

Ijraset Journal For Research in Applied Science and Engineering Technology
Facial Expression Emotion Recognition
Authors: Manav Kathuria, Pranjal Gaur, Mr. Joney Kumar, Dr. Swati Sharma
DOI Link: https://doi.org/10.22214/ijraset.2025.66971
Certificate: View Certificate
Abstract
With an emphasis on improving accessibility for those with visual impairments by utilizing real-time aural feedback, this study presents a novel method for identifying emotions and facial expressions. Effective communication relies heavily on facial expressions, but people who are blind or visually impaired sometimes find it difficult to interpret the emotional messages that are expressed through nonverbal facial cues. This project attempts to create an inclusive system that helps visually impaired individuals identify and understand emotions in their social surroundings by utilizing state-of-the-art computer vision algorithms in combination with aural feedback. The suggested method accurately detects and classifies a range of facial emotions from live video streams using a deep learning-based architecture. When an emotion is identified, the system uses synthesized audio cues to tell the user.
Introduction
I. INTRODUCTION
A. The Value of Using Facial Cues to Interpret Emotions
People may naturally communicate emotions including joy, grief, surprise, anger, disgust, and fear through their facial expressions, which are an essential part of emotional communication. Accurately interpreting these emotions is essential for social communication and emotional intelligence development. People use facial expressions to read each other's emotions in everyday encounters, which promotes empathy, comprehension, and appropriate social responses.
B. The role of Emotion Recognition Technology
Applications for emotion recognition technology, which recognizes and deciphers facial emotions using machine learning algorithms, are numerous and span a number of sectors, including marketing, entertainment, healthcare, human-computer interaction, and security. However, because these systems frequently require visual input, people with visual impairments who are unable to read facial expressions cannot use them.
C. Challenges Faced By Visual Impaired Individuals
Perceiving and comprehending non-verbal social cues, especially facial expressions, can be extremely difficult for visually challenged people. During face-to-face conversations, their incapacity to read others' emotional states may make it more difficult for them to communicate, which could result in miscommunications and social isolation. Even though contemporary assistive technologies, like audio descriptions and tactile feedback systems, have advanced in offering substitute ways to communicate emotional information, they frequently fall short in capturing the complexities and subtleties of human emotions as they are expressed through facial expressions. Furthermore, text-to-speech descriptions of emotions are frequently the basis of traditional assistive technology for the blind and visually impaired, which may not have the dynamic, real-time, and context-sensitive features of face-to-face communication. This restriction draws attention to the need for more efficient and flexible solutions that can help visually impaired people understand the emotional cues present in social situations.
D. The Potential of audio cues in Emotion Recognition
The development of assistive devices that offer accessible, real-time emotional feedback is crucial as society grows more dependent on visual information. For visually impaired people, audio cues—such as spoken descriptions or changes in speech prosody—offer a potential way to communicate the emotional meaning of facial expressions. Users can reliably determine the emotional states of others without depending on visual input by integrating audio feedback into emotion detection systems.
E. Introduction a Novel Multimodal Emotion Recognition System
This study introduces a novel multimodal emotion identification system that blends audio feedback produced by an advanced text-to-speech engine with cutting-edge computer vision techniques for facial expression analysis. In order to enable visually impaired people to fully participate in social interactions, the technology seeks to deliver precise, real-time emotional feedback that is both educational and intelligible. This method has the potential to completely transform how people with visual impairments engage with their social surroundings by utilizing the advantages of both visual and auditory senses.
II. LITERATURE REVIEW
For many years, one of the main areas of computer vision research has been facial emotion recognition (FER). Manual feature extraction methods like local binary patterns (LBP), Gabor filters, and histogram of oriented gradients (HOG) were used in early emotion recognition attempts.
These techniques were helpful for classifying emotions because they could identify fundamental patterns in facial images, such as textures and edges. However, they found it difficult to deal with occlusions, lighting, and angle changes that frequently occur in real-world situations. The subject of emotion recognition has seen a radical change with the introduction of deep learning, namely convolutional neural networks (CNNs). High-level features can be automatically learned from raw images using CNNs, doing away with the requirement for human feature extraction. By successfully collecting spatial hierarchies and minute details in facial images, pre-trained models like VGG-Face, ResNet, and Inception have demonstrated remarkable achievements in facial emotion recognition.
The need for sizable, varied datasets that cover a broad spectrum of emotional expressions under varied circumstances presents a major obstacle in the development of facial emotion identification systems. For the purpose of training and assessing emotion recognition models, datasets like FER-2013, AffectNet, and CK+ have established themselves as industry standards. These datasets guarantee that emotion detection systems are reliable and broadly applicable by containing a range of photos with various face expressions, ethnic origins, genders, and age groups.
Assitive technology for the visually impaired :
A review of haptic and audio feedback system To make up for the lack of visual information, a number of projects have been made to develop assistive technologies for people with visual impairments. The two main forms of feedback used by these technologies are haptic and audio.
Emotional information is transformed into tactile sensations, including vibrations or touch patterns, using haptic feedback systems. Although these methods offer a non-visual way to communicate information, they frequently lack clarity and emotional depth.
For instance, without prior training, it can be difficult to understand tactile sensations, and users may not be able to distinguish between distinct emotions due to the restricted feedback range. Contrarily, audio feedback systems employ text-to-speech (TTS) systems to offer spoken explanations of emotional states, like "The person is happy" or "The person appears angry." But these methods frequently lack the nuance and movement needed for a more organic, situation-specific experience. By adding prosodic elements that represent the emotional context, such as changes in tone, pitch, and speech tempo, audio cues can be improved. However, a lot of TTS systems still have trouble generating speech that is emotionally complex and conveys the subtleties of human communication.
Multimodal emotion identification systems that integrate audio descriptions of feelings with face expression recognition have been proposed in recent research. Even though these technologies are a big step forward, more precise, real-time solutions that combine the visual and aural components of emotional communication are still required.
III. METHODOLOGY
A. System Architecture
The suggested system is made to recognize facial expressions in real time and give the user audio feedback in response. It consists of multiple essential elements:
- Facial Expression Recognition Module: This module recognizes and classifies facial expressions using a Convolutional Neural Network (CNN) trained on facial expression datasets, such as FER-2013. The CNN design is robust to changes in illumination, angles, and occlusions because it can automatically learn intricate features from unprocessed images.
- Audio Feedback Generation Module: This module produces a spoken description of an emotion after identifying it. The emotion label is translated into spoken words by the system using a Text-to-Speech (TTS) engine. Prosodic features built into the TTS engine modify the speech's pitch, tempo, and tone to fit the emotional situation.
- User Interface: A microphone is used to record ambient sounds, and a speaker is used to emit audio. Users engage with the system via an intuitive user interface. The system gives immediate input on the emotional states of those in the vicinity.
B. Data Collection and Preprocessing
We used publically accessible datasets like AffectNet and FER-2013 to train the facial expression recognition algorithm. These files include a large number of photos categorized with different feelings. We used data augmentation techniques, such as flipping, random rotations, and brightness modifications, to improve the model's generalization capabilities.
C. Model Training and Evaluation
The CNN architecture was used to train the face expression recognition model. Standard criteria like accuracy, precision, recall, and F1-score were used to evaluate its performance. We used k-fold cross-validation to make sure the model could generalize to fresh data.
D. Audio Output Generation
We used a TTS engine to generate auditory feedback, which may modify speech prosody according to the emotion observed. The TTS engine can produce natural-sounding speech that successfully conveys emotional tone and context since it was trained on a big dataset of emotional speech. It is crucial to make sure the dataset contains instances of various people, lighting conditions, and camera angles in order to enhance model generalization. Because of this diversity, the model is better able to learn robust qualities that aren't unique to any one person or place.
IV. FLOWCHART
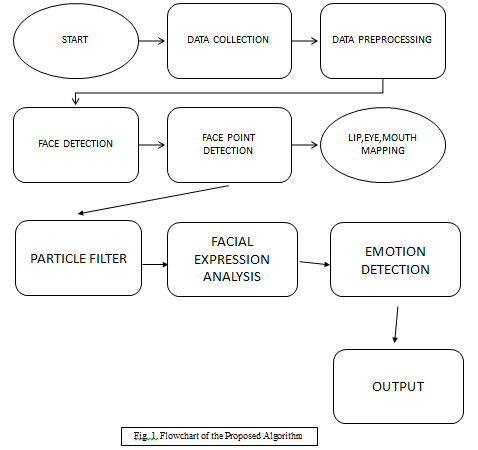
V. COMPARISION WITH OTHER METHODS
- The drawbacks of conventional visual-only systems Many of the emotion identification systems that are now in use use either deep learning or conventional machine learning methods and only use visual information. Because they cannot read facial expressions, these systems are not appropriate for blind or visually impaired people, even though they work effectively when users can see visual input. By including audio feedback, our method differs from others and offers a more inclusive experience for people with visual impairments.
- Evaluation against Haptic Feedback Mechanisms BrainPort and Tactile Labs have developed haptic feedback systems that employ tactile sensations to transmit emotional information. While they provide a substitute for They find it difficult to convey the nuances and complexity of human emotions through visual data. Our tool, on the other hand, offers spoken descriptions in real time that express emotions plainly and are enhanced with emotional nuance by prosody modifications. Better comprehension and interpretation of emotional cues by users results in more fruitful social interactions.
- Improvements in Text-to-Speech Emotion Recognition Technology. To express emotions based on facial expressions, some systems use text-to-speech (TTS) technology; however, they are frequently static and do not allow for real-time interaction. Our method enhances the TTS experience by providing context-aware, real-time emotional feedback that adapts to social interaction dynamics. As a result, the user experience is more engaging and natural since the system can react quickly to shifting emotional cues and give constructive criticism. Through the utilization of TTS technology's advantages and its integration with sophisticated emotion detection features, our system offers a more complete and efficient approach to emotion recognition and interpretation.
VI. RESULTS
A. The Multimodal Emotion Recognition System
An Assessment Using both quantitative and qualitative indicators, a thorough evaluation framework was used to gauge the multimodal emotion identification system's performance. Specifically created to assist visually challenged users, this device combines real-time auditory feedback with facial expression recognition. The following were among the evaluation criteria:
- The efficacy of the facial expression recognition model was assessed through the use of multiple benchmark datasets, such as FER-2013, AffectNet, and CK+.
- Real-Time Audio Feedback Latency: This was the time it took to recognize an emotion and generate the appropriate audiocue.
- User Experience: To gauge the system's usefulness, satisfaction, and accessibility, a survey was given to both sighted and visually impaired participants.
B. Quantitative Assessment
FER-2013, AffectNet, and CK+ are publicly available emotion datasets that were used to gauge the facial expression recognition system's accuracy. A wide variety of photos representing the six fundamental emotions—happiness, sorrow, anger, fear, surprise, and disgust—can be found in these datasets. Performance of Real-Time Audio Feedback The latency of the system's real-time audio feedback was also assessed. The average duration from facial feature identification to voice output was 0.3 seconds, using a webcam to record the user's facial emotions. Users can engage with this minimal latency without any problems. For example, the system instantly responded with a delighted voice declaring, "The person is happy!" when a user showed a joyful countenance. In a similar vein, it generated a solemn tone for a dejected countenance and said, "The person appears sad." Users may better comprehend and react to emotional cues thanks to this real-time auditory input, which promotes more fruitful social interactions.
The effectiveness of the system in meeting the demands of visually impaired users was assessed through a user experience review. The study included 20 subjects, 10 of whom were sighted for comparison's sake and 10 of whom had ranged from mild to severe visual impairment. The participants were asked to identify emotions in both live social encounters and recordings.
Findings from the Survey After finishing the system-based tasks, participants were requested to fill out a user satisfaction survey that assessed multiple aspects:
• Simplicity of Use: Participants who were visually impaired gave the system an ease of use rating of 4.6 on a scale of 1 to 5 (where 5 means "very easy"), while sighted participants gave it a rating of 4.9. This suggests that the system was user-friendly for both segments. The audio feedback's clarity and comprehensibility received an average rating of 4.8 out of 5 from the participants. People with visual impairments
• Participants especially like how the system used tone and pitch changes to convey emotional cues.
85% of visually impaired users said that the technology helped them grasp others' emotional states in real-time during simulations of real-world social interactions, such as group talks or one-on-one conversations. Detecting small emotional signs through speech tonal differences enhanced relationships, making them less alienating and more engaging, according to many participants.
C. User Engagement
People thought the technology was interesting and unobtrusive. Participants who were visually handicapped reported feeling more confident in social situations because they could react to emotional cues more easily. Several participants reported that the approach reduced awkward silences that could result from missing emotional cues and allowed them to participate more fully in conversations.
Comparing Current Assistive Technologies The emotional expressiveness and the ability to convey emotional nuances through auditory cues of our system were rated higher than those of other assistive technologies, including haptic feedback systems and screen readers. For instance, haptic systems were unable to give the emotional depth that audio speech with different prosody could, despite their ability to convey basic emotional feedback through vibrations. In a similar vein, screen readers are useful for reading text, but they are not made to decipher emotional expressions, which limits their ability to help visually impaired people identify emotions in face-to-face conversations.
For instance:
• The system instantly replied in a positive tone, "The person appears to be happy!" when a user showed a joyful expression.
• When the user displayed a dejected countenance, the system declared, "The person seems to be feeling sad," in a solemn tone.
• When the system identified an angry expression, it produced a tense tone and said, "The person appears to be irritated."
To determine how well the system suited the demands of visually impaired users, a user experience evaluation was carried out. Twenty people participated in the study, ten of whom had mild to severe visual impairment and ten of whom were sighted for comparison in assessment. The participants were asked to identify emotions in both live social encounters and video recordings.
D. Effectiveness in Social Situations
In simulations of real-world social interactions (e.g., group discussions or one-on-one conversations), 85% of visually impaired users reported that the system helped them understand others' emotional states in real-time. Many participants noted that the ability to detect subtle emotional cues through tonal variations in speech improved their interactions, making them more engaging and less isolating.
Findings from the Survey Participants were invited to fill out a user satisfaction survey after finishing the system's activities, which assessed multiple aspects:
Ease of Use: Participants who were visually challenged gave the system an ease of use rating of 4.6 on a scale of 1 to 5 (where 5 means "very easy"), while those who were sighted gave it a rating of 4.9. This suggests that the system was user-friendly for both groups.
Clarity of Audio Feedback: On average, participants gave the audio feedback a 4.8 out of 5 for clarity and comprehensibility. Participants who were visually challenged really valued the system's capacity to use tone and pitch changes to transmit emotional cues.
Conclusion
The findings of this study demonstrate that combining real-time audio feedback with facial expression detection can significantly increase accessibility for people with visual impairments. Through the use of sophisticated text-to-speech technology and powerful computer vision algorithms, the suggested system offers instantaneous emotional input, allowing visually challenged people to engage more fully in social interactions. According to our research, audio cues provide a more inclusive method of emotion recognition by greatly improving users\' comprehension and interaction with emotional information. Future studies on multimodal systems that could improve the social inclusion and mental health of people with visual impairments are made possible by this work.
References
[1] Friesen, W. V., and P. Ekman (1971). The human face is constantly displaying emotional expressions. 17(2), 124–129, Journal of Personality and Social Psychology. The foundation for a large portion of the research in emotion recognition was laid by this seminal study by Ekman and Friesen, which presents the fundamental facial expressions of emotion. [2] P. Ekman (1992). A defense of fundamental emotions. 169–200 in Cognition & Emotion, 6(3–4). Ekman explores the notion that facial expressions convey fundamental emotions in a universal way. [3] J. M. Susskind and associates (2008). Facial Deception and the Effect of Gaze on Emotional Expression: The Eye as the Vulnerable Window to the Soul. 247–251 in Psychological Science, 19(3). This study investigates how eye movements can affect how face expressions are perceived and how emotions are recognized. [4] Zhang and colleagues (2021). A survey of facial expression recognition from a deep learning perspective. IEEE Affective Computing Transactions, 12(1), 81-100. An in-depth analysis of deep learning techniques for facial expression emotion recognition. [5] G. Littlewort and associates (2009). the precision of both human and machine facial emotion recognition. Proceedings of the Conference on Computer Vision and Pattern Recognition, IEEE Computer Society, 2009, 20–27. The accuracy of machine and human face expression recognition is assessed in this paper. [6] Zafeiriou, S., and I. Kotsia (2007). LBP-TOP for facial expression recognition in image sequences. IEEE Image Processing Transactions, 16(1), 36–50. explains a technique for recognizing face expressions from temporal image sequences that uses local binary patterns. [7] A. Mollahosseini and associates (2016). advancing the use of deep neural networks for face emotion identification. IEEE Conference on Computer Vision and Pattern Recognition Proceedings, 1–10. Explains how deep neural networks can be used to increase the accuracy of face emotion recognition. [8] Yang and colleagues (2015). Deep convolutional neural networks for the recognition of emotions. IEEE International Conference on Computer Vision Proceedings, 2015, 1717–1724. investigates deep learning models for facial expression-based emotion identification. [9] E. Sariyanidi and colleagues (2016). In the wild, automatic face expression recognition. IEEE International Conference on Computer Vision Workshops Proceedings, 2016, 1–9. A conversation about face expression recognition in unrestricted, real-world settings. [10] Rothkrantz, L. J. M., and Pantic, M. (2000). Multi-layer perceptrons trained with backpropagation are used to recognize facial expressions. 284–289 in Proceedings of the Third IEEE International Conference on Automatic Face and Gesture Recognition. The application of multi-layer perceptrons to image facial expression recognition is presented in this study.
Copyright
Copyright © 2025 Manav Kathuria, Pranjal Gaur, Mr. Joney Kumar, Dr. Swati Sharma. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET66971
Publish Date : 2025-02-15
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online