

Ijraset Journal For Research in Applied Science and Engineering Technology
Fake News Detection and Analysis
Authors: Garima Agarwal, Ayush Kumar, Diwakar Chauhan, Neha Tyagi
DOI Link: https://doi.org/10.22214/ijraset.2024.62129
Certificate: View Certificate
Abstract
The internet is filled with inaccurate information, which makes it tough to distinguish between what is true and what is not. This review paper explores how scholars and IT professionals are countering false information by examining various strategies. We start by looking at different types of fake news and how they circulate. We then discuss a range of methods and tools that can be used to identify false information, including advanced computer programs and language analysis. These approaches can be categorized into three groups: analysing the language used, taking into account contextual data, and studying the distribution trends on the internet. We also discuss a method for teaching computers to detect patterns using machine learning false narratives by learning to differentiate between emotions and language subtleties. The paper also emphasizes the significance of fairness and impartiality in detection technologies. We conclude by discussing possible future research areas for academics and technology professionals it\'s critical to stay current with the quickly developing field of fake news.
Introduction
I. INTRODUCTION
As the digital age has evolved, social media has become the main place to find news, providing fast, easy, and cost-effective access to a variety of information [2]. Online consumers are at risk from a variety of scams, such as those that include fraudulent live-streaming videos, which con artists exploit to trick viewers with phoney content or phishing efforts. Be wary of dubious online discounts as they can be scams intended to fool people into sending personal information or becoming victims of fraud. Watch out for phoney online competitions and surveys. These can be used by scammers to get private information and initiate phishing attacks, endangering online privacy and security. Refrain from interacting with fictitious customer service accounts on social media since con artists pretend to be respectable companies to trick individuals into disclosing personal information or carrying out illicit transactions. Furthermore, be wary of phoney comments left under well-known posts, since con artists may utilise fictitious accounts to disseminate false information, advertise frauds, or carry out phishing operations. Watch out for Foursquare scams where users are tricked into clicking on bogus tips or receiving false information; always double-check information before acting.
User participation in online social media has led to crimes like fake news spread and creating counterfeit content. It's necessary to ensure information authenticity to combat these issues. Detecting FakeX is a priority as it misleads readers by providing false information. Preventing its spread on social media is crucial, but it presents unique challenges. It's essential to acknowledge the potential harms caused by fake news in the digital era.[5] Globally, individuals are generating and consuming unprecedented amounts of news as a result of the growth of social media sites and the improvement in online material accessibility. However, amid this information abundance, concerns about the authenticity and reliability of news have become more pronounced than ever. The term "Fake Data" has emerged as a catch-all phrase to describe misinformation, disinformation, and misleading content that permeate various social media channels. Fake news should never be spread for entertainment. The Coronavirus is an example of such news. With time, fake news is also spreading at an increasing rate. Various technological giants, such as Facebook, Twitter, and YouTube, have contributed to this rapid increase during the past decade. A recent example of it is the Inquisition on 19th October 2019 between, US representative, Alexandria Ocasio Cortez and the founder of Facebook, Mark Zuckerberg. Mark Zuckerberg appeared before the US Congress’s House to converse about Facebook's plans for crypto-currency (Libra). At that moment Alexandria questioned him about the fact-checking done by Facebook for misinformation on its articles. She asked him whether any individual could promote false political propaganda on Facebook to this he accepted that Facebook is not very capable of detecting such hoaxes and rumours. Detection methods in existence often depend on a big mass of training features. Yet, the statistical figure of the recognized rumours is often negligible.
Concerns regarding the way fake news is characterised have been voiced by numerous researchers. Reports that contain inaccurate information may not be seen as fake news, despite the public's belief that journalists do not purposefully present false information. Nonetheless, even though some news reports have some facts, a lot of people view them as untrustworthy because the reporters utilise far too many hyperbolic claims. This study aims to give readers a thorough grasp of current developments in the field of false data research as well as an overview of the various aspects of fake news.
Detecting fake news on social media is a challenging task due to the variety of content (audio, video, text, images etc.), voluminous data, ease of accessibility over the internet, and velocity of data. It has been investigated in previous studies how dissemination and exposure to dishonest information results in negative outcomes. According to some studies, not only users of an explicit age, gender, or educational level experience difficulty with distinctive fake news, but all individuals have issues with it. To combat the spread of false information, it is essential that the skills and education of pretend news reporters be developed. During this review, factors that contribute to the sharing and spreading of fake news have been determined and discussed. As a result of this review, computer users should be equipped with the skills to find and recognize information, as well as cultivate the ability to prevent the spread of inaccurate information.
This study aims to contribute to the expanding body of literature on fake data by delving into the complexities surrounding its generation, dissemination, and societal implications. By conducting a thorough examination of current data the purpose of this study is to shed light on the frequency of fraudulent data, the traits of deceptive material, and the variables impacting the public's perception of it. The study also aims to look into the technological, sociological, and psychological facets of the bogus data phenomena. The main objective is to provide insights that can guide the development of strategies to counteract its harmful effects. Positioned as a pioneering effort in the pursuit of truth, the research endeavours to uncover the intricacies of deception, charting a course toward a society that is more robust, knowledgeable, and discerning.
II. RELATED WORK
A comprehensive overview of relevant research on identifying fake news is presented in this section.
Numerous machine learning and deep learning models are discussed.
The authors have put forward a classifier model for Fake News Detection that analyses the credibility of content with the TF-IDF vectorizer and the passive-aggressive classifier algorithm [1]. They have utilised Sci-kit Libraries in Python. Studies show that the results of the suggested version are comparable to current models. The suggested version is operating correctly and can define an outcome's correctness with an accuracy of up to 93.6%. In another breakthrough research authors have proposed a method for developing a supervised machine learning algorithms-based model on a labelled dataset to identify words, phrases, sources, and titles to ascertain the authenticity or fraud of data. Any system can be combined with this paradigm and used in the future. In this paper, The author used an unsupervised Bayes classifier to identify bogus news. This method was implemented as a software framework and evaluated on several Facebook records [2]. The patterns are predicted with 85-91% accuracy using an unreliable probability threshold. The way that training and test sets perform when we add more data to our classifiers is also examined by the author using learning curves and Precision-Recall. The research employs it to perform tokenization of data and feature extraction of the text of the dataset.
Authors have discussed the delves into news content models, focusing on two methods focused on style and knowledge. Knowledge-based methods verify the truthfulness of claims by leveraging external resources, such as fact-checking by experts, crowdsourcing strategies, and computational methods. Style-based methods aim to detect fake news through writing styles, with deceptionoriented approaches identifying deceptive statements and objectivity-oriented approaches capturing signals of decreased objectivity, such as extreme politicisation and yellow journalism. The two categories of social context models stance-based and propagation-based, utilize user viewpoints and interrelations in social media posts to infer news credibility. These approaches enrich fake news detection by incorporating social engagement perspectives [3]. Yet another study has addressed the challenge of online fake news detection, employing diverse features for analysis. Notable features include creator/user-based features, such as user profiling, credibility, and behaviour. Sentiment analysis and word-level indicators are two examples of linguistic and syntactic-based features that provide useful language cues. Sentiment scores, style terms, and even visual components like pictures and videos are the main focus of content-based features. Social context elements include temporal aspects, distribution patterns, and network-based traits. The evaluation findings show that machine learning algorithms can achieve up to 91% accuracy, which is a promising rate of accuracy. Notably, the efficacy of detection is improved by integrating language and network-based analysis. While Shu, Wang, and Liu (2019b) emphasise the triangular link among publishers, news pieces, and users as vital for efficient fake news detection, Shao et al. (2016) emphasise the necessity of fact-checking content in the fight against misinformation[4].
In another study, the Naïve Bayes classifier was used to present a simple technique for identifying bogus news. The concept was put into practice as a software solution and thoroughly evaluated using a dataset of Facebook news posts. Despite its intrinsic simplicity, the model demonstrated an impressive classification accuracy on the test set of around 74%. The paper outlines some ways to improve these considering everything, the results indicate the potential that artificial intelligence techniques can successfully tackle the problem of identifying false news, which will facilitate future advancements in this area [5].
While there is a little drop in classification accuracy specifically for fake news, the accuracy for both real and false news stories stays similar. This disparity might be attributed to the imbalance in the dataset, as only 4.9% of it had inaccurate information. However, the research highlights the significant finding that even a comparatively simple AI algorithm, like the naive Bayes classifier, has the potential to tackle the crucial issue of categorising false information. These findings highlight the potential effectiveness of AI methods in effectively addressing this important issue.
An additional research project delves further into a variety of machine learning models, including the very effective Naive Bayes models. Additionally, this study incorporates feature extraction methods like TF-IDF. This classifier finds uses in sentiment analysis, spam filtering, text classification, realtime prediction, and recommendation systems. It also demonstrates efficiency with low training data needs. To get appropriate accuracy results, the study also includes datasets, analytic measures, and a rule that combines various categorization approaches with text models. Further improvements may involve refining the rule and expanding the dataset for enhanced accuracy [6]. Using the Naive Bayes classifier, The technique takes advantage of straightforward and well-chosen features from the post and title to achieve an 80% accuracy rate.
This paper addresses the challenge of assessing and correcting inaccurate content, or "fake news," on social media, particularly Twitter. It introduces an automated method for fake news detection, leveraging two Twitter datasets that focus on credibility: CREDBANK and PHEME. The models perform better than those relying on journalist evaluations and a combined dataset because they were trained against crowdsourced labour. All three datasets are publicly available. Feature analysis identifies predictive elements for accuracy assessments, consistently aligning with prior work [7]. Recursive feature elimination was applied to PHEME and CREDBANK models, resulting in notably smaller feature sets. The best combination of seven characteristics for PHEME produced an ROCAUC score of 0.7407 and accurately detected 66.93% of possible false threads. With 12 characteristics, the most informative set from CREDBANK achieved a ROC-AUC score of 0.7184, accurately identifying 70.28% of possible false threads. Remarkably, just three characteristics were common to the journalist and crowdsourced worker models, which is in line with the challenge of spotting fraudulent tweets. While the models show marginal increases in accuracy compared to prior work, they consistently outperform previous results.
In yet another breakthrough research a systematic mapping approach was revealed that the most popular algorithms for detecting fake news are Similarity Algorithm (11.43%), Naive-Bayes (17.14%), and LSTM (17.14%). However, there remains a lack of controlled experiments with big data, emphasizing the urgency for effective solutions, particularly in addressing national security concerns like the COVID-19 pandemic [8]. This study conducts a systematic mapping of Intelligent computing methods for spotting fake news in large amounts of data, revealing 17.14% of Long Short-Term Memory and naïve Bayes (11.43 per cent). are the most employed algorithms. Most papers lack rigorous validation, with 69% utilizing case studies. The U.S. leads in publications (29%), and research in this domain surged in 2018, constituting 17 out of 35 articles. While 71% of studies were published in conferences, the analysis underscores a need for more replication and controlled experiments in the context of voluminous data, signalling the potential for further exploration in this evolving field of national security. In another research, a meta-analysis was conducted to systematically evaluate and compare various artificial intelligence (AI)-based strategies to identify false information and fake news. Utilizing cutting-edge natural language processing (NLP) techniques, the study employs a 5 × 2 cross-validation methodology across benchmark datasets. The formal benchmarking aims to provide a valuable resource for both the research community and practitioners, including those in fact-checking, homeland security, and press organisations that routinely battle false information. This work extends the authors' previous systematic analysis of fake news detection methods and their own ML/AI-based techniques [9].
Authors have explored the incorporation of sentiment analysis, a text analytics component, in fake news detection methods. It delves into the various applications, discusses key aspects, and highlights future requirements such as handling multimedia aspects, explainability, bias mitigation, and multilingualism to increase the efficacy of these detection techniques. Interest in automated detection has increased due to the spread of false information, which is largely due to social media. Sentiment analysis is useful in recognising strong feelings in news articles and user comments. As the discipline matures, it will have to deal with issues like multilingualism and multimedia content, identifying subtle manipulations or algorithmically generated fake news, and guaranteeing justice, accountability, and transparency in systems [10]. In another study, a detection framework leverages a Transformer architecture, utilizing both news content and social contexts. Overcoming challenges of early detection and limited labelled data, our model incorporates features to enhance classification accuracy. Experimental results on realworld data demonstrate superior early detection accuracy compared to baselines, showcasing the effectiveness of our approach. The model exhibits an accuracy of 74.89%, with a precision of 72.40%, indicating a few false positives but a high rate of correctly predicted true positives.
A recall value of 77.68% indicates fewer false negatives, an essential statistic for identifying false news. With an F1score of 74.95%, the experiment was performed quite well overall [11].
In a recent research study, false news causes were investigated using established techniques for identifying them in textual formats. The proposed tripartite methodology offers a dependable means of identifying fraudulent content on social media by combining Semantic Analysis, Naive Bayes classifiers, and Support Vector Machines [12]. This comprehensive strategy tackles the intricacies of social media detection. By including semantic analysis, the already successful combination of Naïve Bayes with SVM in intrusion detection systems is significantly improved, hence reducing the assumption of Naïve Bayes' independence. The suggested approach presents a potential improvement in identifying misleading content in the rapidly expanding field of social media, but it still needs to be empirically tested. By promoting a culture of critical thinking in the consumption of social media content, it becomes imperative to emphasise the need for precise identification to stop misinformation from spreading.
III. EXISTING TECHNIQUES
A. API Based Techniques
- Python API
- NLTK API- NLTK is a library built with Python for natural language processing (NLP) that provides a variety of customizable tools and resources for analysing and manipulating human language data.
- NetworkX API- NetworkX is a Python module that can be used to create, analyse, and visualize complex networks. It provides a user-friendly interface to investigate intricate linkages and patterns within networks, making it valuable for scholars, scientists, and developers.
- Machine Learning API-
- IBM Watson Natural Language Understanding- Text analysis and the identification of false news can both benefit from the sentiment analysis, entity recognition, and emotional analysis tools provided by this API.
- Google Cloud Natural Language API- NLP functions including entity identification, sentiment analysis, and content classification are offered by the Google Cloud Natural Language API. Deep Learning API-
- TensorFlow Serving- TensorFlow models can be deployed and served via TensorFlow Serving, allowing trained models to be exposed as API endpoints for inference in production environments.
- Hugging Face Transformers- A library and framework for exchanging and utilizing pre-trained models in NLP applications is provided by Hugging Face Transformers. (b) Java API-
- JAI (Java Advanced Imaging) - JAI is a Java library extension that provides APIs for image processing, including filtering, transformation, and handling of large images. It is a valuable resource for developers working with graphics and multimedia.
- JSAI(Java Speech API) - Java programmers can include speech synthesis and recognition in their apps using a standardized interface, creating voice-activated and interactive software.
2. R Language API
- Plumber- Plumber simplifies the process of creating and implementing R models or functions into RESTful web services. It is an R package that converts R code into web APIs.
- Shiny- Shiny, a non-standard API, helps R developers create interactive web apps and dashboards that can be shared via web browsers.
B. Visualization Techniques
- Gephi: Gephi is an effective tool for visualising and exploring networks. Its userfriendly interface and rich feature set make network analysis and exploration easy. Researchers, analysts, and data enthusiasts can create visually engaging stories and gain insights from complex network architectures.
- Tableau: Tableau is a powerful platform that helps convert raw data into visually engaging stories. Its intuitive interface and strong analytics features make it a versatile tool that transcends boundaries. Tableau provides real-time insights and interactive dashboards, revolutionizing the field of data exploration.
- Cytoscape: Cytoscape is a multifunctional tool for network visualization and analysis. It is ideal for building, investigating, and evaluating intricate networks, such as social networks and biological pathways. With its user-friendly interface and comprehensive feature set, Cytoscape is a valuable platform for researchers and developers alike.
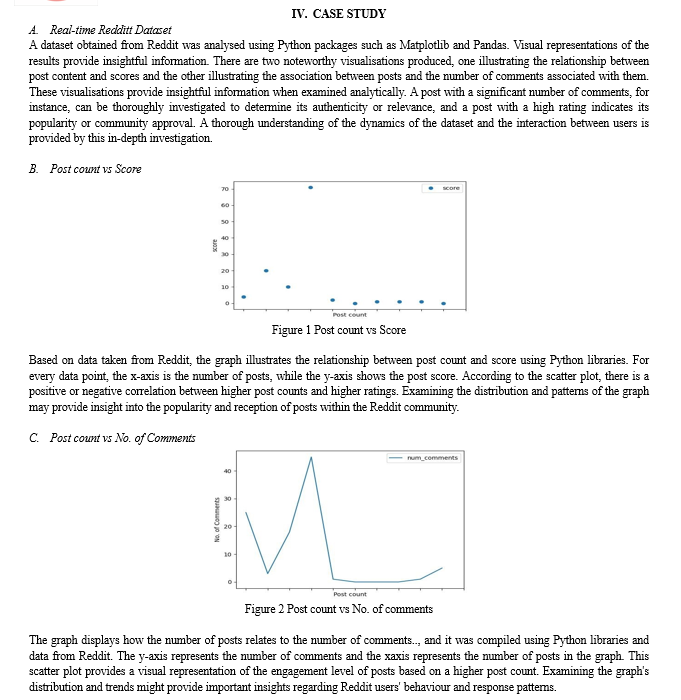
Conclusion
Researchers are actively engaged in studies to discover more accurate approaches for identifying false information in the context of social media, which is susceptible to false information on a large scale. Consequently, this research may be used to assist others in discovering which combination of methods is most effective in spotting false information on social media. To identify false information, we must have some method of detecting the news or be aware of the fact that not all that we read on social media infrastructure are real. As a result, we must always use critical thinking skills. Upon examining the scholarly works of multiple researchers, we discovered methods for categorising publications as authentic or fraudulent. The methods include the Support Vector Machine model (SVM), the Naive Bayes classifier, the Similarity algorithm, the Count and Tiff vectorizers, the passive-aggressive classifier algorithm, and Long and Short-Term Memory. Utilizing the Reddit API, we acquired a realtime dataset from the dynamic and diverse community on Reddit. This dataset was an invaluable tool for our investigation. We used a variety of graph visualisations to improve the data\'s readability and accessibility, providing a thorough and illuminating depiction of the most important patterns and trends. In addition to gaining a better grasp of the complex dynamics inside the dataset, our goal in presenting the data through these visualisations was to give other researchers a more succinct and useful synopsis. Within the Reddit community, the visualisations proved to be an effective tool for clarifying intricate relationships, patterns, and user behaviours. This visual tool is essential to making the topic\'s inquiry more approachable. In summary, researchers are actively investigating accurate ways of identifying misleading content in social media by utilising techniques like Naive Bayes and Support Vector Machines (SVM), among others. A real-time dataset was examined using the Reddit API. Perceptive visualisations were used to improve accessibility and reveal complex patterns.
References
[1] Khanam, Z., Alwasel, B. N., Sirafi, H., & Rashid, M. (2021, March). Fake news detection using machine learning approaches. In IOP conference series: materials science and engineering (Vol. 1099, No. 1, p. 012040). IOP Publishing. [2] Jain, A., Shakya, A., Khatter, H., & Gupta, A. K. (2019, September). A smart system for fake news detection using machine learning. In 2019 International Conference on Issues and Challenges in Intelligent Computing Techniques (ICICT) (Vol. 1, pp. 1-4). IEEE. [3] Shu, K., Sliva, A., Wang, S., Tang, J., & Liu, H. (2017). Fake news detection on social media: A data mining perspective. ACM SIGKDD explorations newsletter, 19(1), 22-36. [4] Zhang, X., & Ghorbani, A. A. (2020). An overview of online fake news: Characterization, detection, and discussion. Information Processing & Management, 57(2), 102025. [5] Granik, M., & Mesyura, V. (2017, May). Fake news detection using naive Bayes classifier. In 2017 IEEE first Ukraine conference on Electrical and Computer Engineering (UKRCON) (pp. 900-903). IEEE. [6] Yerlekar, P. A., & Yerlekar, A. (2021). Fake News Detection using Machine Learning Approach Multinomial Naive Bayes Classifier. International Journal for Research in Applied Science and Engineering Technology, 1304-1308. [7] C. Buntain and J. Golbeck, \"Automatically Identifying Fake News in Popular Twitter Threads,\" 2017 IEEE International Conference on Smart Cloud (SmartCloud), New York, NY, USA, 2017, pp. 208-215, doi: 10.1109/SmartCloud.2017.40. [8] Meneses Silva, C. V., Silva Fontes, R., & Colaço Júnior, M. (2021). Intelligent fake news detection: a systematic mapping. Journal of Applied Security Research, 16(2), 168-189. [9] Kozik, R., Pawlicka, A., Pawlicki, M., Chora?, M., Mazurczyk, W., & Cabaj, K. (2023). A metaanalysis of state-of-the-art automated fake news detection methods. IEEE Transactions on Computational Social Systems. [10] Alonso, M. A., Vilares, D., Gómez-Rodríguez, C., & Vilares, J. (2021). Sentiment analysis for fake news detection. Electronics, 10(11), 1348. [11] Raza, S., & Ding, C. (2022). Fake news detection based on news content and social contexts: a transformer-based approach. International Journal of Data Science and Analytics, 13(4), 335-362. [12] Stahl, K. (2018). Fake news detection in social media. California State University Stanislaus, 6, 4-15.
Copyright
Copyright © 2024 Garima Agarwal, Ayush Kumar, Diwakar Chauhan, Neha Tyagi. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET62129
Publish Date : 2024-05-14
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online