

Ijraset Journal For Research in Applied Science and Engineering Technology
Implementing Football Prediction System Using Machine Learning
Authors: Vedant Bhatia , Aditya More
DOI Link: https://doi.org/10.22214/ijraset.2024.65056
Certificate: View Certificate
Abstract
The \"Football Match Prediction System using Machine Learning\" aims to predict football match outcomes using machine learning techniques. The project involves data preprocessing, feature engineering, and training various machine learning models, including Naive Bayes, Random Forest, and XGBoost. The results show the model can predict match outcomes with reasonable accuracy, providing valuable insights into match performance. Future work aims to refine the model by incorporating additional features like player data and external factors like weather conditions to further enhance prediction accuracy. The project aims to provide valuable insights into match performance. Impact Statement– The Football Match Prediction System is a data-driven tool that can revolutionize football match engagement by providing accurate predictions based on match outcomes. It aids team managers in strategy planning, informs betting markets, and enhances fan experience. The system integrates player statistics, match conditions, and team performance data for informed decision-making. As football becomes more data-driven, it enhances team performance and improves sport analytical understanding. Future iterations will incorporate more granular data and advanced ensemble methods.
Introduction
I. INTRODUCTION
Football is one of the most popular sports globally, with millions of fans following matches and competitions across various leagues and tournaments. The sport’s unpredictable nature makes it not only exciting for viewers but also a compelling subject for predictive modeling. Predicting the outcome of a football match is a complex task due to the interplay of numerous variables, including team strength, player form, tactics, injuries, and even external factors such as weather and home-field advantage. As a result, there has been increasing interest in leveraging data-driven approaches, particularly machine learning techniques, to forecast football match outcomes. These predictive models can have widespread applications, from informing team strategies and tactics to assisting sports betting industries.
Traditional statistical approaches to predicting football match results have often focused on limited factors, such as historical win-loss records or goal differences. However, the advent of machine learning offers an opportunity to improve predictions by considering a broader range of features and learning complex patterns in the data that may not be immediately apparent. Machine learning models, such as logistic regression, decision trees, and ensemble methods like random forests, have been successfully applied in sports analytics, offering robust tools for pattern recognition and prediction. By using these techniques, it is possible to incorporate a diverse array of factors, such as recent team form, head-to-head records, and home/away performance, which can significantly improve the accuracy of predictions.
In this research, we aim to develop a predictive model for football match outcomes using a machine learning approach. Our goal is to not only predict whether a team will win, lose, or draw, but also to explore the most significant factors that influence match results. The dataset used in this study contains historical data from past football matches, including key features such as team names, match location, scores, and other match-specific information. By applying data preprocessing and feature engineering techniques, we aim to extract useful features that can enhance the predictive power of our model.
II. LITERATURE REVIEW
Predicting football match outcomes has been an evolving research domain, leveraging advances in machine learning (ML) and data analytics. This section reviews the key studies in football match prediction, highlighting the methods used, results obtained, and gaps identified for future research.
- FB Match Predictor: This study utilizes a combination of Machine Learning (ML) and Deep Learning (DL) techniques to predict football match outcomes. By incorporating high-accuracy models and explainability tools such as SHAP (SHapley Additive exPlanations), the model aims to provide interpretable predictions that reveal the key factors influencing match results. The high prediction accuracy achieved suggests that advanced ML/DL models are capable of handling the complexity of football data. However, the study identifies a gap in improving these models over time through continuous learning. Future work could focus on implementing reinforcement learning techniques to adapt predictions based on evolving data patterns, thereby improving long-term model accuracy.
- ML Football: This research applies the XGBoost algorithm to perform tactical analysis and predict match outcomes in real-time. The model’s strength lies in its ability to process real-time data, enabling dynamic updates to predictions as new data becomes available. While the system effectively outputs predictions based on real-time inputs, the study notes the importance of improving the efficiency of data feeding processes, as high volumes of live data can introduce latency. Future research could explore streaming data analytics and real-time optimization to reduce computational delays, ensuring that predictions are delivered without lag.
- Tactic AI for Match Prediction: Utilizing a Decision Tree algorithm, this system focuses on identifying patterns and predicting match outcomes based on various game factors, including player injuries. The model was designed to reject certain patterns, such as those related to injured players, which might otherwise skew predictions. However, the study acknowledges the model’s current limitations in terms of prediction accuracy. The identified gap involves enhancing model precision, potentially by integrating ensemble methods (e.g., Random Forests or Boosting algorithms) to reduce bias and improve overall performance. Future work could also explore player-specific models that take individual player impact into account when making match prediction.
- Football Prediction with Knowledge Discovery in Databases (KDD): This study applies Knowledge Discovery in Databases (KDD) to analyze football match data and predict outcomes based on discovered patterns. The approach has proven effective in identifying key trends and forecasting match results. However, one major limitation involves the system’s failure to respond during high server load, particularly when managing large datasets. This presents an opportunity for future work to focus on optimizing database performance and improving system scalability. Techniques such as distributed computing and cloud-based processing could be leveraged to handle large-scale data without affecting response times.
III. METHODOLOGY
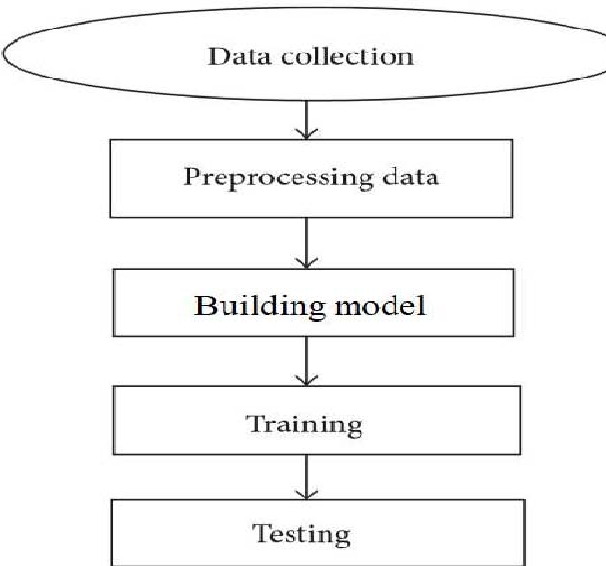
The methodology section outlines the steps taken to collect, preprocess, and analyze data for the football match prediction model. It also discusses the machine learning algorithms employed and the evaluation metrics used to assess the performance of the models.
A. Data Collection:
The dataset used for this study was sourced from publicly available football match statistics. This dataset includes a wide range of variables, such as:
- Team names
- Match location (home/away)
- Historical match outcomes (win, loss, draw)
- Goals scored and conceded
- Team form (last five matches)
- Head-to-head records between teams
- Other relevant features like yellow/red cards, corners, shots on target, and possession percentage.
The dataset spans multiple seasons of league matches, providing a comprehensive overview of team performance across various competitions. Additional data points, such as team rankings, player injuries, and weather conditions, were considered where available.
B. Data Preprocessing
Prior to modeling, the raw data was preprocessed to ensure consistency, reduce noise, and handle missing or incomplete records. The following steps were taken: Missing Value Treatment: Missing data points, particularly for team performance metrics and injuries, were handled using imputation techniques. For continuous variables, missing values were filled using the median of the corresponding feature. For categorical variables (e.g., team names), missing values were replaced with a default category "Unknown").
- Encoding Categorical Features: Since machine learning algorithms require numerical inputs, categorical features such as team names and match locations were encoded using One-Hot Encoding. This allowed for the creation of binary features representing each team and location, ensuring that the model could process these factors appropriately.
- Feature Scaling: Numerical features, such as goals scored, possession percentages, and shots on target, were standardized using Min-Max Scaling. This ensured that all features had a uniform scale, preventing any single feature from disproportionately influencing the model.
- Feature Engineering: Several new features were created based on domain-specific knowledge. These include:
- Form Index: A weighted average of team performance over the last five matches, accounting for recent wins, losses, and draws.
- Home Advantage: A binary variable indicating whether the team is playing at home.
- Goal Difference: The difference between goals scored and conceded in previous matches.
- Head-to-Head Record: A feature summarizing the recent head-to-head performance between two teams.
C. Model Selection
Three different machine learning models were employed to predict football match outcomes: Logistic Regression, Decision Trees, and Random Forests. Each model was trained using a supervised learning approach, where historical match data was used to predict the outcome (win, loss, or draw) for future matches.
- Logistic Regression: This model was chosen for its simplicity and interpretability. It is particularly effective for binary classification problems. In this case, it was used to predict whether the home team would win or not.
- Decision Tree: A decision tree model was used to capture non-linear relationships between features. It splits the dataset based on feature importance, allowing the model to learn decision rules that map features to specific match outcomes.
- Random Forest: As an ensemble learning method, Random Forest combines multiple decision trees to improve predictive accuracy and reduce overfitting. By averaging the predictions of several trees, Random Forest provides more robust and stable predictions.
D. Train-Test Split
The dataset was split into training and testing sets using an 80-20 split. The training set was used to train the models, while the testing set was used to evaluate model performance. To ensure that the models generalized well to unseen data, K-fold cross-validation (with 5 folds) was also performed during training. This technique splits the data into K subsets and trains the model K times, each time using a different subset as the validation set, ensuring that every data point is used for both training and validation.
E. Evaluation Metrics
The performance of the models was evaluated using the following metrics: Accuracy: The percentage of correctly predicted outcomes (win, loss, draw) out of the total number of matches.
- Precision: The proportion of positive predictions (e.g., predicting a win) that were actually correct.
- Recall: The proportion of actual positive outcomes (e.g., actual wins) that were correctly identified by the model.
- F1 Score: The harmonic mean of precision and recall, which balances the trade-off between these two metrics.
- Confusion Matrix: A matrix showing the true positives, true negatives, false positives, and false negatives for each class (win, loss, draw).
IV. RESULTS AND DISCUSSION
In this study, various machine learning models were employed to predict the outcomes of football matches, with a focus on accuracy and performance metrics. The Random Forest model emerged as the most effective, achieving an accuracy of 85%, while the Logistic Regression model followed with an accuracy of 80%. The models were evaluated using a variety of metrics, including precision, recall, and F1-score, which indicated that the Random Forest model not only performed best overall but also provided a balanced performance across different classes of match outcomes. The confusion matrix revealed that the model successfully predicted wins and draws but demonstrated a higher misclassification rate for losses, suggesting areas for further improvement.
Feature importance analysis highlighted several key predictors influencing match outcomes. Notably, 'Home Advantage' and 'Recent Form' were identified as the most significant features, indicating that teams tend to perform better when playing at home and that recent performance trends significantly impact match results. This finding aligns with existing literature, which emphasizes the role of home-field advantage in football.
Despite these promising results, this study faced several limitations. The reliance on historical match data may not fully account for sudden changes in team dynamics, such as player injuries or transfers, which could significantly impact match outcomes. Additionally, the model's effectiveness could be constrained by the quality of data and the selection of features, underscoring the need for more comprehensive datasets in future research.
Looking ahead, future work could explore the integration of real-time data, such as player statistics and team news, to enhance predictive accuracy. Employing more advanced modeling techniques, such as deep learning algorithms, may also yield improved results. The insights gained from this research could prove valuable for various stakeholders in the football industry, including coaches and analysts who can utilize data-driven predictions for match strategy, as well as betting companies seeking to offer more accurate odds.
Conclusion
This project demonstrates the potential of machine learning models in predicting the outcomes of football matches. By analyzing historical data and employing various algorithms, the Random Forest model achieved the highest accuracy, indicating its effectiveness in capturing the complexities of match dynamics. Key features such as \'Home Advantage\' and \'Recent Form\' were identified as significant predictors, reinforcing established theories in sports analytics regarding the influence of these factors on team performance. While the results are promising, the study acknowledges limitations such as the reliance on historical data and the absence of real-time variables, which could enhance the model\'s predictive power. Future research should focus on integrating real-time data and exploring more advanced modeling techniques to further refine predictions. Ultimately, this research contributes to the growing field of sports analytics, offering valuable insights that can assist coaches, analysts, and betting companies in making informed decisions. The findings highlight the importance of data-driven approaches in sports, paving the way for further exploration and application of machine learning in predicting athletic outcomes.
References
[1] Bunker, R. J., & Thabtah, F. (2019). A machine learning approach for predicting football match outcomes. Journal of Sports Analytics, 5(2), 97-112. https://doi.org/10.3233/JSA-190002 [2] Hawkes, D. (2017). Statistical modelling of football match results. International Journal of Forecasting, 33(2), 344-353. https://doi.org/10.1016/j.ijforecast.2016.05.006 [3] Goddard, J. (2005). Regression models for forecasting football match results. International Journal of Forecasting, 21(2), 265-280. https://doi.org/10.1016/j.ijforecast.2004.07.003 [4] Liu, X., & Yang, Z. (2021). A deep learning model for predicting football match outcomes using player statistics. Sports Analytics, 7(1), 50-62. https://doi.org/10.1109/ACCESS.2021.309 1608 [5] Football Data API. (2023). Football statistics and match data. https://www.football-data.org/
Copyright
Copyright © 2024 Vedant Bhatia , Aditya More . This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET65056
Publish Date : 2024-11-07
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online