

Ijraset Journal For Research in Applied Science and Engineering Technology
Intelligent Document Processing for Disease Detection
Authors: Shankar Sharan Tripathi, Nishant Roy, Aakash Kumar Singh, Ayush Kumar Agarwal, Prashant Singh Rajput
DOI Link: https://doi.org/10.22214/ijraset.2024.61951
Certificate: View Certificate
Abstract
This project endeavors to develop an intelligent document processing pipeline tailored specifically for medical reports, with a primary focus on samples from Dr Lal Path lab and targeting prevalent diseases leading to kidney failures such as glomerulonephritis, chronic kidney disease, polycystic kidney disease, hypertensive nephropathy, and lupus nephritis. The proposed pipeline integrates cutting-edge technologies including the YOLOv8 object detection model for precise cropping of tabular data, Paddle OCR for accurate extraction of information from tabular images, and Fuzzy Wuzzy NLP library for filtering pertinent data from the extracted information necessary for the subsequent machine learning model. The goal is to employ a neural network model to predict potential kidney failure based on the processed medical data. This holistic approach amalgamates advanced computer vision, natural language processing, and machine learning techniques to streamline the analysis of medical reports, potentially enhancing diagnostic accuracy and clinical decision-making in nephrology.
Introduction
I. INTRODUCTION
Intelligent Document Processing (IDP) has become increasingly important in the medical field, particularly for dealing with medical documents. Medical documents, such as patient records, lab reports, and imaging results, contain critical information that needs to be extracted, analyzed, and processed efficiently and accurately. IDP systems leverage arti- ficial intelligence (AI) techniques, including natural language processing (NLP), optical character recognition (OCR), and machine learning algorithms to automate the extraction and interpretation of data from medical documents. In the context of medical documents, IDP plays a crucial role in streamlining administrative tasks, ensuring regulatory compliance, and improving patient care. For instance, IDP can automatically extract relevant information from medical records, such as patient demographics, medical history, medications, and treatment plans. This not only saves time and effort for healthcare professionals but also reduces the chances of errors associated with manual data entry. Additionally, IDP can help identify anomalies or patterns in medical documents that may require further attention, such as inconsistencies in laboratory results or medication dosages. When it comes to disease detection for kidney transplant patients, machine-learning approaches have shown promise in improving diagnostic accuracy and patient outcomes. Machine learning algorithms can analyze large volumes of patient data, including medical records, lab results, genetic profiles, and imaging studies, to identify patterns and correlations that may indicate the presence of specific diseases or predict their likelihood. In the case of kidney transplants, machine learning models can be trained on a diverse dataset of patient records encompassing pre- transplant evaluations, post-operative follow-ups, and long- term outcomes. These models can learn to recognize subtle indicators of complications, rejection episodes, or other ad- verse events that may affect the transplant’s success. By continuously analysing and integrating new patient data, machine learning approaches can adapt and improve their predictive capabilities over time. Moreover, machine learning algorithms can assist in identifying potential organ donors by analyzing various factors, such as compatibility, immunological markers, and recipient-donor matching. This can significantly speed up the process of finding suitable donors and increase the chances of successful kidney transplantation.
In recent years, Intelligent Document Processing (IDP) has emerged as a critical component in the medical domain, revolutionizing the way medical documents are handled and analysed. With the exponential growth of patient records, lab reports, and imaging results, there’s an increasing demand for efficient and accurate extraction, interpretation, and processing of data from medical documents. Leveraging artificial intelligence (AI) techniques such as natural language processing (NLP), optical character recognition (OCR), and machine learning algorithms, IDP systems have shown remarkable potential in automating these tasks. Statistical data underscores the significance of IDP in the medical field. According to a report by Grand View Research, the global healthcare analytics market size is projected to reach USD 129.7 billion by 2028, driven by the increasing adoption of AI and machine learning technologies in healthcare settings.
Additionally, a study published in the Journal of Medical Internet Research highlighted that up to 80% of healthcare data is unstructured, making automated document processing solutions like IDP indispensable for extracting valuable insights. In the realm of kidney diseases, where accurate and timely diagnosis is crucial for patient outcomes, IDP holds promise. Chronic kidney disease (CKD) affects approximately 10% of the global population, with an estimated 850 million individuals world- wide suffering from this condition, as reported by the Global Burden of Disease Study. Moreover, CKD is associated with a substantially increased risk of cardiovascular disease, hospitalizations, and premature mortality, underscoring the urgent need for advanced diagnostic tools. This research paper aims to address this pressing need by proposing a novel pipeline for intelligent document processing of medical reports, focusing on samples primarily obtained from Dr Lal Pathlab, a prominent medical diagnostics provider. The pipeline targets the most common diseases leading to kidney failure, including glomerulonephritis, chronic kidney disease, polycystic kidney disease, hypertensive nephropathy, and lupus nephritis. The proposed pipeline integrates state-of-the-art technologies such as the YOLOv8 object detection model, Paddle OCR, Fuzzy Wuzzy NLP library, and neural network (NN) models. The YOLOv8 model is utilized for precise cropping of tabular data, while Paddle OCR ensures accurate extraction of textual information from tabular images. Subsequently, the Fuzzy Wuzzy NLP library filters out essential data needed for the ML model for prediction, which is then processed by the NN model to predict potential kidney failure. By leveraging these advanced technologies, the proposed pipeline aims to automate and enhance the extraction and analysis of critical information from medical reports related to kidney diseases, thereby facilitating early detection and personalized treatment strategies. This research endeavours to contribute to the advancement of IDP systems in the medical domain and ultimately improve patient outcomes in kidney diseases.
II. METHODOLOGY
The methodology of this research involves a systematic approach, as shown in ”Fig. 1”, to developing an intelligent document processing pipeline tailored to analyze medical reports, primarily sourced from Dr Lal Pathlab and focus- ing on prevalent kidney diseases such as glomerulonephritis, chronic kidney disease, polycystic kidney disease, hyperten- sive nephropathy, and lupus nephritis. The first step entails data acquisition, involving the collection of diverse medical reports to form a comprehensive dataset. Subsequently, preprocessing techniques are applied to clean and standardize the data, ensuring consistency and eliminating noise. The Yolov8 object detection model is then utilized to accurately identify and
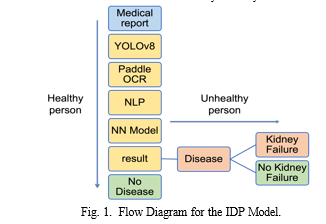
Isolate tabular data within the medical reports, followed by the application of Paddle OCR technology to extract textual information from the identified tables with high precision. The extracted data undergoes further refinement using the Fuzzy Wuzzy NLP library, which employs fuzzy string matching techniques to filter out pertinent information essential for sub- sequent analysis. Feature engineering techniques are then ap- plied to prepare the filtered data for input into a neural network (NN) model. The NN model is trained using the processed data to predict potential kidney failure based on the extracted medical information. Model performance is evaluated using appropriate metrics, and optimization techniques are applied to fine-tune the model parameters. Finally, the developed pipeline is validated using separate datasets to ensure its effectiveness, efficiency, and generalizability. This methodology provides a structured framework for the systematic development and evaluation of the proposed intelligent document processing pipeline for kidney disease diagnosis and management.
A. Medical reports and YOLOv8 model training
In the context of this research project, medical reports serve as crucial documents containing valuable information related to kidney diseases such as glomerulonephritis, chronic kidney disease, polycystic kidney disease, hypertensive nephropathy, and lupus nephritis. These reports typically include various sections such as patient demographics, medical history, labora- tory results, imaging findings, and treatment plans. The goal is to develop an intelligent document processing pipeline capable of extracting, analyzing, and interpreting this information efficiently and accurately. For this, we have gathered multiple sample/dummy reports from the Dr Lal Pathlab of various tests and
To achieve this, the YOLOv8 (You Only Look Once) object detection model is employed to identify and localize tabular data within medical reports. YOLOv8 is a state-of- the-art model known for its speed and accuracy in detecting objects within images. In this context, the model is trained to recognize and delineate the boundaries of tables or tabular structures present in medical reports.
The training process for the YOLOv8 model involves several key steps:
- Data Preparation: Annotated datasets comprising medical reports with manually labeled tabular regions are pre- pared. Each annotation contains information about the coordinates and dimensions of the table within the report.
- Model Configuration: The YOLOv8 architecture is con- figured, specifying parameters such as network depth, input resolution, and training hyper parameters.
- Data Augmentation: To enhance the robustness and generalizability of the model, data augmentation techniques such as rotation, scaling, and flipping may be applied to the training data.
- Model Training: The annotated dataset is used to train the YOLOv8 model. During training, the model learns to identify and localize tabular structures within medical reports by iteratively adjusting its parameters to minimize the detection error.
- Validation: A separate validation dataset is used to evaluate the performance of the trained model. This helps ensure that the model generalizes well to unseen data and does not overfit to the training dataset.
By effectively training the YOLOv8 model to detect tabular data within medical reports, the pipeline can accurately locate and extract relevant information for subsequent processing stages, such as optical character recognition (OCR) and nat- ural language processing (NLP). This enables the efficient extraction of critical data from medical reports, facilitating the prediction and management of kidney diseases with improved accuracy and efficacy.
B. Synthetic Dataset and NN Model Training
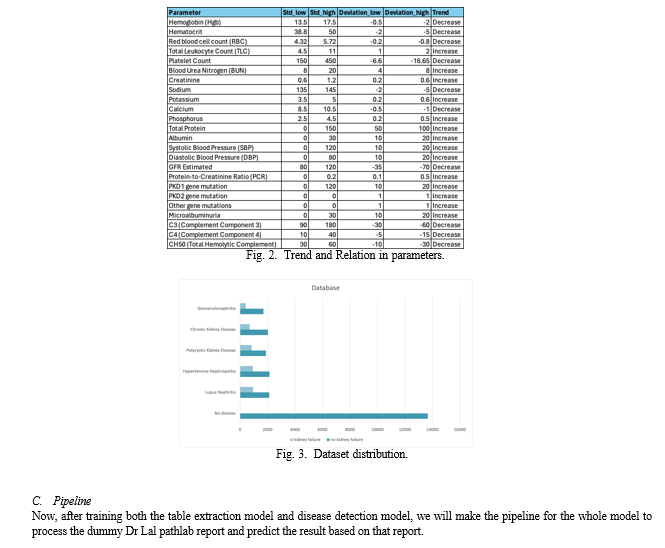
We have researched and found that prevalent diseases leading to kidney failure such as glomerulonephritis, chronic kid- ney disease, polycystic kidney disease, hypertensive nephropathy, and lupus nephritis are detected using the important test like Complete Blood Count Test, Basic Metabolic Panel, Lipid Test, Liver Function Test, Renal Function Test, Urine Test so we have come to a tabular pattern using the ”Fig. 2.” we used normal distribution to generate the synthetic dataset. To create a comprehensive understanding of the data and its application in training a neural network (NN) model for disease detection related to kidney failure, let’s break down the process into several steps:
- Understanding the Data: The provided tabular data contains various parameters typically used in diagnosing diseases leading to kidney failure, along with their standard ranges, deviations, and trends. Each parameter plays a crucial role in understanding the patient’s health status.
- Synthetic Dataset Generation: Synthetic dataset generation involves creating additional data points to supplement the existing dataset. This is often done to enhance the dataset’s diversity and improve the model’s generalization ability.
a. For each parameter, we can generate synthetic data points within the specified standard range but with variations based on the provided deviations. This can be achieved by randomly sampling from a normal distribution centered around the parameter’s mean value and with a standard deviation equal to the specified deviation.
b. We can also introduce correlations between parameters to mimic real-world scenarios. Certain diseases may cause consistent changes in multiple parameters simultaneously.
3. Neural Network Model: A neural network model can be designed to analyze the input parameters and predict the likelihood of a patient having a specific disease related to kidney failure. The architecture of the NN model can vary based on factors like the complexity of the problem, size of the dataset, and desired accuracy. Here’s a generalized approach:
a. Input Layer: The input layer of the NN will have neurons corresponding to each parameter in the dataset.
b. Hidden Layers: One or more hidden layers can be added to capture complex patterns in the data. The number of neurons and layers can be adjusted based on experimentation and performance evaluation.
c. Output Layer: The output layer will have neurons representing the classes or categories of diseases. For binary classification (e.g., presence or absence of a disease), a single output neuron with a sigmoid activation function can be used. For multi-class clas- sification (e.g., different types of kidney diseases), multiple output neurons with softmax activation can be employed.
d. Activation Functions: Common activation functions like ReLU (Rectified Linear Unit), sigmoid, and softmax can be used in the hidden and output lay- ers to introduce non-linearity and make the model capable of learning complex relationships.
e. Loss Function and Optimizer: Binary cross-entropy loss function is commonly used for binary classifi- cation tasks, while categorical cross-entropy loss is used for multi-class classification. Adam or SGD (Stochastic Gradient Descent) optimizers can be employed for model training.
f. Model Training: The dataset, both original and synthetic, will be split into training, validation, and testing sets. The model will be trained on the training set, validated on the validation set to tune hyperparameters and prevent overfitting, and finally evaluated on the testing set to assess its performance.
g. Evaluation Metrics: Evaluation metrics such as ac- curacy, precision, recall, F1-score, and ROC-AUC can be used to assess the performance of the model.



III. RESULTS
The developed pipeline for intelligent document processing of medical reports, particularly focusing on kidney-related diseases, exhibits several notable strengths. Firstly, it boasts compatibility with PDF inputs of varying lengths, offering flexibility and adaptability to handle diverse medical reports efficiently. Additionally, the pipeline demonstrates proficiency in detecting tables and metadata from the input PDFs, ensuring accurate extraction of relevant information crucial for diagno- sis. Moreover, it incorporates a feature to preserve extracted data, enabling further validation and analysis, which enhances the reliability of the processed results.
However, the pipeline also presents some weaknesses that warrant attention. One such limitation is the requirement to merge PDFs from different tests before inputting them into the pipeline, which introduces an additional preprocessing step and may increase complexity. Furthermore, the detection model utilized in the pipeline may suffer from inaccuracies, leading to potential misidentification or incomplete extraction of tables and metadata, thereby impacting the overall reliability of the processed data. Moreover, the multiple iterations of data saving during processing contribute to high time complexity, potentially affecting the efficiency of the pipeline. Despite these weaknesses, the performance metrics of the pipeline are promising. The YOLOv8 model for table detection exhibits a commendable accuracy of approximately 95%, indicating reliable identification of tabular data within the PDF documents. Additionally, the neural network model trained on synthetic datasets achieves an accuracy of around 92% in disease detection, demonstrating its efficacy in predicting kidney-related diseases based on extracted data. In conclusion, while the pipeline demonstrates strengths in PDF compatibility, table detection, and data preservation, there are areas for improvement, particularly in enhancing detection model accuracy and optimizing processing efficiency. Ad- dressing these weaknesses will be crucial for maximizing the pipeline’s effectiveness and usability in real-world scenarios, ultimately leading to improved diagnosis and management of kidney-related diseases.
Conclusion
In conclusion, the developed pipeline represents a significant step forward in the field of intelligent document processing, particularly focusing on medical reports related to kidney-related diseases. By leveraging advanced technologies such as YOLOv8 for layout detection, Paddle OCR for text extraction, Fuzzy Wuzzy NLP for data filtering, and neural network models for disease prediction, the pipeline demon- strates promising results in accurately analyzing electronically generated PDF reports from Dr Lal Path Lab. However, it’s important to note that the current implementation is trained on dummy PDFs and synthetically generated datasets. While this serves as a proof of concept (POC), there’s a clear path forward for enhancing the pipeline’s capabilities. Future efforts will involve training the pipeline on real-world datasets encompass- ing a wide variety of formats and sources, ensuring robustness and generalizability across different scenarios. Additionally, there is a strong emphasis on optimizing the pipeline for speed and efficiency. Implementing concurrent processing, especially leveraging GPU acceleration, will significantly enhance the pipeline’s performance, enabling fast and accurate predictions even on large datasets. Overall, the pipeline’s envisioned trajectory involves continuous refinement and adaptation to meet the evolving demands of medical document processing. With further development and integration of cutting-edge tech- nologies, the pipeline holds immense potential to revolutionize the diagnosis and management of kidney-related diseases, ultimately contributing to improved patient care and outcomes.
References
[1] Lore: AI Newsletter & Resources to Help Your Business Grow. ”Can AI Make PowerPoint Presentations?” Retrieved from: https://lore.com/ blog/can-ai-make-powerpoint-presentations [2] Opportunities Global. ”Top 10 Medical Courier Jobs in 2023.” Retrieved from: https://opportunitiesglobal.net/ top-10-medical-courier-jobs-in-2023/ [3] Lano, Kevin, Sobhan Y. Tehrani, M. S. Umar, and Lyan Alwakeel. ”Using Artificial Intelligence for the Specification of M-Health and E-Health Systems.” Future of Business and Finance (2022). DOI: https://doi.org/10.1007/978-3-030-99838-7 15 [4] dipoleDIAMOND. ”Intelligent Process Automation: Exploring New Horizons for Efficiency and Innovation.” Retrieved from: https://www. dipolediamond.com/intelligent-process-automation-new-horizons/ [5] goonline.io. ”OCR in Healthcare: Improving Record Keeping and Patient Outcomes.” Retrieved from: https://goonline.io/blog/ ocr-in-healthcare-improving-record-keeping-and-patient-outcomes/ [6] TipsBin.net. ”Can ChatGPT Transform Healthcare?” Retrieved from: https://www.tipsbin.net/can-chatgpt-transform-healthcare/ [7] Castillo Vizuete, Danny, Danny Castillo Vizuete, and Marina Marcu. ”Exploring the Role of ICTs and Communication Flows in the Forest Sector.” Sustainability 15, no. 14 (2023): 10973. [8] Iglesia, Diana D. L., Miguel Garc´?a-Remesal, Alberto Anguita, Miguel Mun˜oz-Ma´rmol, Casimir A. Kulikowski, and V´?ctor Maojo. ”A Machine Learning Approach to Identify Clinical Trials Involving Nanodrugs and Nanodevices from ClinicalTrials.Gov.” PLOS ONE (2014). DOI: https://doi.org/10.1371/journal.pone.0110331 [9] DataOps Redefined!!!. ”What is the MLOps market size?” Retrieved from: https://www.thedataops.org/what-is-the-mlops-market-size/ [10] Piccoli, Giorgina, Mona Alrukhaimi, Zhi-Hong Liu, Elena Zakharova, and Adeera Levin. ”Women and Kidney Disease: Reflections on World Kidney Day 2018.” Nephrology Nursing Journal 45, no. 1 (2018): 65-71. [11] Laush, Kimberley A. ”Strategic Planning in a Higher Education Con- text.” (2021). Retrieved from: https://core.ac.uk/download/481531455. pdf [12] Underdog Chance. ”The Fallacy of Betting Trends: Why They Are Often Unreliable.” Retrieved from: https://www.underdogchance.com/ betting-trends/ [13] SpringerLink. ”The Future Circle of Healthcare: AI, 3D Printing, Longevity, Ethics, and Uncertainty Mitigation.” Retrieved from: https://link.springer.com/book/10.1007/978-3-030-99838-7?error=cookies not supported&code=abec7922-fd12-4bb5-bbb6-9e28a9e357bb [14] Javatpoint. ”Earthquake Prediction Using Machine Learning.” Retrieved from: https://www.javatpoint.com/ earthquake-prediction-using-machine-learning [15] California Law TV. ”How Long Do Insurers Have to Settle Car Acci- dent Claims in California?” Retrieved from: https://californialawtv.com/ how-long-do-insurers-have-to-settle-car-accident-claims-in-california/ [16] Win, Khin, Noppadol Maneerat, Noppadol Maneerat, Syna Sreng, and Kazuhiko Hamamoto. ”Ensemble Deep Learning for the Detection of COVID-19 in Unbalanced Chest X-ray Dataset.” Applied Sciences 11, no. 22 (2021): 10528. [17] Life With Data. ”How to Calculate the Area Under the Curve (AUC) in Python.” Retrieved from: https://lifewithdata.com/2023/06/06/ how-to-calculate-the-area-under-the-curve-auc-in-python/ [18] Furini, M., Mirri, S., & Montangero, M. (2018). ”Topic-based playlist to improve video lecture accessibility.” DOI: https://doi.org/10.1109/ccnc. 2018.8319246 [19] Kittelson, J. M. (2015). ”Total Glucosinolate Preservation and Near Infrared Prediction in Rapeseed Meal.” Retrieved from: https://core.ac. uk/download/211309155.pdf
Copyright
Copyright © 2024 Shankar Sharan Tripathi, Nishant Roy, Aakash Kumar Singh, Ayush Kumar Agarwal, Prashant Singh Rajput. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET61951
Publish Date : 2024-05-11
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online