

Ijraset Journal For Research in Applied Science and Engineering Technology
Food Image Recognition and Calorie Prediction
Authors: Akarsh V, Aswathy Santhosh C, Jessil Thomas, Rekha M S, Steffi Thomas
DOI Link: https://doi.org/10.22214/ijraset.2024.60510
Certificate: View Certificate
Abstract
This paper pivot on food classification also with boosting the task accuracy and also productivity through the usage of deep learning algorithms food classification is a major component in applications such as nutritional knowledge and restaurant menu analysis and recognizing food items from photographs is a big difficulty the cony-net and resnet152v2 were set to take on this task this study focuses on the potential of transfer learning to simplify food categorization procedures with algorithm selection playing an important part in reaching high accuracy rates as the amount of food-related applications grows the result of this can act as the selection of transfer-learning algorithms to enhance food recognition and classification systems allowing for breakthroughs in fields such as nutritional analysis and food recommendation systems in this food categorization.
Introduction
I. INTRODUCTION
Food has existed as a necessity for human existence since the beginning of time and is currently gaining more attention than it did in the past. Currently, the main technique used in food supply is to precisely identify and choose the right food items for human visual inspection. This procedure is costly and time-consuming. Therefore, it is essential to have a food image diagnosis system that can automatically classify approved food items. Major advancements in surveillance, medical imaging, detecting, and observing have been made possible by recent forming in processing and identification.
While data mining and machine learning tactics have been successfully applied to automatically classify food photographs, most existing systems classify diets, and datasets often contain entire meals. A limited number of specially produced exist for pictures of food items, and much scrutiny has not been done on multi-class. The different food groups, each with distinct traits and commonalities, are hard for traditional identification techniques to take into consideration. There are advantages and disadvantages to employing different strategies to address this problem, such as creating complex features for enhanced representation even when complex and situation-specific design issues arise. When making decisions, the suggested method gives information the upper hand over intricate representations.
II. METHODOLOGY
It will provide a detailed description of the methods utilized to finish and operate this project successfully. Many methodologies or discoveries from this subject are mostly published in journals for others to use and enhance in future research. The approach is used to attain the project's purpose of producing a faultless output. The technique used to analyse this project is based on the System Development Life Cycle (SDLC), which consists of three primary steps: planning, implementation, and analysis.
A. Planning
Planning needs to be done correctly in order to identify every piece of information and necessity, including software and hardware. Data gathering and the hardware and software requirements are the two primary components of the planning process.
B. Data collection
Make sure the data you are gathering has enough features supplied aiming for your learning model to be appropriately trained. Check you include enough rows since, generally speaking, the more data you have, the better. The initial data which was stack up from web sources is still available in its unprocessed form as sentences, numbers, and qualitative phrases. The unprocessed data contains inconsistencies, omissions, and mistakes. After carefully examining the filled surveys, modifications are necessary. The proceeding of primary data requires the following processes. It is necessary to aggregate a sizable amount of raw data from field surveys so that it finds the details about individual replies that are comparable. Data preparation is one way to turn the raw data into a clean data collection. Stated differently, if data is acquired in unprocessed form from several sources; analysis is not appropriate. A few steps are taken to convert the data into a small, clean data collection.
This way is used before doing an iterative analysis. The set of procedures is called data preparation. Included are data reduction, data cleansing, data integration, and data transformation. Preprocessing of data is necessary since unformatted real-world data does exist. The predominance of data in the real world is inaccurate or missing: Missing data can have a quota of sources, such as erratic data gathering, mistakes in Data preparation is one way to turn the raw data into a clean data collection. Stated otherwise, if data is acquired in unprocessed form from several sources, it is inappropriate for examination. A few steps are taken in aiming to convert the data into a small, clean data collection. This plan is used before doing an iterative analysis. The set of procedures is called data preparation. Included are data reduction, data cleansing, data integration, and data transformation. Preprocessing of data is necessary since unformatted real-world data does exist.
III. LITERATURE REVIEW
It is very important to people in the modern society, especially the elderly. Generally speaking, food consumption is determined using a scale. Despite this, it is laborious because each food item demands to be measured separately before and after consumption. Direct measurement of amount of food consumed on the meal tray is done using a short-range depth camera, which increases measuring ease of use.
To attain the previously indicated goal, two main problems emerge. The impact of the tray's content comes first. The other pixel in the depth image is the one that has no depth values. The estimate is first converted to weight using the specific gravity function, after which the volume is computed. The weight is then converted to calories using the food calorie computation. We can use linear, quadratic or cubic functions to approximate the specific gravity function of any meal. The lowest average inaccuracy of food intake weight in the experimental investigation is 5.6 grams. It is approximately 7.5%. The findings show the victory of the suggested approach in estimating the weight of food consumed. We suggest1 3"Calorie Captor Glass," a HoloLens-based image-based food calorie estimate device. To approximate the specific gravity function of any meal, one can utilize cubic, quadratic, or linear functions.
In the experimental inquiry, the food intake weight with the lowest average inaccuracy is 5.6 grams. That comes to about 7.5%. The results show how well the recommended method works for finding the weight of food consumed. We recommend1 3 "Calorie Captor Glass," an image-based meal calorie estimation tool based on HoloLens technology. We leverage HoloLens's 3D environment recognition capability to estimate meal sizes accurately, allowing for precise calorie and quantity estimates. Using the combination of CNN-based food picture segmentation and predicted 2D meal sizes and meal-dependent quadratic curves between meal size and calories, we estimate the calorie intake of 46 different varieties of meals.
HoloLens displays the anticipated meal categories and calories over the augmented reality area, inviting us to try this unique dining experience. For medical needs, a food nutrition and energy intake identification system will be suggested. In summation to nutritional information tables, this routine is based on food picture processing and shape identification. The device uses a unique road to take pictures of the meal both before consumption and also after consumption so that we can work out how many calories and nutrients the chosen food contains.
Our approach offers a novel tool for determining the food intake that has potential applications and efficacy in the treatment of obesity. People these days have demonstrated a strong desire to lose weight by tracking the number of calories they eat. The assessment of nutrition and calories is used to track body fat. The calorie values in this dietary management system are determined using features extraction, segmentation, and classification. Next, using the food area volume and nutrition measure based on the mass value, the calorie value is calculated. The nutritional evaluation provides an effective method for a person's food consumption by figuring out the calories in each meal item. Here, the food items are segmented using the FCM method, and the segmented food items are then classified using a Sphere Shaped SVM classifier. The food products are automatically identified, and their calorie value is subsequently determined using this procedure. With a 95% accuracy rate, the suggested approach achieves superior categorization.
This research proposes a mechanism for medical applications to recognize dietary nutrition and energy consumption. Additionally for nutritional information tables, this medium is based on food picture processing and shape identification. Numerous studies conducted recently have indicated that serve patients who are obese or overweight may help more from using technology, such as smartphones. The device uses a unique method to take pictures of the meal both before and after consumption in order to calculate how many calories and nutrients the chosen food contains. Our approach offers a novel mechanism for judging food intake that has potential applications and efficacy in the care of obesity.
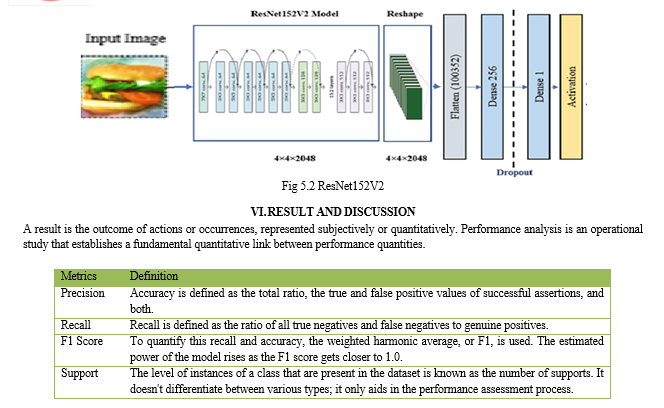
IV. SYSTEM ARCHITECTURE
The relationships between various components might be displayed using a system architecture diagram. They are again and again designed for hardware and software-based systems and the figures display how all these parts interact. System architectures may be split into three parts they are mixed (partially dispersed and partially integrated), integrated, and distributed. It is demonstrated that an architecture's type is determined by its interfaces. More interfaces are present in integrated systems and these bonds are also not well defined. The planning and design phase, operational analysis phase, requirements analysis phase, function analysis phase, and physical synthesis phase are the five processes that should make up the creation of a systems architecture.

Conclusion
We offer an intelligent food recognition and calorie prediction system that predicts the level of calories in a given food image. The e-system automatically estimates the calories in the food simply by taking a photo of the food from above using a pre-registered Reference Article. Also, a bunch of data augmentation and segmentation must be done, and pure pixel values are not needed in CNN, because it learns the general pattern needed to detect and recognize new images by itself. So, using CNN model the accuracy is relatively a lot of other normal models. This gives almost 70% accuracy. An image of food as input to the system, it quickly recognizes the food/products shown in the image and its caloric value as output displayed in the picture together with the output\'s calorie value.
References
[1] G. A. Tahir and C. K. Loo, An Open-Ended Continual Learning for Food Recognition [2] Chengpeng Chen, Weiqing Min, Xue Li, Shuqiang Jiang, Hybrid incremental study of new data and new classes for hand-held object detection. [3] Kamiri, J., & Mariga, G. (2021). A Content Analysis,” International Journal of Computer and Information Technology. [4] He, Jiangpeng, and Fengqing Zhu. \"Online continual training for visual food classification. [5] P. Duan, W. Wang, W. Zhang, F. Gong, P. Zhang, and Y. Rao, \"Food Image Identification Using Pervasive Cloud Computing.
Copyright
Copyright © 2024 Akarsh V, Aswathy Santhosh C, Jessil Thomas, Rekha M S, Steffi Thomas. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET60510
Publish Date : 2024-04-17
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online