

Ijraset Journal For Research in Applied Science and Engineering Technology
F1 Score Based Weighted Asynchronous Federated Learning
Authors: Sneha Sree Yarlagadda, Sai Harshith Tule, Karthik Myada
DOI Link: https://doi.org/10.22214/ijraset.2024.58487
Certificate: View Certificate
Abstract
The domain of federated learning has observed remarkable developments in recent years, enabling collaborative model training while preserving data privacy. This paper discusses several recent advancements in the field of federated learning, particularly in asynchronous and weighted federated learning. A novel approach within the federated learning paradigm titled \"F1 Score Based Weighted Asynchronous Federated Learning\" is introduced. The approach addresses issues of biased aggregation and device heterogeneity by assigning weights to devices based on their F1 scores, prioritizing those with superior performance in classification. Leveraging the asynchronous nature of federated learning, this approach enhances both resource efficiency and convergence speed. By incorporating F1 scores into the weighting mechanism, a balanced emphasis on precision and recall is achieved. It can optimize resource utilization, expediting the learning process by focusing on updates from devices with more accurate and valuable information. This approach can enhance collaborative model improvement while preserving data privacy in federated learning.
Introduction
I. INTRODUCTION
Federated Learning or FL is a pivotal technique offering a collaborative framework where numerous parties can join efforts to develop a machine learning model in the field of Privacy-Preserving Machine Learning. This collaborative process is achieved without the necessity of sharing raw data. Instead, each individual party retains its private dataset and transmits model updates to a central server. A server then combines them and updates the shared model. FL can be found in various domains such as healthcare, IoT and finance. For instance, many hospitals can use their data on a pre-trained model and send their updates to a centralized server to be securely aggregated using FL in the context of constructing a machine learning model with a sensitive survey dataset.Fig. 1 demonstrates the FL approach. Asynchronous federated learning is an approach in FL that allows devices to contribute updates independently, eliminating the need for synchronized coordination and enabling more flexible participation, optimizing resource utilization.
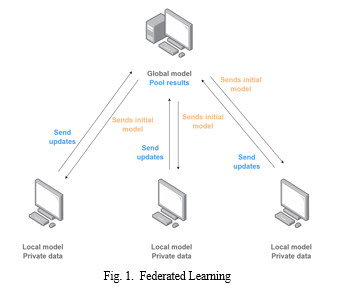
This paper introduces a novel extension to the asynchronous federated learning, termed "F1 Score Based Weighted Asynchronous Federated Learning." The approach utilizes a weighted aggregation strategy in FL, where devices' contributions are assigned weights, based on their F1 scores, thereby prioritizing those with better classification and balanced performance. Additionally, the approach leverages on the asynchronous nature of Federated Learning, enhancing both resource efficiency and convergence speed.Higher F1 scores lead to greater weight assignment, ensuring that devices excelling in classification accuracy and information balance hold more significance in shaping the global model.
II. EXISTING WORK
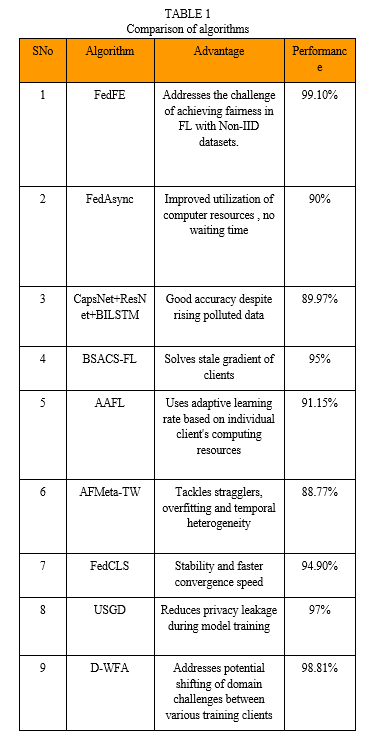
[1] The paper introduces a technique known as FedFE, designed to achieve fairness and efficiency in federated optimization. The inherent challenge of federated learning lies in the non-identically distributed (Non-IID) and non-independent nature of local data across participants. In order to mitigate the bias introduced by particular participants during aggregation, FedFE integrates momentum gradient descent in the training process and suggests a just distribution based on performance of participants in training. Evaluations and analysis on numerous non-IID datasets have been conducted to assess fairness, efficiency, and convergence rate. The results unequivocally demonstrate the superiority of the proposed approach over baseline algorithms. This efficient and equitable method for federated optimization leverages momentum gradient descent in conjunction with an equitable weighting strategy. With the objective of enhancing both effectiveness and equity, it presents a method for equitable weighting based on participants' training accuracy.
The approach suggested in this paper converges much more quickly than q-FedAvg and is comparable to FedFV.Based on experimental analysis, FedFE gained an accuracy of 99.11% on MNIST dataset. The training loss is also considerably less.
[2]The authors propose FedAsync,an Asynchronous Federated Learning algorithm to efficiently use the computer resources and eliminate waiting time that is mandatory in the case of Synchronous FL.This is done on the basis of dual weights:staleness weight and dual volume weight. The concept of staleness weight pertains to the extent of delay in the nodes in uploading model parameters, while the magnitude of data volume possessed by individual nodes in relation to the total volume is the data volume. Clients transmit these weights, and the central server averages the saved average weights of the global model depending on weights, which is subsequently dispatched to the nodes. Aggregation is rejected by the central server if the verison gap is more than or equal to 10.
The MNIST dataset, consisting of handwritten numbers from 0-9 in black-and-white is used. A Convolutional Neural Network(CNN) based on the PyTorch framework with two linear layers is built which is trained to identify handwritten digits. Pre-processed training data is fed through a cross entropy loss function and Stochastic Gradient Descent (SGD) optimiser. After 30 rounds of aggregation, it reaches an accuracy of 90% and statistics conclude it to have an efficient training speed than FedAvg.
[3]Introduces a new method titled “CapsNet+ ResNet+ BILSTM” for asynchronous deep federated learning that is resistant to data pollution. The approach employs a combination of gradient abnormality detection and model fusion to mitigate the effects of pollution. Gradient abnormality detection is used to identify local trainers whose data has been corrupted. These trainers are then removed from the federated learning process. Model fusion is employed to merge the predictions from multiple models, in turn enhancing the overall accuracy of these predictions. The CapsNet+ ResNet+ BILSTM method was evaluated on the CIFAR-10 dataset. Results demonstrate that the proposed method was able to attain high accuracy on both datasets, even in the presence of data pollution.
The paper claims an accuracy of 89.97% after experimental analysis. It proposes a new method for gradient abnormality detection that is robust to data pollution. Next, a method for model fusion that can be used to mitigate the effects of data pollution is detailed. Finally, it evaluates the proposed methods and shows that they are effective in improving the accuracy of federated learning models.
[4]In this paper, an algorithm titled Buffered Semi-Asynchronous Client Selection Federated Learning (BSACS-FL) is introduced, combining a buffer mechanism and Multi-Armed Bandit(MAB) striving to achieve better resource utilization and time efficiency.In the algorithm, only few clients are selected to upload their model in one training round.Selection of clients is done on the basis of freshness of model and computing capabilities. Upper Confidence Bound (UCB)-based MAB is utilized to forecast completion rounds of training and a buffer is set up on the client side to store trained models that were not selected. The buffer removes stale models periodically after it reaches a set bound.
Staleness of local models is associated with Training Staleness, which is the count of rounds required for the training of a model (TS) and Waiting Staleness(equal to total model staleness minus TS), which is the count of rounds where model remains in the buffer(WS). The selected client sends the latest trained model along with the TS, MAB uses TS of clients to select with minimum WS. The global server aggregates the models of the selected clients by a weighted aggregation method and updates TS and WS.
The algorithm is then evaluated with MobiAct and MNIST dataset concluding its efficiency compared to FedAvg, FedASync and FedBuff, with best accuracy of 95%.
[5]The paper focuses on improving the accuracy of federated learning when heterogeneous clients are involved in training a machine learning model. Heterogeneous clients are clients that have different computational resources or data distributions. This can make it difficult for clients to keep up with the global model, which can lead to accuracy degradation. Adaptive asynchronous federated learning (AFL) is a technique that can be used to address the challenge of heterogeneous clients in Federated Learning. AFL algorithms proposed in this paper dynamically adjust the learning rate and communication frequency of each client based on the client's individual characteristics. This measure aids in guaranteeing that every client can participate in the training process, facilitating the convergence of an optimum global model.
The paper sets three different level computational complexity models, each having a different hidden layer input-output channel shrinkage ratio. After experimental analysis with the CIFAR-10 data set, the maximum accuracy of a model is found to be 91.15%.
[6]This paper proposes Asynchronous Federated Meta-learning with Temporary Aggregation of Weighted (AFMeta-TW), one of the first works of asynchronous mode of federated meta-learning. Inorder to enhance model aggregation, it measures the staleness associated with the local models.An approach of temporarily weighted aggregation is utilized to combat temporal heterogeneity effectively and efficiently.The system aims to build an initial model with heterogeneous clients asynchronously by reducing learning time and embracing a meta-model for classification for a considerable performance. The approach resolves issues like stragglers and overfitting and temporal heterogeneity by using temporally weighted aggregation.
The first part of the algorithm includes the clients parallely operating, they receive the model,train it and return the local model and its index to the server.The second part includes the server aggregating the models with help of temporal weights.The revised model is subsequently sent to the clients back and incremented for further rounds.It reaches an accuracy up to 88.77%.
[7]In this study, a novel approach named Federated Learning Client Selection with Cluster Label Information (FedCLS) is introduced to address the limitations of the random client selection technique employed by algorithms like FedAvg, which overlooks the data distribution. This is achieved by creating a model based on cluster label information. Initially, individual machines upload their local faulty data along with corresponding labels to a central server. By leveraging these labels, the machines are grouped into clusters. From these clusters, pertinent ones are selected for training. The selected machines are provided with the global model, which they use to train on their respective local datasets. Subsequently, the central server combines the updates to substitute the existing global model. The iteration persists until convergence, repeating the cycle for new data.
The proposed client selecting method pertains to cluster label information including clustering and extraction. Clustering involves encoding fault labels and forming clusters based on similarity. The process of selecting cluster labels and extracting clients is done randomly, matching labels based on similarity, and updating cluster labels.It achieves an accuracy of 94.9%. Its advantages include: faster convergence, improved stability and resource-efficiency. It also reduces the amount of clients, computing consumption and communication overhead.
[8]This work introduces a collaborative approach to federated learning that primarily emphasizes the reduction of privacy exposure throughout the model training process. The Utilized Stochastic Gradient Descent algorithm, alters parameters only when necessary to secure the gradient, serves as the framework's foundation. The analysis after experiments demonstrates that the approach which is proposed prevents unauthorized information extraction by the server from the model, thus bolstering privacy safeguards and concurrently ensuring the accuracy of the training model. The structure encompasses multiple participants, each possessing an individualized local dataset, and a central server for aggregation updating the model parameters by averaging the parameters of each participant. Additionally, a protocol for exchange of parameters is employed. The stochastic gradient descent process filters the gradients in order to prevent malicious participants from being interested in the data of other participants. The accuracy of the algorithm proposed is 97%. By modifying the submitted gradients and choosing the gradients of the parameters without uploading all of the gradient values, the server cannot derive meaningful information from the uploaded gradient values.
[9]The work introduces a Federated Transfer Learning (FTL) framework with discrepancy-based weighted federated averaging (D-WFA) algorithm that is used for model training. A training approach is introduced within the Federated Learning framework for diagnosing fault, taking the shifting in domain issue into account. This concern is addressed by employing an MMD-based strategy. Dynamic-Weighted Federated Averaging (D-WFA) algorithm, based on discrepancies, addresses potential shifting of domain challenges between various training clients. It balances as well as assesses the influence of the current client models.
The proposed D-WFA algorithm has shown better performance on experimental tests over other FTL algorithms when the ball bearing dataset is used.Whilst ensuring data privacy, D-WFA achieves performance that is close to the non-privacy-preserving centralized learning scheme, consequently, it is a dependable option for practical industrial applications.
The performance of D-WFA is around 98.81%. The D-WFA algorithm achieves a higher diagnosis when compared to the traditional FedAvg and other FTL methods.
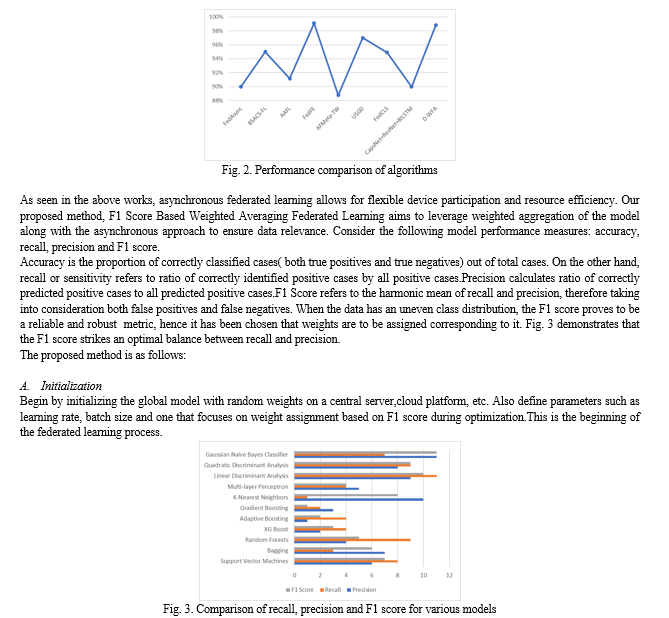
B. Device Selection and Weight Assignment
Assign different weights to each device based on their F1 scores achieved during local model training. Devices with higher F1 scores will be assigned higher weights, hence contributing more.
C. Local Training/Update
The client or device:
- Obtains a global model that the server has provided.
- Trains the model using locally available data.
- Evaluates F1 score on a validation subset of its data
- Update the local model’s weights based on the results of training and validation using optimization algorithms
D. Asynchronous Model Aggregation
Devices communicate their updated local models to the central server in an asynchronous manner, which permits contributions when ready instead of waiting like in the case of synchronous aggregation. Weighted averaging is performed by the central server to aggregate models.
E. Global Model Update
Central server integrates the aggregated local models from devices to update the local model which then acts as a starting point for subsequent rounds of local updates.
F. Iterations
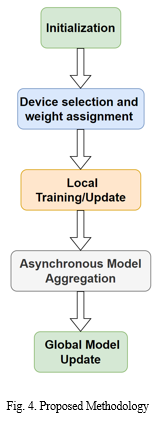
The process of local model updates, asynchronous aggregation is carried out over several iteration cycles. The objective is to improve the effectiveness of the global model during these cycles, accommodating differences in data and resources among various devices.The method is demonstrated in Fig. 4.
III. DISCUSSION
Assigning weights to devices with F1 scores in the federated learning process brings forth multiple advantages. By prioritizing devices with better F1 scores, the approach places emphasis on data relevance and a balance between precision and recall(via F1 Score). This strategy accommodates the heterogeneity of devices, allowing those with stronger performance to exert a greater impact on the global model while mitigating the impact of the comparatively weaker devices.
Consequently, the aggregated model demonstrates enhanced overall performance, especially in scenarios with uneven data distributions.
Biased aggregation is also minimized, as the approach ensures that contributions from well-performing devices carry greater weight.Also, this approach helps in utilizing resources efficiently in line with how federated learning works and makes the learning process finish faster by focusing on updates from devices with more valuable and correct information. In short, this way of assigning weights significantly improves how different devices work together better in making the model improve more efficiently.
Conclusion
In conclusion, the introduced \"F1 Score Based Weighted Asynchronous Federated Learning\" approach can be a noteworthy advancement in federated learning. By fusing the concepts of weighted aggregation and asynchronous updates, the strengths of both techniques create a more efficient, accurate, and privacy-conscious FL approach. In summary, the weighted approach driven by F1 scores in federated learning can lead to enhanced model performance, accommodate device heterogeneity and improve data utilization. This methodology also minimizes biased aggregation and optimizes resource allocation, aiding the model to reach its goal faster.
References
[1] W. Pan and H. Zhou, “Fairness and Effectiveness in Federated Learning on Non-independent and Identically Distributed Data,” 2023 IEEE 3rd International Conference on Computer Communication and Artificial Intelligence (CCAI), Taiyuan, China, 2023, pp.97-102, doi:10.1109/CCAI57533.2023.10201271. [2] Y. Jia and N. Zhang, “Research and Implementation of Asynchronous Transmission and Update Strategy for Federated Learning,” 2022 IEEE 8th International Conference on Computer Communications (ICCC), Chengdu, China, 2022, pp.1281-1286, doi:10.1109/ICCC56324.202210065902. [3] Y. Lu and X. Cao, “Asynchronous Deep Federated Learning Method Based on Local Trainer Data Pollution,” 2022 International Conference on Automation, Robotics and Computer Engineering (ICARCE), Wuhan, China, 2022, pp.1-5, doi:10.1109/ICARCE55724.2022.10046641. [4] C. Wang, Q. Wu, Q. Ma and X. Chen, “A Buffered Semi-Asynchronous Mechanism with MAB for Efficient Federated Learning,” 2022 International Conference on High Performance Big Data and Intelligent Systems(HDIS), Tianjin, China, 2022, pp.180-184, doi:10.1109/HDIS56859.2022.9991371. [5] Y. Liang, C. Ouyang and X. Chen, “Adaptive asynchronous federated learning for heterogeneous clients,” 2022 18th International Conference on Computational Intelligence and Security (CIS), Chengdu, China, 2022, pp.399-403, doi:10.1109/CIS58238.2022.00090. [6] S. Liu, H. Qu, Q. Chen, W. Jian, R. Liu and L. You, “AFMeta: Asynchronous Federated Meta-learning with Temporally Weighted Aggregation,” 2022 IEEE Smartworld, Ubiquitous Intelligence & Computing, Scalable Computing & Trusted Vehicles (SmartWorld/UIC/ScalCom/DigitalTwin/PriComp/Meta), Haikou, DigitalTwin-priComp-Metaverse56740.2022.00100. [7] C. Li and H. Wu, “FedCLS: A federated learning client selection algorithm based on cluster label information,” 2022 IEEE 96th Vehicular Technology Conference (VTC2022-Fall), London, United Kingdom, 2022, pp.1-5, doi:10.1109/VTC2022-Fall1157202.2022.10013064. [8] F. Mei, J. Lv and Y. Cao, “Parameter Update Framework based on Unitized Stochastic Gradient Descent Algorithm in Federated Learning,” 2022 3rd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Xi’an, China, 2022, pp.656-660, doi:10.1109/ICBAIE56435.2022.9985856. [9] J. Chen, J. Li, R. Huang, K. Yue, Z. Chen and W. Li, “Federated Transfer Learning for Bearing Fault Diagnosis With Discrepancy-Based Weighted Federated Averaging,” in IEEE Transactions on Instrumentation and Measurement, vol. 71, pp. 1-11, 2022, Art no. 3514911, doi: 10.1109/TIM.2022.3180417.
Copyright
Copyright © 2024 Sneha Sree Yarlagadda, Sai Harshith Tule, Karthik Myada. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET58487
Publish Date : 2024-02-18
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online