

Ijraset Journal For Research in Applied Science and Engineering Technology
Enhancing In-Vitro Fertilization Outcomes through Machine Learning: A Comparative Analysis of Predictive Models and Dataset Evaluation
Authors: P. Malathi, Dr. M. Gomathi
DOI Link: https://doi.org/10.22214/ijraset.2024.65652
Certificate: View Certificate
Abstract
By enabling the fertilisation of eggs and sperm outside the body, in-vitro fertilisation (IVF) offers couples struggling with infertility hope through a complex medical procedure. The complex procedure involves causing the ovaries to release eggs, extracting the eggs, fertilising them with sperm in a lab environment to create embryos, and then putting the embryos into the uterus.Machine learning methodologies such as K-nearest neighbors (KNN), random forest, and support vector machine (SVM) exhibit potential in forecasting IVF outcomes and alleviating the physical and emotional burden associated with treatment. This study\'s objective was to examine several machine learning algorithms and assess the IVF dataset\'s reliability by contrasting it with other datasets. Consequently, the KNN model achieved a 64% accuracy rate, whereas the SVM, random forest, and logistic regression models obtained perfect accuracy rates of 100%. Assessing the IVF dataset using standardized data models through benchmarking helps confirm its quality, relevance, and importance, thus guiding efforts to improve IVF success rates. In essence, machine learning models are quite good at predicting the outcomes of IVF, which leads to customised reproductive therapies that improve IVF success.
Introduction
I. INTRODUCTION
In-vitro fertilization (IVF) embodies a meticulously transformative and revolutionary medical process that renders a ray of hope and confidence to individuals and couples struggling with sterility. Since it was first introduced in the late 1900s, IVF has developed into a commonly used method of assisted reproductive technology, allowing countless individuals around the globe to achieve their goal of becoming parents. IVF is the process of fertilising a sperm and egg outside of the human body, usually in a lab.[1], [2]. The first important step in this complex process is stimulating the ovaries to create numerous eggs. After that, these eggs are collected and mixed with the sperm in a controlled setting.
Following a time of cultivation, one or more viable embryos are chosen and placed inside the woman's uterus in the hopes that implantation will take place and the pregnancy would be successful. The journey through IVF is often characterized by emotional, physical, and financial challenges, as individuals navigate a series of medical procedures, fertility medications, and uncertainties about the treatment's outcome [4]. However, the potential outcome obtained from overcoming infertility, and achieving a successful pregnancy makes the IVF technique to be the most pursued beacon of hope for those struggling with reproductive complications [7].
Over the years, advancements in reproductive medicine and technology have refined IVF protocols, consecutively enhancing success rates, while parallelly broadening the scope of individuals who can benefit from this pioneering approach or treatment. As researchers continue to explore new techniques, such as predictive modeling using machine learning algorithms like K nearest neighbor (KNN), random forest (RF) and many other algorithms, the landscape of IVF is poised for continued improvement, offering even greater precision and personalization in fertility interventions[5].
The neoteric progressions in colossal technological domains like artificial intelligence and machine learning have spurred the application of predictive modeling methods in reproductive medicine. The indulgence in machine learning, deep learning, image processing and even robotic applications hold pivotal grounds to the augmentation of predictive accuracy in IVF[6].
These methodologies incorporated in the various phases of the process enable a more tailored and data-driven approach, while successfully maximizing the chances of healthy pregnancy. As the field of IVF continues to evolve, researchers and healthcare professionals are not only focused on improving success rates but also on minimizing the physical and emotional toll on individuals undergoing treatment[7] . The ongoing pursuit to precision and personalization in IVF reflects the commitment that could be rendered to expectant couples with the best possible chances of achieving their dream of successful and uncomplicated gestation.
This paper pivots on conducting a comparative analysis between IVF dataset and other several datasets which have integrated machine learning models. When incorporating algorithms in IVF dataset the efficacy of the approach accelerated toward successful and failed IVF practices, alongside establishing a benchmark for the IVF datasets in comparison to others. The indagation is structured with section II explicating the empirical review relevant to the IVF approach and the algorithms entailed, section III articulates the methodology, along with the workflow utilized in the simulative process, and section IV illustrating the results with the final section concluding the research with future work pertinent to the IVF process.
II. LITERATUREREVIEW
“Machine Learning Techniques to Improve the Success Rate in In-Vitro Fertilization (IVF) Procedure" by Patil N Sujata, S M Madiwalar, and V M Aparanji explores the application of machine learning in enhancing IVF success rates. In the field of IVF, embryo quality assessment is traditionally based on visual morphological methods, which may lead to variations in selection processes and subsequently lower success rates. In order to solve this, the study predicts, without the need for human involvement, the quality of embryos transplanted from Day 2 to Day 3. By training over 3000 embryo images using a CNN-based Azure model and validating the results with machine learning methods, the AI approach achieves a precision exceeding 0.98. This method not only improves efficiency but also holds the potential to generalize across different embryo selection scenarios, ultimately contributing to enhanced implantation and success rates in IVF procedures.
“Kapil Sethi, Ankit Gupta, Gaurav Gupta, and Varun Jaiswal's study, "Comparative Analysis of Machine Learning Algorithms on Different Datasets," uses two datasets to examine a number of machine learning algorithms, such as Neural Network (NN), KNN, and SVM. According to the study, SVM performs better than other approaches with high accuracy, indicating machine learning's promise for both experience-based and explanation-based learning. The study emphasises how crucial it is to comprehend and use machine learning in a variety of activities.
III. METHODOLOGY
This section delineates a structured methodology for constructing and deploying machine learning algorithms to forecast IVF outcomes, effectively blending data-driven methodologies with meticulous evaluation protocols. The workflow for this process is executed in Google Colab using Python, offering a comprehensive integration of sophisticated data models. This workflow is shown graphically in Figure 1, which highlights the methodical procedures required in the creation and application of predictive models for IVF results.
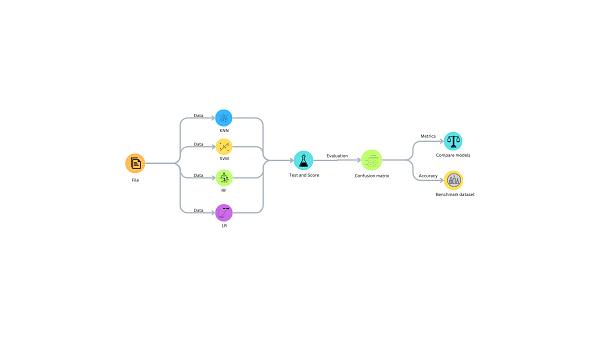
Fig 1: Workflow implementation
A. Data Collection
The data used to assess the diagnostic outcomes of IVF treatment considers information pertinent to the following attributes:
- Ovarian age of individuals undergoing IVF treatment.
- Smoking habits of the patients.
- Alcohol consumption habits.
- History of accidents or trauma.
- Previous surgical interventions undergone by the patients.
- Cryopreservation status indicating whether the sperm used is fresh or frozen.
- Type of embryo, categorized as cleavage or blastocyst, with cleavage representing the initial stage and blastocyst denoting a later phase of embryo development.
- Total number of embryos categorized into good, fair, and poor quality.
- Maximum number of embryos exhibiting heartbeats.
- Diagnostic outcome of the IVF treatment, indicating the success or failure of the procedure.
B. Preprocessing
Preprocessing involves converting categorical variables, such as smoking habits, alcohol consumption, history of accidents or trauma, previous surgical interventions, cryopreservation status (fresh or frozen sperm), and embryo type, into numerical representations. This conversion is essential for uniformity in data representation and analysis. Additionally, preprocessing includes addressing missing data in a systematic manner to ensure the completeness and accuracy of the dataset. Standardizing these features enables consistent and reliable processing for subsequent analysis and modeling tasks.
C. Model Building
1) K-Nearest Neighbor
The KNN algorithm is a straightforward approach that retains and categorizes new cases by assessing their similarity, typically using distance functions. KNN is often categorized as a lazy learner because it doesn't generate a distinct model. In the context of IVF profiles, KNN is employed to segment the data, considering factors such as the number of neighbors and the method of neighborhood classification, commonly implemented through Euclidean distance.[8] The below formula is indicative of the Euclidean distance, and is as follows:
D= (M2-M1)2+ (N2-N1)2 (1)
2) Support Vector Machine
SVM is a supervised learning technique used in regression analysis and classification.Widely employed in the medical field, SVM is particularly adept at classification tasks. It is capable of performing both linear and non-linear classifications, with the latter leveraging kernel tricks. In the context of classifying IVF outcomes as success or failure, the Radial Basis Functions (RBF) Kernel has been implemented to facilitate the classification process[8], [9]. The RBF kernel is incorporated with the below formula for activating the kernel given by
K=exp?(-g x-y2) (2)
Where g represents the gamma value, and x, y are the data points used for evaluation.
3) Random Forest
The RF method comprises a collection of tree predictors, where each tree is constructed independently through random vector sampling and shares the same distribution. The classifier error in a RF is influenced by the strength and correlation among the trees. Noteworthy advantages of RF include their convergence owing to the law of large numbers and their ability to avoid overfitting in predictions without requiring pruning[10], [11].
4) Logistic Regression
Logistic regression (LR) examines the association between numerous independent variables and a categorical dependent variable, estimating the By fitting data to a logistic curve, logistic regression (LR) estimates the probability of an event occurring by analysing the relationship between a large number of independent variables and a categorical dependent variable.
The LR model evaluation involves a number of components. In our study, LR is used to evaluate the model, pinpoint important parameters, and finally determine the model's discriminative or predictive accuracy [12]. We use LR to predict the likelihood of success rates in IVF procedures and to find the significant independent variables associated with our dependent variable.
Logit(pi) = 1/(1+ exp(-pi))
ln(pi/(1-pi)) = Beta_0 + Beta_1X_1 + … + B_kK_k (3)
LR serves as a classification algorithm that converts log-odds into probabilities, making it appropriate for binary classification tasks where the outcome ranges from 0 to 1.
5) Prediction and Evaluation
Ensemble models were employed in the predictive analysis of the IVF procedure to anticipate several elements impacting the IVF success rate outcomes. The model's performance is then rigorously checked using the confusion matrix. To support the evaluation of the model's accuracy, precision, recall, and overall efficacy with the included IVF dataset, this matrix enables a thorough split of predictions into True Positives (TP), True Negatives (TN), False Positives (FP), and False Negatives (FN)[13].
IV. RESULT
The findings from the technological implementations made throughout the research process are further explained in this section. It dives into the specifics of the reached throughputs, encompassing any necessary information, metrics, and observations recorded during the process. Comparison on machine learning models. This study assessed the efficacy of KNN, SVM, RF, and LR in predicting the success rate of IVF practices using a dataset containing 685 patient diagnosis records. The confusion matrix, a tool in binary classification, illustrates the model's predictions against the actual conditions from the dataset. It utilizes parameters such as TP, FP, TN, and FN. Based on the confusion matrix (Figure 2) findings, it is observed that SVM, RF, and LR models achieve a maximum accuracy of 100%. Conversely, KNN exhibits a maximum accuracy of 64%. Consequently, SVM, RF, and LR models demonstrate superior accuracy compared to KNN, which yields the lowest accuracy among the models assessed.
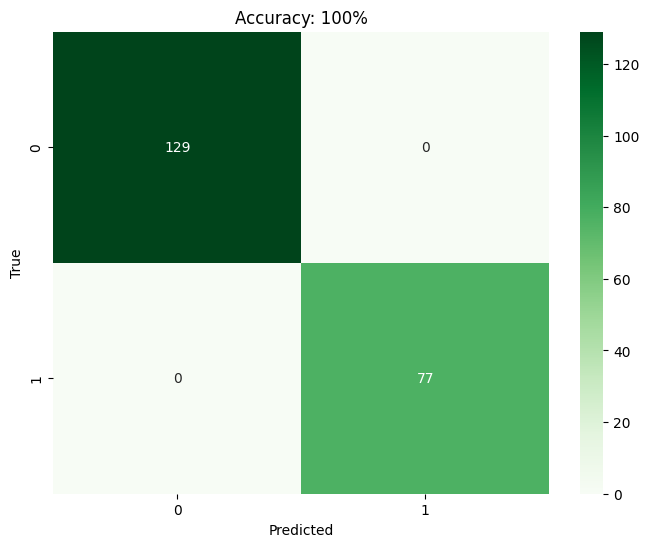
(a)
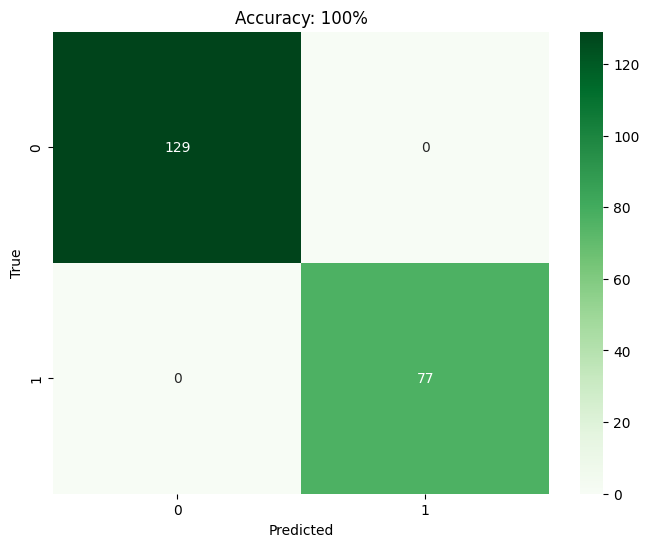
(b)

(c)
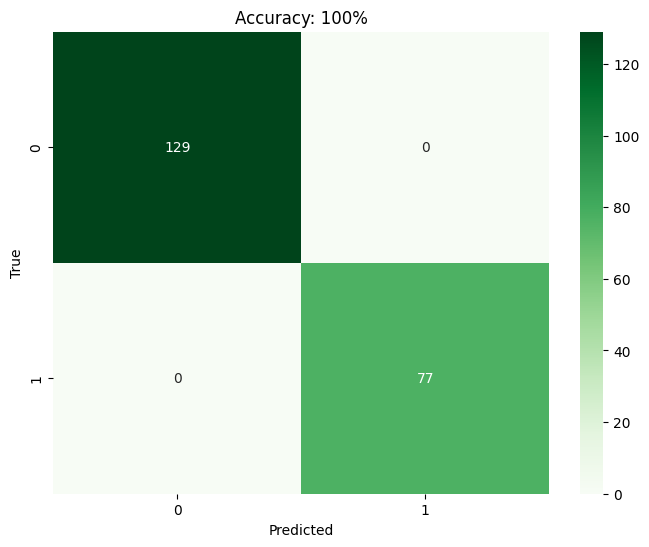
(d)
Fig 2: Confusion matrix visualization for (a) KNN (b) SVM (c) RF and (d) LR.
A. Model Performance Measurement
Based on the confusion matrix, we can compute the recall, precision, and F1-scores (Figure 2). SVM, RF, and LR exhibits the highest recall value of 1.0, along with precision and F1-scores also reaching the maximum of 1.0. This indicates the robust performance of these three models in accurately categorizing IVF success and failure cases. Conversely, the KNN method demonstrates the lowest values across all performance metrics, with scores of 0.64, 0.61, and 0.62 respectively. Apart from accuracy, evaluating the models based on precision, recall, and F1-scores provides insight into their classification performance, as depicted in the figure, illustrating distinct performances among the classifier machines.
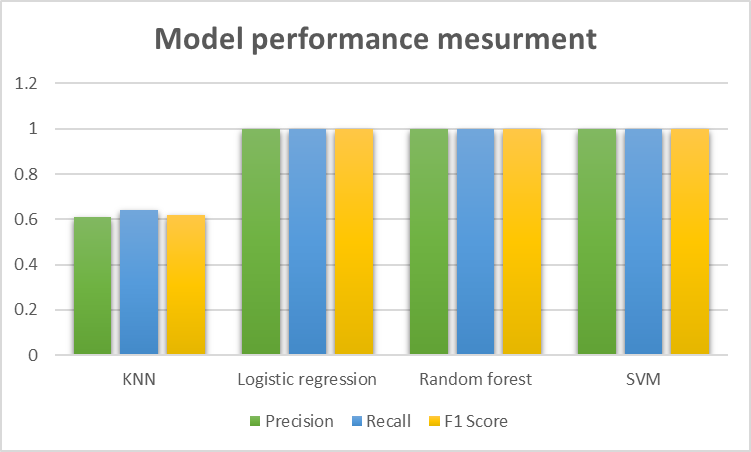
Fig 3: Comparison of the performance of all methods (KNN, LR, RF, SVM)
B. Benchmarking Dataset
In the current study, an IVF dataset was incorporated into several machine learning models, and multiple existing datasets were used to benchmark performance against the proprietary dataset. To validate the reliability of the dataset, the predictive accuracies previously reported for other incorporated datasets were examined. All accuracy scores from the testing are presented in Table 1. As shown in Table 1, SVM methods demonstrated the highest accuracy when comparing the dataset to other alternatives. RF and LR followed with similarly high predictive accuracy. The analysis of the KNN algorithm on the proprietary dataset yielded lower predictive accuracy than when applied to other datasets. This implies that the dataset used for this study may not be optimized for KNN modeling approaches relative to alternative methods. However, when benchmarked against comparable other datasets, the solution exhibited reasonably dependable predictive capabilities overall.
Table 1: Comparative analysis based on accuracy
|
Classifiers |
Dataset |
Accuracy |
Reference |
|
K- Nearest neighbor |
Fruit |
89.09% |
[14] |
|
Stroke |
97.18% |
[15] |
|
|
Cervical Cancer |
84.3% |
[16] |
|
|
In Vitro Fertilization |
64% |
|
|
|
Random Forest |
Fruit |
85.41% |
[14] |
|
Stroke |
73% |
[17] |
|
|
Cancer |
94.44% |
[18] |
|
|
In Vitro Fertilization |
100% |
|
|
|
Support Vector Machine |
Fruit |
91.18% |
[14] |
|
Cancer |
96.85% |
[19] |
|
|
Stroke |
80% |
[17] |
|
|
In Vitro Fertilization |
100% |
|
|
|
Logistic Regression |
Stroke |
78% |
[17] |
|
Cancer |
97.18% |
[20] |
|
|
Diabetes |
78% |
[21] |
|
|
In Vitro Fertilization |
100% |
|
Conclusion
In conclusion, the analysis of predicting success and failure rates in In Vitro Fertilization (IVF) has yielded promising results. Notably, the KNN model demonstrated an impressive accuracy rate of 64%, underscoring its effectiveness in classifying and predicting IVF outcomes. The SVM, RF, and LR models exhibited outstanding accuracy, achieving a perfect rate of 100%. These findings underscore the reliability of these models in predicting the success of fertility treatments, providing a solid basis for informed decision-making in assisted reproduction. The evaluation of these predictive models through the confusion matrix further enhances our understanding of their performance. The absence of misclassifications in the ensemble model highlights its robustness and potential for clinical interventions. The study showcases high accuracy in the analyzed models, laying the groundwork for further research on complex scenarios involving specific diseases correlated with gestation. Benchmarking the variables, measurements, and indicators captured in the IVF dataset to standardized data models will help validate its constructs and ensure alignment with industry norms. Such analysis facilitates identification of both the strengths and limitations of the dataset, guiding efforts to refine data collection protocols and optimize the dataset\'s utility for clinical and research users. Overall, benchmarking the IVF dataset promotes a more rigorous assessment of its quality, generalizability, and value - ultimately enhancing its ability to generate insights that advance the field of reproductive medicine and improve IVF outcomes.
References
[1] “In Vitro Fertilization - StatPearls - NCBI Bookshelf.” Accessed: Apr. 01, 2024. [Online]. Available: https://www.ncbi.nlm.nih.gov/books/NBK562266/ [2] A. M. Eskew and E. S. Jungheim, “A History of Developments to Improve in vitro Fertilization,” Mo Med, vol. 114, no. 3, p. 156, May 2017, Accessed: Apr. 01, 2024. [Online]. Available: /pmc/articles/PMC6140213/ [3] H. Bourne, T. Douglas, and J. Savulescu, “Procreative beneficence and in vitro gametogenesis”. [4] V. A. Kushnir, G. D. Smith, and E. Y. Adashi, “The Future of IVF: The New Normal in Human Reproduction,” Reproductive Sciences, vol. 29, no. 3, p. 849, Mar. 2022, doi: 10.1007/S43032-021-00829-3. [5] A. Mehrjerd, H. Rezaei, S. Eslami, M. B. Ratna, and N. Khadem Ghaebi, “Internal validation and comparison of predictive models to determine success rate of infertility treatments: a retrospective study of 2485 cycles,” Sci Rep, vol. 12, no. 1, Dec. 2022, doi: 10.1038/S41598-022-10902-9. [6] D. J. X. Chow, P. Wijesinghe, K. Dholakia, and K. R. Dunning, “Does artificial intelligence have a role in the IVF clinic?,” Reproduction & Fertility, vol. 2, no. 3, p. C29, Jul. 2021, doi: 10.1530/RAF-21-0043. [7] V. A. Kushnir, G. D. Smith, and E. Y. Adashi, “The Future of IVF: The New Normal in Human Reproduction,” Reproductive Sciences, vol. 29, no. 3, p. 849, Mar. 2022, doi: 10.1007/S43032-021-00829-3. [8] M. C. Panchal, “Prediction of IVF Treatment Outcome using Soft Computing and Various Classifiers: A Survey”, Accessed: Apr. 01, 2024. [Online]. Available: www.rsisinternational.org [9] M. Babitha, “A Survey on the Machine Learning Techniques used in IVF Treatment to Improve the Success Rate”, Accessed: Apr. 01, 2024. [Online]. Available: www.ijert.org [10] C. W. Wang, C. Y. Kuo, C. H. Chen, Y. H. Hsieh, and E. C. Y. Su, “Predicting clinical pregnancy using clinical features and machine learning algorithms in in vitro fertilization,” PLoS One, vol. 17, no. 6, p. e0267554, Jun. 2022, doi: 10.1371/JOURNAL.PONE.0267554. [11] L. Shen, Y. Zhang, W. Chen, and X. Yin, “The Application of Artificial Intelligence in Predicting Embryo Transfer Outcome of Recurrent Implantation Failure,” Front Physiol, vol. 13, p. 1, Jun. 2022, doi: 10.3389/FPHYS.2022.885661. [12] Z. Abbas, A. Saad, M. Ayache, and C. Fakih, “Applications of Logistic Regression and Artificial Neural Network for ICSI Prediction,” The International Arab Journal of Information Technology, vol. 16, no. 3A, 2019. [13] Z. Abbas, S. Ménigot, J. Charara, Z. Ibrahim, C. Fakih, and J.-M. Girault, “Predicting in vitro fertilization from ultrasound measurements using Machine Learning techniques,” pp. 190–194, 2023, doi: 10.1109/ICABME59496.2023.10293011ï. [14] R. Agarwal and P. Sagar, “A Comparative Study of Supervised Machine Learning Algorithms for Fruit Prediction,” Journal of Web Development and Web Designing, vol. 4, no. 1, 2019, doi: 10.5281/zenodo.2621205. [15] “View of Comparative Analysis of KNN and Decision Tree Classification Algorithms for Early Stroke Prediction: A Machine Learning Approach.” Accessed: Apr. 01, 2024. [Online]. Available: https://www.journal-isi.org/index.php/isi/article/view/664/329 [16] “View of Classification of Clinical Dataset of Cervical Cancer using KNN.” Accessed: Apr. 01, 2024. [Online]. Available: https://ischolar.sscldl.in/index.php/indjst/article/view/131756/120093 [17] G. Sailasya and G. L. Aruna Kumari, “Analyzing the Performance of Stroke Prediction using ML Classification Algorithms,” IJACSA) International Journal of Advanced Computer Science and Applications, vol. 12, no. 6, p. 2021, Accessed: Apr. 01, 2024. [Online]. Available: www.ijacsa.thesai.org [18] G. Sun, S. Li, Y. Cao, and F. Lang, “Cervical cancer diagnosis based on random forest,” International Journal of Performability Engineering, vol. 13, no. 4, pp. 446–457, Jul. 2017, doi: 10.23940/ijpe.17.04.p12.446457. [19] M. W. Huang, C. W. Chen, W. C. Lin, S. W. Ke, and C. F. Tsai, “SVM and SVM Ensembles in Breast Cancer Prediction,” PLoS One, vol. 12, no. 1, p. e0161501, Jan. 2017, doi: 10.1371/JOURNAL.PONE.0161501. [20] J. Sultana, J. Sultana, and A. K. Jilani, “Predicting Breast Cancer using Logistic Regression and Multi-Class Classifiers,” International Journal of Engineering & Technology, pp. 22–26, 2018, doi: 10.14419/ijet.v7i4.20.22115. [21] P. Rajendra and S. Latifi, “Prediction of diabetes using logistic regression and ensemble techniques,” Computer Methods and Programs in Biomedicine Update, vol. 1, p. 100032, Jan. 2021, doi: 10.1016/J.CMPBUP.2021.100032.
Copyright
Copyright © 2024 P. Malathi, Dr. M. Gomathi. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65652
Publish Date : 2024-11-29
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online