

Ijraset Journal For Research in Applied Science and Engineering Technology
GAN-Based Super Resolution Algorithm for High-Quality Image Enhancement
Authors: Anjali Singh, Chaitali Choudhary, Dr. Jyothi Pillai
DOI Link: https://doi.org/10.22214/ijraset.2024.61882
Certificate: View Certificate
Abstract
Super Resolution: Leveraging investigates the trans- formative potential of Generative Adversarial Networks (GANs) in the context of super resolution, utilizing state-of-the-art algorithms to achieve high-quality image enhancement. The study encompasses a comprehensive analysis of GAN architectures such as SRGAN, ESRGAN, and others, exploring their strengths, limitations, and practical applications. The proposed methodology delves into dataset selection, preprocessing techniques, and the integration of advanced algorithms within the GAN framework. It evaluates the quantitative and perceptual performance of these techniques, addressing challenges and proposing avenues for future research. The findings contribute to the evolving landscape of GAN-based super resolution, offering insights for researchers and practitioners in advancing image enhancement technologies.
Introduction
I. INTRODUCTION
Super-resolution imaging is a process used to enhance the resolution and quality of an image beyond its original level. The goal is to generate a higher-resolution image from one or more low-resolution input images. This technique is crucial in various fields, including computer vision, medical imaging, surveillance, and photography, where detailed and clear visuals are essential. Low-resolution images may lack fine details and appear blurry, making it challenging to extract valuable information or achieve optimal visual quality. Super-resolution techniques aim to address this limitation by reconstructing a higher-resolution version of the image, providing a clearer and more detailed representation.
GANs are the latest frameworks used in advanced machine learning and deep learning applied fields, which were intro- duced by Goodefellow. GANs have two parts: a generator for generating images and a discriminator for checking their authenticity, and they work in competitive mode to validate each other, as explained below:
- Generator: The generator creates multiple synthetic pieces of content that resemble real data. It starts with random noise as input and gradually improves its ability to generate more realistic data after training. The generator is trained to create data that is indistinguishable from real data.
- Discriminator: The discriminator distinguishes between the data generated by the generator as input data and real data. Its goal is to distinguish whether the generated data is real or fake.
The training process for GANs involves constant feedback training between the generator and discriminator. The generator aims to improve its generation capabilities to fool the discriminator, while the discriminator strives to become better at distinguishing real data from generated data. This adversarial training process continues until the generator produces data that is so realistic that the discriminator can’t differentiate between real and fake data. GANs have numerous applications, such as image generation, image-to-image translation, super- resolution, style transfer, and more. It has made significant contributions to the field of deep learning and has been instrumental in generating high-quality synthetic data. Super-resolution in the context of generative adversarial networks (GANs) refers to the use of GANs to enhance the resolution and quality of images. It’s a technique that takes a low-resolution image and generates a higher resolution version of that image, effectively up scaling it while preserving or enhancing its visual details. GANs are employed to learn com- plex mappings from low-resolution to high-resolution image spaces. The generator network takes a low-resolution image as input and produces a corresponding high-resolution output. The discriminator then evaluates the generated high-resolution image against real high-resolution images, providing feedback to the generator for further improvement.
The iterative adversarial training process refines the generator’s ability to produce realistic and visually pleasing, high- resolution images. The ultimate goal is to generate images with enhanced details, sharper edges, and finer textures, making them visually comparable to or indistinguishable from native high-resolution images. Super-resolution is essential in various applications where higher image quality is required, such as medical imaging, surveillance, satellite imagery, and enhanc- ing the visual appeal of images and videos.
II. RELATED WORK
Chauhan et al. [1] comprehensive review on deep learning- based single-image super-resolution (SISR) provides a thor- ough examination of the advancements and methodologies within this domain. Single-image super-resolution has gar- nered significant attention due to its ability to enhance the resolution and quality of low-resolution images, benefiting various applications such as medical imaging, surveillance, and satellite imagery analysis. The authors highlight the evo- lution of SISR techniques from traditional methods to state-of- the-art deep learning approaches, emphasizing the significant performance improvements achieved by deep learning models. The review delineates the fundamental challenges encoun- tered in SISR, including the balance between computational complexity and performance, as well as issues related to generating high-quality super-resolved images without intro- ducing artifacts or distortion. Chauhan et al. [1] meticulously categorize existing deep learning-based SISR methods based on their underlying architectures, such as convolutional neural networks (CNNs), generative adversarial networks (GANs), and recursive networks. This classification enables a compre- hensive understanding of the diverse approaches adopted to tackle the SISR problem.
Furthermore, the review critically analyzes the strengths and limitations of different deep learning architectures employed for SISR, shedding light on their respective capabilities in handling various image degradation factors and scale factors. The authors delve into the intricacies of loss functions, regular- ization techniques, and optimization strategies utilized in SISR models, elucidating their impact on the final super-resolved image quality.
Moreover, Chauhan et al. [1] discuss the challenges associated with real-world SISR applications, such as handling diverse image content, addressing scalability issues, and en- suring computational efficiency for practical deployment. The review also explores emerging trends and future directions in SISR research, including the integration of domain knowl- edge, leveraging attention mechanisms, and incorporating self- supervised learning paradigms to enhance model generaliza- tion and robustness.
A. Loss Functions
A loss function (also known as a cost function or objec- tive function) is a mathematical measure that quantifies the difference between the predicted output of a neural network and the actual target values. The goal during the training of a deep learning model is to minimize this loss function. The loss function essentially computes a single scalar value that represents how the model is performing on a particular set of input data. It encapsulates the error or discrepancy between the predicted values and the ground truth, providing a measure of the model’s accuracy. The optimization process involves finding the set of model parameters that minimize this loss across the entire training data set.


Fu et al. [2] A crucial task in computer vision is picture super-resolution, which entails enhancing image details to obtain a greater spatial resolution than the original. Fine details are frequently lost in the process of producing vi- sually appealing outcomes using traditional approaches. Im- age Super-Resolution (SR) has witnessed significant advance- ments, particularly with the advent of Generative Adversarial Networks (GANs). It provides an overview of the state-of- the-art techniques in image super-resolution, focusing on the application of GANs. GANs, have emerged as a powerful tool for generating high-quality, realistic images, and the application to SR tasks has garnered attention for producing vi- sually impressive results. This paper explores the foundational concepts of GANs, their integration into the super-resolution framework, and highlights key contributions and challenges in this evolving field.
Liu et al. [3]a novel approach for real-time image super- resolution leveraging a Self-Attention Negative Feedback Net- work (SANFNet). It achieved high-quality, super-resolved images with reduced computational complexity, enabling real- time applications. The proposed SANFNet integrates self- attention mechanisms and negative feedback mechanisms within a neural network architecture, harnessing the synergies between these components for efficient and effective super- resolution. The architecture of the proposed SANFNet de- scribes how self-attention mechanisms are employed to capture long-range dependencies in the input images, and negative feedback mechanisms are incorporated to iterative refine the super-resolved output. The synergy between these components is explained in the context of achieving real-time performance without sacrificing image quality.
B. Methodologies
- Real-time Image SR Network Model: A real-time im- age super-resolution (SR) network model is a deep learning architecture designed to enhance the resolution of images in real-time. The primary goal is to provide a computation- ally efficient solution that can produce high-quality, detailed images promptly. Real-time applications demand low-latency processing, making it essential for the SR model to achieve rapid and efficient upscaling without compromising the quality of the output.
- Feature Extraction Module and Negative Feedback Module: A Feature Extraction Module is a component within a neural network architecture designed to automatically identify and extract relevant features or patterns from raw input data. In image processing, this module analyzes input images and captures important visual characteristics, such as edges, tex- tures, or shapes, that are essential for the network to make accurate predictions or perform specific tasks. A Negative Feedback Module is a component within a neural network or control system that introduces corrective signals based on the difference between the predicted output and the desired or target output. It aim to improve the accuracy and convergence of the model during training.
- Self-attention Mechanism Reconstruction Module: A Self-Attention Mechanism Reconstruction Module is a com- ponent within a neural network architecture designed to incor- porate self-attention mechanisms for enhanced feature capture and reconstruction capabilities. The module combines the strengths of self-attention, which allows the model to focus on different parts of the input sequence when making predictions, with a reconstruction process that aims to generate a faithful representation of the original input.
- Network Model Algorithm: The network model algo- rithm typically refers to the specific set of rules, procedures, or computations that a neural network employs to transform input data into meaningful output. In the context of deep learning and neural networks, an algorithm refers to the mathematical and computational processes that take place within the layers of the network to learn from data and make predictions or classifications.
Shafique et al. [4] explore the utilization of deep learning methodologies for change detection in remote sensing im- agery. Change detection, a critical task in monitoring land cover transformations and environmental changes, has seen significant advancements with the integration of deep learning techniques. It surveys and analyzes various deep learning- based models, architectures, and strategies employed in change detection applications, offering insights into their strengths, limitations, and potential future directions. The importance of change detection in remote sensing and the evolution of methods. It sets the stage for the review by highlighting the emergence of deep learning as a powerful paradigm for handling complex feature representations in remote sensing imagery.
Wang et al. [5] The fusion of Generative Adversarial Net- works (GANs) with super-resolution techniques has emerged as a trans-formative approach for enhancing the spatial resolu- tion of optical remote sensing images. The demand for high- resolution satellite imagery for various applications, including urban planning, environmental monitoring, and disaster man- agement, has driven the exploration of innovative solutions to overcome the inherent limitations of conventional imaging systems. Optical remote sensing images, acquired from satel- lites and other aerial platforms, provide invaluable information for decision-makers across diverse domains. However, the inherent trade-off between spatial resolution and coverage area poses a challenge. Super-resolution techniques, leveraging the power of deep learning and GANs, offer a promising avenue to address this challenge by generating high-resolution images from their lower-resolution counterparts.
Guerreiro et al. [6] The computational process of improving the spatial resolution of an image, aims to produce a higher- resolution version from a lower-resolution input. In medical imaging, particularly magnetic resonance imaging (MRI), the demand for enhanced image clarity and finer anatomical de- tails has led to the exploration of innovative methods. One such approach leverages Generative Adversarial Networks (GANs), a class of deep learning models designed for data generation tasks. The application of GANs to super-resolution in MRI involves training the model on pairs of low-resolution and high-resolution MRI images. The generator learns to map the low-resolution input space to the high-resolution output space, capturing intricate details that may be critical for accurate medical diagnoses. During training, the adversarial process ensures that the generated images exhibit realistic features, enhancing both structural fidelity and visual quality.
Ahmad et al. [7] GAN architecture incorporates innovative design principles to address the unique challenges posed by medical imaging data. Leveraging the adversarial training paradigm, the generator network is trained to transform low- resolution medical images into high-resolution counterparts. This adversarial process ensures that the generated images not only exhibit enhanced spatial details but also maintain the structural integrity crucial for medical interpretation.
- Architectural Innovation: GANs architecture is tailored to the idiosyncrasies of medical imaging data.It cap- tures intricate features and structural nuances present in medical images, ensuring the generation of realistic and clinically relevant high-resolution counterparts.
- Loss Function Enhancement: Loss function specifically tailored for medical image super-resolution. It incor- porates domain-specific considerations, accounting for the importance of preserving anatomical details and minimizing artifacts in the generated high-resolution images.
- Robust Evaluation Metrics: Recognizing the critical need for robust evaluation in medical imaging applica- tions, the proposed metrics are designed to assess the clinical utility of the generated high-resolution images, aligning with the specific diagnostic requirements of medical practitioners.
Wang et al. [8] The acquisition of high-resolution remote sensing imagery is essential for a myriad of applications, ranging from urban planning and environmental monitoring to disaster response and precision agriculture. As the demand for finer spatial details in remote sensing imagery inten- sifies, so does the need for advanced image enhancement techniques. Deep learning, particularly convolutional neural networks (CNNs), has emerged as a transformative paradigm for addressing the critical task of super-resolution in remote sensing images.The ultimate aim is to propel advancements in remote sensing image super-resolution, fostering applications that require precise and high-fidelity Earth observation data.
- Survey of Architectures: It provides an in-depth survey of various deep learning architectures, exploring their strengths, limitations, and applications in the context of remote sensing super-resolution.It includes examining CNNs, recurrent neural networks (RNNs), and attention mechanisms.
- Analysis of Methodological Components: Scrutinize the methodological components crucial for effective remote sensing super-resolution, including loss functions, op- timization strategies, and transfer learning approaches. Evaluate their impact on model performance and gen- eralization across diverse geographic regions and sensor types.
- Assessment of Data Sets and Benchmarks: Evaluate the suitability and representatives of widely-used re- mote sensing data sets and benchmarks for assessing super-resolution models. Consider spatial and spectral diversity, sensor characteristics, and addressing potential biases in existing evaluations.
Zhu et al. [9] Image super-resolution has witnessed sub- stantial advancements is the integration of deep learning techniques, which explore the landscape of image super- resolution methodologies, focus on GAN-based approaches, and highlight the significance of a novel quality loss metric for perceptual enhancement.
- Deep Learning in Image Super-Resolution: The integra- tion of deep learning, especially convolutional neural networks (CNNs), has been pivotal in addressing the challenge of enhancing spatial resolution in images. GANs, known for their ability to generate realistic images, have gained prominence in the super-resolution domain. The efficiency of GANs in capturing fine de- tails and generating visually convincing high-resolution images from lower-resolution inputs
- Challenges in Perceptual Quality Assessment: It lies in quantifying perceptual quality accurately, which often falls short of capturing the subtleties of human visual perception. Prior research has highlighted the impor- tance of developing novel quality metrics that align with human judgment, emphasizing the need for com- prehensive evaluation frameworks to assess perceptual improvements.
- GANs for Image Super-Resolution: The adversarial training paradigm employed by GANs enables the gen- eration of high-resolution images with realistic textures and structures. It persists in achieving a balance between improved resolution and enhanced perceptual quality. Existing GAN-based super-resolution methods have laid the groundwork for advancements, but there remains room for innovative approaches.
- Novel Quality Loss Metrics: The metrics aim to ad- dress limitations in existing assessment techniques by considering perceptual aspects that traditional metrics overlook. This represents a significant step toward more accurate and holistic evaluations of super-resolution results.
- Integration of GANs with Novel Quality Loss: It con- tributes to this evolving landscape by proposing a GAN- based super-resolution approach coupled with a novel quality loss metric. The integration of GANs addresses spatial enhancement, while the novel metric aims to comprehensively assess perceptual improvements. This amalgamation reflects a nuanced understanding of both the technological and perceptual aspects of image super- resolution.
Jiang et al. [10] . The integration of CNN architectures, transfer learning, and multi-temporal data fusion has propelled the accuracy and applicability of change detection models. The synergy between deep learning and change detection holds great promise for advancing our understanding of dynamic en vironmental processes. Change detection from high-resolution remote sensing images is a critical task with applications ranging from urban planning to environmental monitoring. It provides an overview of existing research, focusing on deep learning-based approaches for change detection in high- resolution remote sensing imagery.
- Emergence of Deep Learning in Change Detection: The advent of deep learning marked a paradigm shift in change detection methodologies. CNNs, with their capacity to learn hierarchical representations, exhibited promise in capturing complex spatial dependencies and semantic information. It explored the application of deep learning for change detection, showcasing improved ac- curacy and robustness compared to traditional methods.
- CNN Architectures for Change Detection: It has ex- plored the effectiveness of well-established architectures like U-Net, Fully Convolutional Networks (FCNs), and their variants. These architectures leverage the spatial and contextual information present in high-resolution remote sensing images, contributing to more accurate change detection results.
- Transfer Learning and Pre-trained Models:Transfer learning has emerged as a powerful strategy in change detection. Pre-trained models on large-scale datasets, such as Image-Net, have been fine-tuned for change detection tasks. This transfer of knowledge enables the networks to adapt to specific features and patterns in high-resolution remote sensing images, enhancing their ability to detect changes.
- Multi-temporal Data Fusion: It has investigated the fusion of temporal information using recurrent neural networks (RNNs) and long short-term memory networks (LSTMs). These architectures excel in capturing sequen- tial dependencies, allowing for more accurate modeling of temporal changes.
III. PROPOSED FRAMEWORK
Generative Adversarial Networks (GANs) have emerged as a trans formative force in the realm of image processing, particularly in the domain of super resolution. This investigates the application of state-of-the-art algorithms within the GAN framework to push the boundaries of super-resolution capabilities. Focusing on the advancements made in algorithms such as SRGAN, ESRGAN, and other cutting-edge approaches, our study aims to provide a comprehensive understanding of the current landscape of GAN-based super resolution techniques. The research methodology encompasses several key steps. First, a diverse and representative data set is curated, incorporating high-resolution images across various domains. Prepossessing techniques are then applied to enhance dataset quality and diversity. The selection of a GAN architecture is a critical decision, and our paper thoroughly evaluates the performance of different architectures, considering factors such as computational efficiency and the ability to capture intricate details. The proposed methodology includes the design of a customized loss function that strikes a balance between perceptual quality and traditional fidelity metrics. The architecture of the generator and discriminator networks is carefully crafted, leveraging attention mechanisms and skip connections to capture both global and local features effectively. A progressive training strategy is implemented to stabilize GAN training, and hyperparameter tuning is conducted to optimize model performance. Explores the incorporation of data augmentation during training, aiming to improve the model’s robustness to diverse input images. Evaluation metrics such as Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSI) are employed alongside qualitative assessments for a comprehensive evaluation of the proposed super resolution techniques.
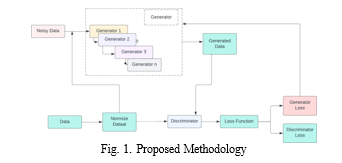
The proposed methodology serves as an advancement in GAN-based super resolution, offering a foundation for contin- ued exploration and innovation.
- Data set Selection: Begin by curating a diverse and representative data set containing high-resolution images relevant to the target application. Incorporate a mix of image types, ensuring the inclusion of complex textures, patterns, and structures.
- Preprocessing: Implement preprocessing techniques such as normalization, data augmentation, and noise reduction to enhance the quality and diversity of the training data set. Ensure careful handling of artifacts, outliers, and potential biases in the data set.
- GAN Architecture Selection: Evaluate and choose a suitable GAN architecture for super resolution. Common architectures include SRGAN, ESRGAN, and ProGAN. Some factors, such as computational efficiency, model complexity, and the ability to handle diverse image content.
- Loss Function Design: Develop a tailored loss function that balances perceptual quality and traditional fidelity metrics like content loss, adversarial loss, and feature loss. Incorporate perceptual loss based on deep feature representations to align the generated images with high- level content.
- Generator and Discriminator Network Design: Design the generator network with attention mechanisms and skip connections to capture both global and local details effectively. Fine-tune the discriminator network to distinguish between high-resolution and generated images, promoting adversarial learning.
- Training Strategy: Implement a progressive training strategy to stabilize GAN training. Start with lower res- olutions and progressively increase the output resolution during training. Utilize techniques such as gradient clip- ping, learning rate scheduling, and batch normalization for stable and efficient convergence.
- Hyperparameter Tuning: Tune hyperparameters such as learning rates, batch sizes, and regularization terms to optimize model performance. Employ cross-validation techniques to ensure robustness and generalization to diverse datasets.
- Data Augmentation During Training: Apply data aug- mentation techniques such as random cropping, rotation, and flipping during training to enhance the model’s ability to handle variations in input images.
- Evaluation Metrics: Utilize a combination of quantitative metrics (PSNR, SSIM) and qualitative evaluations through visual comparisons to assess the performance of the model comprehensively.
- Post-processing Techniques: Investigate post-processing techniques such as gradient-based refinement or demon- ising to further enhance the visual quality of generated high-resolution images.
- Validation and Generalization: Perform extensive validation on separate validation data sets to ensure the model’s generalization to unseen data. Explore transfer learning techniques to adapt the model to specific do- mains or applications. By systematically incorporating these steps into the proposed methodology, it aims to advance GAN-based super resolution techniques, producing high-quality, realistic, and visually pleasing high- resolution images across a diverse range of applications.
A. Super Resolution with CNNs and GANs
Super resolution, the task of enhancing the resolution of low-resolution images, has witnessed remarkable advancements through the collaborative integration of Convolutional Neural Networks (CNNs) and Generative Adversarial Net- works (GANs). The synergistic relationship between CNNs and GANs, leverages their complementary strengths to achieve unprecedented levels of image enhancement. The methodology involves a two-fold approach: a Convolutional Neural Network responsible for extracting intricate features and a Generative Adversarial Network facilitating the generation of high- fidelity, realistic images. The CNN serves as the backbone for understanding complex patterns in low-resolution inputs, while the GAN acts as a generator to transform these inputs into visually compelling, high-resolution outputs. The CNN architecture is meticulously designed to capture both local and global features, employing deep layers with skip connections to enhance the network’s ability to reconstruct finer details. Transfer learning techniques are explored, allowing the CNN to leverage knowledge gained from pre-trained models on large-scale data sets. The GAN component introduces adversarial training to the super resolution task. The generator network aims to produce high-resolution images, while the discriminator network is trained to distinguish between generated and real high-resolution images. This adversarial process not only improves the perceptual quality of the generated images but also encourages the model to produce outputs that are indistinguishable from true high-resolution images. To ensure the stability and efficiency of training, techniques such as progressive training, gradient clipping, and learning rate scheduling are employed. Additionally, a carefully designed loss function encompasses both traditional fidelity metrics and perceptual metrics to strike a balance between quantitative accuracy and qualitative visual appeal.
Evaluates the proposed CNN-GAN hybrid model on diverse data sets, employing rigorous quantitative metrics such as Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSI).
Visual assessments are conducted to qualitatively analyze the model’s ability to reconstruct fine details, textures, and edges in comparison to existing state-of-the-art methods.
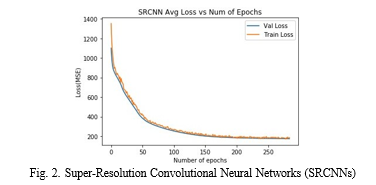
- Super-Resolution Convolutional Neural Network: Super-Resolution Convolutional Neural Networks (SRCNNs) have emerged as a transformative class of deep learning models designed to address the challenge of enhancing the resolution of low-quality images. Delves into the intricacies of SRCNNs, exploring their architecture, training methodologies, and applications in the domain of image super resolution. The core of an SRCNN lies in its ability to learn com- plex mappings between low-resolution and high-resolution image pairs. The architecture typically comprises three main components: a patch extraction layer, a non-linear mapping layer, and a reconstruction layer. The patch extraction layer serves to capture local features, while the non-linear mapping layer learns the intricate relationships between low and high- resolution patches. The final reconstruction layer synthesizes these mappings into a high-resolution output. Training an SRCNN involves utilizing a dataset containing paired low and high-resolution images. The network is optimized to minimize the difference between its predicted high-resolution output and the ground truth. Transfer learning techniques, initialization with pre-trained models, and data augmentation are often employed to enhance the network’s ability to generalize across diverse image content. The depth of the network which is measured by the number of layers in a critical parameter and architectures with varying depths strike a balance between both computational efficiency and performance. The performance of SRCNNs through both quantitative metrics and qualitative visual assessments. Peak Signal-to-Noise Ratio (PSNR) and Structural Similarity Index (SSI) are commonly used met- rics for quantitative evaluation, while qualitative assessments involve visual comparisons of generated high-resolution im- ages against ground truth images. Applications of SRCNNs span across diverse domains, including but not limited to medical imaging, satellite imagery, surveillance, and digital photography. The ability of SRCNNs to uncover finer details, reconstruct textures, and enhance overall visual quality makes them invaluable in scenarios where high-resolution imagery is crucial.
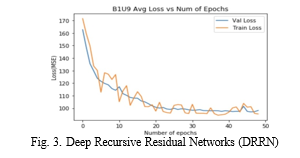
2. Deep Recursive Residual Network: Deep Recursive Residual Networks (DRRN) represent a novel and powerful approach to image super-resolution, harnessing the benefits of both deep architectures and recursive connections. The delves into the intricacies of DRRNs, investigating their architecture, recursive design principles, and the impact of depth on the enhancement of low-resolution images. The architecture of a DRRN is characterized by a deep stack of residual blocks, each incorporating recursive connections. Residual learning allows for the training of exceptionally deep networks by facilitating the direct learning of residual information. Recursive connections further build upon this foundation, enabling the network to iterative refine its predictions and progressively capture intricate details in a hierarchical manner. Explores the significance of depth in DRRNs, analyzing how an increased number of residual blocks contributes to the model’s capacity to learn complex mappings between low and high-resolution image pairs. Techniques such as skip connections and batch normalization are employed to enhance training stability and encourage the effective flow of information through the network. Training a DRRN involves utilizing paired low and high-resolution datasets and optimizing the network parameters to minimize the difference between predicted high-resolution outputs and ground truth images. Transfer learning strategies and pre-training on large-scale datasets are explored to improve the network’s ability to generalize across diverse image content. Quantitative metrics such as Peak Signal-to- Noise Ratio (PSNR) and Structural Similarity Index (SSI) are employed to assess the performance of DRRNs.
Additionally, qualitative evaluations involve visual comparisons between generated high-resolution images and ground truth images, providing insights into the network’s ability to preserve details and textures. It focus to real-world applications, emphasizing the versatility of DRRNs in domains such as medical imaging, satellite imagery, and digital photography. The ability of DR- RNs to uncover finer details, adapt to diverse image content, and generalize well across various scenarios underscores their potential impact in practical image enhancement scenarios.
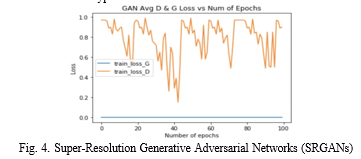
3. Super-Resolution Generative Adversarial Networks: Super-Resolution Generative Adversarial Networks (SR- GANs) have emerged as a groundbreaking paradigm in the field of image processing, particularly in addressing the challenge of enhancing the resolution of low-quality images explores the architecture, training methodologies, and applications of SRGANs, shedding light on their transformative role in image super-resolution. GANs consist of a generator and a discriminator engaged in adversarial simultaneously training, fostering a competition that drives the generator to produce high-fidelity, visually pleasing images that are indistinguishable from their true high-resolution counterparts. The adversarial process adds a perceptual quality dimension to the super-resolution task, surpassing traditional metrics by emphasizing human-like visual appeal.
4. Conditional Generative Adversarial Networks: Conditional Generative Adversarial Networks (cGANs) a pivotal advancement in the realm of generative models, providing a targeted and controlled approach to image generation. Investigates the architecture, training principles, and applications of cGANs, emphasizing their capacity to produce images conditioned on specific input attributes. The architecture of a cGAN extends the traditional Generative Adversarial Network (GAN) by introducing conditional information. In a typical
cGAN setup, both the generator and the discriminator receive additional input parameters, often referred to as conditioning variables or labels. These labels guide the generation process, allowing users to specify desired characteristics such as image category, style, or other semantic attributes. Training a cGAN involves presenting both real and generated images to the discriminator along with their corresponding condition labels. The generator strives to produce images that not only fool the discriminator into believing they are real but also adhere to the specified conditions. This conditional aspect enhances the flexibility and applicability of cGANs across diverse domains. The ability to conditionally generate images based on specific attributes makes cGANs valuable in scenarios where fine- grained control over the generated content is essential. Insights gained to guide researchers and practitioners in harnessing the precision and versatility of cGANs for tailored image generation tasks, opening avenues for advancements in conditional image synthesis and manipulation.
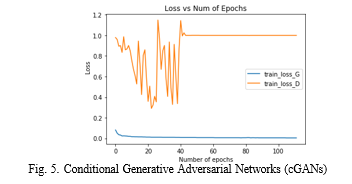
Conclusion
In this paper, We provide a comprehensive exploration into the realm of Super Resolution techniques, particularly focus- ing on the transformative impact of Generative Adversarial Networks (GANs) and state-of-the-art algorithms. Through the analysis of architectures such as SRGAN, ESRGAN, and others investigation has unveiled the remarkable capabilities of GAN-based approaches in enhancing the resolution of low- quality images. Our proposed methodology has guided the selection of diverse and representative datasets, preprocessing techniques, and the integration of cutting-edge algorithms within the GAN framework. The meticulously designed experiments and evaluations have not only showcased the quantitative advancements in terms of metrics like Peak Signal-to- Noise Ratio (PSNR) and Structural Similarity Index (SSI) but have also emphasized the perceptual quality and visual appeal achieved through GAN-based super resolution. The proposed methodology and experimentation outcomes serve as a road map for future advancements in GAN-based super resolution, offering a foundation for continued innovation in the ever- evolving field of image enhancement. As we navigate the intersection of GANs and super resolution, it becomes evident that the synergy between advanced algorithms and generative adversarial networks unlocks a realm of possibilities. From applications in medical imaging to satellite imagery, the impact of GAN-based super resolution is felt across diverse domains, promising to reshape the way we perceive and process visual information.
References
[1] K. Chauhan et al., ”Deep Learning-Based Single-Image Super- Resolution: A Comprehensive Review,” in IEEE Access, vol. 11, pp. 21811-21830, 2023, doi: 10.1109/ACCESS.2023.3251396. [2] Fu, Kui, Jiansheng Peng, Hanxiao Zhang, Xiaoliang Wang, and Frank Jiang. ”Image super-resolution based on generative adversarial networks: a brief review.” (2020). [3] Liu, Xiangbin, et al. ”Self-attention negative feedback network for real-time image super-resolution.” Journal of King Saud University- Computer and Information Sciences 34.8 (2022): 6179-6186. [4] Shafique, Ayesha, Guo Cao, Zia Khan, Muhammad Asad, and Muham- mad Aslam. ”Deep learning-based change detection in remote sensing images: A review.” Remote Sensing 14, no. 4 (2022): 871. [5] Wang, Xuan, Lijun Sun, Abdellah Chehri, and Yongchao Song. ”A Review of GAN-Based Super-Resolution Reconstruction for Optical Remote Sensing Images.” Remote Sensing 15, no. 20 (2023): 5062. [6] Guerreiro, Joa˜o, Pedro Toma´s, Nuno Garcia, and Helena Aidos. ”Super- resolution of magnetic resonance images using Generative Adversar- ial Networks.” Computerized Medical Imaging and Graphics (2023): 102280. [7] Ahmad, Waqar, Hazrat Ali, Zubair Shah, and Shoaib Azmat. ”A new generative adversarial network for medical images super resolution.” Scientific Reports 12, no. 1 (2022): 9533. [8] Wang, Peijuan, Bulent Bayram, and Elif Sertel. ”A comprehensive review on deep learning based remote sensing image super-resolution methods.” Earth-Science Reviews (2022): 104110. [9] Zhu, Xining, Lin Zhang, Lijun Zhang, Xiao Liu, Ying Shen, and Shengjie Zhao. ”GAN-based image super-resolution with a novel quality loss.” Mathematical Problems in Engineering 2020 (2020): 1-12. [10] Jiang, Huiwei, Min Peng, Yuanjun Zhong, Haofeng Xie, Zemin Hao, Jingming Lin, Xiaoli Ma, and Xiangyun Hu. ”A survey on deep learning- based change detection from high-resolution remote sensing images.” Remote Sensing 14, no. 7 (2022): 1552. [11] Zhang, Y.; Li, K.; Li, K.; Wang, L.; Zhong, B. et al. (2018): Image super-resolution using very deep residual channel attention networks. European Conference on Computer Vision, pp. 286-301. [12] Zhu, X.; Cheng, Y.; Peng, J.; Wang, R.; Le, M. et al. (2020): Super- resolved image perceptual quality improvement via multifeature discrim- inators. Journal of Electronic Imaging, vol. 29, no. 1, pp. 013017. [13] Zhong, S.; Zhou, S. (2020): Optimizing generative adversarial networks for image super resolution via latent space regularization. arXiv preprint arXiv:2001.08126. [14] Hayatbini, Negin, Bailey Kong, Kuo-lin Hsu, Phu Nguyen, Soroosh Sorooshian, Graeme Stephens, Charless Fowlkes, Ramakrishna Nemani, and Sangram Ganguly. ”Conditional generative adversarial networks (cGANs) for near real-time precipitation estimation from multispectral GOES-16 satellite imageries—PERSIANN-cGAN.” Remote Sensing 11, no. 19 (2019): 2193. [15] Demiray, Bekir Z., Muhammed Sit, and Ibrahim Demir. ”D-SRGAN: DEM super-resolution with generative adversarial networks.” SN Com- puter Science 2 (2021): 1-11. [16] CS230 Stanford, https://github.com/cs230-stanford/, cs230-code- examples, 2018. [17] tyshiwo, Drrn CVPR17, https://github.com/tyshiwo/DRRNCVPR17, 2017. [18] Cimport matplotlib.pyplot as plt [18] leftthomas, Srgan, https://github.com/leftthomas/SRGAN, 2017. [19] znxlwm,pytorch-generative-modelcollections, https://github.com/znxlwm/pytorch-generative-model-collections, 2017.
Copyright
Copyright © 2024 Anjali Singh, Chaitali Choudhary, Dr. Jyothi Pillai. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET61882
Publish Date : 2024-05-10
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online