

Ijraset Journal For Research in Applied Science and Engineering Technology
Evaluation of Machine Learning Methods for Prediction Student Performance
Authors: Muskan Sihare, Rajendra Kumar Gupta
DOI Link: https://doi.org/10.22214/ijraset.2024.58001
Certificate: View Certificate
Abstract
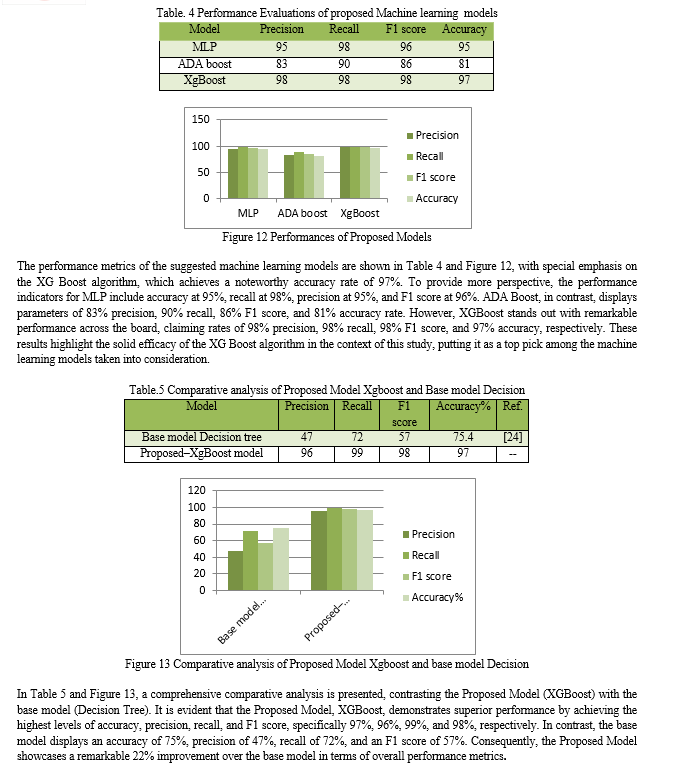
Significant findings and useful insights have emerged from the study of using machine learning techniques to predict student performance. used large datasets with a wide variety of demographic, socioeconomic, and academic performance data to conduct in-depth evaluations of several machine learning methods. Our study highlighted the importance of careful data preprocessing, which involves fundamental steps like classifying student performance and doing in-depth exploratory data analysis (EDA). To ensure the validity of our model assessments, we meticulously split the dataset into training and testing subsets. To effectively apply machine learning models, it is necessary to convert categorical data into numerical representations; we did this by using strategic label encoding and one-hot encoding techniques. Metrics on the effectiveness of the recommended machine learning models are presented, with a spotlight on the XG Boost algorithm\'s remarkable 97% accuracy. The MLP\'s performance indicators are as follows: 95% accuracy, 98% recall, 95% precision, and 96% F1 score. When compared to these, ADA Boost has a precision of 83%, recall of 90%, F1 score of 86%, and accuracy rate of 81%. XGBoost, on the other hand, claims rates of 98% precision, 98% recall, 98% F1 score, and 97% accuracy, making it stand out from the crowd. Based on these findings, the XG Boost algorithm is the best option among the machine learning models considered for this research.
Introduction
I. INTRODUCTION
Due to the widespread use computers and the internet, there is now a substantially larger amount on publicly available data that can be reviewed. New information is generated every day, whether it's regarding user behavior, web traffic, or online sales figures. Such a huge amount of data presents both a challenge and an opportunity[1]. The problem is that analyzing such vast amounts of data is difficult for humans. The advantage is that this content is well-formatted and digitally recorded, making it ideal for processing for computers, who process data far more quickly than people[2].Learning analytics significantly enhances the educational system by focusing on a wide range of perspectives, including those of student, teachers, and administrators. The goals of learning analytics include accurate evaluation, clear understanding of educational challenges, and the choice and timing of efficient interventions, to name a few. Data analytics and several sectors connected to it, including such database-based information retrieval assessment of following framework prediction, text analysis and text mining, neural network-based, and or artificial intelligence techniques, have invaded the nerves of the education systems[3]. The main objective is to use technology to automate conventional methods of instruction and learning. Student information can be gathered using a learning management system. Despite our extensive data collecting, we rarely succeed in gleaning information that is helpful from it. The area of knowledge discovery utilizing databases has attracted interest due to the fact that important information is usually concealed in the data produced by numerous sources. Both decision-makers and educators can benefit from the data that can be gathered from these databases[4].
Education management systems, or LMS, and e-learning have become standard tools in universities thanks to the rapid progress of information and communication (ICTs) and their application in education. Even while using an LMS has many benefits, there are still several challenges to achieving learning goals, the most important of which is improving student performance rates. Classifying data and forecasting student performance are crucial jobs in the educational sector[5]. Techniques from machine learning (ML) are commonly employed to evaluate student learning. Data mining techniques, such as ML algorithms used in computer vision, are being applied in the field of education to analyse student records and give information that can be utilized to guide practice and policy (EDM). Machine learning techniques can forecast students' future performance, and In this way, they can take preventative measures for low-achieving students as soon as possible. The first and most important stage in using machine learning techniques is choosing the properties or descriptive features that will be supplied into the algorithm. There are various ways to classify attributes, such as academic performance, demography, psychological tests, cultural norms, and educational background and history[6].
Utilizing machine learning techniques, it is possible to predict how children will fare in school and identify at-risk students in time to help them improve their grades. One of the most crucial stages of employing these methods is settling on the characteristics or descriptive features that will be sent into the machine learning algorithm. Graduation and grade point averages, demography, psychological make-up, cultural background, and educational attainment are only some of the many categories into which these characteristics fit[7]. Academic performance can be explained using machine learning algorithms (MLAs), which have the intrinsic ability to master itself using previously obtained training experiences. MLAs can be used to reveal the relationship between various academic and personal input components.
A system can be improved by learning from previously sought input-output data in order to create accurate predictions. claimed that MLAs help in both prediction and pattern recognition from training data sets. The literature takes into account supervised, unsupervised, & reinforcement learning as three distinct kinds of MLAs.
Unsupervised machine learning, like clustering, employs unlabeled datasets that enable a system to detect hidden commonalities within the figures. Supervised algorithms learn from labelled records given as just a component of the training dataset. On the other end of the spectrum, the reinforcement learning system was primed by a sequence of unmediated interconnections by way of trial and error[8].
It is suggested that knowledge discovery mine rules from the dataset of Systems of Learning Using management to forecast student performance in this scenario. Techniques from machine learning are used in this instance. There are ten cross-validation iterations. Considerations for classifier evaluation include precision, specificity, sensitivities, kappa statistic, & ROC curve. This pattern of behavior can be examined with the use of machine learning (ML).
This is undoubtedly a wide topic, and there are numerous issues and difficulties to be resolved. The broad category of categorization is the focus of this investigation. ML defines classification as the process of identifying the category to which an observation belongs. Essentially, it is a method for creating correlations between an independent variable as well as a predictor variables (that has a categorical nature) (numerical or categorical in nature)[9].
II. LITERATURE REVIEW
Tarik 2021 et. al enhanced user experience across several sectors. provide a clever method that makes use of artificial intelligence tools to forecast Moroccan students' performance in the Guelmim Oued Noun area during the COVID-19.[10].
Priya 2021 et al. provides a thorough EDM structure in the form of such a rule-based recommendation systems which not only evaluates and forecasts student progress but also elucidates its causes. In order to obtain as much data as possible from peers, instructors, and parents, the suggested framework looks at pupils' demographic data, study-related features, and psychological aspects. The most recent information is gathered via school reports and enquiries, such as student grades, demographic statistics, and social and academic variables. attempting to forecast academic success with the highest level of accuracy possible using a variety of effective data mining techniques. The framework does a good job of identifying the student's deficiencies and providing pertinent advice. In a real-world case study including 200 people, the suggested framework performs better than existing ones[11].
Dhilipan 2021 et al. suggested using their tenth, twelfth, and prior semester's grades. Binomial logistic regression, entropy, decision trees, and KNN classifiers are all used to analyze the study. This framework will help the student understand their final result and enhance their academic performance to get a higher mark[12].
Rajendran 2022 et al. Three metrics—precision, recall, and F1-score—are used to evaluate an MLA' performance. The gradient boosting strategy was demonstrated to yield results that were superior to those generated by the other procedures, with random forest coming in second. According to the model analysis, leading a healthy lifestyle favorably correlates with academic achievement, but stress has a detrimental effect. However, it has been discovered that a student's gender is not a reliable indicator of their academic success.[13].
Alshabandar 2020 et. al employing predetermined computer-marked examinations to evaluate. In instance, after the student completes the online tests, the computer provides immediate feedback. According to the study, in additional to the degree of involvement, the student rate of success in an online class can be correlated with their performance in the preceding session. The literature hasn't given it enough thought to determine how a student's engagement and performance on earlier tests might affect their performance on later tests. In this essay Two prediction models have been created, one for final student performance and the other for students' assessment grades. The model can be employed to identify the elements that affect how well students learn in MOOCs. The outcome demonstrates that both models produce workable and precise outcomes. A mean value of 0.086 for GBM's accuracy in predicting students' final grades was achieved, while RF's RSME gain was 8.131 for students' assessment grades[14].
III. PROPOSED METHODOLOGY
The dataset is made up of different types of data, including student grades, demographic information, social aspects, and features relating to the school, which were collected through reports and surveys from the institution. Two distinct datasets that concentrate on student achievement in the fields of mathematics (mat) and the Portuguese language (Por) have been comprehensively modelled for binary/five-level classification and regression issues. A few numbers in the "final score" column are transformed into category qualities like "Good," "Fair," and "Poor." After that, the data is divided into testing and training phases at a ratio of 70:30 before exploratory data analysis (EDA) is performed. Categorical information is numerically encoded using label encoding, and categorical variables are changed into binary indicator variables using "get dummies." Finally, a variety of models are used to evaluate their effectiveness in predicting student performance categories based on the transformed characteristics, including MLP, Adaboost, and XgBoost. Using sophisticated modeling approaches and in-depth data analysis, this complete methodology provides insightful information about student performance.[15].
A. Data Collection
The methodical and precise process of acquiring and examining information on specific topics with the primary objective of responding to established research issues, examining hypotheses, and evaluating study findings is known as data collection. This fundamental method is shared by all fields, including the humanities, social sciences, business, and natural and applied sciences, which is prevalent throughout a broad range of academic fields. Although different approaches may be used in each field depending on the specific needs of that field, they all agree that it is crucial to maintain the accuracy and integrity of data gathering procedures.[16].Data collected allows a researcher to test their hypothesis. When conducting research, data collection is always the first and most important step, regardless of the topic at hand. The methods used to collect data vary across fields of study and are dependent on the specific information that needs to be gathered.
B. Preprocessing
Data mining uses a process called data preparation to transform raw data into a usable and effective format by removing any redundant or missing information. All the steps taken to prepare raw data ready for further processing are collectively known as "data preparation."[17]. It has traditionally been a crucial first stage in the data mining process. Inferences against AI and machine learning systems have recently been tested using new data preparation techniques. Data preprocessing transforms the information into a format that can be processed more rapidly and effectively for other data scientist tasks, such as machine learning and data analysis. The methods are often used at the very start of the deep learning and artificial intelligence development pipeline to provide dependable results[18].
C. EDA
Data sets are examined and their essential characteristics are highlighted using a statistical technique called exploratory data analysis (EDA). Data visualization methods often include statistical graphics and other methods. EDA differs from traditional testing hypotheses in that it focuses on examining what the data might show in addition to the formal modeling. The application of a statistical model is optional. Since 1970, John Tukey has pushed statisticians to study the data and perhaps develop hypotheses which could lead to more information collecting and experimentation by promoting exploratory data analysis.[19].
D. Data Splitting
Data splitting makes use of the train-test split strategy to evaluate the performance of learning algorithms using test data. There will be a 70% training data to 30% test data split. You may quickly and easily assess the efficacy of machine learning algorithms for your specific predictive modeling challenge. Although the method is simple to implement and comprehend, it shouldn't be utilized in all situations due to data scarcity and the requirement for further settings (such as when it's used for classification and the dataset is imbalanced.[20].
E. Modeling
Machine learning research tries to develop "learning" processes—processes that use data to improve results in a particular set of tasks—and to better understand these processes. It is thought by some AI thinkers to be[21]. By creating a model using training examples, algorithms for machine learning can make decisions and predictions without being specifically programmed to do so. The outcomes have been evaluated using machine learning techniques.
- MLP Model: The Multi-Layer Perceptron is the most straightforward artificial neural network type (MLP). This hybrid is made using many perceptron models. The human brain serves as an inspiration for perceptions, which aim to mimic brain activity in order to solve problems. These perceptions are highly parallel and interconnected in MLP. By utilizing parallel processing, we are able to perform computations more quickly.
- AdaBoost: The "Adaptive Boosting" algorithm, or AdaBoost, is a Boosting method used in machine learning as just an ensemble learning method. The reason adaptive boost is so named is because it reassigns weight to each example, giving examples that were misclassified greater weight. Boosting is used in supervised learning to reduce variation and minimize bias. The approach is predicated on the notion that pupils advance in a rational manner. All subsequent students are derived from their predecessors[22].
- XgBoost: Using gradient-boosted decision trees (GBDTs), a machine learning package known as "extreme gradient boost" makes decisions. It supports parallel tree boosting and is the go-to machine learning framework for issues including regression, classification, and ranking. Understanding XGBoost requires knowledge of supervised methods, decision trees, ensemble learning, gradient boosting, among other machine learning methods and concepts. Supervised machine learning forecasts labeled characteristics from an unlabeled dataset by using a labelled & feature-rich data as a training ground[23].
F. Flowchart

IV. RESULT & DISCUSSION
This section suggests the results of cross-site scripting analysis using machine learning techniques that have preprocessed and encoded the data. On a Windows 10 PC with 16.0GB of RAM as well as a 2.6GHz Intel Core i7-9750H processor, the study was conducted. All of the studies made use of the Jupyter simulation environment, with Python serving as the main programming language. Additionally, certain Python libraries were used. Also included here are the measures for measuring the effectiveness of machine learning models. EDA simulation, visualization Gather information from open-source Data from Kaggle in the areas of math and Portuguese focuses on the total result used to describe student performance and create labels for categorization and prediction. It has a variety of columns and features. Using score selection, choose the final grade and categories it into Good, Fair, and Poor students if the grade is between 15 and 20 (a good student), between 10 and 14 (a fair student), and between 0 and 9 (a poor student). Then, carry out EDA.
A. EDA
EDA is a technique for analyzing sets of data in a way that highlights their salient characteristics. It often uses statistical visualizations as well as other information visualization techniques. have evaluated the results on a graph. Using score selection, the final score column is chosen and transformed into categorized features including such Good, Fair, and Poor, where a final score between 15 and 20 indicates a good student, a final score between 10 and 14 a fair student, and a final score between 0 and 9 a poor student. In addition, a correlation matrix is used. utilized to assign a final grade based on romantic compatibility, with fair obtaining a higher score. It has also been used to distribute study time based on age & desire for higher education.
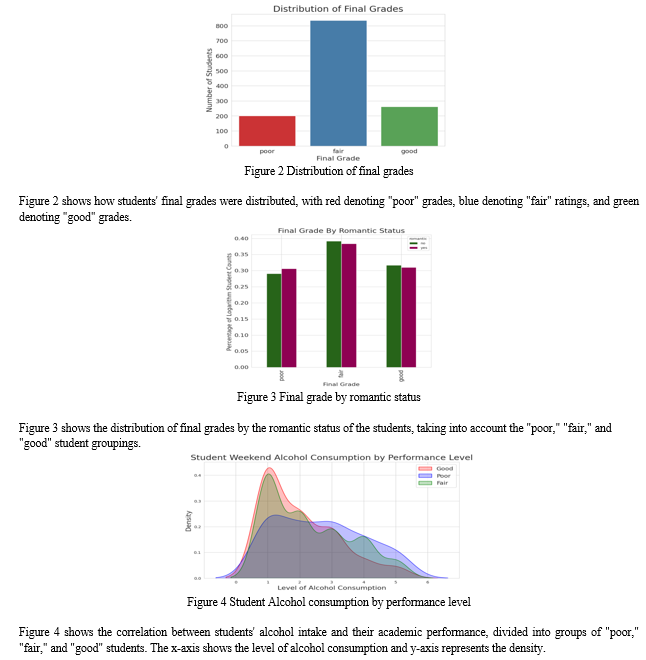
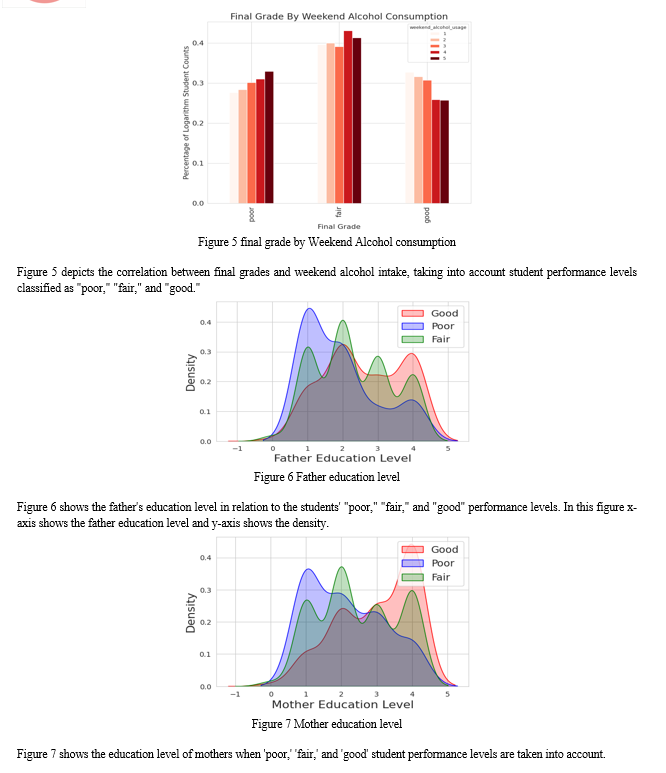


Conclusion
As a result of our investigation into the use of machine learning methods for predicting student performance, we have learned some important lessons. utilized large datasets that included demographic and socioeconomic data as well as academic performance to evaluate several machine learning algorithms. In order to highlight the importance of data preprocessing, our study includes tasks including categorizing student performance and carrying out exhaustive exploratory data analysis (EDA). To confirm the validity and accuracy of our model assessments, we also painstakingly divided the dataset into training and testing sets. Strategic label encoding and one-hot encoding approaches were successfully used to convert categorical data into numerical representations, which is a need for the deployment of machine learning models. A variety of performance indicators were used to assess a number of models, including Multilayer Perceptron (MLP), Adaboost, and Xgboost. When forecasting various facets of student performance, each model showed particular advantages and disadvantages. compared the proposed model (XGBoost) to the baseline model (Decision Tree) in our final study. Accuracy, precision, recall, and F1 score were all areas where the proposed model outperformed the baseline model. The baseline model had an accuracy of 75%, precision of 47%, recall score 72% and F1 score of 57%, while the proposed model showed a stunning 22% total improvement in performance metrics over the base model.
References
[1] S. Li and T. Liu, “Performance Prediction for Higher Education Students Using Deep Learning,” Complexity, vol. 2021, 2021, doi: 10.1155/2021/9958203. [2] X. Li, Y. Zhang, H. Cheng, M. Li, and B. Yin, “Student achievement prediction using deep neural network from multi-source campus data,” Complex Intell. Syst., vol. 8, no. 6, pp. 5143–5156, 2022, doi: 10.1007/s40747-022-00731-8. [3] N. N. Hamadneh, S. Atawneh, W. A. Khan, K. A. Almejalli, and A. Alhomoud, “Using Artificial Intelligence to Predict Students’ Academic Performance in Blended Learning,” Sustain., vol. 14, no. 18, pp. 1–13, 2022, doi: 10.3390/su141811642. [4] M. Ya?c?, “Educational data mining: prediction of students’ academic performance using machine learning algorithms,” Smart Learn. Environ., vol. 9, no. 1, 2022, doi: 10.1186/s40561-022-00192-z. [5] I. Nagaraju, J. Deepthi, P. Navya, and J. I. Technology, “JAC?: A Journal Of Composition Theory ISSN?: 0731-6755 STUDENTS PERFORMANCE PREDICTION IN ONLINE COURSES USING Volume XIV , Issue VI , JUNE 2021 Page No?: 133 JAC?: A Journal Of Composition Theory ISSN?: 0731-6755 Volume XIV , Issue VI , JUNE 2021 Page No,” vol. XIV, no. Vi, pp. 133–140, 2021. [6] A. Y. A. Oku and J. R. Sato, “Predicting Student Performance Using Machine Learning in fNIRS Data,” Front. Hum. Neurosci., vol. 15, no. 1, pp. 336–340, 2021, doi: 10.3389/fnhum.2021.622224. [7] S. G. Kumar and G. H. Reddy, “Prediction of education performance using deep learning,” Int. J. Innov. Technol. Explor. Eng., vol. 8, no. 7, pp. 361–364, 2019. [8] A. Deshmukh and R. Khode, “GRADIVA REVIEW JOURNAL ISSN NO?: 0363-8057 Student ’ s Performance Prediction Using Deep Neural Network Abstract?:,” vol. 8, no. 1, pp. 156–162, 2022. [9] C. Lulla, Y. Agarwal, S. Kankariya, P. Sakaray, and ..., “Student academic performance prediction using machine learning and data mining techniques,” Int. J. …, vol. 10, no. 5, 2017. [10] A. Tarik, H. Aissa, and F. Yousef, “Artificial intelligence and machine learning to predict student performance during the COVID-19,” Procedia Comput. Sci., vol. 184, pp. 835–840, 2021, doi: 10.1016/j.procs.2021.03.104. [11] S. Priya, T. Ankit, and D. Divyansh, “Student performance prediction using machine learning,” Adv. Parallel Comput., vol. 39, pp. 167–174, 2021, doi: 10.3233/APC210137. [12] J. Dhilipan, N. Vijayalakshmi, S. Suriya, and A. Christopher, “Prediction of Students Performance using Machine learning,” IOP Conf. Ser. Mater. Sci. Eng., vol. 1055, no. 1, p. 012122, 2021, doi: 10.1088/1757-899x/1055/1/012122. [13] S. Rajendran, S. Chamundeswari, and A. A. Sinha, “Predicting the academic performance of middle- and high-school students using machine learning algorithms,” Soc. Sci. Humanit. Open, vol. 6, no. 1, p. 100357, 2022, doi: 10.1016/j.ssaho.2022.100357. [14] R. Alshabandar, A. Hussain, R. Keight, and W. Khan, “Students Performance Prediction in Online Courses Using Machine Learning Algorithms,” Proc. Int. Jt. Conf. Neural Networks, vol. 02, no. 11, pp. 74–79, 2020, doi: 10.1109/IJCNN48605.2020.9207196. [15] L. Sandra, F. Lumbangaol, and T. Matsuo, “Machine Learning Algorithm to Predict Student’s Performance: A Systematic Literature Review,” TEM J., vol. 10, no. 4, pp. 1919–1927, 2021, doi: 10.18421/TEM104-56. [16] M. S. V. Et. al., “Study Of Students’ Performance Prediction Models Using Machine Learning,” Turkish J. Comput. Math. Educ., vol. 12, no. 2, pp. 3085–3091, 2021, doi: 10.17762/turcomat.v12i2.2351. [17] K. G. Rani, “PREDICTING STUDENT ACADEMIC PERFORMANCE USING MACHINE LEARNING,” vol. 26, no. 6, pp. 200–205. [18] V. A., P. D., and M. V., “Predicting Student’s Performance using Machine Learning,” Commun. Appl. Electron., vol. 7, no. 11, pp. 11–15, 2017, doi: 10.5120/cae2017652730. [19] K. Neha, J. Sidiq, and M. Zaman, “Deep neural network model for identification of predictive variables and evaluation of student’s academic performance,” Rev. d’Intelligence Artif., vol. 35, no. 5, pp. 409–415, 2021, doi: 10.18280/ria.350507. [20] N. Ahmad, N. Hassan, H. Jaafar, and N. I. M. Enzai, “Students’ Performance Prediction using Artificial Neural Network,” IOP Conf. Ser. Mater. Sci. Eng., vol. 1176, no. 1, p. 012020, 2021, doi: 10.1088/1757-899x/1176/1/012020 [21] A. D. Vergaray, C. Guerra, N. Cervera, and E. Burgos, “Predicting Academic Performance using a Multiclassification Model: Case Study,” Int. J. Adv. Comput. Sci. Appl., vol. 13, no. 9, pp. 881–889, 2022, doi: 10.14569/IJACSA.2022.01309102. [22] A. A. Enughwure and M. E. Ogbise, “Application of Machine Learning Methods to Predict Student Performance: A Systematic Literature Review,” Int. Res. J. Eng. Technol., no. May, pp. 3405–3415, 2020. [23] H. Altabrawee, O. A. J. Ali, and S. Q. Ajmi, “Predicting Students’ Performance Using Machine Learning Techniques,” J. Univ. BABYLON Pure Appl. Sci., vol. 27, no. 1, pp. 194–205, 2019, doi: 10.29196/jubpas.v27i1.2108. [24] “predictive Academic performance of students using hybrid data mining approach.”
Copyright
Copyright © 2024 Muskan Sihare, Rajendra Kumar Gupta. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET58001
Publish Date : 2024-01-12
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online