

Ijraset Journal For Research in Applied Science and Engineering Technology
Fake News Detection Using Machine Learning
Authors: Rodda Madhunitha, N. Naveen Kumar
DOI Link: https://doi.org/10.22214/ijraset.2024.63570
Certificate: View Certificate
Abstract
The pervasive spread of misinformation in today\'s digital environment presents a daunting problem, influencing public opinion and possibly causing unfavorable social consequences. This paper conducts a thorough investigation into the effectiveness includes a broad variety of false information in text, images, and video formats. Our study carefully assesses SVM, random forest, MLP, and naive Bayes classifiers using a large and painstakingly selected dataset. We provide a classifier of voting to improve accuracy and consistency by integrating the forecasts from these several models. Voting Classifier\'s outstanding performance, attaining a perfect accuracy rate and highlighting the ensemble approach\'s inherent robustness. The research emphasizes the vital ensemble methods\' key part in strengthening the foundation the identification of bogus news systems and providing a strong barrier against the unrelenting propagation of fake information.
Introduction
I. INTRODUCTION
The digital era phony news source isa big problem because it may distort popular sentiment and even cause social unrest. After social media's advent and online news sources, false information has spread widely, leaving the public confused and distrustful. This study attempts to assess how well machine learning algorithms can detect deceptive information across several mediums, such as words, images, and recordings, in response to this urgent issue. By enabling automated detection of forged news across a variety of media types, machine learning approaches provide encouraging prospects for addressing this problem. Machine learning replicas can be trained to be able to recognize trends suggestive of disinformation, such as deceptive graphics, sensationalist rhetoric, or edited video footage, by utilizing large datasets and sophisticated algorithms. These algorithms can analyze video sequences for anomalies or disparities, assess the authenticity of images through pixel-by-pixel examination, and search textual content for linguistic markers.
This research investigates many machines learning methods, such as logistic regression, SVM, random forest, MLP, and naive Bayes, for analyzing false news. It also looks into how effective an ensemble method using Voting Classifiers is. Improving the accuracy and dependability of misinformation identification across many modalities is the goal.
In this research, we offer an original method and resource to determine inaccurate information that use:
- Text Preprocessing: consisted of removing special characters and stop words of the text.
- Encoding: Eliminate stop words, punctuation, and other elements from the text data.
- Extraction: To differentiate between fabricated and authentic news, it entails recognizing multiple clues.
- Voting Classifier: Integrate the classifiers to create a voting classifier, train it, and assess its output.
II. RELATED WORK
Fake news aims to spoof real news while simultaneously distorting the facts using a variety of linguistic techniques. Its content is quite broad regarding topics, styles, and media channels. Fake news has been established, for example to back non-factual claims using accurate information presented in the wrong context [1]. In contrasting two distinct feature extraction methods and six distinct classification methods, the authors of this research present a false news detection model that applies machine learning and n-gram analysis techniques. Considering the outcomes of the trials, the so-called features extraction method yields the best results [2]. Toward train the suggested system, we additionally suggest providing an array of real and fraudulent news. Results obtained demonstrate how effective the system is. In this study, we describe a machine learning-based method for identifying false news. [3]. The reason behind this isthe rise and subsequent expansion of the use of social media platforms has the problem of false news more severe, which is why companies like Facebook are involved in it [4]. Specifically, the majority of these websites also have a sharing feature encouraging visitors to spread the word about the content of the page.
Websites for social networking make it possible for content to be shared effectively and quickly, which gives users the ability to quickly spread false information. Following Cambridge millions of people were compromised by the data leak at Analytica accounts, Facebook and other major players pledged to take further action to halt the spread of false information [5]. There could be very detrimental effects on people and society from the widespread dissemination of fake news. Consequently, the study of identifying erroneous data on social media has recently gained a lot of attention [6]. In this research, we provide a framework based on several machine learning approaches to address a range of issues, such as high processing times to handle thousands of tweets in a second, time lag (Bootmaker), and accuracy lack. First, 400,000 tweets have been gathered from HSpam14[7]. According to their article, deception detection utilizing the labelled benchmark data set "LIAR" is clearly more effective at identifying bogus postings and news. Utilizing corpora for stance classification, opinion mining, rumour detection, and political natural language processing research was advocated by the authors [8]. The automatic false news inference model known as Fake Detector is discussed by the paper's authors. To learn the representations of news items, it creates a deep diffusive network model based on textual classification [9]. Our goal is to find the most successful categorization scheme news by utilizing several machine learning algorithms. We have employed fictitious and authentic news datasets from several sources [10]. Training found that over the last three months of the US election, fake election news items from popular news sites including the New York Times, Washington Post, NBC News, Huffington Post, and other publications generated greater engagement on Facebook than they did on other platforms [11]. For a great deal of individuals worldwide, social media has evolved into the primary news source. Modern Social networking sites differ greatly from one another. Structurally from traditional news outlets like newspapers. Social media sites do not perform actions that broad news sourcesdid, such as third-party filtering, fact- checking, as well as editorial discretion [12]. As a result, reaching as many users as possible well-known real news platform has become incredibly simple either for people or groups without a prior track record [13]. Automated fact-checking focus on one or more of the three overlapping objectives: to find wrong and questionable claims propagating on online social media; to verify and identify the claims; and to deliver the corrections across social media. With automatic capability, fact-checkers can respond quickly to the misinformation [14]. In addition, social platforms also promote ‘Echo Chamber Effect’. This happened as a result of naive social media users follow famous public influencers such as well- known celebrities and subsequently get impacted by the words and information conveyed bythese influencers owing to the blind admiration they have for these influencers. As an illustration, users who are not biased receives less attention compared to partisan users [15]. An architecture for recurrent neural networks using LSTM called EmoCred, which investigates the function of emotional signals in credibility assessment, was introduced in this research. EmoCred uses a vector of emotional signals in addition to word embeddings produced from fictitious sentences as features [16].
III. PROPOSED SYSTEM
The system establishes voting classifier tackle on a false news dataset. The The information is then classified as true or deceptive using the model.
A. Architecture of the Proposed System
An image, text, and video collection containing bogus news is fed into the suggested system. Afterwards, it converts including them into a dataset of features suitable for the learning stage. This change is known as preprocessing, and it includes a number of tasks like encoding, filtering, and cleansing. Two portions are separated for training and testing, respectively. The instruction package constructs a model of decision-making that is used with the dataset under test by utilizing the voting classifier method as well as training data. The training process will come to a conclusion if the approved model and employed. If not, the learning algorithm's settings are adjusted to raise accuracy. Figure 1 illustrates the suggested system
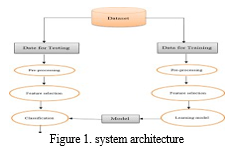
B. Preprocessing
Whether the counterfeit news is in the kind of text, imagery, or videos, preprocessing is an essential while t he procedure. To prepare the raw data in a way that is capable of utilized in the process of extracting features and model training is the aim.
- Textual Information
Write a news article that incorporates the author's words and performs by the following operations:
a. Lowercasing: Convert all text to lowercase to maintain consistency.
b. Removing Punctuation and Special Characters: Strip out punctuation, special characters, and numbers.
c. Removing Stop Words: Eliminate common words that do not contribute much to the meaning (e.g., 'the', 'and').
d. Tokenization: Split the text into separate words or tokens.
e. Stemming and Lemmatization: Reduce words to their base or root form.
In this feature extraction can be done by using techniques like TF-IDF. For word e4mbeddings like BERT, Word2vec can be used.
2. Image Processing Data
The pixel values and associated information that comprise a picture are referred to as data in image processing. In light of the particular application and the kind of image being processed, this data can be saved and altered among a range of formats and structures. It contains two steps:
a. Image Loading and Resizing
- Resize Images: Standardize the extent of images for uniformity.
- Normalization: Normalize pixel values to a range of 0-1
b. Data Augmentation
Techniques: Apply transformations like rotation, flipping, zooming, and shifting to augment the dataset. In image processing, the data can be analyzed from image by converting into text format.
IV. CLASSIFIERS
- Logistic Regression: logistic regression predicts the result, an occurrence, or an observation for the purpose of complete binary classification problems. The output is binary, or dichotomous, with two possible outcomes: true or false, 0/1, or yes/no.
- SVM: that determines boundaries between data points based on predefined classes, labels, or outputs. It uses supervised learning models to solve complex problems related to classification, regression, and outlier detection.
- Random Forest: Leo Breimanand Adele Cutler created the Forest, which aggregates the output of several decision trees to produce a single outcome. Its versatility and ease of use, combined with its ability to handle both regression and classification problems, have driven its popularity.
- MLP: Another multi-layer artificial neural network approach is the multi-layer perceptron (MLP). While clearly linear issues is able to handle in a single perceptron, non-linear this method.
- NAIVE BAYES: It’s a fundamental learning method that applies the Bayes rule and makes the strong assumption that, given the class, the attributes are conditionally independent. Even though the independence assumption is frequently broken in real-world scenarios, naïve Bayes frequently achieves competitive classification accuracy. P(A|B) = P(B|A) P(A) P(B)
- Voting Classifier: The Voting Classifier algorithm (RF + SVC + GNB + LR) integrates predictions from several base classifiers, such as Gaussian Naive Bayes (GNB), Random Forest (RF), Support Vector Classifier (SVC), and Logistic Regression (LR). The Voting Classifier generates a final result by aggregating the individual predictions from each base classifier, either by weighted average (soft voting) or by majority vote (hard voting). The aim of the Voting Classifier is to increase overall precision and resilience predictions by leveraging the advantages of several classifiers.
A. Implementing a Voting Classifier for Fake News Detection
Data preprocessing, model selection, ensemble model training, and performance evaluation on a test dataset are usually involved in the implementation of a voting classifier for fake news identification. The voting classifier can efficiently categorize news articles by adjusting each model individually and streamlining the voting process.
Advantages
- Improved Accuracy
- Robustness Against Bias
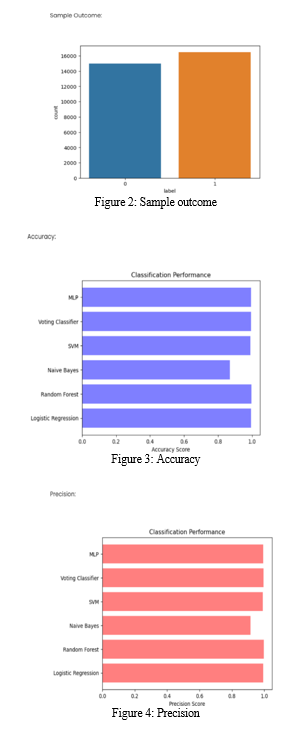
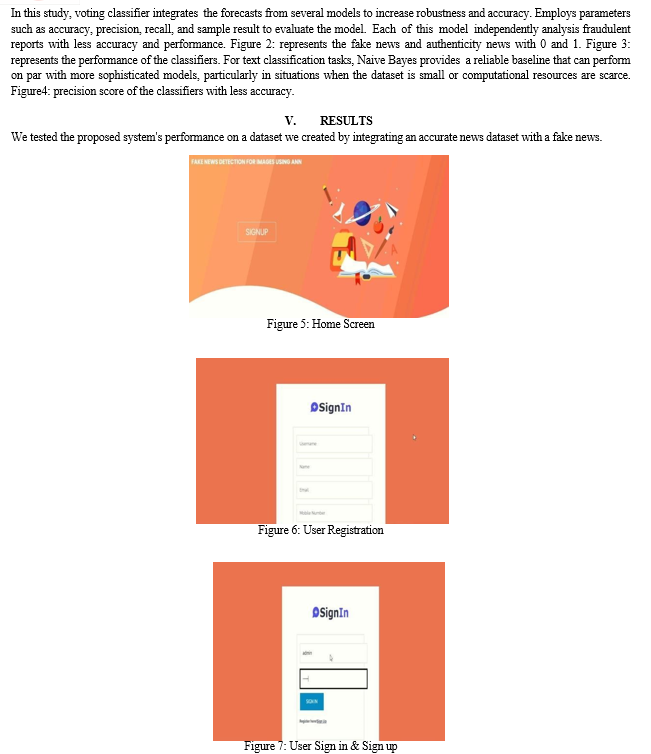

VI. FUTURE ENCHANCEMENT
Voting classifiers will be integrated with more complex algorithms as machine learning methodologies continue to progress, which will be vital for future attempts to identify bogus news. The spaceof false news identification is well-positioned to make substantial progress in countering disinformation and maintaining the trustworthiness of news sources by tackling the obstacles and constraints of existing methods.
Conclusion
Finally, a strong and genuine strategy for detect phony news is offered by the incorporation of a voting classifier into machine learning. The voter classifier improves the robustness, accuracy, and dependability of its identifying bogus news by utilizing the combined intelligence of several models. Voting classifiers and other ensemble learning approaches have the ability to enhance the identification and mitigation of phony information in the digital sphere given that technology keeps developing.
References
[1] Koustav Rudra and Animesh Mukherjee\'s \"Data mining approach for detecting fake news on social media\". 2018 saw publication in the Big Data Journal. [2] Animesh Mukherjee and Sourav Bardhan\'s \"Automatic Machine Learning-Based Fake News Detection Techniques\". appeared in the 2017 IEEE International Conference on Data Mining Proceedings. [3] P. Ravi Kumar and M.Tech., \" Identifying False News with Machine Learning Techniques\". The International Journal of Computer Science Advanced Research Science published this research in 2018. [4] Alexandros Ntoulas, Efthymios Kouloumpis, and Vasileios Lampos, \"Combining top-down and bottom-up approaches for fake news detection\". Originally published in 2017 in the Proceedings At the 26th World Wide Web International Conference Companion. [5] Shuaiqiang Wang, Yiqun Liu, and Shuang Wang\'s \" Identifying False News on social media: A Survey\". Printed in the 2020 issue of ACM Computational Intelligence Magazine. [6] \"Identifying Misinformation on Social Networks Platforms\" Monther Aldwairi, Ali Alwahedi, Zayed University\'s College of Technological Innovation, Abu Dhabi 144534, United Arab Emirates accessible via the internet on November 5, 2018. [7] A stylometric investigation on hyperpartisan and fake news was conducted by M. Potthast, J. Kiesel, K. Reinartz, J. Bevendorff, and B. Stein in CoRR, vol. abs/1702.05638, 2017. [8] \"A framework for real-time spam detection in Twitter,\" by H. Gupta, M. S. Jamal, S. Madi shetty, and M. S. Desarkar, 10th World Congress onCommunication Systems & Networks (COMSNETS), Bengaluru, 2018, pp. 380-383 [9] KaiShu, Amy Sliva, Huan, Jiliang Tang, and Suhang Wang Liu, \"Fake News Detection on Social Media,\" arXiv:1708.01967v3 [cs.SI], published on September 3, 2017. [10] Published: \"An Automatic Recognizing Fake News System Techniques,\" by Shagun Sharma, Kalpna Guleria, IEEE Archana Saini, Nikitha, and Syed Ishfaq Manzoor. [11] Gentzkow, M. and Allcott, H. (2018). Social media and fake news during the 2016 presidential election. [Virtual] NBER. At http://www.nber.org/papers/w23089, it is accessible. [12] Ahmed H. N-gram analysis combined with semantic similarity, identifying spam and phony opinions news. [13] \"Identifying Fake News and Fake Users on Twitter,\" C. S. Atodiresei, A. Tanaselea, and A. Iftene, Procedia Computer Science, Aug. 28, 2018. [14] Fake News Identification on Twitter with Hybrid CNN and RNN Models, O. Ajao, D. Bhowmik, and S. Zargari, \"(PDF) Fake News Identification on Twitter with Hybrid CNN...,\" July 2018. [15] Florian Sauvageau. Nouvelles fausses, nouvelles facettes, nouvelles difficultés. How do we assess the information\'s value in democratic societies? Laval University Press, 2018. [16] Alexander J. Smola and Bernhard Scholkopf. Using kernels for learning: regularization, optimization, support vector machines, and more. The 2018 series on Adaptive Computation and Machine Learning.
Copyright
Copyright © 2024 Rodda Madhunitha, N. Naveen Kumar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET63570
Publish Date : 2024-07-07
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online