

Ijraset Journal For Research in Applied Science and Engineering Technology
Foreseeing Outbreak Investigation by Means of Machine Learning
Authors: Dinesh AR, Dr. Pradeep Udupa
DOI Link: https://doi.org/10.22214/ijraset.2023.50250
Certificate: View Certificate
Abstract
The deliberate breach of a security strategy is what intrusion exposure is. In order to look for any malicious actions or extortions, invasion discovery systems monitor network traffic passing across numerous types of computer systems and deliver warnings when it perceives any hazards. Systems for identifying extortions should be able to recognize every injurious software and occurrence in the linkage. All forms of occurrences, comprising intrusion, file less malware, botnets, and malware, are changing the threat environment. In order to identify harmful events by investigating the program\'s negotiating pattern, a learning recognition system is essential. In this situation, we have form the structure to stipulate the type of attack that machine learning has accepted. Malicious action exposure can be alienated into two classes: signature grounded discovery and misuse discovery. For both types of revealing, an IDS must gather the essential data, assess it, and then associate it to outbreak signs retained in big databanks. In our paper, we advised a technique for generating nominal IDS employing either the stacking procedure or the decision tree procedure. According to the outcomes, the recommended method achieves more precisely and professionally than other approaches like logistic regression and random forest. The accurateness rate values for the results formed by the proposed technique are 99.36%. Outbreak analyzer method uses four dissimilar procedures to assess numerous kinds of protocols constraints and endorse users. After that, it stacks approaches with and without characters choice to assess the accuracy and choose the best algorithm to recognize which types of outbreaks such as, port scans, brute force attacks, benign, DoS, bot attacks, infiltration, and web attacks.
Introduction
I. INTRODUCTION
Extortions or malevolent action is originate using an imposition discovery system. To safeguard a computer network, the IDS receipts network level distrustful action. The hazard or imposition always exhibits itself as an irregularity in a linkage. The protection of a network is violated when an intruder takes advantage of system defects such as lax security rules, software issues like buffer overflows, and DoS attacks that exploit network flaws. The intruders could be cybercriminals, who are regular internet users who want to steal or harm extremely sensitive data from the victim's system, or they could be system users with fewer privileges who want to have more access to allowed data.
The types of intrusion detection methods include signature-based and anomaly-based techniques. A specialized system or piece of software monitors packet flow in the network and compares it to earlier discovered, configured known signatures of known threats. This is known as signature-based detection. Comparing
Defined legitimate user parameters with occurrences that reveal divergence from the legitimate user parameters is how the anomaly detection technique finds assaults, in contrast. Whenever malicious behavior occurs in a network, the IDS creates logs and notifies the network administrator.
Systems for detecting threats should be able to identify every harmful software and activity in the network. All forms of threats, including incursion, file-less malware, botnets, and malware, are changing the threat environment. In order to identify harmful events by examining the program's behavioral pattern, a learning detection system is necessary. Using machine learning and deep learning approaches, we have created models to recognize the malicious software and system events. Before generating the end outcome, ensemble is a technique for mixing the output of various algorithms.
A. Goals
- Threat detection systems that can accurately identify all malicious programmers and network events
- The threat environment is changing for all forms of attacks, including intrusion, malware, file-less malware, and botnets. To identify malicious occurrences, it is necessary to use a learning detection system that examines the program's behavioral pattern.
- Secure automatic threat detection and prevention scans the network and server functions and alerts the analyst if any suspicious behavior is found in the network traffic. This method is more efficient at reducing the burden of the analyst. It continuously monitors the system and reacts in accordance with the threat environment.
- Our technology uses a variety of machine learning methods to identify network intrusion. IDS keeps an eye out for malicious behavior and guards against unauthorized access from users, possibly even from insiders, to a computer network.
- The danger or intrusion manifests as an anomaly in a network. Network faults are exploited by hackers that violate the security of the network by abusing network vulnerabilities like lax security regulations and software problems like buffer overflows.
II. BACKGROUND AND ANTIQUITY
At the center of the project is a machine learning algorithm. The most pertinent items are suggested to users via a recommendation engine, which filters the data using various techniques. It records the user's preferences and inclinations and then proposes alternatives that are consistent with those preferences.
A. Procedure Used
- Extra Tree Classifier
Extremely randomized trees are a constituent of ensemble learning approaches. The decision trees are constructed by it. The decision rule is drawn at random during tree construction. With the exception of random split value selection, this algorithm's rule is quite similar to that of Random Forest.
2. Decision Tree Classifier
Data contribution is classified as usual or irregular using the decision tree classifier. A decision tree is a graph in the form of a tree with central nodes that signify tests on characteristics, branches that designate the outcomes of the tests, and leaf nodes that exemplify class labels.
The route selected from the root node to the leaf decides the grouping models. The root node is divided first, then each input information. Decision trees are capable to assess data and spot patterns in the network that point to malicious action. By investigating a noteworthy amount of intrusion discovery data, it can progress countless real time security systems. It can spot patterns and trends that aid in surveillance, attack signature generation, and other investigative tasks. Decision trees offer a rich set of guidelines that are simple to grasp and can be easily linked with real-time solutions. This is the fundamental benefit of utilizing decision trees instead of other classification systems.
3. Random Forest Algorithm
The recommended intrusion discovery framework employs Random Forests as a classifier. According to empirical discoveries, developing an IDS that is successful and efficient for network intrusion detection is made possible by the Random Forests classifier with SMOTE and information gain-based feature selection.
4. XGBoost Algorithm
A gradient boosting outline is used by the ensemble machine learning technique XGBoost, which is decision-tree grounded. Artificial neural networks normally outperforms all other procedures or outlines in prediction problems requiring unstructured knowledge. But when it includes small to intermediate amounts of structured data, decision tree grounded procedures are right away observed as best in class.
5. Ensemble Algorithm:
An ensemble machine learning approach called "Stacking," or simply "Stacking," uses generalization. It entails using techniques like bagging and boosting to combine the predictions from various machine learning models on the same dataset. Stacking frequently takes into account diverse weak learners, trains them in parallel, and then combines them by teaching a meta-learner to produce estimates based on the predictions of the diverse weak learners.
III. LITERATURE REVIEW
- Correlation-based feature selection (CFS-BA) Ensemble technique, which consists of the C4.5, Random Forest (RF), and Forest by Penalizing algorithms (Forest PA) In this study's outlier detection method, the neighborhood outlier factor is used to measure the dataset of anomalies (NOF).
The trained model in this instance uses a distributed storage infrastructure and large datasets to improve the effectiveness of the intrusion detection system.
The outcomes of the experiments demonstrated that the suggested approach finds abnormalities far more accurately than any other approaches. [1]
2. This study introduces an efficient and automatic network monitoring system that keeps track of all network switches and notifies the administrator through email or SMS whenever a network switch fails. Additionally, this system indicates where the topology of the network is problematic and how it affects the remainder of the network.
In a Linux context, this network monitoring solution makes use of the clever interplay between Request Tracker (RT) and Nagios software. In Nagios, the network architecture is constructed, and every network node is continuously monitored according to the services assigned to them.
The RT software receives a notification from Nagios as soon as a network node fails. With details about the faulty node and how it affects the rest of the network, this message will create a ticket in the RT database. The RT software is set up to immediately transmit the ticket to the network administrator through email and SMS after it is produced. According to the stated priority, if the administrator is currently busy and does not resolve the complaint within an hour, the same issue is immediately sent to the second network responsible person. As a result, each person on the priority list is notified individually until the problem is addressed. [2]
3. Secure automated threat detection and prevention scans the network and server functions and alerts the analyst if any suspicious activity is found in the network traffic.
This method is more successful at reducing the workload of the analyst. It continuously monitors the system and reacts in accordance with the threat environment. From phase to phase, this reaction action changes. In this case, suspicious activity is discovered with the aid of artificial intelligence, which serves as a virtual analyst while working with network intrusion detection systems to protect against the threat environment and take appropriate action with the analyst's approval. Its final phase entails performing packet analysis to look for attack vectors and classifying both supervised and unstructured data. Wherein the algorithm will be automatically updated after the unsupervised data has been decoded or converted to supervised data with the assistance of analyst feedback (Virtual Analyst Algorithm). In order for the algorithm to improve over time by becoming stronger and more efficient, it uses an active learning mechanism. As a result, it can fight against similar or identical attacks [3].
4. Numerous public and commercial enterprises are in danger due to malicious insider activity. In this research, a novel method for identifying malevolent behavior is presented. Textual session-based data samples are the granularity level we suggest using to describe user log data. Character embedding and a deep learning model made up of CNN and LSTM are used to model the user's behavior.
Using characters embedding, the input samples are represented. Then, local tri-gram features are extracted from the input samples using a convolution layer, and the order of these features is taken into account using an LSTM layer (tri- grams). We run tests using a variety of model designs that lack any custom features. A portion of the CERT Insider Threat dataset, version 4.2, is used to evaluate the proposed model.
a. Hardware and Software Requirements
- Operating System: Windows 7/ Windows 10
- Language: PYTHON- DJANGO
- Software with version: VS CODE 1.48.2
- Database Proposed: SQLITE /MySQL
IV. PROPOSED SYSTEM ARCHITECTURE
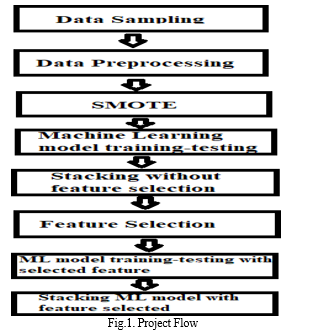
The actual project flow, initiating with data sampler that is still stacking, is depicted in Fig1 above. It also comprises the technique used for feature assortment. A training dataset can be transmuted using a diverse methods delivered by data sampling in order to stabilize or better balance the class dispersal. The newly transformed dataset can be accomplished directly using ordinary machine learning methods after it has been stabilized. This empowers the exertion of imbalanced classification to be preserved and overcame using a data preparation approach, even with significantly imbalanced class dispersals.
Data preprocessing is the procedure of transforming raw data into something that can be utilized to train or test a machine learning model. The preliminary and most significant step in developing a machine learning model is this one. We infrequently see clean, prearranged data when developing a machine learning project. Additionally, any time you work with data, you need to cleanse it up and prepare it. So, in order to do this, we pre- process data.
The most popular oversampling technique used to address the imbalance issue we previously addressed is called SMOTE (synthetic minority oversampling technique). By boosting the random replication of minority class cases, it seeks to balance class distribution. SMOTE combines already existing minority instances to create new minority instances. For the minority class, it creates virtual training records using linear interpolation. By randomly choosing one or more examples from the minority class, these synthetic training records are created.
Stacking, also known as Stacked Generalization, Exploring a range of several models for the same problem is the goal of stacking. The concept is that you can utilise a learning problem with various sorts of models that can only learn a portion of the problem—not the entire problem field. In order to create an intermediate prediction, you can design numerous learning machines, each of which you utilise to make a single forecast for each taught model. Then you incorporate a fresh model that has the same aim that will gain knowledge from the earlier predictions. The actual objective and the anticipated target will be compared.
This last form is described as being layered on top of one another. As a result, it enhances overall performance and frequently results in a model that is superior to each particular intermediate model. The advantage of this over a single Notice, as is frequently the case with any machine learning technique, is that it does not provide you with any guarantees.
A subset of pertinent features are chosen through the feature selection (or attribute selection) procedure to be used in the model construction [15]. In order to avoid dimensionality in machine learning, boost generalization by lowering variance, and save training time, feature selection approaches are used. When using the feature selection technique on data, it is common for the data to still have traces of characteristics that are redundant or unnecessary but can be deleted without significantly affecting the data’s quality.

With the training dataset's full set of features, four diverse single classifiers are trained, and forecasts are made. Table I exhibits the accurateness outcomes for the numerous training systems. Random Forest accuracy is 98.04%, Decision tree accuracy is 99.36%, XGBoost accuracy is 97.07%, and Extra Tree Classifier accurateness is 98.89%.According to the decision algorithm. All four algorithms employ the ML staking method. The total yield from each classifier is used as input for the staking procedure, which returns a value of 99.36%.

The graphical representation of the value acquired for each algorithm based on its accuracy is shown above Fig. 3. It can be observed that the suggested approach was successful.
In our project, the Attack Analyzer system authenticates the user and adds data value that uses a decision tree algorithm to identify several attack kinds, such as "Benign," "DoS," "PortScan," "BruteForce," "WebAttack," "Bot," and "Infiltration," before identifying infiltration.
Final Output- which types of attack is detected
|
Attack Types |
Benign |
DoS |
Port Scan |
Brute Force |
Web Attack |
Bot |
Infiltration |
Conclusion
Safety apprehensions have amplified because of substantial upsurge in number of terminals or large system over internet. To discover malicious actions by examining the interactive outline of the program a learning discovery scheme is essential. The projected procedures decision tree and stacking technique has accomplished very fine as compared to random forest, extra tree classifier xgboost without any feature assortment technique implemented. The outcome attained by our proposed method has the Accurateness rate is 99.36%.
References
[1] Intrusion Detection System (IDS): Anomaly Detection Using Outlier Detection Approach International conference on Intelligent Computing, Communication & Convergence (ICCC-2014) [2] D. Ten, S. Manickam, S. Ramadass, and H. A. Bazar, “Study on Advanced Visualization Tools In Network Monitoring Platform,” in Third UKSim European Symposium on Computer Modeling and Simulation, EMS ‘09’, Minden Penang, Malaysia, December 2009. [3] L. Chang, W.L. Chan, J. Chang, P. Ting, M. Netrakanti, “A network status monitoring system using personal computer,” presented at IEEE Global Telecommunications Conference, August 2002. [4] Intrusion Detection System (IDS): Anomaly Detection Using Outlier Detection Approach International conference on Intelligent Computing, Communication & Convergence (ICCC-2014) [5] J. Brownlee, “A Tour of Machine Learning Algorithms”, https://machinelearningmastery.com/a-tour-of-machine-learning- algorithms/ 2013 [6] E. K. Viegas, A. O. Santin, and L. S. Oliveira, “Toward a reliable anomaly-based intrusion detection in real-world environments,” Comput. Networks, vol. 127, pp. 200–216, 2017. [7] A. Verma and V. Ranga, “Statistical analysis of CIDDS-001 dataset for Network Intrusion Detection Systems using Distance-based Machine learning,” Procedia Comput. Sci., vol. 125, pp. 709–716, 2018. [8] T. Hamed, R. Dara, and S. C. Kremer, “Network intrusion detection system based on recursive feature addition and bigram technique,” Computer. Secure. vol. 73, pp. 137–155, 2018. [9] C. R. Wang, R. F. Xu, S. J. Lee, and C. H. Lee, “Network intrusion detection using equality constrained-optimization-based extreme learning machines,” Knowledge-Based Syst., vol. 147, pp. 68–80, 2018. [10] G. Fernandes, L. F. Carvalho, J. J. P. C. Rodrigues, and M. L. Proença, “Network anomaly detection using IP flows with Principal Component Analysis and Ant Colony Optimization,” J. Netw. Comput. Appl., vol. 64, pp. 1–11, 2016. [11] U. Ravale, N. Marathe, and P. Padiya, “Feature selection based hybrid anomaly intrusion detection system using K Means and RBF kernel function,” Procedia Comput. Sci., vol. 45, no. C, pp. 428–435, 2015. [12] V. Hajisalem and S. Babaie, “A hybrid intrusion detection system based on ABC-AFS algorithm for misuse and anomaly detection,” Computer Networks, vol. 136, pp. 37–50, 2018. [13] C. Khammassi and S. Krichen, “A GA-LR wrapper approach for feature selection in network intrusion detection,” Comput. Secur., vol. 70, pp. 255–277, 2017. [14] M. R. Gauthama Raman, N. Somu, K. Kirthivasan, R. Liscano, and V. S. Shankar Sriram, “An efficient intrusion detection system based on hypergraph - Genetic algorithm for parameter optimization and feature selection in support vector machine,” Knowledge-Based Syst., vol. 134, pp. 1–12, 2017. [15] S. Shitharth and D. Prince Winston, “An enhanced optimization based algorithm for intrusion detection in SCADA network,” Comput. Secur., vol. 70, pp. 16–26, 2017. [16] S. M. Hosseini Bamakan, H. Wang, T. Yingjie, and Y. Shi, “An effective intrusion detection framework based on MCLP/SVM optimized by time-varying chaos particle swarm optimization,” Neurocomputing, vol. 199, pp. 90–102, 2016. [17] D. C. Le and A. N. Zincir-Heywood, “Evaluating insider threat detection workflow using supervised and unsupervised learning,” in IEEE Security and Privacy Workshops, 2018. [18] P. A. Legg, O. Buckley, M. Goldsmith, and S. Creese, “Automated insider threat detection system using user and role-based profile assessment,” IEEE Systems Journal, vol. 11, no. 2, 2017. [19] A. Tuor, S. Kaplan, B. Hutchinson, N. Nichols, and S. Robinson, “Deep learning for unsupervised insider threat detection in structured cybersecurity data streams,” in AAAI Workshop on AI for CyberSec., 2017. [20] B. Bose, B. Avasarala, S. Tirthapura, Y. Y. Chung, and D. Steiner, “Detecting insider threats using radish: A system for real-time anomaly detection in heterogeneous data streams,” IEEE Systems Journal, 2017.
Copyright
Copyright © 2023 Dinesh AR, Dr. Pradeep Udupa. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET50250
Publish Date : 2023-04-10
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online