

Ijraset Journal For Research in Applied Science and Engineering Technology
Ethical Considerations for the Use of AI Language Model
Authors: Daksha Gaud
DOI Link: https://doi.org/10.22214/ijraset.2023.54513
Certificate: View Certificate
Abstract
The rapid advancements in artificial intelligence (AI) and natural language processing have led to the development of sophisticated language models like ChatGPT, Siri, Google Assistant. These models possess the ability to generate human-like text, enabling them to engage in conversations and assist users in various domains. However, as these models become increasingly integrated into our lives, it becomes crucial to examine the ethical considerations associated with their use. This survey-based research paper aims to explore and analyze the ethical implications of deploying ChatGPT and similar language models, focusing on concerns such as bias, privacy, accountability, and transparency. The research was qualitative research as data was collected through surveys using the questionnaire tool. By identifying these ethical challenges, we can foster responsible development, deployment, and regulation of AI technologies to ensure their beneficial and ethical integration into society.
Introduction
I. INTRODUCTION
A key component of Natural Language Processing (NLP) is AI language models which enables computers to understand and generate human like texts. Due to the advancement in AI based language model, the line between conversating with human or a machine has been blurred. A good example of this is OpenAI’s ChatpGPT-3, an advanced AI language model based on 175-billion parameter that can generate human like text and even code given a short prompt containing instructions. It is based on the GPT-3.5 architecture, which stands for "Generative Pre-trained Transformer 3.5." The model has been trained on an extensive dataset comprising a wide range of texts from the internet, including books, articles, websites, and more. ChatGPT is designed to generate human-like responses to a given question. It leverages deep learning techniques, specifically a type of neural network called a transformer, to understand and generate coherent and contextually relevant text.
With its vast knowledge and language understanding, ChatGPT can engage in interactive conversations on various topics, provide explanations, offer creative ideas, assist with problem-solving, and much more. When asked for a disclaimer, ChatGPT responded something like this.

The above disclaimer clearly states that ChatGPT provides information to us based on the training data that is fed to it rather than personal experience or real-time knowledge. So, the users should always cross-verify its responses from trusted sources. Also, the users should keep in mind not to provide it any personal or confidential information as it uses the data to update itself. Since, the knowledge of ChatGPT was cutoff in September 2021, it has less to zero information about the events that has taken place after that.
The purpose of this research paper is to critically examine the ethical considerations associated with the use of ChatGPT and similar language models. As these models become increasingly integrated into various aspects of our lives, it is essential to understand and address the ethical challenges they present. The scope of this paper encompasses an exploration of key ethical concerns, including bias, privacy, accountability, transparency, user manipulation, and psychological impact.
By analyzing these ethical dimensions, the paper aims to provide insights into the responsible development, deployment, and regulation of AI technologies. The research paper will delve into the impact of biases within training data, the preservation of user privacy and data security, the attribution of accountability and transparency, the prevention of user manipulation, and the psychological effects of interacting with AI. Furthermore, it will explore existing regulatory frameworks and propose recommendations for ethical guidelines and best practices for the use of ChatGPT and similar language models.
II. LITERATURE REVIEW
A. Ethical Concerns Related to Language Models
The use of language models raises a number of ethical concerns, including issues related to bias, privacy, responsibility, and transparency. One of the most significant concerns is the potential for biases to be introduced into language models, which could reinforce existing social inequalities or lead to unfair or discriminatory outcomes. Studies have shown that language models trained on large datasets can exhibit biases in their output, particularly with respect to race, gender, and other demographic factors (Bender et al., 2021).
Another key concern is privacy, particularly with respect to the use of language models for conversational interfaces. As language models become more sophisticated, they may be able to generate responses that are highly personalized and reveal sensitive information about individuals. This raises important questions about data protection and the use of personal information (Goodman and Flaxman, 2016).
Responsibility is also an important ethical consideration. As language models become more advanced, it may become difficult to determine who is responsible for their outputs and how they should be held accountable for any negative outcomes. This raises important questions about the need for transparency and accountability in the development and use of language models (Jobin et al., 2019).
B. Studies on Bias in Language Models
A number of studies have investigated biases in language models, particularly with respect to race, gender, and other demographic factors. For example, Bender et al. (2021) found that large language models exhibit biases with respect to race and gender, and that these biases can have negative impacts on downstream applications. Other studies have investigated biases in language models with respect to age (Dinan et al., 2020) and socioeconomic status (Ravfogel et al., 2021), highlighting the need for careful curation of training data and the development of debiasing techniques.
C. Legal and Regulatory Frameworks
There are a number of legal and regulatory frameworks that are relevant to the development and use of language models. For example, the General Data Protection Regulation (GDPR) sets out specific requirements for the collection and processing of personal data, which could be relevant to the use of language models for conversational interfaces. Other frameworks, such as ethical guidelines for AI development, provide a more general framework for ensuring that the development and use of language models is consistent with broader ethical principles (Floridi et al., 2018).
III. RESEARCH METHODOLOGY
A. Research Design
I will be using a descriptive survey research design to study the impact of Chat Generative Preprocessing Transformers in our daily lives.
B. Sampling
The size of the sample for this research is around 300 people from different backgrounds, working in different industries and who are of different age groups. I am using a stratified random sampling technique to select respondents from each age group.
C. Data Collection Technique
The research will obtain primary data through online surveys utilizing Google Forms. The survey will include questions focusing on the ethical considerations associated with the use of ChatGPT. Google Forms was chosen for its broad accessibility and user-friendly interface, ensuring clear understanding for survey participants.
D. Analysis of Data Collected –
Regarding data analysis, descriptive statistics will be used to analyze the collected data. The responses to the survey questions will be organized and examined to draw conclusions regarding the ethical considerations involved while using ChatGPT.
Questionnaire that was prepared for the survey is as follows:
- Have you ever interacted with a language model like ChatGPT or Siri?
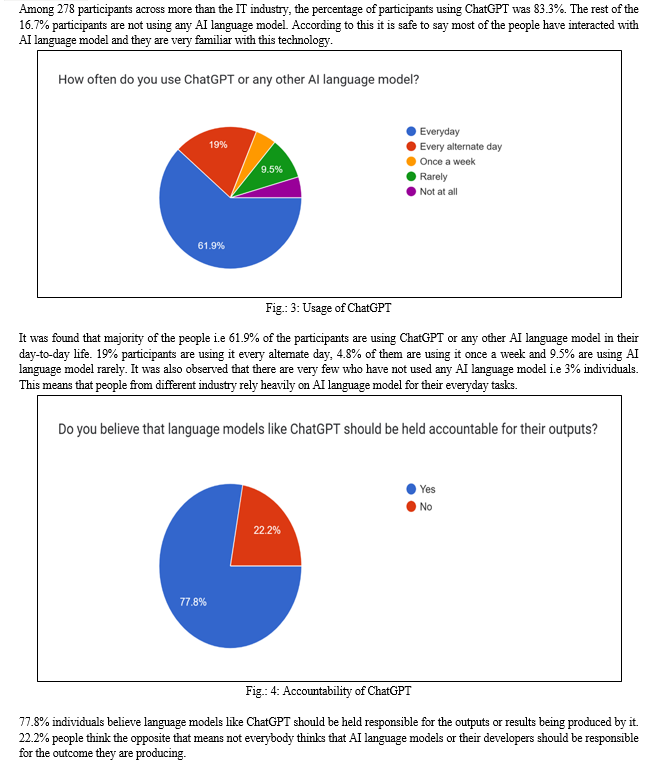
- How often do you use ChatGPT or any other AI language model?
- Do you believe that language models like ChatGPT should be held accountable for their outputs?
- How concerned are you about the privacy implications of using language models like ChatGPT for conversational interfaces?
- Do you believe that existing legal and regulatory frameworks are sufficient for addressing the ethical considerations of using language models like ChatGPT?
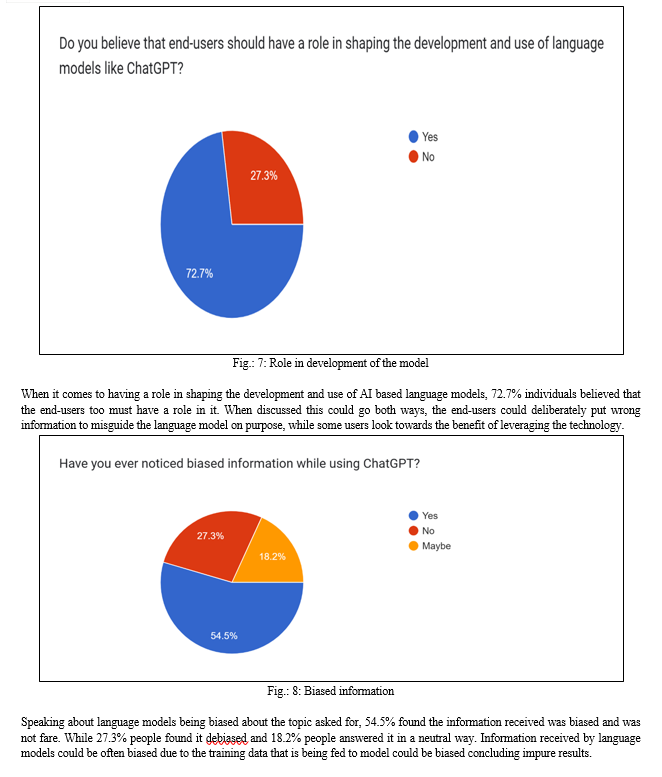
- Do you believe that end-users should have a role in shaping the development and use of language models like ChatGPT?
- Have you ever noticed biased information while using ChatGPT?
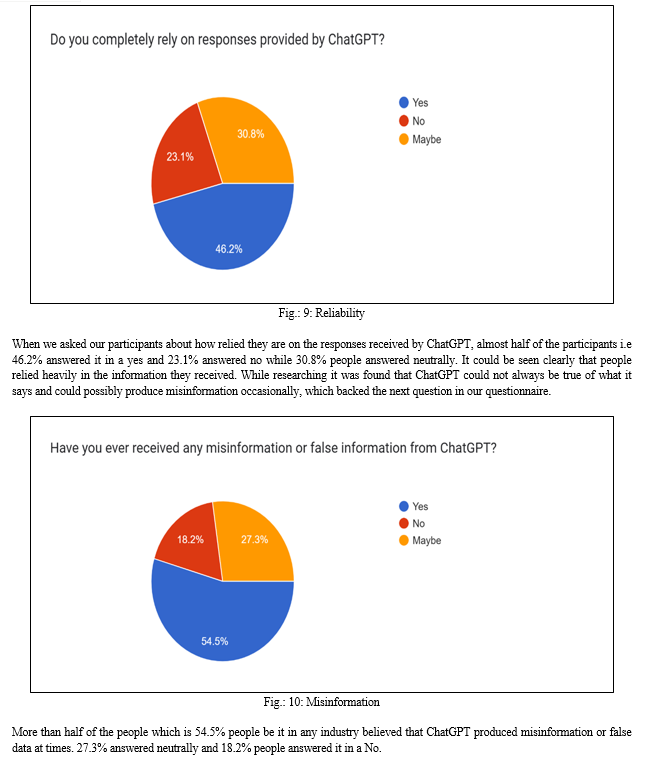
- Do you completely rely on responses provided by ChatGPT?
- Have you ever received any misinformation or false information from ChatGPT?
- Do you think language models can be manipulated to generate responses according to the user’s needs?
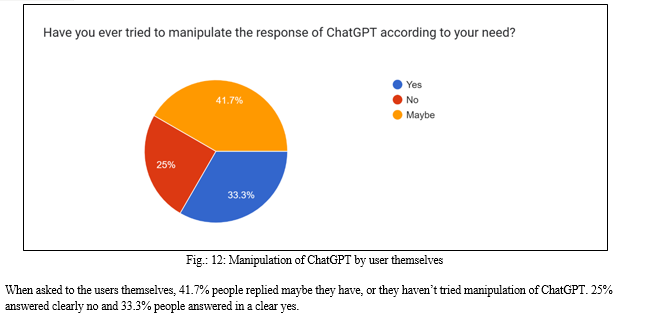
- Have you ever tried to manipulate the response of ChatGPT according to your need?
IV. RESULT AND DISCUSSION
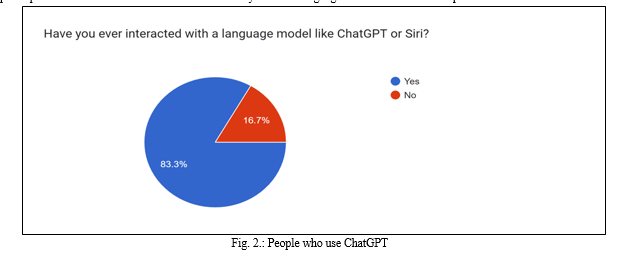
The main purpose for choosing participants across different industries was to study the impact that language models have in different fields. According to our study, more than 3/4th of the participants has used ChatGPT or other language models like Siri (Apple voice assistant).
A survey was conducted of 278 people who belonged to different industry and age groups. The question started with whether the participants have ever interacted with ChatGPT or any other AI language model. Here are the responses.


Conclusion
In conclusion, there are some ethical considerations that should be taken care of while interacting with AI language models. AI language models like ChatGPT could be biased or unfair. It can also produce misinformation, so it is necessary to cross-verify the information received from ChatGPT. Information received from AI language modal cannot be blindly trusted.
References
[1] https: //www.investopedia.com/terms/g/general-data-protection-regulation-gdpr.asp [2] https: //incora.software/insights/chatgpt-limitations [3] https: //papers.ssrn.com/sol3/papers.cfm?abstract_id=4402499 [4] https://www.researchgate.net/publication/367161545_Chatting_about_ChatGPT_How_may_AI_andGPT_impact_academia_and_libraries
Copyright
Copyright © 2023 Daksha Gaud . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET54513
Publish Date : 2023-06-29
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online