

Ijraset Journal For Research in Applied Science and Engineering Technology
Federated Learning for Privacy-Preserving Machine Learning: Decentralized Model Training with Enhanced Data Security
Authors: Daryn Monteiro, Ishaan Mavinkurve, Parth Kambli, Prof. Sakshi Surve
DOI Link: https://doi.org/10.22214/ijraset.2024.65062
Certificate: View Certificate
Abstract
Artificial Intelligence has found widespread use across various industries, from optimizing manufacturing workflows to diagnosing health conditions. However, the large volumes of data required to train AI models raise privacy concerns, especially when stored in centralized databases vulnerable to leaks. Federated Learning solves this problem by training models collaboratively by avoiding centralization of the sensitive data, preserving privacy while allowing decentralized models to be exported to edge devices. This paper explores Federated Learning, focusing on its technical aspects, algorithms, and decentralized architecture. By keeping raw data localized, Federated Learning enables global models while safeguarding individual privacy, fostering collaboration across sectors like healthcare, finance, and IoT. It also addresses challenges such as privacy vulnerabilities and model aggregation across devices, proposing solutions to strengthen Federated Learning\'s effectiveness. Ultimately, this study highlights Federated Learning\'s pivotal role in the future of AI, where privacy preservation and collaboration are key. By balancing model performance with data privacy, Federated Learning stands as a promising framework for responsible and inclusive AI development.
Introduction
I. INTRODUCTION
In the era of big data, machine learning (ML) is essential for uncovering insights and driving innovation across various fields, including healthcare, finance, and autonomous systems. Traditional ML methods typically involve centralizing data into a single repository for training models, which poses substantial privacy and security concerns, leading to risks of data breaches and challenges in meeting regulatory compliance. Federated Learning (FL), the concept that Google introduced in 2017, offers decentralized solution towards these issues by keeping data on local devices while still enabling collaborative model training. FL represents a shift from the traditional centralized data approach to a decentralized model training process, thereby reducing privacy risks and complying with the regulations towards protection of data imposed by HIPAA and GDPR. Originating from concepts such as distributed learning and multi-party computation, FL was first demonstrated by Google to improve predictive text models on Android devices. In this approach, each device locally trains the model and only the updates in training are sent to the central server which then aggregates these results with the previous ones, enhancing the global model without centralizing sensitive user data. It enhances privacy by ensuring that the bulk of the raw data remains on local devices. It also incorporates techniques such as secure aggregation and differential privacy to provide further protection. Secure aggregation encrypts model updates during transmission, while differential privacy introduces noise to these updates, making it difficult to identify individual data points. [1]
II. BACKGROUND
FL has shown significant benefits in the healthcare sector. In 2020, a consortium of medical institutions used FL to develop predictive models for patient outcomes while keeping health records confidential and adhering to regulatory requirements. This collaboration improved model accuracy and facilitated cooperative research in personalized medicine. In the financial sector, FL is used to strengthen fraud detection and risk management. Financial institutions often face challenges in sharing data due to competitive pressures and regulatory constraints. FL allows these institutions to collaboratively train models on transaction by maintaining the privacy of the customers. A 2019 initiative by major banks successfully used FL to enhance fraud detection, utilizing diverse datasets while maintaining data confidentiality. However, FL also presents challenges, such as communication overhead, system heterogeneity, and the robustness of model updates [2].
Communication overhead, resulting from frequent model update exchanges, can be mitigated by techniques such as model compression and sparse updates. System heterogeneity, which can affect efficiency, is addressed through adaptive protocols and resource-aware scheduling. The robustness of model updates is another concern, with risks such as malicious updates being mitigated by methods like anomaly detection, robust aggregation, and Byzantine fault tolerance. Research is also ongoing to ensure fairness and equity in the learning process. In summary, Federated Learning is a major step forward in privacy-preserving machine learning. Through decentralizing model training while protecting data privacy, FL offers a powerful solution to the challenges associated with traditional centralized approaches [3]. With its applications in healthcare, finance, and beyond, FL is poised to be an important concept in the future of responsible and inclusive AI.
III. METHODOLOGIES
A. Local Model Training
Explained below is how local model training works in federated learning:
Global Model Initialization: A central server sets up the global model and shares it with all participating clients.
Local Model Training: Each client trains the model using its own local data, following these steps:
Data Preparation: The client pre-processes its local data, which includes tasks such as normalization, augmentation, and splitting into training and validation sets.
Model Training: The model is trained by the client on its local dataset for a certain number of epochs. The steps like forward passes, loss computation, and backpropagation are involved here to update the model's weights.
Local Model Update: After training, the client obtains a locally updated version of the model.
Local Model Upload: Each client sends only the parameters of the updated model (weights and biases) to the central server and not the raw data.
Global Model Aggregation: Now, it is the responsibility of the central server to combine the updates received by all the clients to create a new updated global model. Common aggregation methods include Federated Averaging (FedAvg), in which, the averaging of the updates is done according to the number of samples each client contributes.
Global Model Distribution: The central server distributes the updated global model back to all clients, and this cycle continues for multiple times until the model converges or achieves the required performance.
1) The process of training a local model on every client is mentioned below:
Receive Global Model: Each client obtains the initial or updated global model from the central server.
Data Segmentation: Two sets out of the local dataset are formed for training and validation purpose in the ratio 80-20.
Model Training: The model is trained using local data. This involves:
Forward Pass: Input data is sent through the model for computing the predictions
Loss Calculation: A loss function is used to compute the difference between the predicted and actual values.
Backward Pass: Gradients are computed through backpropagation.
Weight Update: Model weights are updated using an optimization algorithm like SGD or Adam.
Evaluation: The locally trained model is evaluated on the local validation set to monitor performance and ensure it is learning effectively.
Send Updates: The locally trained model parameters (or the differences from the initial parameters) are sent back to the central server.
2) Benefits of Local Model Training in Federated Learning:
Data Privacy and Security: Raw data remains on the client’s device, reducing breach risks and aiding compliance with regulations like GDPR and CCPA.
Reduced Communication Overhead: Each client sends only updates minimizing data transfer and lowering bandwidth usage.
Scalability: The system scales across many clients with large datasets without needing a central data repository, distributing computational load across client devices.
Improved Model Generalization: Training on diverse local datasets enhances model robustness and reduces bias towards any single data source.
These benefits make local model training in federated learning a powerful approach for developing machine learning models in a decentralized, privacy-preserving, and efficient manner.
B. Model Aggregation
Rather than sending raw data to a centralized server, each client develops a local model using its own data and shares only the model updates (e.g. changed weights of the model, gradients) with the server. The server then compiles these updates to form a global model, that is sent back to the clients for additional training. This process repeats until the model reaches convergence. Model aggregation is a very important step in FL, as it combines the locally trained models into a single, more robust global model. The aggregation process must be designed to handle the heterogeneity of data and computational resources across clients, ensure privacy and security, and maintain the efficiency and effectiveness of the learning process. The next part of the paper provides the details of various aspects and methods of model aggregation in federated learning.
- Weight Initialization: The process starts with the initialization of weights. The initial weights of the model are determined and sent to the parameter server, which holds the master model.
- Parameter Server with Master Model: The parameter server maintains the global model, which is the central version of the model being trained. The server sends the initial model weights to all participating clients.
- Clients (Local Training): Each client receives the model from the parameter server and performs local training on its own dataset for a certain number of local iterations or epochs. During local training, clients update the model weights based on their locally available data.
- Local Epochs: Each client iterates over its local data for several epochs, improving the model weights locally without sharing its data with the server or other clients.
- Client Updates: Once the local training is completed, clients return their updated weights back to the parameter server.
- Global Epoch: The parameter server collects the weights from all clients. It averages these weights to create a new set of global weights, which is the updated global model. This process of collecting weights, averaging them, and updating the model is referred to as a global epoch.
- Average Weights and Update Model: The weights received from all clients are averaged by the server and it then updates the master model accordingly.
- Cycle Repeats: The global model, now updated, is sent back to the clients, and this process repeats for several global epochs until the model converges.
a) Aggregation Methods
- Federated Averaging (FedAvg): FedAvg is a very commonly used aggregation method in FL. It works by averaging the weights or gradients of the models trained locally on each client. The global model update can be mathematically represented as:
Where w(t+1) is the global model weights at time t+1,N is the number of clients, and wit+1 are the model weights from client i. This method assumes that all clients contribute equally to the global model.
- Weighted Aggregation: To address the inequality in contributions, weighted aggregation assigns varying weights to client updates, considering parameters such as the size of the local dataset or the client’s reliability. The weighted averaging formula is:
Here ni represents the number of data points at client i and ∑Nj=1 nj denotes the total number of data points across all clients. This method gives more influence to clients with superior datasets, aligning the global model more closely with the majority data distribution.
- Adaptive Aggregation: Adaptive aggregation dynamically adjusts the aggregation strategy based on the observed performance or behaviour of the clients. Techniques like FedProx, which introduces a proximal term to handle the heterogeneity of clients, and other adaptive methods that weigh client updates based on recent performance metrics, fall under this category.
C. Privacy Preserving Techniques
Differential Privacy: This is an algorithm to see to it that output from a data analysis algorithm is independent of any single individual data. Mathematically, an algorithm α will be considered differentially private if for 2 datasets D1 and D2 such that they differ by only 1 element, for any possible subset S of the output, the probability that α produces an output in S is nearly the same for both datasets. It is stated as: P[α(D1)∈S]≤e?P[α(D2)∈S] ,where ? is a non-negative parameter that measures the extent of privacy loss. In a research paper titled “The Algorithmic Foundations of Differential Privacy” written by Aaron Roth, it is noted that differential privacy promises the outcome of a survey will remain the same whether a user participates in it or not. Hence, users have no reason to not participate.
1) Laplace Distribution:
Adding noise from a Laplace distribution into the function’s output helps protect individual data points.
Properties of the Laplace Distribution:
- Symmetric around the mean.
- Sharper peak and heavier tails as compared to the Gaussian distribution, allowing for higher probability of extreme values.
- Cantered around 0, meaning that the noise is unbiased.
- It’s scale can be adjusted based on the sensitivity of the query or desired privacy level.
- The Laplace distribution provides a standard for introducing noise into data. For a function f with sensitivity Δf, the Laplace mechanism output is: α(D) = f(D) + Lap(Δf/?), where Δf is the maximum change in f with a single data point change, and Lap(Δf/?) is the added noise.
2) Fitting differential privacy into Federated Learning:
Before sending updates from the local model to the global model, the individual device adds carefully calibrated noise to updates to ensure differential privacy. By adding this noise, individual contributions to the global server by each device become indistinguishable, protecting user privacy. The central server collects the noisy data. As it knows that the data is noisy and cannot be trusted blindly, it employs mechanisms that account for added noise to accurately aggregate the updates. [4]
- Model Performance: Ensuring that the added noise does not significantly degrade the global model’s performance is essential. Techniques such as adaptive noise scaling and differential privacy-aware optimization algorithms can help mitigate this issue
- Secure Multiparty Computation: Secure Multiparty Computation is another method of Privacy Preserving which is used in Federated Learning systems to further improve the efficiency of processing outputs. This concept was introduced to introduce a problem wherein multiple computers wanted to compute a function collaboratively while keeping their individual inputs private.
3) Protocols and Techniques:
- Secret Sharing: A Secret Sharing Scheme splits a secret into several pieces and distributes these pieces to various parties. Each party holds only a part of the secret, and to reconstruct the entire secret, collaboration among a sufficient number of parties is required. This is known as Shamir’s Secret Sharing Scheme. [5]
- Homomorphic Encryption: The method of Homomorphic Encryption enables computations to be performed on encrypted data without requiring decryption beforehand. Traditionally, data is decrypted before computation, but this exposes the secret data to the computing device. Homomorphic Encryption enables mathematical operations directly on ciphertext, such as addition and multiplication. When decrypted, the result matches what would be obtained from operations performed on the plaintext.
- Oblivious Transfer: This method is a protocol used in cryptography that allows a sender to send a message from a set to a receiver and the sender is completely not aware of which message was sent. Similarly, the receiver is unaware of whether the message received is complete and does not know which piece of information was transferred. [6]
D. Adaptive Learning
Adaptive learning is a progressive methodology that bolsters the efficiency and efficacy of model training by a significant amount. This technique involves selecting different devices adaptively based on their capabilities and constraints.
This type of a system becomes very beneficial in federated learning as it addresses the heterogeneous nature of devices involved, ensuring that training is both efficient and robust.
1) Key principles of adaptive learning:
- Computational resources: Adaptive learning accounts for the different devices participating in the federated learning. These devices will have different hardware and hence different processing powers. Adaptive learning algorithms will evaluate the computational power of each node. Devices with higher processing capabilities are assigned more complex tasks, while those with limited resources are given fairly simple tasks. By allocating tasks based on computational power, the overall training time is reduced, and resource utilization is optimized. This prevents overloading weaker devices and attains maximum throughput from powerful devices.
- Data quality: Adaptive learning scans through the data available on various machines. With the help of this scan, it can bifurcate devices on the basis of quality of data. The algorithms assess the quality of data available on each device. This includes factors like the amount of data, its relevance, and the presence of noise or outliers. Devices with high-quality, relevant data are prioritized in the training process. This guarantees that the model gains from the best available information, improving its accuracy and robustness.
- Privacy constraints: Adaptive learning respects the privacy of data on each machine. As different devices have different computing power, they will also have different privacy constraints. Adaptive learning accounts for the privacy constraints of each device. Machines that are stricter about data sharing are assigned tasks that require minimal data exposure or are given privacy-preserving transformations. The algorithms ensure that the participation of each device aligns with its privacy rules, maintaining user trust and legal compliance.
2) Implementation of Adaptive learning involves several steps:
- Resource Profiling: Continuously monitor and profile the computational resources of each device. This is done so that the load can be distributed accordingly to achieve efficiency.
- Data Quality Assessment: Regularly evaluate the quality and relevance of the data on each device. Some devices may have more valuable data than others. Hence bifurcation based on data is critical.
- Privacy Evaluation: Identify and respect the privacy constraints of each device. Some devices may be sensitive to data pooling. These constraints should be recognised.
- Dynamic Task Allocation: Develop algorithms capable of dynamically allocating tasks depending upon the real-time assessment of resources, data quality, and privacy rules.
3) Benefits of adaptive learning:
- Efficiency: by matching the tasks to the profiles of each machine, adaptive learning maximizes the use of available resources, reducing unnecessary loads and overall efficacy.
- Effectiveness: adaptive learning ensures that even the devices with limited data can contribute meaningfully. Hence leveraging this exceptional data from the best-suited devices improves the training outcomes, leading to a more generalized model.
- Scalability: the adaptive learning methodology allows federating learning to scale efficiently across a vast range of devices, from powerful servers to low-power IoT devices. Scalability is essential for real-world applications that involve different types of devices.
- Robustness: by considering privacy constraints, adaptive learning ensures robust participation without compromising data security. Dynamic selection also mitigates the impact of unreliable devices. Hence maintaining the integrity of the training process.
E. Security Measures
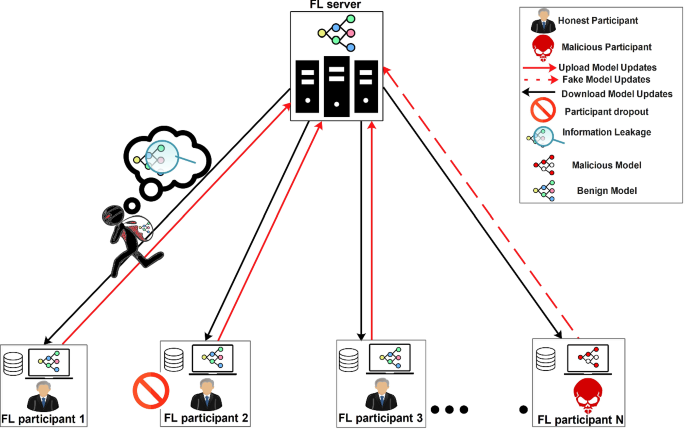
Fig. 1 Potential security risks and malicious behaviors within a federated learning system
In the digital transformation era, the security of machine learning models has become paramount, especially in decentralized systems like Federated Learning (FL). This section explores the necessity of robust security measures in FL systems to prevent attacks such as model poisoning, data injection, and Byzantine attacks. We discuss various techniques, including secure aggregation, cryptographic protocols, and anomaly detection, and demonstrate their effectiveness through a prototype implemented using Python.
1) FL systems face several security threats:
Model Poisoning: Malicious actors can corrupt the global model by introducing harmful updates during training.
Data Injection: Attackers can inject false data into the training process, skewing the model's performance.
Byzantine Attacks: Adversaries may send arbitrary or incorrect updates to disrupt the learning process.
2) Techniques that can be employed to secure FL systems:
Secure Aggregation: Secure aggregation techniques ensure that updates from individual model stay confidential throughout the process of aggregation. This prevents attackers from accessing sensitive information from individual updates.
Cryptographic Protocols: Cryptographic protocols, like homomorphic encryption and secure multi-party computation (SMPC), may improve privacy and security by allowing computations on encrypted data without decrypting it.
Anomaly Detection: Anomaly detection algorithms identify and mitigate suspicious updates that may indicate an ongoing attack. These algorithms help maintain the integrity of the global model. [7]
IV. FUTURE RESEARCH AND DEVELOPMENT
Though federated learning has shown significant promise, several areas warrant further exploration. Future research efforts might focus on enhancing model robustness against adversarial threats, as well as strengthening privacy measures, even in complex network environments. Integrating federated learning with advancing technologies like blockchain and differential privacy could further improve data security, creating a more resilient framework. Expanding its applications to emerging fields such as smart cities and energy management could reveal new possibilities. Additionally, improving communication efficiency and minimizing resource demands will be essential steps toward making federated learning more scalable and accessible across a wider range of fields.
Conclusion
The adoption of federated learning (FL) as a secure method for collective machine learning relies upon applying robust security measures. FL allows decentralized learning over multiple devices while maintaining user privacy and data confidentiality. However, this decentralized nature introduces unique security challenges, such as model poisoning, data injection, and Byzantine attacks. To address these challenges, various techniques and protocols have been developed to protect FL systems. Model aggregation guarantees individual updates in the model remain confidential during the assemblage process by encrypting updates, then securely aggregating them, preventing attackers from accessing sensitive details or tampering with the model. Cryptographic protocols, like homomorphic encryption and secure multi-party computation (SMPC), bolster the confidentiality and security of FL systems. Homomorphic encryption facilitates computations on encrypted data, safeguarding user privacy while deriving insights. SMPC allows multiple parties to collaboratively compute functions while ensuring that the inputs remain confidential, maintaining individual data security throughout the process. Anomaly detection algorithms are crucial for securing FL systems by identifying and mitigating suspicious updates indicative of attacks. These algorithms analyze individual device behavior and flag deviations from expected patterns, allowing proactive measures to maintain the global model\'s integrity. Moreover, combining secure aggregation, cryptographic protocols, and anomaly detection in FL mechanisms fosters collaborative research and innovation in machine learning. Researchers can train models on sensitive or proprietary data without giving up privacy, enabling new implementations in industries like healthcare and finance, where privacy of data is crucial. In conclusion, the privacy and security of FL data models are vital for their success. By implementing robust security measures, FL systems can protect user privacy, preserve data confidentiality, and maintain global model integrity.
References
[1] Bonawitz, K., Eichner, H., Grieskamp, W., Huba, D., Ingerman, A., Ivanov, V., ... & McMahan, H. B. (2019). Towards Federated Learning at Scale: System Design. Proceedings of the 2nd SysML Conference. [2] Kairouz, P., McMahan, H. B., Avent, B., Bellet, A., Bennis, M., Bhagoji, A. N., ... & Zhao, S. (2019). Advances and Open Problems in Federated Learning. [3] Bonawitz, K., Kairouz, P. & McMahan, H. B. (2021). Federated Learning and Privacy: Building privacy-preserving systems for machine learning and data science on decentralized data [4] Dwork, C., & Roth, A. (2014). The Algorithmic Foundations of Differential Privacy. Foundations and Trends in Theoretical Computer Science, 9(3-4), 211-407. [5] Yao, A. C. (1986). How to Generate and Exchange Secrets. 27th Annual Symposium on Foundations of Computer Science (sfcs 1986). [6] Rabin, M. O. (1981). How to Exchange Secrets with Oblivious Transfer. Technical Report TR-81, Aiken Computation Laboratory, Harvard University. [7] Bonawitz, K., Ivanov, V., Kreuter, B., Marcedone, A., McMahan, H. B., Patel, S. & Ramage, D. (2017). Practical secure aggregation for privacy-preserving machine learning. In Proceedings of the 2017 ACM SIGSAC Conference on Computer and Communications Security (pp. 1175-1191).
Copyright
Copyright © 2024 Daryn Monteiro, Ishaan Mavinkurve, Parth Kambli, Prof. Sakshi Surve. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65062
Publish Date : 2024-11-07
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online