matching” [15] which was published. In the pa- per, a new CNN architecture is used to estimate the parameters of a geometric transformation between two input images. This architecture is intended to resemble the several phases of the traditional computer vision pipeline. Using a local descriptor, both input images are extracted in the first step. In the second stage, a collection of tentative correspondences is formed by matching descriptors across pictures. The last steps involve estimating the geometric model’s parameters by RANSAC [22] or Hough voting.
B. TOM
- Combining the wrap cloths with the intended recipient is the primary function of the try-on module [1]. Two techniques are combined in the try-on module. The initial step is to maintain the features of the warped cloths[13], which will be pasted straight over the picture of the intended recipient. But the drawback of this is that it will cause an odd look at the cloth’s edge, occulting parts of the body that are not wanted.
- At the end of TOM, a synthesizing discriminate is used to enhance the image generated. The synthesizing discrim- inate is SN-PatchGAN [13] that takes in the result and the ground truth image.
C. CP-VTON+
It’s also helpful to deal with highly warped and misaligned clothing. To ensure a fair comparison, the same dataset was used in the CP-VTON+[13] and a 256×128 synthesized result was obtained.CP-VTON+ is a picture based VTON framework that upgrades the nature of attire disfigurement and the take a stab at results by working on the information configuration and misfortune capability for the learning informational index and framework. CP-VTON+ contains the accompanying two modules: a mathematical matching module (GMM) for chang- ing garments to the objective individual and a take a stab at module (TOM) for distorting garments to match the individual.
D. Clothes Warping
There are 2 consecutively associated encoder-decoder or- ganizations, one encoder in the garments distorting module. By and large, utilize the Densepose descriptor to remove the human surface portrayal of the info picture I1, which is meant as D. Then we send D and C2 into an encoder-decoder network named as MPN[13]. The MPN will create the cover of the garments district (i.e., Mclothes1) also, skin district (i.e., Mskin1) of the information picture, which are utilized as the earlier direction for additional warping and generate individually.
E. Blending Stage
Upgrades to the TOM stage are three overlap. First and foremost, in request to hold the other human parts other than the target clothing region, the wide range of various regions, e.g., face, hair, lower garments and lower limb are added to the human portrayal contribution of TOM. Also, in the cover misfortune term in the TOM misfortune capability, we supplant the Arrangement Cover with the managed truth cover for areas of strength for a veil

F. Dataset
VTON PLUS is the source of the dataset used. They include pairs of top garment images and about 19000 front views of ladies. 16253 of the 19000 cloths are useable pairs, which are further divided into training and testing sets. There are 14221 picture pairings in the training set and 2032 image pairs in the testing set. The dataset also includes person parse, cloth mask, and human posture key point.
IV. THE PROPOSED METHOD: CP-VTON+
CPVTON+,[13] our new VTON pipeline, was designed us- ing the pipeline structure of CP-VTON [22]. The architecture is shown in Fig 4.
As previously mentioned, we expanded the current CP-VTON implementation. We enhanced segmentation using automated refining, Employed a comparable environment for training as [22]:
”λ1 = λ V GG = λ mask = 1 and λ reg = 0.5.” (1)
We used the VITON PLUS clothing human dataset for all experiments.The CNN geometric matching [24] is the founda- tion of the CP-VTON GMM[15] network. In contrast to CNN geometric matching, which makes use of two colour pictures, CP-VTON GMM takes as inputs coloured try-on clothes, silhouettes, joint heatmaps, and binary mask information. Our
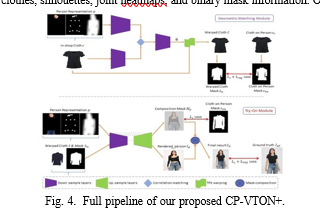
GMM employs a garment mask since the coloured texture from the try-on clothes does not aid in the matching process.To ensure minimal differences in warping between the previous and subsequent grid-gaps in the equation, our grid warping regularization is established based on the grid deformation rather than the TPS parameters for ease of visualization and comprehension.
V. LITERATURE REVIEW
Sangho Lee, Seoyoung Lee and Joonseok Lee (2022) [2] their research introduces the Clothes Fitting Module (CFM)[1] within the three-step Details-Preserving Virtual Try-On (DP-VTON)[1] model to effectively disentangle the characteristics of the person and source clothes. By employing VGG loss (LVGG) and L1 loss (L1) for training, DP-VTON significantly enhances the quality of virtual try-on experiences, outperforming the most up-to-date methods like CP-VTON+[13], ACGPN[19], and PFAFN. DP-VTON[1]
Expresses the target clothing’s detailed characteristics accurately and faithfully, seamlessly fits various pose and body shape, addressing limitations observed in other approaches and advancing the field of virtual try-on technology CP-VTON (Wang et al., 2018)[3] Wang et al. presented Trademark Safeguarding Picture put together Virtual Attempt With respect to Organize (CPVTON) that can accomplish a persuading take a stab at picture unions. Contrasted with other networks, it is additionally ready to safeguard the qualities of fabric better also. CP-VTON is separate to two sections, to be specific the Mathematical matching module (GMM) and take a stab at module (TOM). Initial segment is Mathematical Matching Module (GMM) which is utilized to change the garments of the focus into distorted dressed. Then, it is lined up with a portrayal of the information individual. Moreover, in GMM, there is a proposition of another learnable meager plate spline (TPS) change
Conclusion
Image-based virtual try-on for clothes project marks a significant step towards revolutionizing the fashion and retail industry. It directly addresses the longstanding challenge of online shopping, where customers often grapple with uncer- tainties about fit and style. By providing an engaging, virtual platform for customers to preview clothing on their own digital avatars, this technology fosters a more confident and informed shopping experience. With a substantial reduction in return rates, consumers benefit from time and cost savings, while retailers can streamline their operations and harness data- driven insights. Our enhanced image-based VTON system, CPVTON+, addresses the shortcomings of earlier methods, including incorrect human representation, flawed datasets, network architecture, and imprecise cost functions. The CP- VTON+ enhances the performance
References
[1] S. Lee, S. Lee and J. Lee, ”Towards Detailed Characteristic-Preserving Virtual Try-On,” 2022 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), New Orleans, LA, USA, 2022, pp. 2235-2239. [2] Wen-Huang Cheng, Sijie Song, Chieh-Yun Chen, Shintami Chusnul Hidayati, and Jiaying Liu. Fashion Meets Computer Vision: A Survey. ACM Computing Surveys, 54(4):1–41, 2021. [3] J. Yao and H. Zheng, ”LC-VTON: Length Controllable Virtual Try-on Network,” in IEEE Access, vol. 11, pp. 88451-88461, 2023. [4] Du, C., Yu, F., Jiang, M. et al. High fidelity virtual try-on network via semantic adaptation and distributed componentization. Comp. Visual Media 8, 649–663 (2022). [5] Seunghwan Choi, Sunghyun Park, Minsoo Lee, and Jaegul Choo. Viton- HD: High-resolution virtual try-on via misalignment-aware normaliza- tion. In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2021 [6] T. Wang, X. Gu and J. Zhu, ”A Flow-Based Generative Network for Photo-Realistic Virtual Try-on,” in IEEE Access, vol. 10, pp. 40899- 40909, 2022. [7] Xintong Han, Zuxuan Wu, Zhe Wu, Ruichi Yu, and Larry S. Davis. VI- TON: An image-based virtual try-on network. In Proc. of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), 2018. [8] A. Mir, T. Alldieck, G. Pons-Moll, “Learning to Transfer Texture from Clothing Images to 3D Humans,”. in IEEE Conference on Computer Vision and Pattern Recognition. 2020. [9] J. Xu, Y. Pu, R. Nie, D. Xu, Z. Zhao and W. Qian, ”Virtual Try-on Network With Attribute Transformation and Local Rendering,” in IEEE Transactions on Multimedia, vol. 23, pp. 2222-2234, 2021 [10] C. Ge, Y. Song, Y. Ge, H. Yang, W. Liu and P. Luo, ”Disentangled Cycle Consistency for Highly-realistic Virtual Try-On,” 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 2021, pp. 16923-16932. [11] J.C. Patel, Z. Liao, G. Pons-Moll, “TailorNet: Predicting Clothing in 3D as a Function of Human Pose, Shape and Garment Style,”. in IEEE Conference on Computer Vision and Pattern Recognition. 2020. [12] J.Lee, H. J.; Lee, R.; Kang, M.; Cho, M.; Park, G. LA-VITON: A [13] network for looking-attractive virtual try-on. In: Proceedings of the IEEE/CVF International Conference on Computer Vision Workshop, 3129–3132, 2019. [14] Matiur Rahman Minar, Thai Thanh Tuan, Heejune Ahn, Paul Rosin, and Yu-Kun Lai. CP-VTON+: Clothing shape and texture preserving image-based virtual try-on. In CVPR Workshops, 2020. [15] J. M. Sekine, K. Sugita, F. Perbet et al., “Virtual fitting by single- shot body shape estimation,”. in Int. Conf. on 3D Body Scanning Technologies. Citeseer, pp. 406-413, 2014. [16] Rocco, I.; Arandjelovic, R.; Sivic, J. Convolutional neural network archi- tecture for geometric matching. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 2 [17] J.D. Yoo, N. Kim, S. Park et al., “Pixel-level domain transfer,”. in European Conference on Computer Vision. Springer, Cham, pp. 517- 532, 2016. [18] J. C. Lassner, G. Pons-Moll et al., “A generative model of people in clothing,”. in IEEE International Conference on Computer Vision, pp. 853-862, 2017 [19] J. Wang, W. Zhang, W Liu et al., “Down to the Last Detail: Virtual Tryon with Detail Carving,”. 2019. [20] H. Yang, R. Zhang, X. Guo et al., “Towards Photo-Realistic Vir- tual TryOn by Adaptively Generating-Preserving Image Content,”. in IEEE/CVF Conference on Computer Vision and Pattern Recognition, [21] pp. 7850-7859, 2020 [22] J. Duchon, “Splines minimizing rotation-invariant semi-norms in Sobolev spaces,”. in Constructive theory of functions of several vari- ables. Springer, Berlin, Heidelberg, pp. 85-100, 1977. [23] X. Han, Z. Wu, Z. Wu et al., “Viton: An image-based virtual try- on network,” in IEEE conference on computer vision and pattern recognition, pp.7543-7552, 2018. [24] B. Wang, H. Zheng, X. Liang et al., “Toward characteristic-preserving image-based virtual try-on network,”. in European Conference on Com- puter Vision (ECCV), pp.589-604, 2018. [25] Ma, Q. L.; Yang, J. L.; Ranjan, A.; Pujades, S.; PonsMoll, G.; Tang, [26] S. Y.; Black, M. J. Learning to dress 3D people in generative clothing. In: Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 6468–6477, 2020. [27] Ignacio Rocco, Relja Arandjelovic, and Josef Sivic. Convolutional neural network architecture for geometric matching. In CVPR, pages 6148–6157, 2017 [28] Bochao Wang, Hongwei Zhang, Xiaodan Liang, Yimin Chen, Liang Lin, and Meng Yang. Toward characteristic-preserving image-based virtual try-on network. In ECCV, 2018.
Copyright
Copyright © 2024 Damini Ravindra Dube, Aakanksha Girish Borse, Mansi Pravin Tamkhane, Ruchita Sahebrao Wagh. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET61440
Publish Date : 2024-05-01
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online