

Ijraset Journal For Research in Applied Science and Engineering Technology
Human Identification and Obstacle Detection System for Blind
Authors: Bhuvanesh ., Sreerambabu , Nimmy Pailochan, Kalidasan
DOI Link: https://doi.org/10.22214/ijraset.2023.55036
Certificate: View Certificate
Abstract
According to the World Health Organization (WHO), there are millions of visually impaired individuals worldwide in detecting obstacles and identifying people. It emphasizes the advancements in information technology and spatial cognition theory for visually impaired individuals as a new opportunity. The prototype proposes a simple and cost-effective solution using artificial vision through an AI-based intelligent system. The system utilizes the Faster Region Convolutional Neural Network (FRCNN) architecture to recognize human and scene objects or obstacles in real-time, even in complex environments. It provides users with comprehensive information about the presence, position, and nature of targets, and uses voice messages to alert blind individuals about obstacles or people nearby. The goal is to create a user-friendly technology that facilitates communication and independence for visually impaired individuals, enabling them to navigate both indoor and outdoor locations effectively.
Introduction
I. INTRODUCTION
“Visual impairment” is a broad term that is used to refer to any degree of vision loss that affects a person’s ability to perform the usual activities of daily life. The way in which vision impairments are classified differs across countries. The World Health Organization (the WHO) classifies visual impairment based on two factors: the visual acuity, or the clarity of vision, and the visual fields, which is the area from which you are able to perceive visual information, while your eyes are in a stationary position and you are looking straight at an object. Moving safely and efficiently through both indoor and outdoor environments can be challenging for the blind due to the unpredictability of obstacles. Traditional mobility aids, like white canes and guide dogs, remain valuable tools, but recent technological developments have significantly augmented these solutions.
Computer vision algorithms and depth-sensing technologies have been integrated into wearable devices to detect obstacles and offer real-time navigation assistance. These devices utilize cameras and sensors to create a spatial map of the surroundings, identifying potential obstacles like curbs, poles, staircases, and other hazards. Through auditory or haptic feedback, the user is alerted to the presence of these obstacles, allowing them to navigate more confidently and independently.
II. EXISTING SYSTEM
The existing systems and technologies for visually impaired navigation and assistance offer a diverse range of solutions. One approach involves a Kinect-based navigation system, requiring a backpack-carrying setup with a standard Kinect sensor, battery, and laptop. Utilizing SLAM technology, the smart cane provides centimeter-level accuracy for indoor positioning and obstacle detection. Another innovative system, the virtual haptic radar, replaces traditional sensors with a combination of 3D modeling and ultrasonic-based motion capture, warning users through vibrations when approaching objects. Mobile applications like Moovit, BlindSquare, and Lazzus leverage GPS and location databases to provide real-time guidance and information about points of interest. On the vision-based side, techniques like HOG and SSD enable object detection in images, adding another dimension to the array of solutions available. Together, these advanced technologies aim to enhance the mobility and independence of visually impaired individuals, enabling them to navigate their surroundings confidently.
Disadvantages of the existing navigation and assistance systems for visually impaired individuals include:
- Infrared Sensor Blind Spots: Some systems rely on infrared sensors, which can experience blind spots with no depth values, especially under strong sunlight. This limitation can hinder the accuracy and reliability of the system in certain outdoor conditions.
- Limited Object and Face Detection: Identifying objects and faces at reasonable distances and speeds can be challenging for some systems. This limitation may affect the system's ability to provide timely and relevant information to the user.
- High Cost: Some of the advanced technologies used in these systems can be expensive to implement, making them less accessible to a wider user base, particularly for those with limited financial resources.
- Portability and Convenience Issues: Ensuring portability and convenience remains a significant challenge for some systems. Carrying heavy or complex equipment in a backpack or bag can be burdensome for users, affecting their willingness to use the system regularly.
- False Predictions: Some systems may suffer from false predictions, where the technology incorrectly identifies objects or provides inaccurate information, leading to potential safety risks and confusion for the user.
- Time Taken for Prediction: The time taken for the system to process data and provide predictions can be a concern. Delays in providing real-time information may hinder the user’s ability to react promptly to their surroundings.
III. PROPOSED SYSTEM
The proposed system of the project is to design and fabricate a Smart Electronic Glass that designed to make recognizing faces and objects easier for visually impaired people.
- Improved Speed and Accuracy: By using deep learning models like Faster R-CNN, the detection speed and accuracy are significantly enhanced compared to earlier computer vision methods. This allows for real-time and more reliable object recognition, which is crucial for assisting visually impaired individuals in their daily activities.
- Reduced Computational Complexity: The adoption of Faster R-CNN and the Region Proposal Network (RPN) has greatly reduced the computational complexity. This means the system can run efficiently on various devices, including the Smart Electronic Glass, without requiring excessive computational resources.
- Multi-scale Object Detection: The ability to auto focus on different scales of objects in multi-scale feature maps enhances the system's versatility in recognizing objects of varying sizes, contributing to its overall robustness.
- Adaptive Semantic Information: The system adaptively selects semantic information and specific details from different levels, allowing it to efficiently process complex scenes and identify objects effectively.
- Flexibility and Efficiency: The combination of Faster R-CNN and the RPN provides flexibility and robustness in the detection process while maintaining efficiency during inference time. This is vital for real-world applications where quick responses are needed.
- Trained Assistant with Spoken Feedback: The integration of a trained assistant that provides spoken feedback about the objects and faces detected enables a seamless user experience for visually impaired individuals. This feature enhances the usability and practicality of the Smart Electronic Glass.
- Object Identification Support: The system's ability to recognize and detect objects will be highly useful for visually impaired individuals in identifying their surroundings, locating objects, and navigating their environment more confidently and independently.
IV. DEVELOPMENT ENVIRONMENT
A. Hardware Requirement
- Processor : i3 Processor.
- RAM : 8 GB.
- Hard Disk : 250 GB.
B. Software Requirement
- Operating system: Windows 10.
- Server Side : Python (64-bit).
- Client Side : HTML, CSS.
- IDE : Flask.
- Database : MySQL.
- Server : WampServer.
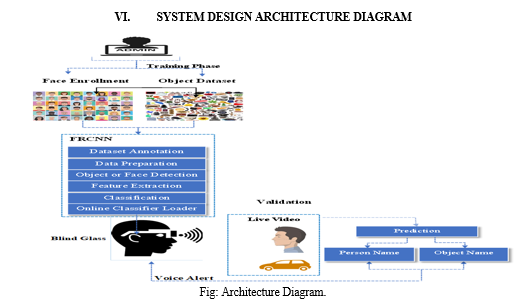
V. MODULE DESCRIPTION
A. Blind Obstacle Firmware
This module involves designing an AI-powered smart glass firmware with an integrated camera.
Images captured by the camera are processed using FRCNN machine learning models, and the speech response is sent back to the user through the glass's built-in speaker.
B. Object Detection Phase
- Dataset Annotation: The user annotates 100 images for 5 classes (person, animal, car, bicyclist, monitor, water bottle).
- Preprocessing: Image preprocessing steps include converting RGB to grey, applying noise filters, and converting grey to binarization.
- Segmentation: Region Proposal Network (RPN) is used to detect obstacles.
- Feature Extraction: Grey Level Co-occurrence Matrix is used to extract obstacle features in bad weather conditions.
- FRCNN Classification: Images are classified into 4 classes (person, animal, car, bicyclists).
C. Face Recognition Phase
- Capture Face: In this module record the video of the face.
- Frame Conversion: The video is converted into frames.
- Preprocessing: Read image, RGB to Grey Scale conversion, Resize image, Remove noise, Binarization.
- Face Detection: Region Proposal Network (RPN) is used to generate face regions.
- Feature Extraction: Grey Level Co-occurrence Matrix is used to extract facial features.
- Classification: Face images are classified as known or unknown.
D. Prediction Module
- Capture Video: The capture video clear and accurate images from video of human faces and objects. This is require a camera with high resolution and good lighting conditions to capture images.
- Predict Object: After capturing the object image from the smart glass, the image is given to object detection module to identify the object.
- Identify Person: After capturing the face image from the smart glass, the image is given to face detection module to identify the person.
E. Voice Integrator
Audio output, if a data is triggered during processing, voice synthesis is used to alert the user, generating for example: “stop” if there is an obstacle in the way. Saying that Hi Bhuvanesh.
VII. FUTURE ENHANCEMENT
- In addition to camera-based obstacle detection, other sensors such as proximity sensors and sonar can also be integrated into the system.
- This will provide a more comprehensive approach to obstacle detection, improving overall accuracy.
- The current implementation uses a web interface to access the system. However, by developing a mobile application, blind individuals can access the system more conveniently through their smartphones.
- The system's current voice assistance feature provides support for a single language. By implementing multi-language support, the system can cater to a broader user base.
Conclusion
In Conclusion, the proposed system is a comprehensive solution for assisting the visually impaired with known or unknown human identification and obstacle detection. It utilizes wearable technology, a CNN model, and voice assistance with Python Flask, TensorFlow, and MySQL. The CNN model is trained to provide real-time obstacle detection and human identification, with voice assistance through text-to-speech. Data management is handled using MySQL, allowing for customizable voice assistance settings. The user can access and manage the system through a user-friendly web interface. Overall, the system aims to enhance the independence and safety of visually impaired individuals, significantly improving their navigation and overall quality of life.
References
[1] F. Catherine, Shiri Azenkot, Maya Cakmak, “Designing a Robot Guide for Blind People in Indoor Environments,” ACM/IEEE International Conference on Human-Robot Interaction Extended Abstracts, 2015. [2] H. E. Chen, Y. Y. Lin, C. H. Chen, I. F. Wang, “Blindnavi: a mobile navigation app specially designed for the visually impaired,” ACM Conference Extended Abstracts on Human Factors in Computing Systems, 2015. [3] K. W. Chen, C. H. Wang, X. Wei, Q. Liang, C. S. Chen, M. H. Yang, and Y. P. Hung, “Vision-based positioning for Internet-of-Vehicles,” IEEE Transactions on Intelligent Transportation Systems, vol. 18, no.2, pp. 364–376, 2016. [4] M. Cordts, M. Omran, S. Ramos, T. Rehfeld, M. Enzweiler, R. Benenson, U. Franke, S. Roth, and B. Schiele, “The Cityscapes Dataset for Semantic Urban Scene Understanding,” IEEE Conference on Computer Vision and Pattern Recognition, 2016. [5] J. Ducasse, M. Macé, M. Serrano, and C. Jouffrais, “Tangible Reels: Construction and Exploration of Tangible Maps by Visually Impaired Users,” ACM CHI Conference on Human Factors in Computing Systems, 2016. [6] J. Guerreiro, D. Ahmetovic, K. M. Kitani, and C. Asakawa, “Virtual Navigation for Blind People: Building Sequential Representations of the Real-World,” International ACM SIGACCESS Conference on Computers and Accessibility, 2017.
Copyright
Copyright © 2023 Bhuvanesh ., Sreerambabu , Nimmy Pailochan, Kalidasan . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET55036
Publish Date : 2023-07-26
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online