

Ijraset Journal For Research in Applied Science and Engineering Technology
Review Paper on Heart Disease Prediction Using Advanced Machine Learning
Authors: Prof. A. P. Tiwari, Prof. K. A. Kadu
DOI Link: https://doi.org/10.22214/ijraset.2024.64142
Certificate: View Certificate
Abstract
Heart disease remains a leading cause of mortality worldwide, necessitating early and accurate diagnosis to improve patient outcomes. Traditional diagnostic methods often rely on manual assessment and basic statistical models, which may not fully capture the complexity of cardiovascular conditions. This paper explores the application of advanced machine learning algorithms for heart disease prediction, leveraging large datasets and sophisticated feature extraction techniques. By comparing various machine learning models, including decision trees, support vector machines, and deep learning approaches, this research aims to identify the most effective predictive Model. The results demonstrate that these advanced techniques significantly enhance predictive accuracy, offering a promising tool for early detection and personalized treatment of heart disease
Introduction
I. INTRODUCTION
Heart disease, a multifaceted and pervasive condition, poses significant challenges to global healthcare systems. Early detection is crucial for reducing morbidity and mortality, yet traditional diagnostic methods often fall short due to their limited scope and reliance on clinician expertise. The integration of machine learning in medical diagnostics presents an opportunity to overcome these limitations by analyzing complex datasets and identifying patterns that may be imperceptible to human observers. This paper investigates the potential of advanced machine learning techniques to predict heart disease, focusing on the comparative performance of various algorithms. By utilizing a diverse set of clinical and demographic features, the study aims to establish a reliable predictive model that can be applied in clinical settings to improve patient outcomes.
II. LITERATURE SURVEY
In this paper the primary objective of this study was to classify heart disease using different models and a real-world dataset. The k-modes clustering algorithm was applied to a dataset of patients with heart disease to predict the presence of the disease. The dataset was preprocessed by converting the age attribute to years and dividing it into bins of 5-year intervals, as well as dividing the diastolic and systolic blood pressure data into bins of 10 intervals. The dataset was also split on the basis of gender to take into account the unique characteristics and progression of heart disease in men and women. The elbow curve method was utilized to determine the optimal number of clusters for both the male and female datasets. The results indicated that the MLP model had the highest accuracy of 87.23%. These findings demonstrate the potential of k-modes clustering to accurately predict heart disease and suggest that the algorithm could be a valuable tool in the development of targeted diagnostic and treatment strategies for the disease. The study utilized the Kaggle cardiovascular disease dataset with 70,000 instances, and all algorithms were implemented on Google Colab. The accuracies of all algorithms were above 86% with the lowest accuracy of 86.37% given by decision trees and the highest accuracy given by multilayer perceptron, as previously mentioned... [1]
This research analyzes the effectiveness of machine learning in predicting coronary heart disease. Firstly, the data analytics revealed patterns in the data and important features for the binary logistic classification. The statistical approach in addition to the k-nearest neighbors played a vital part and allowed for effective feature selection from the dataset. The models explored, however, had a capped accuracy at 75%. The base models analyzed had an average accuracy of 71.92% while the neural network approached 73.97% accuracy. The ensemble techniques of bagging, boosting, and stacking proved effective in raising the accuracy of the base models. The average accuracy change shown by bagging was +1.9%, raising the bagged models’ average accuracy to 73.82%. While boosting, the Gradient Boosting approach proved to be the most powerful, yielding an accuracy of 73.89% when optimized. The K-Folds Cross-Validation depicted the consistency in the results produced with models: accuracies had low standard deviations ranging from 0.3% to 0.6%. Stacking, involving heterozygous models, proved to be the most effective ensemble method, producing an accuracy of 75.1%. This involved stacking KNN, random forest classifier, and support vector machine with logistic regression as the meta-classifier. However, the other statistical methods depicted flaws in the models. The precision of each model was high, with an average of 76.1%. However, the recall score was considerably lower, which decreased the area under the Receiving Operator Curves as well. An average of 66.8% was achieved for the recall score across all models. In the future, we aim to validate the proposed model on lab test data to gauge the practicality of the predictions. Additionally, other ensemble techniques such as ensemble neural networks will be explored. Currently, the study was limited to ensemble techniques such as boosting, bagging, and stacking. [2]
The aim of this study after implementing decision tree model on cardio dataset, it is observed that the accuracy is not very good. May be Naïve Bayes classifier will be better option for this dataset for predicting risk of heart disease. Also in order to improve accuracy we will design a wrist band which will continuously monitor pulse rate, body temperature, blood flow rate. Adding these parameters in the dataset will definitely improve accuracy. [3]
This paper has provided a systematic aimed to enhance heart disease risk prediction accuracy by employing ensemble classification techniques. We evaluated how well various classification algorithms, including Random Forest, Multilayer Perceptron, Decision Tree, and Nave Bayes, performed by comparing their accuracy. According to our research ensemble classification algorithms significantly improved heart disease risk prediction accuracy when compared to individual classifiers. We were able to provide predictions that were more accurate and dependable by using ensemble approaches like Bagging, Boosting, and Stacking, which capitalize on the advantages and combined knowledge of a number of classifiers. The algorithm with the most promise, Random Forest, had an initial accuracy of 81.53%. With the inclusion of feature selection, accuracy improved much more, with FS6 and FS2 attaining maximums of 88.18% and 90.52%, respectively. With FS6, the Multilayer Perceptron method's accuracy increased considerably from an initial accuracy of 78.52% to 96.18%. Similar improvements were also made in FS4 and FS3. Our results highlight the significance of feature selection in raising the accuracy of models that predict the likelihood of acquiring heart disease. By selecting the most relevant qualities, we were able to filter out noise and focus on the primary risk factors for heart disease, producing forecasts that were more accurate. Our research shows that the precision of heart disease risk prediction can be greatly increased by using feature selection and ensemble classification algorithms. With the use of these techniques, several classifiers can be combined in order to provide predictions that are more dependable and accurate. The findings of this study contribute to the improvement of heart disease risk prediction, which aids in the development of early diagnosis and prevention methods for better patient care and better health outcomes. [4]
III. SYSTEM DIAGRAM
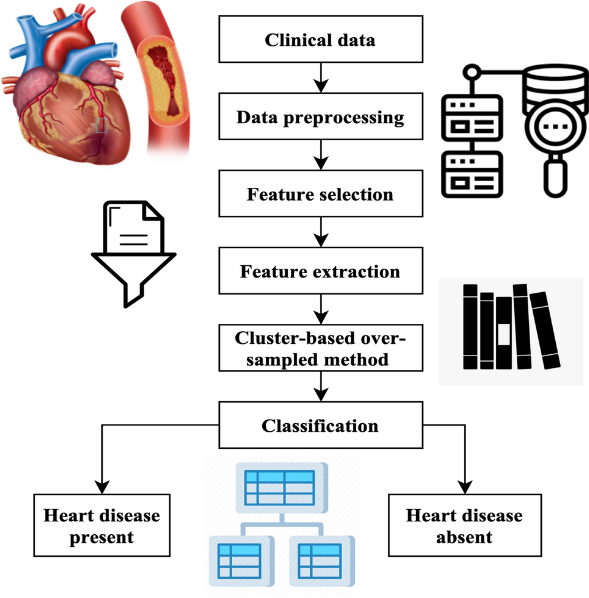
Fig: Heart Disease Prediction Using Advanced Machine Learning
Conclusion
The application of advanced machine learning algorithms in heart disease prediction offers a substantial improvement over traditional diagnostic methods. This study\'s findings underscore the potential of these techniques to enhance predictive accuracy and support early intervention strategies. Among the models evaluated, deep learning approaches, in particular, have shown superior performance, highlighting their ability to handle complex relationships within medical data. As machine learning continues to evolve, its integration into clinical practice could revolutionize heart disease diagnosis and treatment, leading to more personalized and effective care. Future research should focus on refining these models, addressing ethical considerations, and facilitating their adoption in healthcare settings.
References
[1] Citation: Bhatt, C.M.; Patel, P.; Ghetia, T.; Mazzeo, P.L. Effective Heart Disease Prediction Using Machine Learning Techniques. Algorithms 2023, 16, 88. https:// doi.org/10.3390/a16020088 [2] Vardhan Shorewala, Early detection of coronary heart disease using ensemble techniques https://doi.org/10.1016/j.imu.2021.100655 Received 2 April 2021; Received in revised form 28 June 2021; Accepted 28 June 2021 [3] Dr. Rakhi Waigi1 , Dr Sonali Choudhary2 , Dr Punit Fulzele3 , Dr. Gaurav Mishra Predicting The Risk Of Heart Disease Using Advanced Machine Learning Approach European Journal of Molecular & Clinical Medicine ISSN 2515-8260 Volume 7, Issue 07, 2020 [4] Rupali Atul Mahajan1 , Dr. Balasaheb Balkhande2 , Dr. Kirti Wanjale3 , Dr. Abhijit Chitre4 , Tushar Ankush Jadhav5 , Dr. Sheela Naren Hundekari Enhancing Heart Disease Risk Prediction Accuracy through Ensemble Classification Techniques Submitted: 25/05/2023 Revised: 07/07/2023 Accepted: 26/07/2023 [5] Mohan, S.; Thirumalai, C.; Srivastava, G. Effective Heart Disease Prediction Using Hybrid Machine Learning Techniques. IEEE Access 2019, 7, 81542–81554. [CrossRef]. [6] Waigi, R.; Choudhary, S.; Fulzele, P.; Mishra, G. Predicting the risk of heart disease using advanced machine learning approach. Eur. J. Mol. Clin. Med. 2020, 7, 1638–1645. [7] Gonsalves AH, Thabtah F, Mohammad RM, Singh G. Prediction of coronary heart disease using machine learning. Proceedings of the 2019 3rd international conference on deep learning. Technologies - ICDLT 2019. https://doi.org/ 10.1145/3342999.3343015.. [8] Svetlana ulianova. Cardiovascular disease dataset. Retrieved from, https://www.ka ggle.com/sulianova/cardiovascular-disease-dataset; 2019, january 01. [9] Latha CB, Jeeva SC. Improving the accuracy of prediction of heart disease risk based on ensemble classification techniques. July 02, https://www.sciencedirect. com/science/article/pii/S235291481830217X; 2019
Copyright
Copyright © 2024 Prof. A. P. Tiwari, Prof. K. A. Kadu . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET64142
Publish Date : 2024-09-02
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online