

Ijraset Journal For Research in Applied Science and Engineering Technology
Enhancing Human-Robot Interaction through Voice-Driven Natural Language Processing System
Authors: Ms. Sayali Parab, Mr. Chayan Bhattacharjee
DOI Link: https://doi.org/10.22214/ijraset.2024.65921
Certificate: View Certificate
Abstract
With robotics rapidly advancing, more effective human-robot interaction is increasingly needed to realize the full potential of robots for society. While spoken language must be part of the solution, our ability to provide spoken language interaction capabilities is still limited. Voice communication with robots has the potential to greatly improve human-robot interactions and enable a wide range of new applications. However, there are still many challenges that need to be overcome in order to fully realize this potential, and further research and development is needed in areas such as noise reduction and dialogue management. This paper explores the current state of the technology, including the challenges and limitations that still need to be overcome.
Introduction
I. INTRODUCTION
Voice communication can be used to control and interact with robots. This includes both command-based interfaces, where the user gives specific commands to the robot, and more natural language interfaces, where the robot can understand and respond to more conversational interactions. We will also look at the various technologies that are currently being used to enable voice communication with robots, such as automatic speech recognition and natural language processing.
Alongside this, some challenges still need to be overcome to improve the functionality and usability of voice communication with robots. These include issues such as noise and ambient sound, which can make it difficult for the robot to accurately understand the user's commands, and the need for more sophisticated dialogue management systems that can handle more complex interactions.
The potential applications of voice communication with robots, including in industries such as healthcare, retail, and manufacturing. For example, in healthcare, robots with voice communication capabilities could assist with tasks such as patient monitoring and medication reminders. In retail, robots could be used to assist customers with finding and purchasing products, and in manufacturing, robots could be used to improve efficiency and productivity by allowing workers to give voice commands to the robot. Voice communication with robots also includes the potential for further advancements in the technology and the impact it may have on society. This may include the development of more advanced natural language interfaces that can understand and respond to more nuanced and context-aware interactions.
II. BACKGROUND AND CONCEPTS
The current state of voice communication technology includes several key components such as automatic speech recognition, natural language processing, and text-to-speech synthesis. Automatic Speech Recognition (ASR) is a technology that allows computers to convert spoken words into text. It involves the analysis of speech signals, the identification of linguistic units such as phonemes and words, and the recognition of the speaker's intent. Natural language processing (NLP) is a branch of artificial intelligence that deals with the interaction between computers and human languages. It enables computers to understand, interpret, and generate human language. Text-to-speech synthesis (TTS) is a technology that allows computers to convert written text into spoken words. It involves the analysis of text, the generation of speech signals, and the synthesis of a voice that sounds natural.
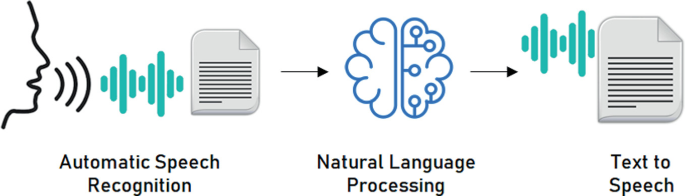
Fig 1: Essential Components for Voice Communication with Machine
A. Automatic speech recognition (ASR)
It is a technology that allows computers to convert spoken words into written text. It is a subfield of artificial intelligence and natural language processing that deals with the recognition and interpretation of spoken language. The ASR system typically consists of several components such as an acoustic model, a language model and a decoder. The acoustic model is trained to recognize the sounds of speech, and maps the sounds to a sequence of phonemes, which are the basic units of sound in a language. The language model is trained to recognize the structure of a language, such as grammar and syntax, and is used to predict the most likely word or phrase given the phonemes and context. The decoder combines the output of the acoustic and language models to generate the final transcription. ASR technology can be used in a wide range of applications such as speech-to-text transcription, voice commands, virtual assistants, and speech-enabled interactive systems. It is used in many industries such as healthcare, finance, retail, automotive and many more. ASR technology has advanced significantly in recent years and has become more accurate and efficient, thanks to the use of deep learning algorithms and the availability of large amounts of data. However, ASR systems still face some challenges, such as dealing with different accents, dialects, and noise in the environment. Additionally, ASR systems can be affected by factors such as the speaker's gender, age, and emotional state, which can also impact their performance. Overall, automatic speech recognition is a powerful technology that allows computers to understand and transcribe spoken language. As the technology continues to evolve, it will likely become even more accurate and versatile, leading to new and improved applications in a wide range of fields.
B. Natural Language Processing (NLP)
It is a subfield of artificial intelligence and computational linguistics that deals with the interaction between computers and human (natural) language. It is a set of techniques that enables computers to understand, interpret and generate human language. The goal of NLP is to make it possible for computers to understand, interpret and generate natural language, just as humans do. NLP techniques are used in a variety of applications such as language translation, text summarization, sentiment analysis, question answering and many more. NLP systems typically have several components such as a morphological analyser, a syntactic parser, a semantic role labeller, and a pragmatic analyser. The morphological analyser is responsible for identifying the root form of the words and the grammatical structure. The syntactic parser is responsible for identifying the grammatical roles of the words in a sentence. The semantic role labeller is responsible for identifying the relationships between the words in a sentence. The pragmatic analyser is responsible for identifying the intended meaning of the sentence.
NLP technology has advanced significantly in recent years and has become more accurate and efficient, thanks to the use of deep learning algorithms and the availability of large amounts of data. However, NLP systems still face some challenges, such as dealing with ambiguity, context and sentiment. Additionally, NLP systems are affected by factors such as the domain, tone, and style of the language, which can also impact their performance. Overall, Natural Language Processing is a powerful technology that allows computers to understand, interpret, and generate human language. As the technology continues to evolve, it will likely become even more accurate and versatile, leading to new and improved applications in a wide range of fields, such as voice assistants, chatbots, text-to-speech, and many more.
C. Text-to-speech synthesis (TTS)
It is a technology that allows computers to convert written text into spoken words. It is a subfield of natural language processing and speech processing that deals with the generation of synthetic speech. The TTS system typically consists of several components such as a text analysis module, a prosody model, and a speech synthesizer. The text analysis module is responsible for analyzing the input text and breaking it down into smaller units such as phrases, sentences, and words. The prosody model is responsible for generating the appropriate intonation, rhythm, and stress to make the synthetic speech sound more natural. The speech synthesizer is responsible for generating the actual audio output based on the prosody model. TTS technology can be used in a wide range of applications such as speech-enabled interactive systems, voice assistants, and screen readers for the visually impaired. It is also used in industries such as healthcare, finance, retail, automotive and many more. TTS technology has advanced significantly in recent years and has become more accurate and natural-sounding, thanks to the use of deep learning algorithms and the availability of large amounts of data. However, TTS systems still face some challenges, such as dealing with different accents, dialects, and languages. Additionally, TTS systems can be affected by factors such as the speaker's gender, age, and emotional state, which can also impact their performance. Overall, Text-to-speech synthesis is a powerful technology that allows computers to generate spoken words from written text. As the technology continues to evolve, it will likely become even more accurate and natural-sounding, leading to new and improved applications in a wide range of fields.
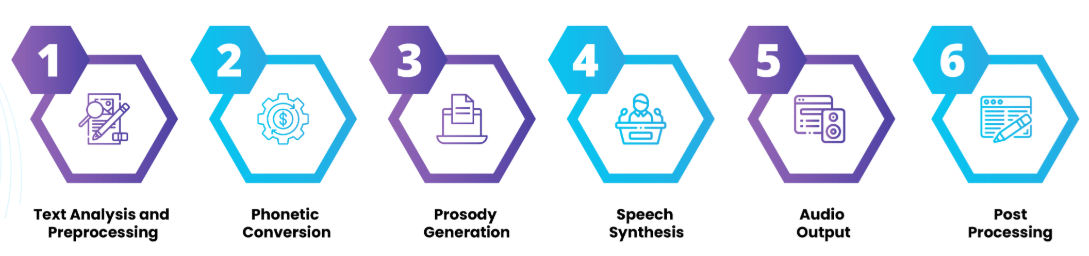
Fig 2: Working of Text-To-Speech
III. VOICE COMMUNICATION TYPES
There are several types of voice communication with robots, each with its own set of advantages and limitations. Some of the main types of voice communication with robots include:
- Command-based Interfaces: These interfaces rely on the use of pre-defined commands that the user must speak in order to interact with the robot. These interfaces are generally easy to use and understand, but they can be limited in terms of the types of interactions that are possible.
- Natural Language Interfaces: These interfaces allow users to interact with the robot using more natural and conversational language. These interfaces are generally more flexible and can handle a wider range of interactions, but they can be more complex to design and implement.
- Speech-to-text: This type of voice communication is used to transcribe the user's speech into text, which can then be used for further processing. This type of voice communication is widely used for tasks such as dictation and transcription.
- Text-to-Speech: This type of voice communication is used to convert text into speech, which can then be used to generate an audio output from the robot. This type of voice communication is widely used for tasks such as voice assistants, automated phone systems, and other applications where the robot must speak to the user.
- Biometric Voice: This type of voice communication uses biometric features like pitch, tone, and rhythm of the user's speech, to identify the user and authenticate them.
- Multimodal Interfaces: This type of voice communication is a combination of other types of voice communication, such as speech-to-text, text-to-speech, and command-based interfaces, to provide a more natural and intuitive interaction with the robot.
IV. BENEFITS, EASE OF USE AND SECURITY CONCERNS
A. Benefits Of Voice Interaction With Robots
- Spoken language has the potential to often be the fastest and most efficient. Speed is critical for robots capable of interacting with people in real time. Especially in operations where time is of the essence, slow performance is equivalent to failure. Speed is required not only during the action, but also in the human-robot communication, both prior to and during execution. This interaction will enable new dimensions of human-robot cooperative action, such as the realtime coordination of physical actions by human and robot.
- Spoken language interaction is socially potent, and will enable robots to engage in more motivating, satisfying, and reassuring interactions, for example, when tutoring children, caring for the sick, and supporting people in dangerous environments.
- As robots become more capable, people will expect speech to be the primary way to interact with robots, that you can talk with may be simply better liked, a critical consideration for consumer robotics.
- Robots can be better communicators than disembodied voices; being co-present, a robot’s gestures and actions can reinforce or clarify a message, help manage turn-taking more efficiently, convey nuances of stance or intent, and so on.
- Building speech-capable robots is an intellectual grand challenge that will drive advances across the speech and language sciences and beyond. Not every robot needs speech, but speech serves functions that are essential in many scenarios. Meeting these needs is, however, beyond the current state of the art.
B. Ease of use with Voice communication
- Hands-free operation: By using voice commands, users can control and interact with robots without having to use their hands. This can be especially useful in situations where the user's hands are occupied or in environments where it is not safe or practical to use traditional input methods.
- Efficiency and Productivity: Voice communication can make it easier for users to give commands to robots, which can improve efficiency and productivity in tasks such as manufacturing, retail, and healthcare. For example, in a manufacturing setting, a worker could use voice commands to control a robot and automate repetitive tasks, freeing up their hands to perform other tasks.
- Improved Accessibility: Voice communication can make robots more accessible to people with disabilities or limited mobility. For example, voice-controlled robots could help people with limited mobility to perform tasks that would otherwise be difficult or impossible for them to do.
- Increased Convenience: Voice commands can be more convenient for users than traditional input methods, such as buttons or touchscreens. For example, users can control their home appliances or smart devices with voice commands instead of manually turning them on or off.
- Better user Experience: Voice communication can lead to a more natural and intuitive interaction between the user and the robot, which can improve the overall user experience. For example, a customer service chatbot that can understand and respond to natural language inputs can make it more pleasant to interact with.
Overall, voice communication with robots can help to ease user work by making it faster, more efficient, and more convenient for users to interact with and control robots. As the technology continues to evolve, it will likely lead to more advanced and sophisticated interactions that can help to further ease user work.
C. Security of Voice Communication
Voice communication with robots, like any other communication system, is not completely secure and may have some potential security risks.
- Eavesdropping: Voice communication can be intercepted by unauthorized parties, especially if the communication is not encrypted. This can potentially lead to sensitive information being compromised.
- Impersonation: An attacker could potentially use a recording of a user's voice to impersonate them and gain unauthorized access to the robot or the systems it is connected to.
- Privacy concerns: Voice communication systems can also raise privacy concerns, as they may collect and store audio data of the user's voice. This data can be used for targeted advertising or shared with third parties without the user's consent.
- Vulnerabilities: As with any technology, software vulnerabilities can be found and exploited by attackers. These vulnerabilities can be used to gain unauthorized access to the robot or the systems it is connected to.
To mitigate these risks, it is important to implement proper security measures such as encryption, secure authentication, and access control to protect the voice communication systems. Also, it's important to regularly update the software and ensure that the devices are not compromised.
There are also some best practices for securing voice communication with robots, such as using strong passwords, avoiding using easily guessable phrases, and being aware of the physical security of the devices. Additionally, it is important to be aware of the policies and practices of the companies that provide the voice communication technology, to ensure that they are taking steps to protect user data and privacy. In conclusion, voice communication with robots is not completely secure and has some potential security risks. However, by implementing proper security measures and following best practices, these risks can be minimized and help to ensure the security of the communication.
V. LIMITATIONS AND APPLICATION
A. Limitation of Voice Communications
- Noise and accent recognition: Robots may have difficulty understanding speech in noisy environments or recognizing different accents, which can lead to errors in speech recognition.
- Complexity of natural language understanding: Understanding human speech is a complex task, and robots may struggle to understand idiomatic expressions, sarcasm, and other nuances of human language.
- Privacy and security: Voice communication with robots involves the collection, storage, and processing of personal data, which raises concerns about privacy and security.
- Limited voice recognition and response: Robots may not be able to respond to all voice commands, or may not understand certain words or phrases.
- Limited context awareness: Robots may not be able to understand the context of a conversation, leading to confusion or misinterpretation of commands.
- Limited emotional recognition: Robots may not be able to understand the emotions behind a human voice, leading to a lack of empathy or understanding.
- Limited physical capabilities: Robots may not be able to physically act on all commands, such as reaching high places or lifting heavy objects.
- Cost and complexity: Developing advanced voice communication systems can be expensive, and the technology may be too complex for some applications.
B. Applications of Voice-Driven Robots
There are many real world examples of voice communication with robots being used in various industries. Some examples include:
- Healthcare: Robots with voice communication capabilities are being used in hospitals and care facilities to assist with tasks such as patient monitoring, medication reminders, and language translation for non-English speaking patients.
- Retail: Many retailers are now using robots with voice communication capabilities to assist customers with finding and purchasing products. For example, Lowe's has implemented LoweBot, a robot that uses voice recognition to help customers navigate the store and find products.
- Manufacturing: Robots with voice communication capabilities are being used in manufacturing environments to improve efficiency and productivity. For example, companies such as GE and Amazon are using robots that can be controlled using voice commands to automate tasks such as picking and packing.
- Home automation: Voice-controlled smart speakers and home automation devices such as Amazon Echo, Google Home and Apple Homepod are widely used for controlling lights, temperature, and other smart appliances in homes.
- Customer Service: Many companies are now using voice-controlled chatbots or virtual assistants that can handle customer queries and complaints through voice commands.
- Automotive: Many cars now come with voice-controlled infotainment systems which allow drivers to control various features of the car with voice commands.
These are just a few examples of how voice communication with robots is being used in the real world. The technology is continually evolving, and it is likely that we will see more and more applications of voice communication with robots in the future.
Conclusion
In conclusion, voice communication with robots is a promising technology with a wide range of potential applications. However, significant technical challenges must be overcome in order to achieve accurate and natural communication between humans and robots. Further research and development in natural language processing, speech recognition, and user interface design is needed to fully realize the potential of this technology.
References
[1] H. Yan, M. H. Ang, and A. N. Poo, “A survey on perception methods for human–robot interaction in social robots,” Int. J. Soc. Robot., vol. 6, no. 1, pp. 85–119, 2014 [2] P. Tsarouchi, S. Makris, and G. Chryssolouris, “Human–robot interaction review and challenges on task planning and programming,” Int. J. Comput. Integr. Manuf., vol. 29, no. 8, pp. 916–931, 2016. [3] N. Lubold, E. Walker, and H. Pon-Barry, “Effects of voice-adaptation and social dialogue on perceptions of a robotic learning companion,” in 2016 11th ACM/IEEE International Conference on Human-Robot Interaction (HRI), 2016, pp. 255–262. [4] M. Ahmad, O. Mubin, and J. Orlando, “A systematic review of adaptivity in human-robot interaction,” Multimodal Technol. Interact., vol. 1, no. 3, p. 14, 2017. [5] S. A. Alim and N. K. A. Rashid, “Some commonly used Badr & Abdul-Hassan | 11 speech feature extraction algorithms,” From Nat. to Artif. Intell. Appl., 2018. [6] K. Mannepalli, P. N. Sastry, and M. Suman, “Accent Recognition System Using Deep Belief Networks for Telugu Speech Signals,” in Proceedings of the 5th International Conference on Frontiers in Intelligent Computing: Theory and Applications, 2017, pp. 99–105. [7] M. Glodek et al., “Multiple classifier systems for the classification of audio-visual emotional states,” in International Conference on Affective Computing and Intelligent Interaction, 2011, pp. 359–368. [8] A. M. Badshah et al., “Deep features-based speech emotion recognition for smart affective services,” Multimed. Tools Appl., vol. 78, no. 5, pp. 5571–5589, 2019. [9] O. Mubin, J. Henderson, and C. Bartneck, “You just do not understand me! Speech Recognition in Human Robot Interaction,” in The 23rd IEEE International Symposium on Robot and Human Interactive Communication, 2014, pp. 637–642. [10] V. Deli? et al., “Speech technology progress based on new machine learning paradigm,” Comput. Intell. Neurosci., vol. 2019, 2019. [11] M. Tahon, A. Delaborde, and L. Devillers, “Real-life emotion detection from speech in human-robot interaction: Experiments across diverse corpora with child and adult voices,” 2011. [12] A. Poncela and L. Gallardo-Estrella, “Command-based voice teleoperation of a mobile robot via a human-robot interface,” Robotica, vol. 33, no. 1, p. 1, 2015.
Copyright
Copyright © 2024 Ms. Sayali Parab, Mr. Chayan Bhattacharjee. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65921
Publish Date : 2024-12-14
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online