

Ijraset Journal For Research in Applied Science and Engineering Technology
Fine-Grained Multi-class Road Segmentation using MultiScale Probability Learning
Authors: A Vadivelu, Mamidipaka Sai Roshini, Yamali Sravya
DOI Link: https://doi.org/10.22214/ijraset.2024.61924
Certificate: View Certificate
Abstract
Driven road segmentation, a crucial part of advanced driver assistance systems, looks at the surroundings to keep vehicles within safe driving limits (ADASs). It begins by outlining the automatic lane detection shortfalls of conventional computer vision systems, pointing out problems such subpar segmentation, insufficient mask edge contours, sluggish processing, and restricted flexibility in intricate urban environments. Next, a multi-step procedure using deep learning networks is offered as a solution. This involves extracting vector skeletons, computing neighbouring pixels, assigning proportional weights depending on endpoints, and getting binary prediction masks. The conversation also touches on how self-driving technology will affect society, emphasizing how it could provide safe and intelligent transportation choices in the face of an increase in traffic accidents caused by careless drivers. Self-driving cars could be the first practical example of socially conscious robots interacting with humans, the story implies, even if it acknowledges possible public opposition. Furthermore, the story highlights the latest developments in autonomous driving technology, highlighting the vital requirement for strong sensing, perception, and cognitive technologies to enable completely autonomous vehicles that can adjust to changing road conditions.
Introduction
I. INTRODUCTION
Roads are important for more reasons than just infrastructure; they are essential to human life and many industrial operations, including traffic management, mapping, urban planning, and navigation. Researchers have begun automating the process of gathering road information after realizing how labor-intensive manual collection of such data is, especially when using photographs from remote sensing. Road scene segmentation is essential to accurately recognize and separate road-related objects from their surroundings because to the fast pace of urbanization and rising demands for transportation. This technology gives cars the environmental awareness required for safe navigation through traffic, and it finds applications in intelligent transportation systems, traffic monitoring, and autonomous driving. There is tremendous promise for the development of autonomous driving technology, and active safety features are improving the effectiveness and safety of transportation. One of the most important functions of advanced driver assistance systems (ADAS) is driven area segmentation, which tries to keep cars within safe driving parameters and avoid any collisions. To travel safely, this calls for a comprehension of complex driving conditions and the identification of drivable regions.
Additionally, self-driving mobility bots—such as the Self-Driving Sweeping Bot (SDSB) use machine vision and sensors to navigate and carry out activities like picking up trash. But problems still exist in fields like road segmentation and machine vision for target recognition, underscoring the necessity for continued study to develop these technologies. Road scene segmentation and drivable area segmentation are essential for improving the efficiency and safety of transportation, especially when it comes to autonomous driving systems. Even though there has been a lot of progress, more study is still needed to solve problems and enhance the accuracy and resilience of these technologies in a variety of intricate road conditions.
II. LITERATURE SURVEY
The current semantic segmentation idea in autonomous driving significantly encourages on-road driving when objects may be classified with high confidence based on their observable structures and strict inter-class boundaries are enforced. Because typical on-road sceneries are well-structured, current road extraction algorithms are highly successful and enable most kinds of vehicles to go across the area that is detected as a road. Off-road driving is highly unstructured due to the numerous additional uncertainties it entails, including ditches, quagmires, hidden items, uneven terrain structure, and positive and negative impediments. Therefore, an alternative approach to segmenting the off-road driving path is required, one that allows consideration of the vehicle type in a manner not possible with state-of-the-art on-road segmentation approaches. To overcome this constraint and facilitate path extraction in the off-road driving arena, we offer the traversability concept and accompanying dataset.
The idea behind the notion is that driving trails should be finely resolved into different areas and sub-trails that match to the capabilities of different vehicle classes in order to achieve safe traversal. [2] Road network extraction from remotely sensed images has become a powerful tool for updating geospatial datasets because to advances in deep learning semantic segmentation approaches employing convolutional neural networks (CNNs) and high-resolution imagery given by current remote sensing. However, most CNN approaches cannot produce segmentation maps with high precision and rich information when processing high-resolution remote sensing imagery. In this paper, we propose generative adversarial networks (GANs) as a deep learning method for road segmentation from high-resolution aerial imagery. In order to obtain a high-resolution segmentation map of the road network, we employ a modified UNet model (MUNet) in the generating component of the proposed GAN approach. The proposed method outperforms earlier approaches in road network segmentation when edge-preserving filtering is added as a simple pre-processing step. Experiments conducted on the Massachusetts road photo dataset yield 91.54% precision and 92.92% recall for the proposed technique. Comparisons demonstrate that the proposed GAN framework outperforms earlier CNN-based techniques, particularly in maintaining edge information. [3] Semantic segmentation using RGB and thermal imaging is an effective way to comprehend road scenes. In this work, we develop an illumination-aware feature fusion network, named IAFFNet, for all-day semantic segmentation of urban road scenes by studying fusion strategies at different stages. At the encoding step, we integrate a bidirectional guided feature fusion module to effectively recalibrate and unify RGB and temperature data. We have created adaptive fusion modules that combine high-level semantic information and low-level properties throughout the decoding process. At last, a decision-level illumination-aware method for robust all-day segmentation is available. To the best of our knowledge, we are the first to directly apply light cues to RGB-T semantic segmentation. Thorough experimental evaluations show that, in comparison to state-of-the-art methods, the proposed method can achieve outstanding performance on publically available datasets. [4] One of the most often utilized methods for comprehending road scenes is semantic segmentation. Road scene interpretation has greatly advanced using recently created deep learning-based semantic segmentation networks, which are typically based on the encoder-decoder structure. We present a boundary-aware, lightweight prediction and refinement module that can hierarchically improve the segmentation results with spatial information in order to solve this issue. The upper-level border attention unit and the upper-level prediction attention unit are the two attention units in the proposed refinement module. While the upper-level boundary attention unit concentrates on features close to the semantic boundary of the upper-level segmentation result, the upper-level prediction attention unit highlights the features in the regions that require refinement using the upper-level's predicted class probability. The suggested prediction and boundary-aware refinement module in the decoder network can be used to gradually improve the segmentation result top-down to a more precise and comprehensive one. The suggested prediction and border attention-based refinement module can provide a significant performance improvement in segmentation accuracy with a slight increase in computational cost, according to experimental results on the Cityscapes and CamVid datasets. [5] The need for personal mobility among the elderly and crippled is growing as society ages. According to domestic government statistics, there were 90,000 electric wheelchairs in Korea as of 2017, and the number has continued to rise. However, due to their poorer judgment and coordination than average persons, elderly and those with impairments are more likely to be involved in car accidents. Unbalanced road surface conditions can interfere with a vehicle's ability to steer, which is one of the variables that might cause accidents. In order to stop these kinds of incidents from happening, we provide in this study a lightweight semantic segmentation technique that can quickly identify areas of road-surface damage in photos. In an experiment, more than 1,500 training data and 150 validation data, including damage to the road surface, were manufactured specifically to evaluate the algorithm. Unlike the auto-encoding type, which consists of both encoder and decoder, we propose a novel form of deep neural network based solely on encoder type using the data. Four accuracy measures and two speed metrics were taken into consideration in order to assess the performance of the suggested algorithm. This deep neural network method outperforms the conventional approach with improvements in every accuracy index, an 85.7% reduction in parameters, and a 6.1% boost in computational speed. It is anticipated that the use of such a fast algorithm will increase personal transportation safety. [7] This research presents an approach that uses spatial contexts to jointly infer road layouts and partition urban sceneries semantically. The suggested approach is predicated on the hypothesis that there exists a locational relationship between a group of pertinent factors in an urban setting. To aid in precise image segmentation, this relationship can be modeled as a location prior and label cooccurrences. On the inferred road layout, special coordinates known as road-normal coordinates are constructed in order to apply these environmental characteristics. These coordinates are found by taking the output of an existing segmentation technique and using the marginal probability to calculate the most appropriate road plan. After projecting all potential segments in an image containing depth data from the lidar sensor into the road normal coordinates, each segment is subjected to additional potentials of a conditional random field model based on the learnt location prior and label co-occurrence statistics. The suggested approach is assessed using an urban dataset that is accessible to the general public, which includes point clouds and associated photographs.
[8] Incorporating the complementary advantages of point clouds and photos, this study tackles the problem of semantic segmentation of large-scale 3D road scenes. This research extracts 2D visual data from images using a Convolutional Neural Network (CNN) for 2D semantic segmentation and 3D geometric features from a point cloud using a deep neural network to fully leverage geometrical and visual information. This work employs superpoints as an intermediary representation to connect the 2D features with the 3D features in order to bridge the features of the two modalities. A superpoint-based pooling method is proposed for combined learning to mix the data from the two different modalities. The process is evaluated through the creation of three-dimensional scenes using the Virtual KITTI dataset. The experiment data show that the recommended method makes significant advantages over the 2D picture and 3D point cloud semantic segmentation approaches, and that it is possible to segment large-scale 3D road sceneries based on the compact and semantically homogeneous superpoints. [9] Computer vision-based artificial intelligence models that categorize each picture pixel to a certain item class are trained using semantic segmentation annotation. A variety of supervised deep learning techniques are employed by model developers to find features that can be utilized to identify items of interest. The existing approaches to semantic segmentation have two drawbacks. Second, because certain classes are more common than others, the datasets used for the semantic segmentation job are not balanced. As a result, the model exhibits biased behavior in favor of the more represented. Based on a deep reinforcement learning algorithm, we propose a novel method for reinforced active learning. This work presents a modified Deep $Q$ Learning formulation for active learning. From an unlabeled data pool, an agent learns the strategy of choosing a subset of small image regions that have more knowledge than the complete set of images. The selected area is determined for training based on the segmentation model uncertainty and underlying assumptions. We evaluate the proof of concept with CamVid and the RGB indoor test scenes dataset. According to our findings, our strategy requires underrepresented groups to submit more labels than baselines, which boosts their output and lowers the class discrepancy. On the Camvid road segmentation scene dataset, our technique outperforms the typical deep learning models in detecting 8 out of 11 classes. With an accuracy of around 75.82% and a BF score of 77.25% on the SUNRGB indoor scenes dataset, it exceeds the state-of-the-art methods. [15] The most important stage in the modeling and extraction of the road network is the road centerline extraction. Traditional road extraction methods' hand-crafted feature engineering is unstable, which can lead to overall extracting mistakes as well as complex scenarios where the extracted road centerline deviates from the road center. Lately, deep neural network-based semantic segmentation-based road centerline extraction techniques have significantly surpassed more conventional techniques. Nevertheless, the post process of road segmentation is error-prone, and the pixel-wise labels required for training deep learning models are costly. We present Deep Window, a novel approach to automatically extract the road network from remote sensing photos, which is inspired by the work of human posture estimate. Without first requiring road segmentation, Deep Window tracks the road network straight from the photos using a sliding window guided by a CNN-based decision function. To estimate the road center points inside a patch, we first create and train a CNN model. Next, using the CNN model, the road seeds are automatically searched patch by patch. Lastly, our method tracks the road center-line iteratively along the road direction guided by the CNN model after first estimating the road direction using a Fourier spectrum analysis algorithm, beginning from seeds. By using point annotations to train the CNN model instead of semantic model training, our approach significantly lowers training costs.
III. METHODOLOGY
The project "Fine-Grained Multiclass Road Segmentation using Multi Scale Probability Learning" employs a methodology that consists of multiple crucial processes, all aimed at precisely classifying and demarcating distinct road classes using high-resolution aerial or satellite information. The project starts by gathering and preparing data. Road networks are represented in high-resolution aerial or satellite photography that is gathered from various sources, including open data repositories, satellite providers, and governmental organizations. After that, preprocessing is done on the imagery to improve its quality, eliminate noise, and standardize the format for analysis later on. Preprocessing techniques like image scaling, normalization, and color correction may be used to guarantee consistency and interoperability between various datasets. The research then focuses on learning representations and extracting features. From the preprocessed pictures, Convolutional Neural Networks (CNNs) are used to automatically train discriminative features. Multiple convolutional layers in the CNN architecture are intended to capture hierarchical spatial patterns and contextual information, making it specifically tailored to handle the fine-grained nature of road segmentation. Additionally, transfer learning approaches can be used to bootstrap the learning process and enhance generalization performance by utilizing CNN models that have already been trained on sizable picture datasets.
The project culminates with the analysis and application of the results. To find chances for additional refinement, potential errors, and places for improvement, the segmented road maps produced by the CNN-MPL model are evaluated.
The results of the project are disseminated to stakeholders, such as decision-makers, urban planners, and transportation authorities, in order to influence plans for urban development, transportation infrastructure management, and policy-making. Additionally, the trained segmentation model can be used to assist safer, more effective, and sustainable transportation systems in real-world applications including traffic management, autonomous vehicle navigation.
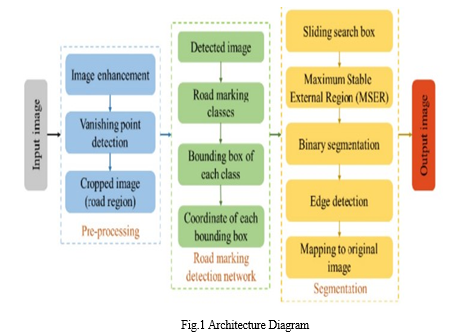
"Fine-Grained Multi-class Road Segmentation using Multi-Scale Probability Learning" has an architecture designed to efficiently identify roads from satellite or aerial photos. First, the model applies convolutional layers to the input image in order to extract hierarchical features that capture both specific details and a wider context. By combining features from several convolutional layers, multi-scale feature fusion preserves complex information and incorporates deeper contextual knowledge. Next, each pixel is given a class name by the multi-class classification head, which may include categories other than roadways, such as sidewalks or cars. By calculating class probabilities for every pixel, the model uses probability learning to improve predictions and facilitate more sophisticated decision-making. To aid with optimization, a loss function measures the difference between the ground truth and anticipated labels during training. In the end, the output layer creates a segmented image with labels for each pixel based on the expected class. This segmentation result may be improved by post-processing techniques, which guarantee clean borders and the elimination of artifacts. Assessment criteria, like the F1 score or Intersection over Union (IoU), evaluate the model's performance and confirm that it is effective in precisely segmenting roadways among a variety of environmental factors.
IV. PROPOSED WORK
In order to generate more accurate and reliable segmentation results, the proposed system for fine-grained multiclass road segmentation utilizing MultiScale Probability Learning (MPL) leverages deep learning and probabilistic modeling techniques. This marks a substantial leap over prior methods. A convolutional neural network (CNN) architecture specifically designed for road segmentation tasks forms the basis of the suggested system. Large-scale annotated datasets with high-resolution aerial or satellite imagery are used to train CNNs so they can automatically identify discriminative characteristics and spatial patterns linked to various road classes, including highways, city streets, and country roads. The suggested method uses MultiScale Probability Learning techniques in addition to CNNs for feature extraction to improve segmentation accuracy. In order to function, MPL models the probability distribution of road pixels at various sizes while taking into account contextual data that is both local and global. More accurate and dependable segmentation results are produced by the segmentation algorithm's ability to capture uncertainties and variations in road appearance across various spatial resolutions thanks to this probabilistic modeling method.

The suggested method can efficiently handle the complexity and variety of road networks in real-world scenarios by utilizing the complementing characteristics of numerous MPL models, producing segmentation results that are more dependable and consistent. The suggested system is tested on separate testing datasets to gauge its generalization performance after training and validation. The system's robustness and accuracy in segmentation are measured by the computation of performance measures such F1-score, precision, recall, and accuracy. To evaluate the quality of segmented road maps and pinpoint possible areas for improvement, qualitative visual inspections are also carried out. The effectiveness of the proposed system in fine-grained multiclass road segmentation tasks is validated by comparing its performance against state-of-the-art methodologies and baseline methods. In the end, the suggested approach has a lot of potential to improve road segmentation precision and dependability in a variety of difficult settings. The proposed system provides a comprehensive solution for fine-grained multiclass road segmentation by combining deep learning with probabilistic modeling techniques. This allows transportation authorities, urban planners, and decision-makers to obtain precise and comprehensive information about road networks for well-informed decisions and infrastructure management initiatives.
Conclusion
When noise, buildings, and trees cast shadows on the environment, it becomes very hard to generate road boundaries from complex remote sensing data. The process of creating segmentation masks and using them to forecast the road borders is a simple solution to this problem. The segmentation masks\' sharpness has a major impact on how well this technique works. Our model makes use of a hybrid encoder that is split into two sections: the first section generates high-quality feature encoding, while the second section extracts features in full resolution. On the other hand, the second section makes advantage of max-pooling layers to expand our network\'s overall receptive field and supply the network with sufficient context information to function. Before the features from both sections are combined together, an activation map is created for each component, giving the network the ability to choose how much weight to assign the features from each encoder stage. Large road segmentation and the creation of fine-edged segmentation masks are made easier by this, which is a crucial function when the segmentation performance has a significant impact on the edge detection module\'s performance. The road borders are subsequently detected using the encoded features and the fine-edged segmentation masks. It is simpler to identify edges when a road\'s structure is revealed from a very complicated environment thanks to the segmented masks. In the area of drivable area segmentation, ours performs better in terms of accuracy and real-time performance. Furthermore, our techniques work with other networks as well, demonstrating the method\'s generalizability.
References
[1] ShahrzadShashaani,MohammadTeshnehlab,AmirrezaKhodadadian,MaryamParvizi,Thomas Wick,Nima Noii Using Layer-Wise Training for Road Semantic Segmentation in Autonomous Cars IEEE Access, 2023. [2] AbolfazlAbdollahi,BiswajeetPradhan,GauravSharma,KhairulNizamAbdulMaulud,Abdullh Alamri Improving Road Semantic Segmentation Using Generative Adversarial Network IEEE Access, 2021. [3] Hou,Yan Jia,Zhijiang Hou,Xiaoli Hao,Yan Shen IAFFNet: Illumination-Aware Feature Fusion Network for AllDay RGB-Thermal Semantic Segmentation of Road Scenes IEEE Access, 2022 . [4] Jee-Young Sun,Seung-Won Jung,Sung-Jea Ko Lightweight Prediction and Boundary Attention-Based Semantic Segmentation for Road Scene Understanding IEEE Access, 2020. [5] Seungbo Shim,Gye-Chun Cho Lightweight Semantic Segmentation for Road-Surface Damage Recognition Based on Multiscale Learning IEEE Access, 2020. [6] Weiwei Zhang,Zeyang Mi,Yaocheng Zheng,Qiaoming Gao,Wenjing Li Road Marking Segmentation Based on Siamese Attention Module and Maximum Stable External Region IEEE Access, 2019 . [7] Jeonghyeon Wang,Jinwhan Kim Semantic Segmentation of Urban Scenes Using Spatial Contexts IEEE Access, 2020. [8] Liuyuan Deng,Ming Yang,Zhidong Liang,Yuesheng He,Chunxiang Wang Fusing geometrical and visual information via superpoints for the semantic segmentation of 3D road scenes Tsinghua Science and Technology, 2019. [9] Usman Ahmad Usmani,Junzo Watada,Jafreezal Jaafar,Izzatdin Abdul Aziz,Arunava Roy A Reinforced Active Learning Algorithm for Semantic Segmentation in Complex Imaging IEEE Access, 2021. [10] A. Paszke, A. Chaurasia, S. Kim and E. Culurciello, ENet: A deep neural network architecture for real-time semantic segmentation, arXiv:1606.02147, 2016. [11] D. Qiao and F. Zulkernine, Drivable area detection using deep learning models for autonomous driving, Proc. IEEE Int. Conf. Big Data (Big Data), pp. 5233-5238, Dec. 2021. [12] D. K. Dewangan and S. P. Sahu, Optimized convolutional neural network for road detection with structured contour and spatial information for intelligent vehicle system, Int. J. Pattern Recognit. Artif. Intell., vol. 36, no. 6, May 2022. [13] J. Cheng, H. Li, D. Li, S. Hua and V. S. Sheng, A survey on image semantic segmentation using deep learning techniques, Comput. Mater. Continua, vol. 74, no. 1, pp. 1941-1957, 2023. [14] M. A. S. Bahri, K. N. A. Maulud, M. A. Rahman, A. O. R. Oon and C. H. C. Hashim Integrated facility and assets management using GIS-Web application, IOP Conf. Ser. Earth Environ. Sci., vol. 540, Aug. 2020. [15] Renbao Lian,Liqin Huang DeepWindow: Sliding Window Based on Deep Learning for Road Extraction From Remote Sensing Images IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 2020.
Copyright
Copyright © 2024 A Vadivelu, Mamidipaka Sai Roshini, Yamali Sravya. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET61924
Publish Date : 2024-05-10
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online