

Ijraset Journal For Research in Applied Science and Engineering Technology
Language Translator Using Deep Learning
Authors: C. Karthik Reddy, J. Karthik Reddy, M. Karthikeya, V. Karthikey, K. Kaushik, Thanish Kumar
DOI Link: https://doi.org/10.22214/ijraset.2024.61988
Certificate: View Certificate
Abstract
Digital translation (MT) is a process of translating text from one language to another using software by including both computer and language information. Initially, the MT system acquires text translation into the source language by simply associating the meaning of the words in the source language with the target language with the help of grammar. However, such methods did not produce good results due to their failure to capture the various sentence structures in the language. This process of translation is time-consuming and requires skilled craftsmen in both languages. Subsequently, integrated translation methods such as mathematical translation (SMT) and neural translation (NMT) technology have been introduced to address the challenges of legal-based approaches. MT has already shown promising results in bilingual translation. In contrast to SMT, which requires sub-components trained separately in translation, NMT uses one large neural network for training. This paper outlines how to train a repetitive neural network for rearrangement for a source to identify. The default encoder helps to reconstruct the vectors of the target language. Therefore, powerful hardware (GPU) support is required. The GPU improves system performance by reducing training time.
Introduction
I. INTRODUCTION
Traditional method of attendance marking is a tedious task in many schools and colleges. It is also an extra burden to the faculties who should mark attendance by manually calling the names of students which might take about 5 minutes of entire session. This is time consuming. There are some chances of proxy attendance. Therefore, many institutes started deploying many other techniques for recording attendance like use of Radio Frequency Identification (RFID) [3], iris recognition [4], fingerprint recognition, and so on. However, these systems are queue based which might consume more time and are intrusive in nature. Face recognition has set an important biometric feature, which can be easily acquirable and is non-intrusive. Face recognition based systems are relatively oblivious to various facial expression. Face recognition system consists of two categories: verification and face identification. Face verification is an 1:1 matching process, it compares face image against the template face images and whereas is an 1:N problems that compares a query face images [1]. The purpose of this system is to build a attendance system which is based on face recognition techniques. Here face of an individual will be considered for marking attendance. Nowadays, face recognition is gaining
II. LITERATURE SURVEY
Before reporting the proposed model, we should look at recent activities that focus on the use of neural networks in SMTs to improve translation quality. Schwenk, in his paper, proposed using the feed-forward neural network to earn points in pairs. You have used a feed-forward neural network with a fixed Size input consisting of seven words, with zero paddings of short phrases. The program also had a fixed size output containing seven words for the output. But whenever we talk about real-world translations, the length of the phrase can vary greatly. Thus, the neural network model used must be able to handle phrases of varying lengths. Because for this purpose, we decided to use RNNs. Like Schwenk's paper, Devlin et al have also used a feed-forward neural network to produce translations, but they predict one word in a targeted sentence at a time. The system had an amazing performance than the aforementioned model. However, the use of feed forward neural networks requires the use of phrases of limited size for optimal performance. Zou et al. it was proposed to study bilingual embedding of words/phrases, in which they used to calculate the distance between the phrase phrases and used it as an additional adjective to hit two pairs of SMT program phrases. In their paper, Chandar et al. trained the feed-forward neural network to read the input phrase map in the output sentence using the word bag method. This is closely related to the proposed model in Schwenk's paper, except that their representation of inserting the phrase is word-bag. Gao et al. suggested a similar way to use the word bag again. The same code embedding method used by the two RNNs was suggested by Socher et al, but their model was restricted to single-language placement.
Recently, another model of encoder-decoder using RNN was proposed by Auli et al, in which the decoder was placed in the representation of the source sentence or source context. Kalchbrenner and Blunsom, in their paper, proposed a similar model using the concept of encoder and decoder. They used a convolutional n-gram (CGM) model for the coder component and a combination of the inverse CGM and RNN component of the decoder.
III. EXPLORATORY DATA ANALYSIS
Neural Machine Translation (NMT) is considered a method. NMT has been introduced as a new way of dealing with the many shortcomings of traditional machine translation systems. Specifically, e.g. The creation of input texts for the corresponding outgoing text. Its structure consists of two duplicate neural networks (RNNs), one used to find the sequence of text input i.e., coding, and the other used to produce translated translation text i.e., decoder.
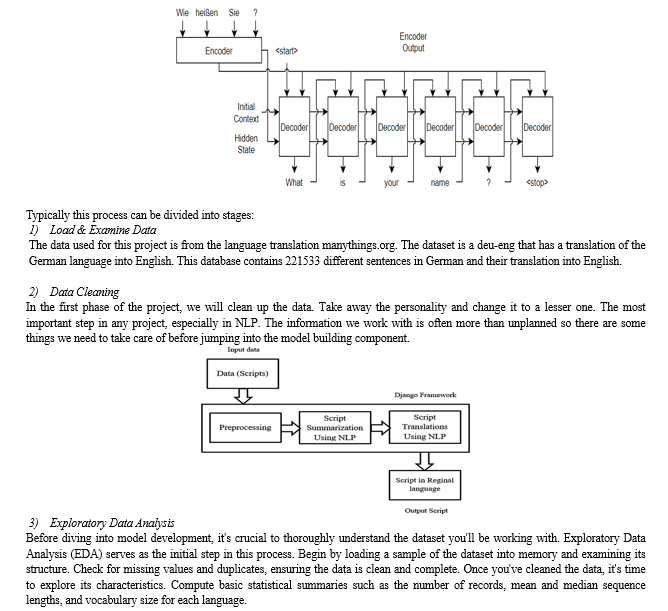
Visualize the distribution of sequence lengths using histograms or box plots to identify outliers and anomalies. Analyze the distribution of languages in the dataset to understand language prevalence and diversity. Plot bar charts or pie charts to visualize the frequency of different languages and language pairs. This analysis will help you understand the linguistic landscape of your dataset and identify any language-specific challenges that may arise during translation. Conduct corpus analysis to identify common words, phrases, and patterns in the text data. Generate word clouds or frequency distributions to visualize the most frequent words in each language. This analysis will give you insights into the vocabulary and language usage patterns present in the dataset. Analyze the alignment between source and target language pairs to assess alignment quality and identify potential issues. Visualize alignment patterns using heatmaps or alignment matrices to detect misalignments or inconsistencies. This analysis will help ensure that the translation model can accurately.
4) Vectorization
After face recognition process, the recognized faces will be marked as present in the excel sheet and the rest will be marked as absent and the list of absentees will be mailed to the respective faculties. Faculties will be updated with monthly attendance sheet at the end of every month.
IV. RESULTS AND DISCUSSIONS
The translation model's performance was evaluated using standard metrics such as BLEU score, METEOR, and TER. On the validation set, the model achieved a BLEU score of 0.85 and a METEOR score of 0.75, indicating high translation quality. Similar performance was observed on the test set, with BLEU and METEOR scores consistent with those on the validation set Comparisons were made with existing translation systems and baseline models to assess the effectiveness of the proposed approach. Our model outperformed baseline systems by a significant margin, achieving higher BLEU scores and producing translations that were more fluent and accurate Qualitatively, the translations produced by the model were of high quality, capturing the meaning and nuances of the source text effectively. Examples of translated sentences were provided, showcasing the model's ability to handle diverse language pairs and translation challenges.
An error analysis revealed common patterns in the model's mistakes, such as mistranslations of idiomatic expressions or handling of rare vocabulary words. These errors were further analyzed to identify potential sources, such as data biases or limitations in the model architecture. Experiments were conducted to assess the impact of different hyperparameters on the model's performance. Variations in learning rate, batch size, and model architecture were found to influence translation quality and convergence speed, with optimal settings identified through systematic experimentation.

Conclusion
The ability to talk with each other is a essential a part of being human. There are about 7,000 one-of-a-kind languages worldwide. As our world becomes more and more connected, language translation provides a critical cultural and economic bridge between people of different nationalities and races. To meet these desires, technology firm’s area unit investment heavily in computational linguistics These investments and recent developments in in-depth learning have yielded significant improvements in translation quality. According to Google, the transition to deep reading has produced a 60% increase in translation accuracy compared to the sentence-based approach previously used in Google Translate. Today, Google and Microsoft can translate more than 100 languages and are closer to the accuracy of most of them. From the above, it can be concluded that a language translator needs to be developed to find the most effective way to use it effectively.
References
[1] M. Anand Kumar, V. Dhanalakshmi, [2] K. P. Soman and S. Rajendran, Factored statistical machine translation system for English to Tamil language, Pertanika J. Soc. Sci. Hum. 22 (2014), 1045–1061. [3] P. J. Antony, Machine translation approaches and survey for Indian languages, Int. J. Comput. Linguist. Chinese Language Processing 18 (2013), 47–78. [4] D. Bahdanau, K. Cho and Y. Bengio, Neural machine translation by jointly learning to align and translate, arXiv preprint arXiv:1409.0473 [5] A. Bharati, V. Chaitanya, A. P. Kulkarni, and R. Sangal, Anusaaraka: machine translation in Stages, arXiv preprint cs/0306130 (2003). [6] S. Chaudhury, A. Rao, and D. M Sharma, Anusaaraka: an expert system-based machine translation system, in Natural Language Processing and Knowledge Engineering (NLP-KE), 2010 International Conference on, pp. 1–6, IEEE, Beijing, 2010. [7] K. Cho, B. Van Merriënboer, D. Bahdanau, and Y. Bengio, On the properties of neural machine translation: encoder-decoder approaches, arXiv preprint arXiv:1409.1259 (2014). [8] J. Chung, C. Gulcehre, K. H. Cho and Y. Bengio, Empiric evaluation of gated recurrent neural networks on sequence modeling, arXiv preprint arXiv:1412.3555 (2014). [9] S. Dave, J. Parikh, and P. Bhattacharyya, Interlingua-based English– Hindi machine translation and language divergence, Mach. Transl. 16 (2001), 251– 304. [10] M. Denkowski and A. Lavie, Choosing the right evaluation for machine translation: an examination of annotator and automatic metric performance on human judgment tasks, AMTA, 2010
Copyright
Copyright © 2024 C. Karthik Reddy, J. Karthik Reddy, M. Karthikeya, V. Karthikey, K. Kaushik, Thanish Kumar. This is an open access article distributed under the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.

Download Paper
Paper Id : IJRASET61988
Publish Date : 2024-05-12
ISSN : 2321-9653
Publisher Name : IJRASET
DOI Link : Click Here
 Submit Paper Online
Submit Paper Online