

Ijraset Journal For Research in Applied Science and Engineering Technology
The Evolving Landscape of Site Reliability Engineering: Research and Innovations
Authors: Nagarjuna Malladi
DOI Link: https://doi.org/10.22214/ijraset.2024.64327
Certificate: View Certificate
Abstract
This article explores the rapidly evolving landscape of Site Reliability Engineering (SRE), examining cutting-edge research and innovations shaping the field\'s future. It delves into key advancements such as integrating AI and machine learning in SRE practices, cloud-native SRE strategies, advanced observability and monitoring techniques, the evolution of chaos engineering, and the role of automation and DevOps in SRE. The article also discusses emerging research areas and challenges, including quantifying SRE impact, SRE culture and organization, talent development, and adapting SRE practices for emerging technologies. By providing insights into these trends and innovations, the article offers valuable perspectives for SRE professionals, software engineers, and business leaders on the future direction of system reliability and performance management in complex, distributed environments.
Introduction
I. INTRODUCTION
Site Reliability Engineering (SRE) has emerged as a critical discipline in modern IT operations. It seamlessly integrates software engineering principles with operational expertise to ensure the reliability and performance of increasingly complex digital systems. As organizations navigate the challenges of scaling their digital infrastructures and meeting ever-growing user expectations for seamless experiences, the field of SRE continues to evolve rapidly [1].
The concept of SRE, first introduced by Google in the early 2000s, has since gained widespread adoption across the tech industry. It represents a paradigm shift from traditional IT operations, focusing on treating operations as a software problem and applying software engineering solutions to operational challenges [2]. This approach has proven particularly effective in managing large-scale, distributed systems characteristic of today's cloud-native environments. In recent years, several key technological advancements have transformed the SRE landscape. Integrating artificial intelligence (AI) and machine learning (ML) into SRE practices has opened up new possibilities for predictive analytics, anomaly detection, and automated incident response. These technologies enable SRE teams to move from reactive to proactive system reliability management, significantly reducing downtime and improving overall system performance.
Simultaneously, the widespread adoption of cloud-native architectures, containerization, and microservices has introduced new challenges and opportunities for SRE professionals. Managing the complexity of these distributed systems requires novel approaches to observability, monitoring, and incident management. Advanced techniques such as distributed tracing and log analytics have become essential tools in the SRE toolkit, providing unprecedented visibility into system behavior and performance.
This article delves into the cutting-edge research and innovations shaping the future of Site Reliability Engineering. We explore how SRE practices are adapting to meet the challenges of today's dynamic technological landscape, covering a range of topics including:
- The integration of AI and ML in SRE practices
- Cloud-native SRE strategies and tools
- Advanced observability and monitoring techniques
- The evolution of chaos engineering
- Automation and DevOps in the context of SRE
- Emerging research areas and challenges in the field
Our exploration covers not only the technical aspects of these innovations but also their impact on organizational culture, team structures, and talent development within the SRE domain. We examine how companies are quantifying the impact of SRE practices on their business outcomes and how the role of SRE is evolving within organizations.
Additionally, we highlight some of the innovative tools and platforms that are at the forefront of SRE innovation, providing concrete examples of how these technologies are being applied in real-world scenarios. From comprehensive monitoring solutions to chaos engineering platforms, these tools are enabling SRE teams to push the boundaries of system reliability and performance [2].
Whether you're an experienced SRE professional looking to stay abreast of the latest developments in the field, a software engineer interested in transitioning to an SRE role, or a business leader seeking to understand the strategic importance of SRE, this article offers valuable insights into the trends and advancements driving the next generation of reliable, scalable, and efficient systems.
As we embark on this exploration of the evolving landscape of Site Reliability Engineering, we invite you to consider how these innovations might apply to your own organization's reliability challenges and how they might shape the future of your IT operations.
|
Year |
SRE Adoption (%) |
AI/ML Integration (%) |
Cloud-Native SRE (%) |
Chaos Engineering Adoption (%) |
|
2018 |
35 |
10 |
25 |
5 |
|
2019 |
45 |
18 |
35 |
12 |
|
2020 |
55 |
28 |
48 |
20 |
|
2021 |
65 |
40 |
60 |
30 |
|
2022 |
72 |
52 |
70 |
42 |
|
2023 |
78 |
63 |
78 |
55 |
|
2024 |
83 |
72 |
85 |
65 |
Table 1: Trends in SRE Adoption and Associated Technologies (2018-2024) [1]
II. EMERGING SRE TECHNOLOGIES AND TOOLS
The landscape of Site Reliability Engineering (SRE) is rapidly evolving, driven by advancements in artificial intelligence (AI), machine learning (ML), and cloud-native technologies. These innovations are reshaping how SRE teams approach system reliability, performance optimization, and incident management.
A. AI and ML-Driven SRE
Artificial Intelligence and Machine Learning are revolutionizing SRE practices, enabling more proactive and efficient management of complex systems.
1) Predictive Analytics
Predictive analytics leverages historical data to forecast potential issues, allowing SRE teams to take preemptive action. This approach significantly reduces system downtime and improves overall reliability. For example, major tech companies have reported significant reductions in unexpected failures in their data centers through AI-powered predictive maintenance systems.
Implementing predictive analytics in SRE typically involves:
- Data collection from various sources (logs, metrics, events)
- Feature engineering to identify relevant indicators
- Model training using historical incident data
- Real-time analysis of incoming data to predict potential issues
2) Anomaly Detection
AI-powered anomaly detection tools can identify unusual patterns in system behavior, enabling engineers to pinpoint problems early before they escalate into major incidents. These tools use advanced algorithms to establish baseline behavior and flag deviations in real-time.
For instance, Netflix's anomaly detection system, which uses a combination of statistical and machine learning techniques, has been crucial in maintaining their service quality across millions of streaming sessions [3].
3) Root Cause Analysis
Automation of root cause analysis through AI and ML techniques has significantly sped up incident resolution and helps prevent recurring issues. These systems can analyze vast amounts of data from various sources to identify the underlying causes of incidents more quickly and accurately than manual analysis.
LinkedIn's Auto-Remediation and Diagnostic Engine (ARDE) is an example of how AI is being applied to root cause analysis. ARDE uses machine learning models to automatically diagnose and remediate issues in LinkedIn's distributed systems [3].
4) Task Automation
AI and ML are increasingly being used to automate routine SRE tasks, freeing up engineers to focus on more strategic initiatives. This includes automating:
- Configuration management
- Capacity planning
- Performance tuning
- Incident response workflows
For example, Facebook's AI-powered 'Sapienz' system automates the process of finding and reproducing bugs in mobile apps, significantly reducing the manual effort required in the testing phase of the development lifecycle [3].
B. Cloud-Native SRE
The shift towards cloud-native architectures is fundamentally reshaping SRE practices, introducing new challenges and opportunities for ensuring system reliability and performance.
1) Serverless Computing
SRE teams are developing new strategies for managing serverless architectures, with a focus on metrics, logging, and tracing in ephemeral environments. This shift requires a reevaluation of traditional SRE practices, as many conventional monitoring and debugging techniques are less effective in serverless environments.
Key considerations for serverless SRE include:
- Implementing distributed tracing across function invocations
- Optimizing cold start times
- Managing concurrency and scaling
- Monitoring and optimizing costs
AWS Lambda's built-in monitoring and observability tools, integrated with Amazon CloudWatch, exemplify how cloud providers are adapting their offerings to support SRE practices in serverless environments [4].
2) Kubernetes
As Kubernetes becomes the de facto standard for container orchestration, SRE practices are evolving to manage and scale Kubernetes clusters efficiently. This includes developing expertise in:
- Cluster autoscaling
- Service mesh implementation (e.g., Istio)
- Custom resource definitions (CRDs) for extending Kubernetes functionality
- Kubernetes-native monitoring and logging solutions
Google's Kubernetes Engine Autopilot is an example of how cloud providers are incorporating SRE best practices into their managed Kubernetes offerings, automating many aspects of cluster management and optimization.
3) Cloud-native Security
Security is being integrated deeper into the SRE lifecycle, with tools for vulnerability scanning, threat detection, and incident response tailored for cloud-native environments. This shift towards "DevSecOps" ensures that security considerations are addressed throughout the development and operational lifecycle.
Key areas of focus include:
- Runtime application self-protection (RASP)
- Container image scanning
- Network policy enforcement
- Secrets management
Tools like Aqua Security and Twistlock have emerged as leaders in providing comprehensive security solutions for cloud-native environments, integrating seamlessly with popular CI/CD pipelines and container registries [4].
As these emerging technologies continue to mature, they promise to significantly enhance the capabilities of SRE teams, enabling more proactive, efficient, and secure management of complex, distributed systems. However, their adoption also requires continuous learning and adaptation from SRE professionals, as the landscape of tools and best practices evolves rapidly.
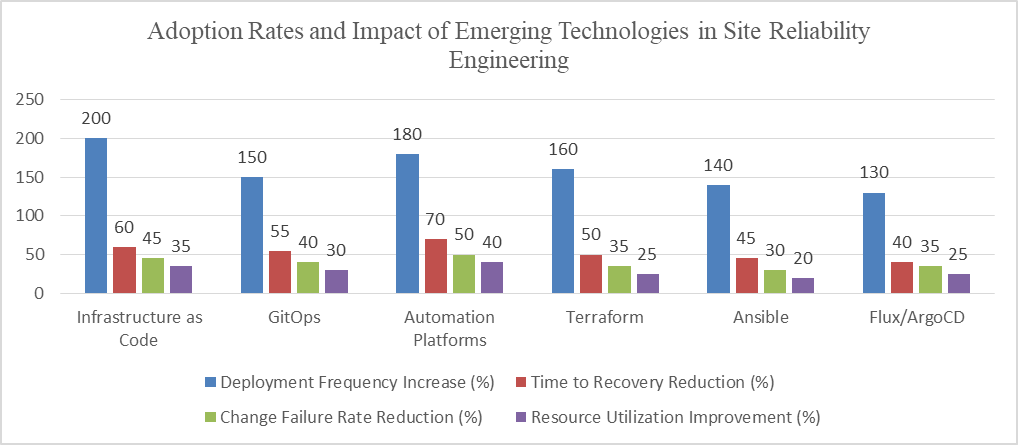 Fig 1: Impact of Emerging SRE Technologies on Key Performance Indicators [3, 4]
Fig 1: Impact of Emerging SRE Technologies on Key Performance Indicators [3, 4]
III. OBSERVABILITY, MONITORING, AND CHAOS ENGINEERING
As systems grow more complex and distributed, Site Reliability Engineering (SRE) teams are adopting advanced techniques for observability, monitoring, and proactive resilience testing. These practices are crucial for maintaining high availability and performance in modern, cloud-native environments.
A. Observability and Monitoring
Advancements in observability are providing unprecedented insights into system behavior, enabling SREs to identify and resolve issues in complex, distributed systems quickly.
1) Distributed Tracing
Distributed tracing has emerged as a critical technique for improving visibility into complex distributed systems. It helps SREs understand request flows across multiple services and identify performance bottlenecks [5]. Key benefits include:
- End-to-end visibility of request lifecycles
- Latency analysis across service boundaries
- Identification of critical paths and bottlenecks
- Correlation of traces with logs and metrics for comprehensive debugging
For example, Uber's distributed tracing system, Jaeger, has been instrumental in helping their engineers understand and optimize the performance of their microservices architecture [5].
2) Log Analytics
Enhanced log analysis capabilities, powered by advanced search and correlation techniques, are enabling faster troubleshooting and more effective system optimization. Modern log analytics platforms incorporate:
- Machine learning for anomaly detection
- Natural language processing for log parsing
- Real-time indexing and searching
- Automated correlation of logs with metrics and traces
Google's Cloud Logging, for instance, uses AI-powered log analytics to help developers and SREs quickly identify and resolve issues in their cloud applications [6].
3) Synthetic Monitoring
SRE teams are creating more realistic and effective synthetic monitoring tests to identify issues from an end-user perspective proactively. This approach involves:
- Simulating user interactions with the system
- Testing from multiple geographic locations
- Monitoring third-party API integrations
- Verifying end-to-end business transactions
For example, Netflix's Automated Canary Analysis system uses synthetic transactions to validate new deployments, ensuring that changes don't negatively impact the user experience [6].
B. Chaos Engineering
Chaos engineering practices are becoming more sophisticated, allowing organizations to identify weaknesses in their systems and improve overall resilience proactively.
1) Chaos Engineering as Code
Automating chaos experiments increases efficiency and repeatability, allowing for more frequent and comprehensive testing. This approach, known as "Chaos Engineering as Code," involves:
- Defining experiments in version-controlled configuration files
- Integrating chaos experiments into CI/CD pipelines
- Automating the execution and analysis of experiments
- Ensuring consistent and reproducible chaos testing across environments
Tools like Chaos Toolkit and Litmus Chaos provide frameworks for implementing Chaos Engineering as Code, making it easier for organizations to adopt these practices at scale [7].
2) Game Days
Organizations are conducting more targeted chaos engineering exercises, often in the form of "game days," to improve system resilience and team readiness. These exercises typically involve:
- Simulating real-world failure scenarios
- Cross-functional participation (SRE, development, operations)
- Time-boxed problem-solving under pressure
- Post-exercise debriefs and action item tracking
For instance, Amazon regularly conducts game days to test and improve the resilience of their systems, including simulating the failure of entire data centers [7].
3) Chaos Engineering for Cloud-Native
Adapting chaos engineering practices for Kubernetes and serverless architectures is an active area of innovation. This includes:
- Developing Kubernetes-native chaos engineering tools
- Creating chaos experiments for serverless functions
- Testing service mesh resilience
- Validating auto-scaling and self-healing capabilities
Projects like Chaos Mesh, specifically designed for Kubernetes environments, are helping organizations apply chaos engineering principles to their cloud-native infrastructure [7]. As these observability, monitoring, and chaos engineering practices continue to evolve, they are becoming integral to the SRE toolkit. By providing deeper insights into system behavior and proactively identifying weaknesses, these techniques are enabling SRE teams to build and maintain more reliable, resilient, and performant systems.
|
Technique |
Issue Detection Improvement (%) |
Mean Time to Resolution Reduction (%) |
System Uptime Increase (%) |
Cost Efficiency Gain (%) |
|
Distributed Tracing |
65 |
40 |
15 |
20 |
|
Advanced Log Analytics |
70 |
45 |
12 |
25 |
|
Synthetic Monitoring |
55 |
30 |
10 |
15 |
|
Chaos Engineering as Code |
50 |
35 |
18 |
10 |
|
Game Days |
45 |
25 |
20 |
5 |
|
Cloud-Native Chaos Engineering |
60 |
38 |
22 |
18 |
Table 2: Comparative Effectiveness of Advanced SRE Techniques in System Reliability [5, 6]
IV. AUTOMATION AND DEVOPS IN SRE
Site Reliability Engineering (SRE) is at the forefront of automation and DevOps practices, continuously pushing the boundaries to improve system reliability, efficiency, and scalability. As systems grow more complex, automation becomes not just a convenience but a necessity for maintaining high levels of service reliability and performance.
A. Infrastructure as Code (IaC)
Infrastructure as Code (IaC) is rapidly expanding to manage increasingly complex infrastructure, improving consistency and reducing manual errors. IaC allows SRE teams to define and manage infrastructure using declarative configuration files, treating infrastructure provisioning and management as a software development process [8].
Key benefits of IaC in SRE include:
- Version Control: Infrastructure configurations can be version-controlled, allowing for easy rollbacks and change tracking.
- Reproducibility: Environments can be easily replicated across development, staging, and production.
- Scalability: Infrastructure can be scaled up or down programmatically based on demand.
- Compliance and Security: Security policies and compliance requirements can be codified and consistently applied.
Popular IaC tools in the SRE space include:
- Terraform for multi-cloud infrastructure provisioning
- Ansible for configuration management and application deployment
- Pulumi for infrastructure programming using familiar languages like Python or TypeScript
For example, major cloud providers have reported significant improvements in their infrastructure management efficiency by adopting IaC practices, allowing them to manage thousands of instances with small teams of engineers [8].
B. GitOps
The adoption of GitOps principles for declarative configuration management and deployment is streamlining SRE workflows. GitOps extends the Git-based workflow to infrastructure and application deployment, using Git repositories as the single source of truth for declarative infrastructure and applications [9].
Key aspects of GitOps in SRE include:
- Declarative Configurations: All system configurations are defined declaratively and stored in Git.
- Version Control: Changes to infrastructure and applications are tracked through Git commits.
- Automated Synchronization: Tools automatically sync the desired state in Git with the actual state in the production environment.
- Pull-based Deployment: Changes are pulled from Git repositories rather than pushed to environments, improving security and control.
Benefits of GitOps for SRE teams include:
- Improved collaboration between development and operations
- Enhanced auditability and traceability of changes
- Faster and more reliable rollbacks
- Simplified disaster recovery processes
Tools like Flux and ArgoCD have emerged as popular choices for implementing GitOps in Kubernetes environments, allowing for automated deployment and synchronization of applications and infrastructure [9].
C. Automation Platforms
Comprehensive automation platforms are being developed to handle end-to-end SRE workflows, from monitoring to incident response. These platforms aim to integrate various SRE tasks into a cohesive, automated system, reducing manual intervention and improving overall reliability [10].
Key features of modern SRE automation platforms include:
- Integrated Monitoring and Alerting: Automated collection and analysis of metrics, logs, and traces.
- Automated Incident Response: Triggering of predefined runbooks or playbooks in response to detected issues.
- Self-healing Systems: Automated remediation of common issues without human intervention.
- Capacity Planning: AI-driven forecasting and automated scaling of resources.
- Performance Optimization: Automated tuning of system parameters based on observed behavior and predefined policies.
For instance, several open-source projects demonstrate the power of integrated automation platforms in managing large-scale, complex systems [10].
The evolution of these automation platforms is closely tied to advancements in AI and machine learning, with many platforms incorporating predictive analytics and anomaly detection to preempt issues before they impact users [10].
As SRE practices continue to evolve, the focus on automation and DevOps principles is likely to intensify. These approaches not only improve system reliability and performance but also allow SRE teams to manage increasingly complex infrastructures at scale, freeing up time for more strategic initiatives and continuous improvement.
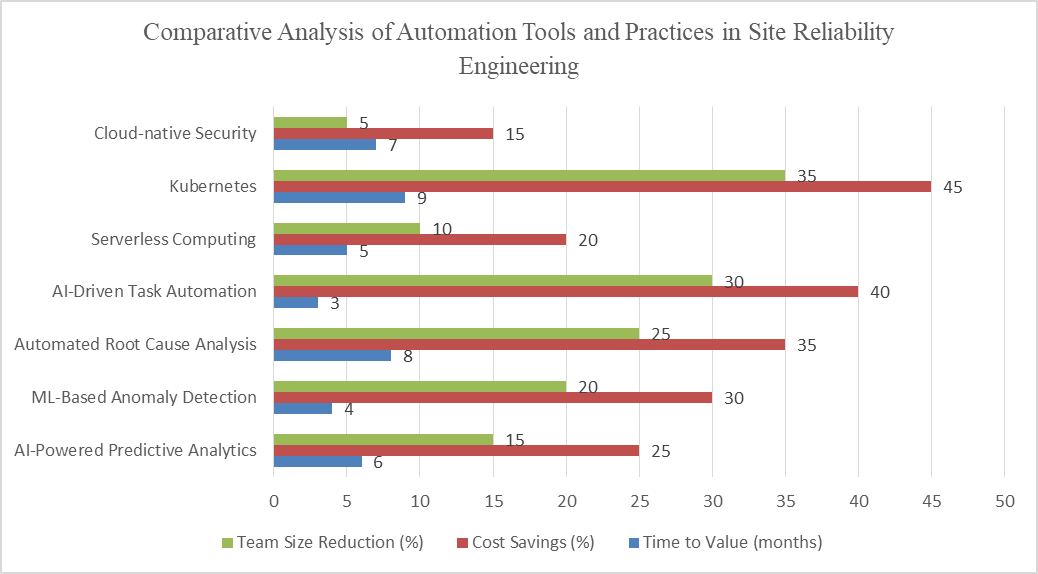 Fig 2: Impact of Automation and DevOps Practices on SRE Key Performance Indicators [8-10]
Fig 2: Impact of Automation and DevOps Practices on SRE Key Performance Indicators [8-10]
V. RESEARCH AREAS AND CHALLENGES IN SITE RELIABILITY ENGINEERING
As Site Reliability Engineering (SRE) continues to evolve, several key research areas are emerging that are shaping the future of the field. These areas not only address current challenges but also pave the way for the next generation of reliable, scalable, and efficient systems.
A. Quantifying SRE Impact
Developing metrics and methodologies to measure the business impact of SRE practices is crucial for justifying investments and guiding strategy. This research area focuses on creating a clear link between SRE initiatives and business outcomes.
Key aspects of this research include:
- Defining SRE-specific KPIs: Identifying and standardizing key performance indicators that accurately reflect the impact of SRE practices.
- Correlating Technical Metrics with Business Outcomes: Establishing clear relationships between technical reliability metrics (e.g., error budgets, SLOs) and business metrics (e.g., user satisfaction, revenue).
- Long-term Impact Analysis: Developing methodologies to assess the long-term effects of SRE practices on system reliability, operational efficiency, and organizational agility.
Recent industry discussions have highlighted the need for standardized measurement approaches in this field, emphasizing the importance of quantifiable metrics in demonstrating the value of SRE practices [11].
B. SRE Culture and Organization
Research into the role of SRE in organizational culture and structure is helping companies optimize their operational models. This area explores how SRE principles can be effectively integrated into different organizational contexts.
Key research topics include:
- SRE Team Structures: Investigating optimal team structures and reporting lines for SRE functions within organizations of different sizes and industries.
- Cultural Integration: Studying how SRE culture can be fostered and integrated with existing DevOps and Agile practices.
- Cross-functional Collaboration: Exploring models for effective collaboration between SRE teams and other functions such as development, security, and product management.
Limoncelli's work on "SRE in the Small and in the Large" provides insights into how SRE practices can be adapted for organizations of varying sizes and complexities [11].
C. SRE Talent Development
Identifying the skills and competencies needed for successful SRE teams and developing effective training programs is vital for addressing the talent shortage in the field. This research area focuses on building a sustainable pipeline of SRE talent.
Key research directions include:
- Skill Mapping: Identifying core and emerging skills required for SRE roles, including both technical and soft skills.
- Curriculum Development: Creating and validating curricula for SRE education in both academic and professional settings.
- Career Progression: Studying career paths within SRE and developing frameworks for professional growth and specialization.
The evolving nature of SRE roles, from small-scale to large-scale implementations, underscores the need for diverse skill sets and continuous learning in the field [11].
D. SRE for Emerging Technologies
Exploring SRE challenges and opportunities in areas like edge computing, IoT, and blockchain is paving the way for the next generation of reliable systems. This research area focuses on adapting and extending SRE practices to new technological paradigms.
Key research topics include:
- Edge Computing Reliability: Developing SRE practices for managing the unique challenges of distributed edge computing environments.
- IoT Device Management: Creating scalable SRE approaches for managing the reliability and security of large-scale IoT deployments.
- Blockchain Infrastructure: Exploring how SRE principles can be applied to ensure the reliability and performance of blockchain networks.
As SRE practices evolve to address these emerging technologies, new challenges in scaling and adapting reliability practices are likely to emerge, requiring innovative solutions [11]. As these research areas continue to evolve, they promise to significantly enhance the capabilities of SRE teams and extend the reach of SRE practices to new domains. However, they also present challenges in terms of standardization, tool development, and industry-wide adoption. Addressing these challenges will be crucial for the continued growth and maturation of the SRE field.
E. Innovative SRE Tools
The landscape of Site Reliability Engineering is constantly evolving, with new tools emerging to address the complex challenges faced by modern distributed systems. Here are some of the most innovative SRE tools that are shaping the future of the field:
- Datadog: This comprehensive monitoring and analytics platform has become a cornerstone for many SRE teams. Datadog's strength lies in its ability to provide a unified view of metrics, traces, and logs across complex, distributed environments. Its AI-powered anomaly detection capability uses machine learning algorithms to identify unusual patterns in system behavior, often catching issues before they escalate into major incidents. The platform's distributed tracing feature allows engineers to follow requests across microservices, making it easier to pinpoint performance bottlenecks. Datadog's integrations with over 400 technologies make it a versatile choice for diverse tech stacks [12].
- Prometheus: As an open-source monitoring system, Prometheus has gained widespread adoption in the SRE community, particularly in cloud-native environments. Its pull-based architecture and powerful query language (PromQL) provide flexibility and scalability that traditional push-based systems struggle to match. Prometheus excels in environments with dynamic service discovery, making it well-suited for container orchestration platforms like Kubernetes. Its built-in alerting capabilities, combined with tools like Alertmanager, enable SRE teams to set up sophisticated alerting and notification workflows. The project's active community ensures continuous improvements and a rich ecosystem of exporters for various systems.
- Chaos Mesh: In the realm of chaos engineering, Chaos Mesh stands out as a cloud-native platform specifically designed for Kubernetes environments. It allows SRE teams to simulate various failure scenarios, including pod failures, network issues, and even kernel-level faults. What sets Chaos Mesh apart is its declarative approach to defining chaos experiments, which aligns well with GitOps practices. The tool provides a web UI for visualizing and managing experiments, making it accessible to team members with varying levels of Kubernetes expertise. Chaos Mesh's ability to conduct targeted experiments on specific nodes or pods helps teams build more resilient systems without risking widespread production outages.
- Spinnaker: As a multi-cloud continuous delivery platform, Spinnaker has revolutionized the way SRE teams approach software deployment. Originally developed by Netflix, Spinnaker supports sophisticated deployment strategies like canary releases and blue-green deployments across multiple cloud providers. Its pipeline-as-code feature allows teams to version control their deployment processes, enhancing reproducibility and collaboration. Spinnaker's integration with cloud providers' native services (like AWS Auto Scaling Groups or Kubernetes Deployments) provides fine-grained control over infrastructure during deployments. The platform's robust plugin system allows for customization and extension, making it adaptable to various organizational needs.
- Istio: In the world of microservices, Istio has emerged as a powerful service mesh solution that addresses many SRE concerns. By providing a uniform way to secure, connect, and monitor microservices, Istio simplifies many complex operational tasks. Its traffic management capabilities allow for sophisticated routing and load balancing, enabling practices like canary deployments and A/B testing. Istio's built-in telemetry features provide detailed insights into service-to-service communication, aiding in troubleshooting and performance optimization. The platform's security features, including mutual TLS and fine-grained access policies, help SRE teams enforce consistent security practices across their microservices architecture. As organizations scale their microservices deployments, Istio's ability to abstract away many infrastructure-level concerns becomes increasingly valuable.
Conclusion
The field of Site Reliability Engineering is experiencing unprecedented growth and innovation, driven by the increasing complexity of modern digital systems and the demand for higher reliability and performance. From AI-driven predictive analytics and advanced observability tools to sophisticated chaos engineering practices and comprehensive automation platforms, SRE methodologies and technologies are rapidly evolving to meet the challenges of cloud-native, distributed environments. As organizations continue to prioritize system reliability and operational efficiency, the role of SRE is becoming increasingly strategic. The ongoing research in quantifying SRE impact, optimizing organizational structures, developing talent, and adapting practices for emerging technologies promises to enhance the capabilities of SRE teams further. Looking ahead, the continued evolution of SRE practices and tools will be crucial in enabling organizations to build and maintain more resilient, scalable, and efficient systems in an ever-changing technological landscape.
References
[1] B. Beyer, N. R. Murphy, D. K. Rensin, K. Kawahara, and S. Thorne, \"Site Reliability Engineering: How Google Runs Production Systems,\" O\'Reilly Media, 2016. [Online]. Available: https://research.google/pubs/site-reliability-engineering-how-google-runs-production-systems/ [2] Adrian Colley, Alex Martelli, manager at Google, Mark Lamourine, Richard L. Seroter, Ivan Dimitrov, \"The Practice of Cloud System Administration: DevOps and SRE Practices for Web Services, Volume 2,\" Addison-Wesley Professional, 2014. [Online]. Available: https://the-cloud-book.com/ [3] Kim Hazelwood; Sarah Bird; David Brooks; Soumith Chintala; Utku Diril; Dmytro Dzhulgakov, \"Applied Machine Learning at Facebook: A Datacenter Infrastructure Perspective,\" in 2018 IEEE International Symposium on High Performance Computer Architecture (HPCA), 2018, pp. 620-629. [Online]. Available: https://ieeexplore.ieee.org/abstract/document/8327042 [4] A. Iosup et al., \"The AtLarge Vision on the Design of Distributed Systems and Ecosystems,\" in 2019 IEEE International Conference on Cloud Engineering (IC2E), 2019, pp. 227-237. [Online]. Available: https://ieeexplore.ieee.org/document/8885212 [5] Y. Shkuro, \"Mastering Distributed Tracing: Analyzing performance in microservices and complex systems,\" Packt Publishing, 2019. [Online]. Available: https://www.packtpub.com/product/mastering-distributed-tracing/9781788628464 [6] C. Sridharan, \"Distributed Systems Observability,\" O\'Reilly Media, 2018. [Online]. Available: https://www.oreilly.com/library/view/distributed-systems-observability/9781492033431/ [7] C. Rosenthal, N. Jones, and A. Basiri, \"Chaos Engineering: Building Confidence in System Behavior through Experiments,\" O\'Reilly Media, 2017. [Online]. Available: https://icdt.osu.edu/chaos-engineering-building-confidence-system-behavior-through-experiments [8] N. Forsgren, J. Humble and G. Kim, \"Accelerate: The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations,\" IT Revolution Press, 2018. [Online]. Available: https://itrevolution.com/book/accelerate/ [9] A. Rocha, H. Adeli, L. P. Reis and S. Costanzo, \"Trends and Innovations in Information Systems and Technologies,\" Springer, 2020. [Online]. Available: https://link.springer.com/book/10.1007/978-3-030-45691-7 [10] L. Bass, I. Weber and L. Zhu, \"DevOps: A Software Architect\'s Perspective,\" Addison-Wesley Professional, 2015. [Online]. Available: https://www.oreilly.com/library/view/devops-a-software/9780134049885/ [11] Niall Murphy and Todd Underwood, \"SRE in the Small and in the Large,\" in ACM Queue, vol. 18, no. 5, pp. 55-66, Sept.-Oct. 2020. [Online]. Available: https://www.usenix.org/conference/lisa16/conference-program/presentation/closing-plenary [12] G. Beyer, C. Jones, J. Petoff, and N. R. Murphy, \"Site Reliability Engineering: How Google Runs Production Systems,\" O\'Reilly Media, Inc., 2016. [Online]. Available: https://research.google/pubs/site-reliability-engineering-how-google-runs-production-systems/
Copyright
Copyright © 2024 Nagarjuna Malladi. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET64327
Publish Date : 2024-09-24
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online