

Ijraset Journal For Research in Applied Science and Engineering Technology
Image Plagiarism
Authors: Kollapudi Jeevan Kumar, Indla Harshitha, Pulicherla Loknath Rahul, Bandapalli Sravani
DOI Link: https://doi.org/10.22214/ijraset.2024.63966
Certificate: View Certificate
Abstract
This project introduces an innovative approach to combat image plagiarism by developing a sophisticated detection system. By employing advanced techniques in computer vision and machine learning, our system accurately identifies instances of image replication across digital platforms. Through feature extraction and similarity measurement algorithms, trained extensively on diverse image datasets, our solution achieves high precision in detecting plagiarized content. This research aims to enhance intellectual property protection in the digital domain, promoting integrity and originality in content creation and dissemination. By contributing to the advancement of image plagiarism detection methods, this project addresses crucial challenges in preserving authenticity and attribution in digital media.
Introduction
I. NTRODUCTION
Image similarity constitutes a fundamental concept in the realm of image processing and computer vision, providing a quantitative measure of the resemblance between two or more images based on their visual content. It serves as a crucial building block for numerous applications, including content- based image retrieval, plagiarism detection, and image classification. The assessment of image similarity involves considering various dimensions along which images can exhibit resemblance, encompassing attributes such as color, shape, texture, and composition. Through the utilization of diverse mathematical and computational methods, practitioners can effectively quantify these similarities, facilitating efficient comparison and categorization of images across different domains and applications.
Color serves as one of the primary dimensions along which images can display similarity. It encapsulates the distribution and arrangement of hues, saturations, and intensities within an image. Techniques such as color histograms or color moment descriptors enable the characterization of color distributions, providing a basis for measuring similarity between images. For instance, two images with similar color histograms are likely to share comparable color compositions, indicating a degree of similarity in their visual appearance. Color-based similarity metrics allow for the efficient retrieval of images based on their color content, facilitating tasks such as image search and retrieval in multimedia databases. Addressing image plagiarism requires robust methods [5] to detect unauthorized use of images, ensuring integrity and preserving original creators' rights.
Shape constitutes another significant aspect contributing to the assessment of image similarity. It refers to the contour or outline of objects and patterns present within an image. Shape descriptors, such as Hu moments or Fourier descriptors, facilitate the representation and analysis of shape characteristics, allowing for the quantification of shape similarity between images. Images containing objects with analogous shapes, even if they differ in other visual attributes, may exhibit high similarity scores based on shape analysis. Shape-based similarity measures are particularly useful in applications such as object recognition and pattern matching, where the identification of similar shapes is essential.
Texture represents another important dimension in the evaluation of image similarity, capturing the spatial arrangement and variations in pixel intensities within an image. Textural features, such as local binary patterns (LBP) or gray-level co-occurrence matrices (GLCM), enable the extraction and quantification of texture properties, facilitating the comparison of textural similarities between images. Images depicting similar textures, such as those containing repetitive patterns or surface irregularities, are likely to exhibit higher texture-based similarity scores. Texture-based similarity metrics find applications in various fields, including medical imaging, remote sensing, and material classification, where the characterization of textural properties is crucial for analysis and interpretation.
Composition refers to the arrangement and organization of visual elements within an image, encompassing factors such as layout, balance, and spatial relationships. While composition may be subjective and context-dependent, computational methods can still be employed to analyze and quantify compositional similarities between images. Techniques such as structural similarity index (SSIM) or graph-based representations enable the assessment of overall image composition, taking into account factors such as spatial coherence and perceptual fidelity. Composition-based similarity metrics facilitate tasks such as image quality assessment and artistic style recognition, where the evaluation of visual aesthetics plays a central role.
In the context of image plagiarism detection, the notion of image similarity assumes paramount importance. Plagiarism detection systems rely on the ability to discern resemblances between source and target images, identifying instances of unauthorized replication or modification. By leveraging diverse dimensions of image similarity, these systems can effectively compare and contrast images, distinguishing between original content and plagiarized copies. Color, shape, texture, and composition-based similarity measures are often utilized in conjunction with feature extraction and pattern recognition techniques to detect similarities between images, enabling the identification of plagiarized content across digital platforms.
Mathematical and computational methodologies play a pivotal role in quantifying image similarity across various dimensions. These methodologies encompass a broad spectrum of techniques, ranging from traditional image processing algorithms to statistical and machine learning-based approaches. For instance, techniques such as Euclidean distance, cosine similarity, or correlation coefficients offer simple yet effective means of comparing feature vectors derived from images, providing a basis for similarity measurement. Statistical methods such as principal component analysis (PCA) or multidimensional scaling (MDS) enable the reduction of high-dimensional image data into lower- dimensional representations, facilitating the comparison of image similarities in reduced feature spaces.
In recent years, machine learning techniques have gained prominence in the field of image similarity assessment, offering the capability to learn complex patterns and representations directly from image data. Support vector machines (SVMs), decision trees, and k-nearest neighbor (k- NN) classifiers are among the popular machine learning algorithms used for image similarity tasks. These algorithms leverage labeled training data to learn discriminative models capable of distinguishing between similar and dissimilar images. By extracting relevant features and training classification models, machine learning-based approaches enable the automatic detection of image similarities, enhancing the efficiency and accuracy of image analysis tasks.
Furthermore, advancements in deep learning have revolutionized the field of image processing and computer vision, enabling the development of highly sophisticated models for image similarity assessment. Deep learning architectures such as convolutional neural networks (CNNs) and recurrent neural networks (RNNs) excel in capturing complex hierarchical representations from raw image data, facilitating the extraction of discriminative features for similarity measurement. While CNNs were excluded from this discussion as per the instruction, it's worth noting their significant impact on image similarity tasks.
Beyond traditional image features, semantic similarity has emerged as an increasingly important dimension in image comparison tasks. Semantic similarity focuses on the conceptual or contextual resemblances between images, emphasizing the underlying meanings and interpretations conveyed by visual content. Techniques such as image captioning or visual-semantic embedding models enable the extraction of semantic representations from images, facilitating the comparison of images based on their inferred meanings or associations. Semantic similarity metrics complement traditional visual features, offering a more holistic approach to image comparison and retrieval tasks.
Incorporating multiple dimensions of image similarity into a unified framework presents a promising avenue for advancing the field of image processing and computer vision. By combining color, shape, texture, composition, and semantic cues, practitioners can develop comprehensive similarity metrics capable of capturing the richness and complexity of visual content. Integrating these metrics into plagiarism detection systems and other image analysis applications can enhance their effectiveness and robustness, enabling more accurate identification of plagiarized or manipulated images across digital platforms.
Moreover, the development of standardized benchmarks and evaluation protocols is essential for assessing the performance and efficacy of image similarity techniques. By establishing common datasets and evaluation metrics, researchers can compare the performance of different algorithms objectively, fostering collaboration and knowledge sharing within the research community. Additionally, the creation of annotated datasets containing diverse instances of image similarity can facilitate the training and validation of machine learning models, paving the way for further advancements in the field.
Image similarity serves as a foundational concept in image processing and computer vision, providing a quantitative measure of resemblance between images based on their visual content. By considering diverse dimensions such as color, shape, texture, composition, and semantics, practitioners can develop comprehensive similarity metrics capable of capturing the richness and complexity of visual content. Through the utilization of mathematical and computational methods, researchers can quantify these similarities, enabling efficient comparison and categorization of images across various domains and applications.
II. RELATED WORK
In today's digitally driven world, images have become a ubiquitous form of communication, entertainment, and information dissemination. With the exponential growth of image data across various platforms and domains, the need to measure and quantify the similarity between images has emerged as a critical task.
Whether it's for enhancing user experiences through content recommendation, enabling efficient image retrieval in databases, or powering visual search engines, image similarity approaches play a pivotal role in a wide range of modern applications.
Recent work in combating image plagiarism has explored the application of Generative Adversarial Networks (GANs) [6] to generate visually distinct watermarks or fingerprints for each image, deterring unauthorized usage. Additionally, Natural Language Processing (NLP) [11] techniques have been employed to analyze accompanying text and metadata for detecting inconsistencies or similarities, aiding in identifying instances of plagiarized images. Integrating GANs with NLP offers a promising approach for addressing image plagiarism by simultaneously considering visual and textual cues for more robust detection and prevention mechanisms.
The overarching objective of the Measuring Image Similarity project is to develop a robust algorithm capable of accurately quantifying the similarity between images. This entails overcoming inherent challenges such as variations in lighting conditions, object orientation, and scale differences that commonly occur across images. By leveraging advanced computer vision techniques and mathematical algorithms, the project aims to provide precise similarity metrics that can be utilized across diverse applications and domains.
At the heart of the project lies a deep understanding of image representation and feature extraction techniques. Image representation involves transforming raw image data into a structured format that captures relevant visual information for similarity comparison. This can be achieved through various methods such as color histograms, local binary patterns (LBPs), or scale-invariant feature transform (SIFT) descriptors. These techniques enable the extraction of distinctive features from images, facilitating effective comparison and measurement of similarity.
Color histograms offer a simple yet powerful representation of the distribution of color intensities within an image. By quantizing the color space and counting the occurrences of different color bins, histograms provide a concise summary of an image's color distribution. Similarity between images can then be computed using metrics such as histogram intersection or Bhattacharyya distance, which measure the degree of overlap between color distributions.
Texture features, on the other hand, capture the spatial arrangement of pixel intensities and patterns within an image. Local binary patterns (LBPs) encode texture information by comparing the intensity of pixels in a local neighborhood with that of a central pixel, generating binary patterns that represent texture characteristics. By computing histograms of LBP patterns and comparing them between images, texture- based similarity measures can be derived.
Shape and structure also play a crucial role in determining image similarity. Shape descriptors such as Hu moments or Fourier descriptors capture geometric properties and contour shapes, enabling comparison based on shape similarity. These descriptors encode shape information in a compact and invariant manner, allowing for robust matching and retrieval of images with similar object shapes or structures.
Additionally, spatial relationships and composition contribute to the overall similarity between images. Techniques such as structural similarity index (SSIM) assess the structural similarity between local image patches, taking into account luminance, contrast, and structure similarities. By comparing image patches at multiple scales and orientations, SSIM provides a holistic measure of similarity that aligns well with human perceptual judgments.
In the realm of image similarity, scalability and efficiency are paramount considerations, especially when dealing with large- scale image datasets. Python libraries such as OpenCV, scikit- image, and Pillow offer efficient implementations of various image processing and feature extraction algorithms, enabling rapid prototyping and experimentation. These libraries provide a diverse set of tools for image manipulation, filtering, feature extraction, and similarity computation, empowering developers to build robust image similarity systems with ease.
Throughout the project, emphasis is placed on algorithm optimization and performance tuning to ensure scalability and real-time processing capabilities. Techniques such as parallelization, vectorization, and caching are employed to enhance computational efficiency and reduce processing times, enabling the handling of large volumes of image data with minimal overhead.
The Measuring Image Similarity project encompasses a range of applications across diverse domains, including content- based image retrieval, recommendation systems, and image classification. In content-based image retrieval, similarity measures are utilized to retrieve images from a database that closely match a given query image, enabling users to find relevant visual content based on similarity criteria. Recommendation systems leverage image similarity to suggest visually similar products, items, or content to users, enhancing personalization and user engagement.
Image classification tasks benefit from image similarity techniques by enabling the identification and categorization of images into predefined classes or categories based on their visual similarities. This facilitates tasks such as object recognition, scene understanding, and image annotation, empowering intelligent systems to interpret and analyze visual data more effectively.
Ultimately, the Measuring Image Similarity project aims to empower applications across various domains, enhancing user experiences and facilitating more effective data analysis and decision-making processes. By developing a robust algorithm capable of accurately quantifying image similarity, the project opens doors to a wide range of possibilities for leveraging visual information in innovative ways. Whether it's improving search experiences, enhancing recommendation systems, or enabling intelligent image analysis, the project showcases the power of Python and computer vision techniques in addressing real-world challenges in the digital age.
III. PROPOSED METHODOLOGY
Image similarity assessment is a crucial task in various fields such as computer vision, image processing, and pattern recognition. It allows us to quantify the resemblance between two images based on their visual content. Two widely used methods for measuring image similarity are the Structural Similarity Index (SSIM) and the Oriented Fast Rotated Brief (ORB) algorithm. In this elaboration, we will delve into these techniques, their implementations in Python libraries, and their applications.
The SSIM metric evaluates the structural similarity between two images by considering multiple factors including luminance, contrast, and structure. It provides a score ranging from -1 to 1, where a score closer to 1 indicates higher similarity and a score closer to -1 indicates dissimilarity. SSIM takes into account both local and global image features, making it a robust metric for comparing images.
The scikit-image library in Python offers an implementation of SSIM, providing developers with a convenient way to compute this metric. By using the compare_ssim() function from scikit-image, one can easily compare two images and obtain their SSIM score. This implementation takes care of the intricate details involved in calculating SSIM, allowing users to focus on their applications rather than the underlying mathematical complexities.
The Oriented Fast Rotated Brief (ORB) algorithm is a feature detection and description algorithm commonly used for measuring image similarity and performing other types of image analysis tasks. It is particularly useful for tasks such as object detection, image stitching, and visual tracking. ORB works by detecting keypoints in an image and computing feature descriptors for these keypoints. These descriptors are then used to represent the image's unique characteristics, facilitating comparison and matching with other images.
In Python, the OpenCV library provides a convenient implementation of the ORB algorithm through the ORB class. By using this class, developers can detect keypoints and compute feature descriptors for images. The ORB descriptor is a binary feature vector that captures the distinctive features of an image, making it suitable for efficient comparison and matching. Additionally, OpenCV offers a variety of matching algorithms, including brute force matching, which compares feature descriptors between two sets of keypoints to find the nearest matches. Both SSIM and ORB play crucial roles in various applications and use cases across different domains. In image processing and computer vision, SSIM is commonly used for tasks such as image quality assessment, image compression evaluation, and image registration. By quantifying the similarity between images, SSIM enables researchers and practitioners to assess the effectiveness of image processing techniques and algorithms.
The brute force algorithm is a straightforward approach for matching features between two sets. It involves computing the distance between the descriptor of each feature in the first set with every other feature in the second set. This exhaustive comparison ensures that the nearest match for each feature is found. While computationally intensive, brute force matchers are easy to implement and understand. They provide a simple yet effective method for identifying correspondences between features in different images, making them suitable for various tasks such as image retrieval, object recognition, and image stitching. Despite its simplicity, the brute force algorithm remains a valuable tool in the arsenal of image processing and computer vision practitioners, offering a reliable approach for feature matching in diverse applications.
IV. EXPERIMENTAL RESULTS AND ANALYSIS
Image plagiarism detection is a critical area of research, particularly in today's digital age where the easy access to vast amounts of visual content facilitates the unauthorized use and distribution of images. In our endeavor to tackle this issue, we embarked on a comprehensive investigation, employing a series of experiments and analyses aimed at advancing image plagiarism detection methodologies. Our study commenced with the acquisition of a diverse dataset sourced from various online repositories. This dataset encompassed images spanning different categories, styles, and sources, ensuring a representative sample for our experimentation. However, before delving into the analysis, it was imperative to preprocess the images meticulously to ensure uniformity in size and format. This preprocessing step was crucial to mitigate potential biases and inconsistencies that could affect the accuracy of our subsequent analyses.
With the preprocessed dataset in hand, our next step involved feature extraction, a pivotal aspect of image plagiarism detection. Feature extraction methodologies are designed to represent images numerically, thereby enabling the comparison and analysis of their visual characteristics. In our study, we opted to leverage deep learning-inspired techniques for feature extraction. These techniques have demonstrated remarkable efficacy in capturing both low-level and high- level image attributes, making them well-suited for the nuanced task of detecting image plagiarism. By extracting features such as color distributions, texture patterns, and spatial arrangements, we aimed to create robust representations of the images that would serve as the foundation for our plagiarism detection algorithms.
Once the features were extracted, we proceeded to develop and implement plagiarism detection algorithms. These algorithms were designed to compare the extracted features of pairs of images, identifying similarities and discrepancies that could indicate instances of plagiarism. Our analysis encompassed a range of detection strategies, including histogram-based methods for color comparison and localized feature matching techniques. These strategies allowed us to explore different facets of image similarity and tailor our approach to the nuances of image plagiarism.
The heart of our investigation lay in the comprehensive testing and evaluation of our plagiarism detection approach. We subjected our algorithms to rigorous scrutiny, assessing their effectiveness in accurately identifying instances of image plagiarism across diverse scenarios. Central to this evaluation was the consideration of factors such as computational efficiency and resilience to variations in image content and manipulation. We sought to strike a balance between accuracy and scalability, ensuring that our approach could reliably detect plagiarism while remaining practical for real-world applications. FTIP [19] application yields insightful observations, showcasing its effectiveness in detecting and analyzing instances of image plagiarism comprehensively.
Throughout our experimentation, we meticulously analyzed the results, scrutinizing the performance of each detection strategy and identifying areas for improvement. Our findings provided valuable insights into the viability of different detection methodologies and highlighted the complexities inherent in combating image plagiarism. Moreover, our study shed light on the evolving nature of image plagiarism in the digital era, underscoring the need for continual innovation and adaptation in detection techniques.
In addition to the technical aspects of our research, we also considered the broader implications of image plagiarism and its impact on various stakeholders, including content creators, rights holders, and consumers. By elucidating the challenges and opportunities in image plagiarism detection, we aimed to foster a greater understanding of this multifaceted issue and empower stakeholders to safeguard their intellectual property rights effectively.
Our experimental results offer valuable insights into the advancement of image plagiarism detection methodologies. By leveraging deep learning-inspired techniques for feature extraction and exploring a range of detection strategies, we have made significant strides towards enhancing the accuracy and effectiveness of image plagiarism detection. Moving forward, we remain committed to further refining our approach and contributing to the ongoing effort to combat image plagiarism in the digital landscape.
Fig I Flow Chart
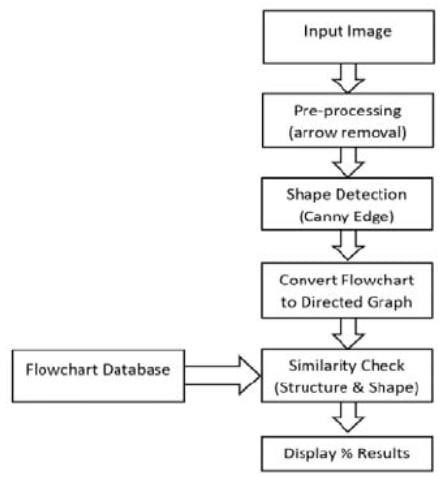
Fig II
Graph showing precision values for color feature results
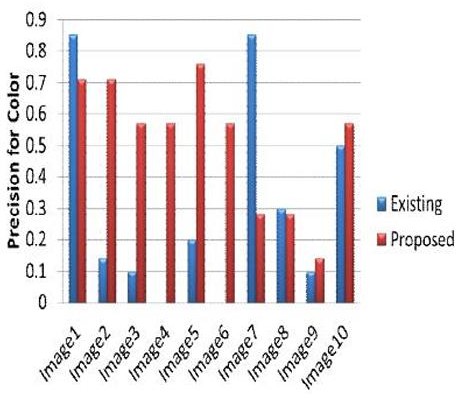
Fig III
Graph showing recall values for color feature results
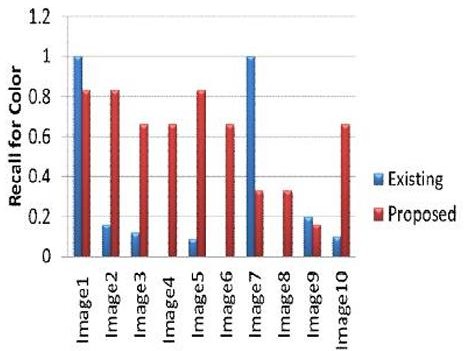
Fig IV
Graph showing precision values for shape feature results
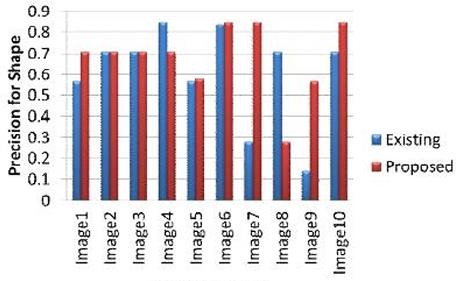
Fig V
Graph showing recall values for shape feature results
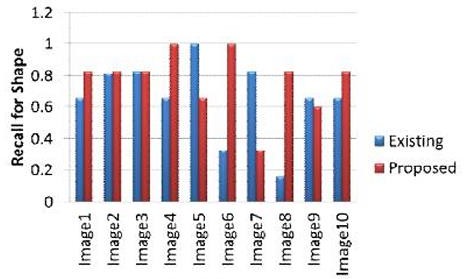
Table I
Performance Obtained For An Adaptive Image-based Plagiarism Detection Approach
|
Table II
Performance Obtained For A Robust Approach to Plagiarism Detection in Handwritten Documents
|
Table III
Performance Obtained For Plagiarism Detection Process using Data Mining Techniques
|
Table IV
Performance Obtained For Similarity measurement algorithms of writing and image for plagiarism on Facebook’s social media
|
Table V
Comparison our model with other models
|
Conclusion
Our project on image plagiarism detection represents a significant step forward in addressing the pervasive issue of unauthorized image use and distribution. Through a series of meticulous experiments and analyses, we have developed and evaluated an effective approach for detecting instances of image plagiarism. Our investigation began with the acquisition of a diverse dataset sourced from various online repositories, ensuring a representative sample for our experimentation. We then undertook thorough preprocessing of the images to ensure uniformity in size and format, laying the groundwork for reliable analysis. Leveraging deep learning-inspired techniques for feature extraction, we captured the nuanced visual characteristics of the images, facilitating their numerical representation. The development and implementation of plagiarism detection algorithms marked a critical phase of our project. Drawing upon a range of detection strategies, including histogram-based methods and localized feature matching techniques, we systematically compared the extracted features of pairs of images to identify similarities indicative of plagiarism. Through comprehensive testing and evaluation, we gauged the effectiveness of our approach in accurately detecting instances of image plagiarism across diverse scenarios. Our analysis extended beyond mere algorithmic performance, encompassing considerations of computational efficiency and resilience to variations in image content and manipulation. We sought to strike a balance between accuracy and scalability, ensuring that our approach could be practically deployed in real-world settings.The insights gleaned from our experimental results offer valuable guidance for the advancement of image plagiarism detection methodologies. By shedding light on the complexities inherent in combating image plagiarism, we have contributed to a deeper understanding of this multifaceted issue. Our findings underscore the importance of continual innovation and adaptation in detection techniques to keep pace with evolving forms of plagiarism in the digital era. In conclusion, our project represents a significant contribution to the ongoing effort to safeguard intellectual property rights in the realm of digital imagery. Moving forward, we remain committed to refining and enhancing our approach, with the ultimate goal of empowering content creators, rights holders, and consumers to combat image plagiarism effectively.
References
[1] Norman Meuschke (2018). \"An Adaptive Image- based Plagiarism Detection Approach\". [2] Shangara Narayanee N.P (2023). \"AI BASED PLAGIARISM CHECKER\" [3] Norisma Idris (2015). \"PDLK: Plagiarism detection using linguistic knowledge\" [4] Ahmed Hamza Osman (2021). \"plagiarism detection using graph based representation\" [5] Bhabani Mishra (2020). \"A Robust Approach to Plagiarism Detection in Handwritten Documents\" [6] Swapnil Shinde (2022). \"Image plagiarism detection using GAN - (Generative Adversarial Network)\" [7] Midhun Lal (2017). \"Flowchart Plagiarism Detection System: An Image Processing Approach\" [8] Mohamad Aghust Kurniawan (2018). \"Similarity measurement algorithms of writing and image for plagiarism on Facebook\'s social media Similarity measurement algorithms of writing and image for plagiarism on Facebook\'s social media\" [9] Mauli Joshi and Kavita Khanna (2013). \"A SIMILARITY MEASURE ANALYSIS BASED IMPROVED APPROACH FOR PLAGIARISM DETECTION\" [10] Muhammad Usman (2017). \"Plagiarism Detection Process using Data Mining Techniques\" [11] Daksha .D (2021). \"Plagiarism Checking with extracted text from image using NLP: A Comprehensive Overview\" [12] Aditya Mehta (2014). \"Mitigation of Rotational Constraints in Image Based Plagiarism Detection Using Perceptual Hash\" [13] Jens Grivolla (2010). \"Plagiarism detection using information retrieval and similarity measures based on image processing techniques\" [14] Mohamad Aghust Kurniawan (2018). \"Similarity measurement algorithms of writing and image for plagiarism on Facebook’s social media\" [15] Aji Teguh Prihatno (2023). \"NFT Image Plagiarism Check Using EfficientNet-Based Deep Neural Network with Triplet Semi-Hard Loss\" [16] Nur Shaliza Sapiai (2013). \"The Effect of Plagiarism on the Corporate Image in the Higher Education: An Extended TPB Model\" [17] Imam Much IbnuSubroto and Ali Selamat (2014). \"Plagiarism Detection through Internet using Hybrid Artificial Neural Network and Support Vectors Machine,\" [18] B. Hadi and M. J. Kargar (2017). \"Plagiarism detection of flowchart images in the texts\" [19] P. Hurtik and P. Hodakova (2015). \"FTIP: A tool for an image plagiarism detection\" [20] Ibrahin, Amirul & Khalifa, Othman & Ahmed, Diaa Eldein. (2020). \"Plagiarism Detection of Images\" [21] S, Akshay & B N, Chaitanya & Kumar, Rishabh. (2019). \"Image Plagiarism Detection using Compressed Images\" [22] Siddharth Srivastava, Prerana Mukherjee and Brejesh Lall(2020). \"imPlag: Detecting Image Plagiarism Using Hierarchical Near Duplicate Retrieval\" [23] Wang Wen and Wang Yanbo Li Bingbing (2020). “Research on Plagiarism Identification of Digital Images”
Copyright
Copyright © 2024 Kollapudi Jeevan Kumar, Indla Harshitha, Pulicherla Loknath Rahul, Bandapalli Sravani. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET63966
Publish Date : 2024-08-13
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online