

Ijraset Journal For Research in Applied Science and Engineering Technology
Haptic Summarizer for Visually Impaired Using Rasberry PI
Authors: Gauri Dhanorkar, Minal Zope, Sanika Mane, Rudra Pingle, Ramit Desai
DOI Link: https://doi.org/10.22214/ijraset.2024.62551
Certificate: View Certificate
Abstract
The project endeavours to ameliorate the constraints inherent in conventional reading modalities for visually impaired individuals through the development of a self-contained reading apparatus. This device is designed to facilitate access to printed textual material while augmenting its capabilities with image captioning functionality, thus extending its applicability beyond mere textual content. To achieve this objective, the project will leverage sophisticated deep learning methodologies, including Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and ResNet architectures, for image analysis and caption generation tasks. Furthermore, optimization of the system will be carried out using stochastic gradient descent, ensuring optimal performance and efficacy in practical usage scenarios. Additionally, the device will include voice output capabilities for delivering prompts, notifications, and user interaction feedback, enhancing the overall usability and accessibility for users with visual impairments.
Introduction
I. INTRODUCTION
The project endeavours to revolutionize the reading experience for visually impaired individuals by introducing a state-of-the-art self-contained reading device powered by Raspberry Pi.
This device is meticulously designed to address the inherent limitations of conventional reading methods faced by the visually impaired community. By seamlessly integrating cutting-edge technologies such as text-to-speech (TTS) conversion, voice output capabilities, and advanced image captioning using deep learning techniques, the device not only enhances access to printed textual material but also expands its functionality to comprehend visual content.
Raspberry Pi, a small yet powerful single-board computer, serves as the core component of the reading device, providing the computational capabilities necessary for executing complex tasks with efficiency and precision. This versatile platform empowers developers to create innovative solutions tailored to specific needs, making it an ideal choice for developing assistive technologies like the proposed reading device.
The current scenario of reading for visually impaired individuals primarily relies on the Braille system, which poses challenges due to the limited availability of Braille materials. This limitation restricts the range of accessible content and hinders the independence of visually impaired individuals in accessing information. Consequently, there is a pressing need for innovative solutions that enable better manageable, eyes-free operation for reading tasks.
In response to this need, the project sets out to create a comprehensive reading device that empowers visually impaired individuals with a versatile tool for accessing and comprehending both textual and visual content. Leveraging sophisticated deep learning methodologies, including Convolutional Neural Networks (CNNs), Recurrent Neural Networks (RNNs), and ResNet architectures, the device excels in image analysis and caption generation tasks, thereby enriching the reading experience beyond traditional text-based approaches.
The integration of voice output capabilities further enhances the usability of the device by providing auditory prompts, notifications, and user interaction feedback. This not only improves accessibility but also fosters a seamless and intuitive user experience for individuals with visual impairments. Through meticulous optimization utilizing stochastic gradient descent, the project ensures that the device delivers optimal performance and efficacy in real-world usage scenarios. By bridging the gap between textual and visual information, this innovative reading device, powered by Raspberry Pi, is poised to make a significant impact in empowering visually impaired individuals to access and comprehend a broader range of content with greater independence and efficiency.
II. LITERATURE SURVEY
|
Author |
Technique |
Results |
Limitation |
|||||
|
”S. Srija, *P. Kawya, T. Akshara Reddy, M. Dhanalakshmi” |
Miniaturized Camera, Image Processing, Raspberry Pi, Vibration Mo tors. |
The Raspberry pi based wearable reader captures printed text as images and then segments the image to obtain the text alone. |
proposed work ad- dresses only upward deviations from the current text-line. |
|||||
|
”Megha P Arak- |
Raspberry Pi, |
The proposed so- |
A few extensions that |
|||||
|
eri, Keerthana |
Optical Charac- |
lution is to de- |
can be added to this |
|||||
|
N S,Madhura |
ter Recognition |
sign an inexpen- |
product are Speech In- |
|||||
|
M, Anusha |
(OCR), Object |
sive wearable de- |
teraction, Facial Ex- |
|||||
|
Sankar ,Tazeen |
Recognition, |
vice that uses com |
pression Recognition |
|||||
|
Munnavar[2008]” |
Text to Speech, |
puter vision to read |
and Human Face Rec- |
|||||
|
|
Language Trans- |
out any form of text |
ollection. |
|||||
|
|
lation.
|
around the user in various alignments and lighting conditions. |
|
|||||
|
”Usman Ma- sud 1,2, Tareq Saeed3, Hunida M. Malaikha4, UL Islam1, AND Ghulam Abbas1[2022]” |
Smart system, visual losses, biomedical sensor, object recognition, ten- sorflow, Viola Jones, ultrasonic sensor. |
we plan to add a text-to-speech system and embed it with the GSM module so that blind person can actually hear the directions in form of voice.
|
Limited object recog- nition, potential false alarms, limited depth perception, and de- pendency on technol- ogy. |
|||||
|
”Xiaochen |
assistive naviga- |
Based on the lo- |
Relies on depth cues, |
|||||
|
Zhang, Bing |
tion; semantic |
calization and the |
which may limit its |
|||||
|
Li, Samleo |
path planning; |
semantic digital |
performance in sce- |
|||||
|
L. Joseph, |
SLAM; wearable |
map, the user is |
narios where accurate |
|||||
|
Jizhong Xiao, Yi |
device |
navigated to the |
depth information is |
|||||
|
Sun andYingli |
|
desired room. The |
not available. |
|||||
|
Tian,J. Pablo |
|
user can be guided |
|
|||||
|
Mun˜oz, Chucai |
|
by the audio output |
|
|||||
|
Yi[2020]”
|
|
command to the destination easily and conveniently with usability humanistic audio interface. |
|
|||||
|
”Amey Hen- |
Assistive Tech- |
The Smart Cap |
the addition of |
|
||||
|
gle,NirajKulka- |
nologies, Rasp- |
acts as a con- |
more robust hard- |
|
||||
|
rni,Atharva |
berry Pi, Face |
versational agent |
ware support like |
|
||||
|
Kulka- |
Recognition, Im- |
bringing together |
GPUs will not |
|
||||
|
rni,Nachiket |
age Captioning, |
the disciplines of |
only improve the |
|
||||
|
Bavadekar |
Text Recog- |
Internet of Things |
device’s response |
|
||||
|
,Rutuja |
nition, OCR, |
and Deep Learn- |
time but also pave |
|
||||
|
Udyawar[2020]” |
News Scraping |
ing and provides |
the way for the |
|
||||
|
|
|
|
features like face |
inclusion of faster |
|
|||
|
|
|
|
recognition, im- |
and more accu- |
|
|||
|
|
|
|
age captioning, |
rate deep learning |
|
|||
|
|
|
|
text detection and |
models. OCR can |
|
|||
|
|
|
|
recognition, and |
be coupled with- |
|
|||
|
|
|
|
online newspaper |
Document Image |
|
|||
|
|
|
|
reading.
|
Analysis (DIA) for getting more optimal results. |
|
|||
|
”Anmol |
Raspberry |
Pi; |
Results of the |
It is during this |
|
|||
|
Bhat,Aneesh |
Object de- |
|
different modules |
process that sev- |
|
|||
|
C Rao,Anirud h |
tection; |
Text |
were generated and |
eral essentials in |
|
|||
|
Bhaskar,Adithya |
extraction; |
|
Analyzed for dif- |
the speaker’s deliv- |
|
|||
|
V,Prof. Pratiba |
Speech-to- |
|
ferent test inputs. |
ery are missed out. |
|
|||
|
D |
text; Natural |
The object detec- |
|
|
||||
|
|
Language Pro- |
tion classifier, as |
|
|
||||
|
|
cessing.
|
Mentioned before, was trained using two models. In the initial training run, with the ssdmobilenet v1 coco model, the accu- racy obtained was pretty less. |
|
|
||||
|
”1 S Gayathri, |
RFID reader, |
The merchandise is |
The technical |
|
||||
|
K.Jeyapiriya, |
Raspberry Pi, |
scanned by visually |
complexity of the |
|
||||
|
K.JeyaPrakash” |
loT, RFID scan- |
challenged people |
system, involving |
|
||||
|
|
ner.result. |
using RFID cards, |
Raspberry |
Pi, |
|
|||
|
|
|
and the audio is |
Bluetooth, |
and |
|
|||
|
|
|
transformed into |
IoT, could |
pose |
|
|||
|
|
|
voice by the Rasp- |
challenges |
for |
|
|||
|
|
|
berry Pi in figure |
maintenance |
and |
|
|||
|
|
|
3, which the person |
repair, which may |
|
||||
|
|
|
hears.
|
be particularly problematic for visually impaired users who depend on the technology. |
|
||||
|
”Simon L. |
propose a novel |
Four layers |
Complex mechan- |
|
||||
|
GAY 1, Edwige |
and inclusive |
achieved the |
ics, potential for |
|
||||
|
Pissaloux 2, |
haptic architec- |
highest accuracy of |
reduced precision, |
|
||||
|
Katerine Romeo |
ture to access |
98.60 in both train- |
and limited adapt- |
|
||||
|
2,AND NGOC- |
and interact |
ing and testing |
ability for 3D data. |
|
||||
|
TAN Troung 2. |
with 2D data, |
|
|
|
||||
|
[2021]”
|
relying on the force-feedback principle, and named Force- Feedback Tablet (F2T) |
|
|
|
||||
|
”Nathan |
wearable hap- |
Haptic Morse code |
Speed |
constraints, |
|
Dunkelberger, |
tics, language |
was explored using |
form |
factor limita- |
|
Student Mem- |
communication, |
an electrodynamic |
tions, |
and learning |
|
ber, IEEE, |
multi-sensory |
minishaker that |
curve |
challenges for |
|
Jennifer L. Sul- |
haptics, tactile |
represented dots or |
haptic language trans- |
|
|
livan, Member, |
device, phoneme |
dashes by the du- |
mission. |
|
|
IEEE, Joshua |
coding. |
ration of a fingertip |
|
|
|
Bradley,Indu Manickam, Gau- tam Dasarathy, Richard Bara- niuk, and Mar- cia K.[2011]” |
|
displacement.
|
|
|
|
”Arthur K. K. |
Automatic |
The multi- |
The low image reso- |
|
|
Wong, N. K. |
Flame Image |
threshold al- |
lution of 320x240 pix- |
|
|
Fong [2021]” |
Segmentation, |
gorithm with |
els may lead to inade- |
|
|
|
Image Recogni- |
Rayleigh distri- |
quate fire detection for |
|
|
|
tion, Tracking |
bution analysis |
small or distant fires. |
|
|
|
Fire Spread Di- |
(modified segmen- |
|
|
|
|
rection, Flame |
tation algorithm) |
|
|
|
|
Movement Pre- |
successfully im- |
|
|
|
|
diction.
|
proved flame image segmentation. |
|
|
III. RESEARCH LIMITATIONS
Research on a Raspberry Pi-based wearable reader aimed at aiding visually impaired individuals through haptic feedback encounters multifaceted limitations across technical, usability, environmental, accessibility, ethical, and evaluation domains. Technical constraints stemming from the Raspberry Pi's computational limitations, including processing power and memory restrictions, pose challenges for implementing sophisticated image processing and object recognition algorithms, potentially limiting the system's accuracy and responsiveness. Moreover, the precision and adaptability of haptic feedback mechanisms present usability hurdles, as users may require time to acclimate to the sensory cues, and feedback granularity might be insufficient for discerning intricate details. Wearability concerns arise from factors such as device size, weight, and comfort, impacting long-term user acceptance and adoption. Additionally, the device's performance may be influenced by environmental factors like lighting variations and obstacle detection reliability, affecting its effectiveness across diverse scenarios. Accessibility issues emerge concerning the device's affordability, technical complexity, and ethical considerations, including privacy safeguards and equitable access. Finally, evaluation limitations, such as small sample sizes and the need for extended longitudinal studies, challenge the comprehensive assessment of the device's efficacy, usability, and user satisfaction. Mitigating these limitations necessitates a holistic approach encompassing meticulous design iterations, extensive user testing and feedback integration, ethical guidelines adherence, and rigorous evaluation methodologies to ensure the device's practicality, effectiveness, and ethical integrity in assisting visually impaired individuals.
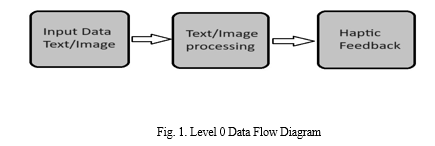
IV. PROPOSED WORK
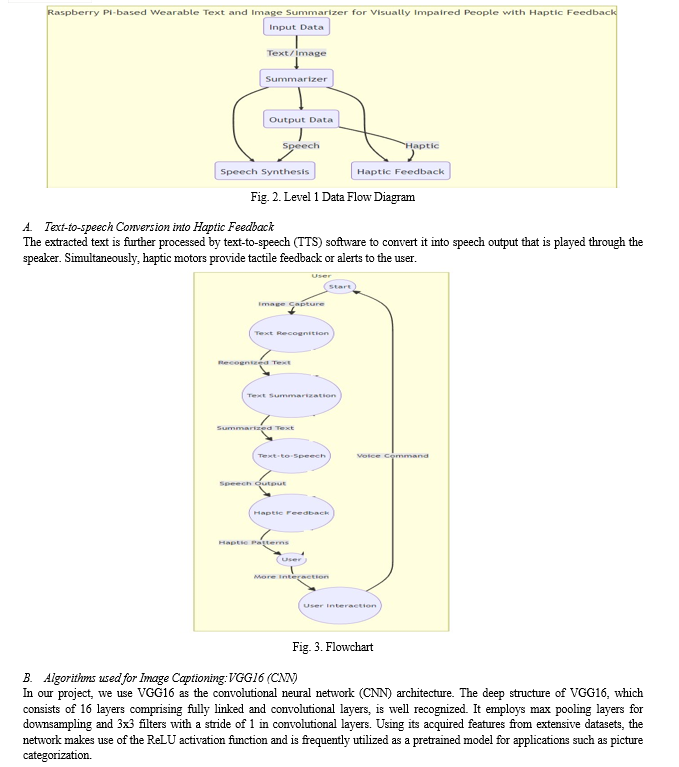
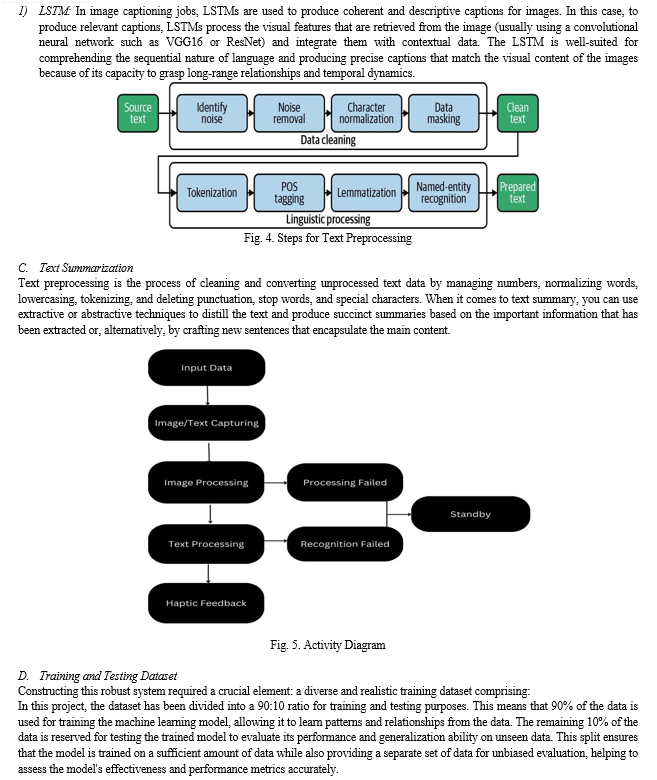
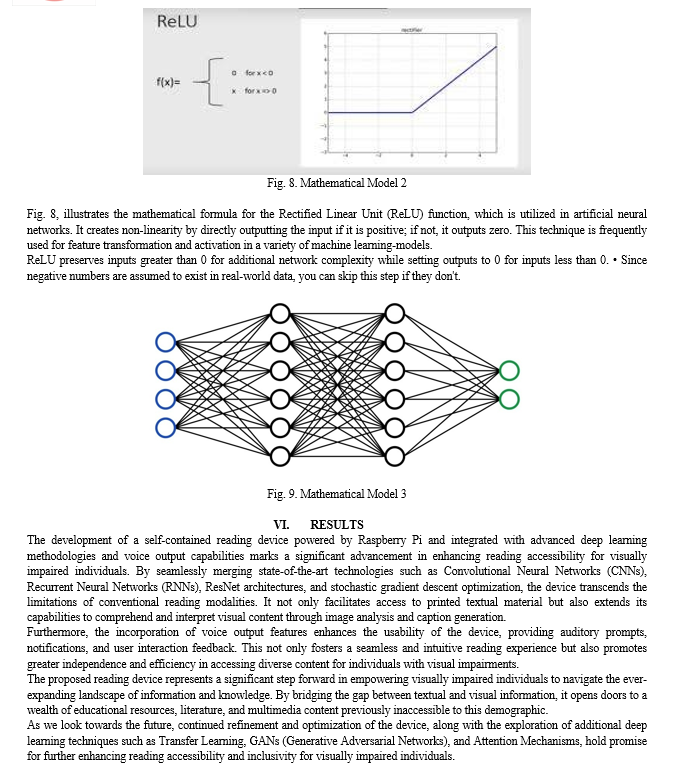
This innovative research combines state-of-the-art technologies in computer vision and deep neural networks to tackle critical challenges. The device's workflow encompasses tasks such as image capture, processing, text extraction, and conversion to speech, all integrated with feedback mechanisms through both speech and haptic interfaces.



VIII. CHALLENGES AND FUTURE SCOPE
The challenges faced by the project include technical complexity in integrating various technologies, ensuring accuracy and reliability of image captioning, designing an intuitive user interface, managing battery life and portability, addressing accessibility needs, balancing cost and affordability, complying with regulations, and gathering user feedback for iterative development. These challenges require a multidisciplinary approach and commitment to user-centered design principles to overcome and create a transformative reading device for visually impaired individuals.
the future scope of the project includes ongoing enhancement of features, miniaturization of hardware, integration with wearable technology, fostering collaborative platforms, personalization options, educational tools, remote assistance capabilities, and ensuring global accessibility. These advancements aim to continuously improve the reading experience and overall quality of life for visually impaired individuals.
Conclusion
In conclusion, the development of a wearable reader utilizing a high-resolution miniature camera, Raspberry Pi microcontroller, and vibration motors represents a pioneering solution to address the limitations faced by visually impaired individuals in accessing printed text. By enabling real-time image capture and processing, the device converts printed text into computerized format, enhancing accessibility and expanding learning resources beyond those available in Braille. The incorporation of tactile feedback through vibration motors aids users in maintaining reading orientation, while the conversion of text to audible speech offers a hands-free and versatile reading experience. This innovative device holds great potential to empower visually impaired users with increased independence and access to a diverse range of educational materials, thereby fostering greater inclusivity and opportunities for learning.
References
[1] J. N. Madhuri and R. Ganesh Kumar, ”Extractive Text Summarization Using Sentence Ranking,” 2019 International Conference on Data Science and Communication (Icon DSC), Bangalore, India, 2019, pp. 1-3, doi: 10.1109/IconDSC.2019.8817040. [2] Rahul, S. Adhikari and Monika, ”NLP based Machine Learning Approaches for Text Summarization,” 2020 Fourth International Con- ference on Computing Methodologies and Communication (ICCMC), Erode, India, 2020, pp. 535-538, doi: 10.1109/ICCMC48092.2020.ICCMC- 00099. [3] Rahul, S. Rauniyar and Monika, ”A Survey on Deep Learning based Various Methods Analysis of Text Summarization,” 2020 International Conference on Inventive Computation Technologies (ICICT), Coimbat- ore, India, 2020, pp. 113-116, doi: 10.1109/ICICT48043.2020.9112474. [4] P. Janjanam and C. P. Reddy, ”Text Summarization: An Essential Study,” 2019 International Conference on Computational Intelli- gence in Data Science (ICCIDS), Chennai, India, 2019, pp. 1-6, doi: 10.1109/ICCIDS.2019.8862030 [5] G. V. Madhuri Chandu, A. Premkumar, S. S. K and N. Sam- path, ”Extractive Approach For Query Based Text Summarization,” 2019 International Conference on Issues and Challenges in Intelligent Computing Techniques (ICICT), Ghaziabad, India, 2019, pp. 1-5, doi: 10.1109/ICICT46931.2019.8977708. [6] C. Xu, ”Research on Information Retrieval Algorithm Based on TextRank,” 2019 34rd Youth Academic Annual Conference of Chinese Association of Automation (YAC), Jinzhou, China, 2019, pp. 180-183, doi: 10.1109/YAC.2019.8787615 [7] A.Ramesh, K. G. Srinivasa and N. Pramod, ”SentenceRank — A graph based approach to summarize text,” The Fifth International Con- ference on the Applications of Digital Information and Web Technologies (ICADIWT 2014), 2014, pp. 177-182, doi: 10.1109/ICADIWT.2014 [8] D. J. Calder, “Assistive technologies and the visually impaired: A digital ecosystem perspective,” in Proceedings of the 3rdInternational Conference on PErvasive Technologies Related to Assistive Environments, ser. PETRA’10. New York, NY, USA: ACM, 2010, pp. 1- 8 [9] W. Chan, N. Jaitly, Q. V. Le, and O. Vinyals, “Listen, attend and spell,” CoRR, vol. abs/1508.01211, 2015 [10] R. Prabhavalkar, K. Rao, T. N. Sainath, B. Li, L. Johnson, and N. Jaitly, “A Comparison of Sequence-to- sequence Models for Speech Recognition,” in Proc. Interspeech, 2017. [11] Yun Ren, Changren Zhu, Shunping Xiao, “Object Detection Based on Fast/Faster RCNN Employing Fully Convolutional Architectures”, in Hindawi. Mathematical Problems in Engineering, Vol. 2018
Copyright
Copyright © 2024 Gauri Dhanorkar, Minal Zope, Sanika Mane, Rudra Pingle, Ramit Desai. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET62551
Publish Date : 2024-05-23
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online